- 1Linux Centos 78 计划任务 开机自动启动 查杀木马过程-使用 rootkit 隐藏踪迹_centos隐藏计划任务
- 2qt视窗事件,定时器事件及自定义事件处理源码分析_qt自定义事件能带参数吗
- 3数据库-MySQL-02-基本查询-条件查询-聚合函数-分组查询-排序查询-分页查询-多表设计_mysql聚合函数做查询条件
- 4【数据结构】堆(Heap)_数据结构堆
- 5特殊矩阵的压缩存储
- 6Aurora 8B/10B IP核(1)----如何理解Aurora 8B/10B协议?_aurora 8b10b
- 7数据结构——堆和堆排序(python)_堆数据结构
- 8【Langchain多Agent实践】一个有推销功能的旅游聊天机器人
- 9机器学习笔记(14)Transformer(三):positional encoding的理解_bert positional encoding 知乎
- 10C++初阶学习第八弹——探索STL奥秘(三)——深入刨析vector的使用
推荐系统系列—协同过滤算法_基于协同过滤算法资源推荐
赞
踩
目录
什么时候使用UserCF,什么时候使用ItemCF?为什么?
协同过滤算法
基本思想:是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐).简单来说,就是物以类聚,人以群分。这种思想还可以应用到跨域推荐中。而在FFM算法模型中,引入了“域”的概念,这是运用了这种思想。
使用的数据:是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐)
目前应用比较广泛的协同过滤算法是基于邻域的方法, 而这种方法主要有下面两种算法:
-
基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
-
基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
不管是UserCF还是ItemCF算法, 非常重要的步骤之一就是计算用户和用户或者物品和物品之间的相似度, 所以下面先整理常用的相似性度量方法, 然后再对每个算法的具体细节进行展开。
相似度度量方法
-
余弦相似度
从向量的角度进行描述,令矩阵A为用户-商品交互矩阵(因为是TopN推荐并不需要用户对物品的评分,只需要知道用户对商品是否有交互就行),即矩阵的每一行表示一个用户对所有商品的交互情况,有交互的商品值为1没有交互的商品值为0,矩阵的列表示所有商品。若用户和商品数量分别为m,n的话,交互矩阵A就是一个m行n列的矩阵。此时用户的相似度可以表示为(其中u*v指的是向量点积):
-
皮尔逊相关系数
基于用户的协同过滤算法(UserCF)
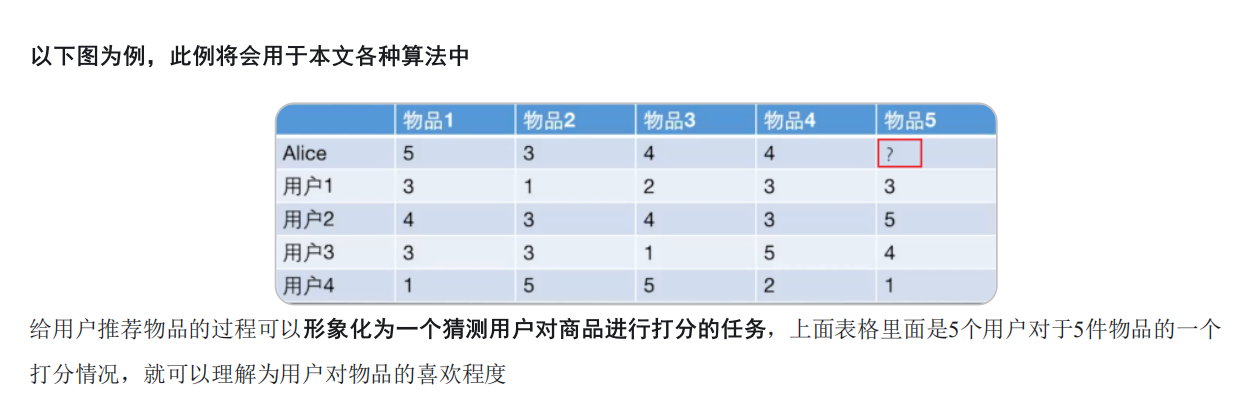
应用UserCF算法的两个步骤:
-
首先根据前面的这些打分情况(或者说已有的用户向量)计算一下Alice和用户1, 2, 3, 4的相似程度, 找出与Alice最相似的n个用户
-
根据这n个用户对物品5的评分情况和与Alice的相似程度会猜测出Alice对物品5的评分, 如果评分比较高的话, 就把物品5推荐给用户Alice, 否则不推荐。
最终得分结果的预测
我们选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值, 那么是怎么计算的呢?


UserCF示例代码
import pandas as pd
import numpy as np
import warnings
import random, math, os
from tqdm import tqdm
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
# 评价指标
# 推荐系统推荐正确的商品数量占用户实际点击的商品数量
def Recall(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rel_set)
return round(hit_items / all_items * 100, 2)
# 推荐系统推荐正确的商品数量占给用户实际推荐的商品数
def Precision(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rec_set)
return round(hit_items / all_items * 100, 2)
# 所有被推荐的用户中,推荐的商品数量占这些用户实际被点击的商品数量
def Coverage(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
rec_items = set()
all_items = set()
for uid in Rec_dict:
for item in Trn_dict[uid]:
all_items.add(item)
for item in Rec_dict[uid]:
rec_items.add(item)
return round(len(rec_items) / len(all_items) * 100, 2)
# 使用平均流行度度量新颖度,如果平均流行度很高(即推荐的商品比较热门),说明推荐的新颖度比较低
def Popularity(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
pop_items = {}
for uid in Trn_dict:
for item in Trn_dict[uid]:
if item not in pop_items:
pop_items[item] = 0
pop_items[item] += 1
pop, num = 0, 0
for uid in Rec_dict:
for item in Rec_dict[uid]:
pop += math.log(pop_items[item] + 1) # 物品流行度分布满足长尾分布,取对数可以使得平均值更稳定
num += 1
return round(pop / num, 3)
# 将几个评价指标指标函数一起调用
def rec_eval(val_rec_items, val_user_items, trn_user_items):
print('recall:', Recall(val_rec_items, val_user_items))
print('precision', Precision(val_rec_items, val_user_items))
print('coverage', Coverage(val_rec_items, trn_user_items))
print('Popularity', Popularity(val_rec_items, trn_user_items))
def get_data(root_path):
# 读取数据
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(os.path.join(root_path, 'ratings.dat'), sep='::', engine='python', names=rnames)
# 分割训练和验证集
trn_data, val_data, _, _ = train_test_split(ratings, ratings, test_size=0.2)
trn_data = trn_data.groupby('user_id')['movie_id'].apply(list).reset_index()
val_data = val_data.groupby('user_id')['movie_id'].apply(list).reset_index()
trn_user_items = {}
val_user_items = {}
# 将数组构造成字典的形式{user_id: [item_id1, item_id2,...,item_idn]}
for user, movies in zip(*(list(trn_data['user_id']), list(trn_data['movie_id']))):
trn_user_items[user] = set(movies)
for user, movies in zip(*(list(val_data['user_id']), list(val_data['movie_id']))):
val_user_items[user] = set(movies)
return trn_user_items, val_user_items
def Item_CF(trn_user_items, val_user_items, K, N):
'''
trn_user_items: 表示训练数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
val_user_items: 表示验证数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
K: K表示的是相似商品的数量,为每个用户交互的每个商品都选择其最相思的K个商品
N: N表示的是给用户推荐的商品数量,给每个用户推荐相似度最大的N个商品
'''
# 建立user->item的倒排表
# 倒排表的格式为: {user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...} 也就是每个用户交互过的所有商品集合
# 由于输入的训练数据trn_user_items,本身就是这中格式的,所以这里不需要进行额外的计算
# 计算商品协同过滤矩阵
# 即利用user-items倒排表统计商品与商品之间被共同的用户交互的次数
# 商品协同过滤矩阵的表示形式为:sim = {item_id1: {item_id2: num1}, item_id3: {item_id4: num2}, ...}
# 商品协同过滤矩阵是一个双层的字典,用来表示商品之间共同交互的用户数量
# 在计算商品协同过滤矩阵的同时还需要记录每个商品被多少不同用户交互的次数,其表示形式为: num = {item_id1:num1, item_id2:num2, ...}
sim = {}
num = {}
print('构建相似性矩阵...')
for uid, items in tqdm(trn_user_items.items()):
for i in items:
if i not in num:
num[i] = 0
num[i] += 1
if i not in sim:
sim[i] = {}
for j in items:
if j not in sim[i]:
sim[i][j] = 0
if i != j:
sim[i][j] += 1
# 计算物品的相似度矩阵
# 商品协同过滤矩阵其实相当于是余弦相似度的分子部分,还需要除以分母,即两个商品被交互的用户数量的乘积
# 两个商品被交互的用户数量就是上面统计的num字典
print('计算协同过滤矩阵...')
for i, items in tqdm(sim.items()):
for j, score in items.items():
if i != j:
sim[i][j] = score / math.sqrt(num[i] * num[j])
# 对验证数据中的每个用户进行TopN推荐
# 在对用户进行推荐之前需要先通过商品相似度矩阵得到当前用户交互过的商品最相思的前K个商品,
# 然后对这K个用户交互的商品中除当前测试用户训练集中交互过的商品以外的商品计算最终的相似度分数
# 最终推荐的候选商品的相似度分数是由多个相似商品对该商品分数的一个累加和
items_rank = {}
print('给用户进行推荐...')
for uid, _ in tqdm(val_user_items.items()):
items_rank[uid] = {} # 存储用户候选的推荐商品
for hist_item in trn_user_items[uid]: # 遍历该用户历史喜欢的商品,用来下面寻找其相似的商品
for item, score in sorted(sim[hist_item].items(), key=lambda x: x[1], reverse=True)[:K]:
if item not in trn_user_items[uid]: # 进行推荐的商品一定不能在历史喜欢商品中出现
if item not in items_rank[uid]:
items_rank[uid][item] = 0
items_rank[uid][item] += score
print('为每个用户筛选出相似度分数最高的N个商品...')
items_rank = {k: sorted(v.items(), key=lambda x: x[1], reverse=True)[:N] for k, v in items_rank.items()}
items_rank = {k: set([x[0] for x in v]) for k, v in items_rank.items()}
return items_rank
if __name__ == "__main__":
root_path = './data/ml-1m/'
trn_user_items, val_user_items = get_data(root_path)
rec_items = Item_CF(trn_user_items, val_user_items, 80, 10)
rec_eval(rec_items, val_user_items, trn_user_items)
数据及下载链接:链接:https://pan.baidu.com/s/1a9v9g_6w7NxVVW4LwP2LSQ 提取码:vcp9
UserCF优缺点
User-based算法存在两个重大问题:
-
数据稀疏性。
一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。这导致UserCF不适用于那些正反馈获取较困难的 应用场景(如酒店预订, 大件商品购买等低频应用)
-
算法扩展性。
基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出Topn相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加,不适合用户数据量大的情况使用。
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
基于物品的协同过滤
应用ItemCF算法的两个步骤:
-
首先计算一下物品5和物品1, 2, 3, 4之间的相似性(它们也是向量的形式, 每一列的值就是它们的向量表示, 因为ItemCF认为物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c, 所以就可以基于每个用户对该物品的打分或者说喜欢程度来向量化物品)
-
找出与物品5最相近的n个物品
-
根据Alice对最相近的n个物品的打分去计算对物品5的打分情况

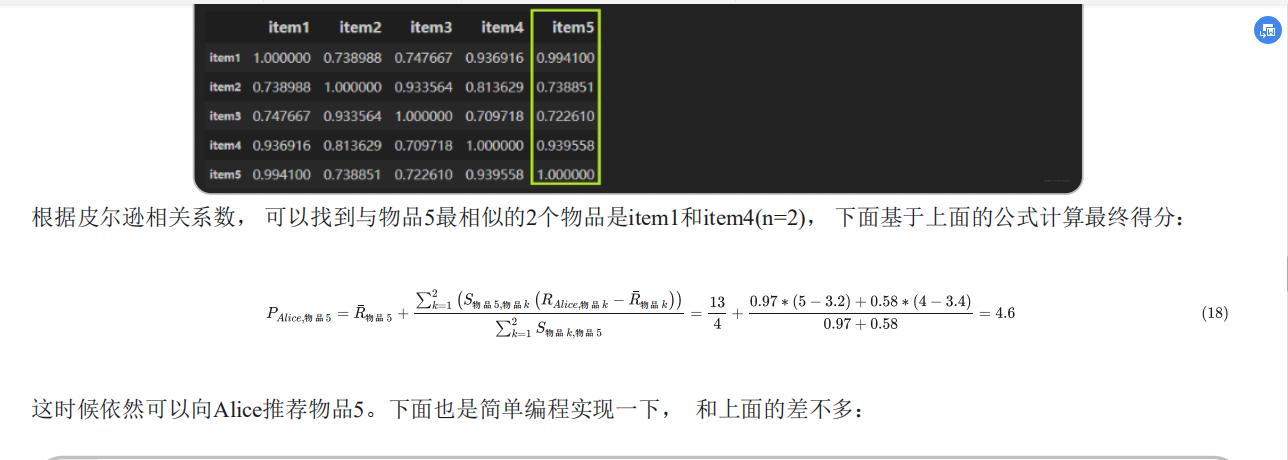
ItemCF示例代码
import pandas as pd
import numpy as np
import warnings
import random, math, os
from tqdm import tqdm
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
# 评价指标
# 推荐系统推荐正确的商品数量占用户实际点击的商品数量
def Recall(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rel_set)
return round(hit_items / all_items * 100, 2)
# 推荐系统推荐正确的商品数量占给用户实际推荐的商品数
def Precision(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rec_set)
return round(hit_items / all_items * 100, 2)
# 所有被推荐的用户中,推荐的商品数量占这些用户实际被点击的商品数量
def Coverage(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
rec_items = set()
all_items = set()
for uid in Rec_dict:
for item in Trn_dict[uid]:
all_items.add(item)
for item in Rec_dict[uid]:
rec_items.add(item)
return round(len(rec_items) / len(all_items) * 100, 2)
# 使用平均流行度度量新颖度,如果平均流行度很高(即推荐的商品比较热门),说明推荐的新颖度比较低
def Popularity(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
pop_items = {}
for uid in Trn_dict:
for item in Trn_dict[uid]:
if item not in pop_items:
pop_items[item] = 0
pop_items[item] += 1
pop, num = 0, 0
for uid in Rec_dict:
for item in Rec_dict[uid]:
pop += math.log(pop_items[item] + 1) # 物品流行度分布满足长尾分布,取对数可以使得平均值更稳定
num += 1
return round(pop / num, 3)
# 将几个评价指标指标函数一起调用
def rec_eval(val_rec_items, val_user_items, trn_user_items):
print('recall:', Recall(val_rec_items, val_user_items))
print('precision', Precision(val_rec_items, val_user_items))
print('coverage', Coverage(val_rec_items, trn_user_items))
print('Popularity', Popularity(val_rec_items, trn_user_items))
def get_data(root_path):
# 读取数据
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv(os.path.join(root_path, 'ratings.dat'), sep='::', engine='python', names=rnames)
# 分割训练和验证集
trn_data, val_data, _, _ = train_test_split(ratings, ratings, test_size=0.2)
trn_data = trn_data.groupby('user_id')['movie_id'].apply(list).reset_index()
val_data = val_data.groupby('user_id')['movie_id'].apply(list).reset_index()
trn_user_items = {}
val_user_items = {}
# 将数组构造成字典的形式{user_id: [item_id1, item_id2,...,item_idn]}
for user, movies in zip(*(list(trn_data['user_id']), list(trn_data['movie_id']))):
trn_user_items[user] = set(movies)
for user, movies in zip(*(list(val_data['user_id']), list(val_data['movie_id']))):
val_user_items[user] = set(movies)
return trn_user_items, val_user_items
def Item_CF(trn_user_items, val_user_items, K, N):
'''
trn_user_items: 表示训练数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
val_user_items: 表示验证数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
K: K表示的是相似商品的数量,为每个用户交互的每个商品都选择其最相思的K个商品
N: N表示的是给用户推荐的商品数量,给每个用户推荐相似度最大的N个商品
'''
# 建立user->item的倒排表
# 倒排表的格式为: {user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...} 也就是每个用户交互过的所有商品集合
# 由于输入的训练数据trn_user_items,本身就是这中格式的,所以这里不需要进行额外的计算
# 计算商品协同过滤矩阵
# 即利用user-items倒排表统计商品与商品之间被共同的用户交互的次数
# 商品协同过滤矩阵的表示形式为:sim = {item_id1: {item_id2: num1}, item_id3: {item_id4: num2}, ...}
# 商品协同过滤矩阵是一个双层的字典,用来表示商品之间共同交互的用户数量
# 在计算商品协同过滤矩阵的同时还需要记录每个商品被多少不同用户交互的次数,其表示形式为: num = {item_id1:num1, item_id2:num2, ...}
sim = {}
num = {}
print('构建相似性矩阵...')
for uid, items in tqdm(trn_user_items.items()):
for i in items:
if i not in num:
num[i] = 0
num[i] += 1
if i not in sim:
sim[i] = {}
for j in items:
if j not in sim[i]:
sim[i][j] = 0
if i != j:
sim[i][j] += 1
# 计算物品的相似度矩阵
# 商品协同过滤矩阵其实相当于是余弦相似度的分子部分,还需要除以分母,即两个商品被交互的用户数量的乘积
# 两个商品被交互的用户数量就是上面统计的num字典
print('计算协同过滤矩阵...')
for i, items in tqdm(sim.items()):
for j, score in items.items():
if i != j:
sim[i][j] = score / math.sqrt(num[i] * num[j])
# 对验证数据中的每个用户进行TopN推荐
# 在对用户进行推荐之前需要先通过商品相似度矩阵得到当前用户交互过的商品最相思的前K个商品,
# 然后对这K个用户交互的商品中除当前测试用户训练集中交互过的商品以外的商品计算最终的相似度分数
# 最终推荐的候选商品的相似度分数是由多个相似商品对该商品分数的一个累加和
items_rank = {}
print('给用户进行推荐...')
for uid, _ in tqdm(val_user_items.items()):
items_rank[uid] = {} # 存储用户候选的推荐商品
for hist_item in trn_user_items[uid]: # 遍历该用户历史喜欢的商品,用来下面寻找其相似的商品
for item, score in sorted(sim[hist_item].items(), key=lambda x: x[1], reverse=True)[:K]:
if item not in trn_user_items[uid]: # 进行推荐的商品一定不能在历史喜欢商品中出现
if item not in items_rank[uid]:
items_rank[uid][item] = 0
items_rank[uid][item] += score
print('为每个用户筛选出相似度分数最高的N个商品...')
items_rank = {k: sorted(v.items(), key=lambda x: x[1], reverse=True)[:N] for k, v in items_rank.items()}
items_rank = {k: set([x[0] for x in v]) for k, v in items_rank.items()}
return items_rank
if __name__ == "__main__":
root_path = './data/ml-1m/'
trn_user_items, val_user_items = get_data(root_path)
rec_items = Item_CF(trn_user_items, val_user_items, 80, 10)
rec_eval(rec_items, val_user_items, trn_user_items)
协同过滤算法的权重改进
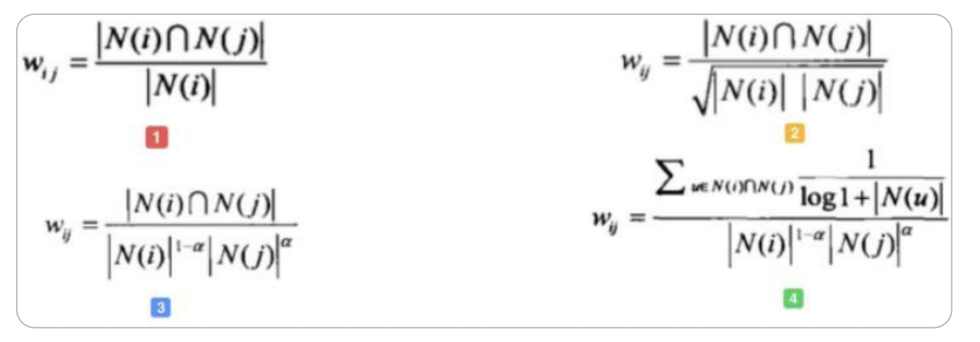
-
基础算法
图1为最简单的计算物品相关度的公式, 分子为同时喜好itemi和itemj的用户数
-
对热门物品的惩罚
图1存在一个问题, 如果 item-j 是很热门的商品,导致很多喜欢 item-i 的用户都喜欢 item-j,这时wij就会非常大。同样,几乎所有的物品都和 item-j 的相关度非常高,这显然是不合理的。所以图2中分母通过引入N(j)来对 item-j 的热度进行惩罚。如果物品很热门, 那么N(j)就会越大, 对应的权重就会变小。
-
对热门物品的进一步惩罚
如果 item-j 极度热门,上面的算法还是不够的。举个例子,《Harry Potter》非常火,买任何一本书的人都会购买它,即使通过图2的方法对它进行了惩罚,但是《Harry Potter》仍然会获得很高的相似度。这就是推荐系统领域著名的Harry Potter Problem。如果需要进一步对热门物品惩罚,可以继续修改公式为如图3所示,通过调节参数阿尔法 ,阿尔法越大,惩罚力度越大,热门物品的相似度越低,整体结果的平均热门程度越低。
-
对活跃用户的惩罚
同样的,Item-based CF 也需要考虑活跃用户(即一个活跃用户(专门做刷单)可能买了非常多的物品)的影响,活跃用户对物品相似度的贡献应该小于不活跃用户。图4为集合了该权重的算法。
协同过滤算法的问题分析
协同过滤算法存在的问题之一就是泛化能力弱, 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。 比如下面这个例子:
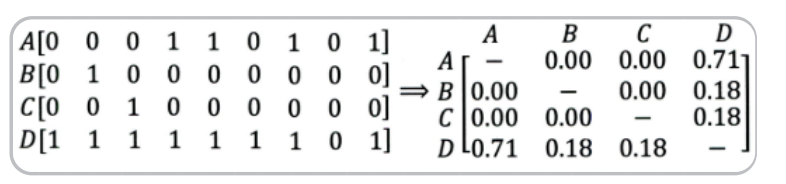
A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。 但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。 所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向 量的能力弱。
User
什么时候使用UserCF,什么时候使用ItemCF?为什么?
-
UserCF
由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于用户少, 物品多, 时效性较强的场合, 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。对于用户较少, 要求时效性较强的场合, 就可以考虑UserCF。
-
ItemCF
这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合, 比如推荐艺术品, 音乐, 电影。
协同过滤的缺陷
-
较差的稀疏向量处理能力。即系统无法将两个物品相似的信息推广到其他物品的相似性上 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。具体参考本节的协同过滤算法的问题分析。此缺点可以通过矩阵分解技术,使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
-
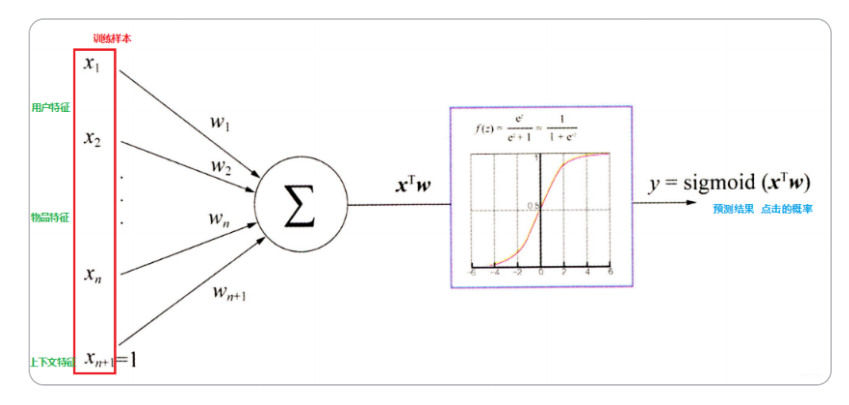
完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息。如:用户年龄, 性别,商品描述,商品分类,当
前时间,地点等一系列用户特征、物品特征和上下文特征。造成信息遗漏。此问题可以使用逻辑回归算法将属性特征进行embeding之后再输入到sigmoid中进行解决,如下图。