
- 1Spring源码分析-BeanDefinition_spring源码系列之beandefinition
- 2Mac 解决配置 zsh 后,nvm不见的问题
- 3苹果微信分身双开怎么弄?2024最新苹果微信分身下载教程!
- 4AI代码生成助手Cursor、TabNine 、Cosy使用体验_cursor是基于chargbt的吗
- 5四、Hybrid_astar.py文件中Hybrid A * 算法程序的详细介绍
- 6微信小程序电子签名及图片生成_电子签名小程序
- 7腾讯云认证FAQ | 热门考试方向、考试报名流程、模拟试题等_腾讯云运维工程师认证
- 8Sublime text3 Version 3.22下载安装及注册_sublime 322 注册
- 9详解Python对Excel处理_python能处理xls文件吗
- 10《Flink原理、实战与性能优化》(Flink知识梳理一)
新一代状态空间模型网络替代Transformer 综述_vmrnn时空预测
赞
踩
本文首先初步介绍了状态空间模型(SSM)的工作原理。然后,从多个方面回顾SSM的相关工作,包括SSM的起源和变化、自然语言处理、计算机视觉、图、多模态处理、多模态和多媒体、点云/事件流数据、时间序列数据等领域的相关工作。
此外,作者在多个下游任务中进行了广泛的实验,以验证SSM的有效性。下游的任务包括单/多标签分类、视觉目标跟踪、像素级分割、图像到文本的生成和人/车辆的重识别。最后,提出了SSM的在理论和应用上的一些可能的研究方向,并对本文作出了总结。
论文:https://arxiv.org/abs/2404.09516
作者单位:安徽大学、哈尔滨工业大学、北京大学
更多相关工作将在以下GitHub上不断更新
https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List
- 1
- 2
- 3
- 4
- 5
论文列表:
技术原理
状态空间模型(SSM)起源于经典卡尔曼滤波
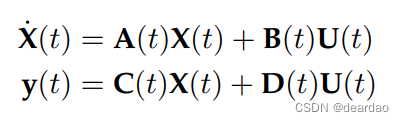
采用[零阶保持器(ZOH)](https://en.wikipedia.org/wiki/Zero-order hold)进行离散化,得到
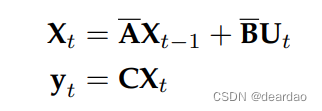
然而,与RNN模型类似,我们面临着计算不能并行化的困境。通过简单地展开上面的公式,我们有
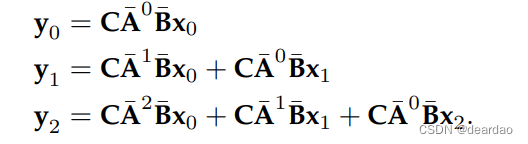
写成卷积的形式:
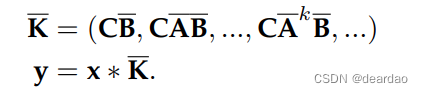
状态空间模型是用一组一阶微分方程(连续时间系统)或差分方程描述动态系统行为的数学模型
(离散时间系统)来表示系统内部状态的演化,而另一组方程来描述状态与系统输出之间的关系。
这些方程可以用矩阵和向量的形式来表示,以处理多变量系统。随后,Gu等人[34]引入了线性状态空间层
(LSSL),它结合了循环神经网络(rnn)、时间卷积网络和神经微分方程(NDEs)的优点,同时解决了它们在模型能力和计算效率方面的缺点。
这种新的序列模型受到控制系统的启发,并通过线性状态空间层(LSSL)实现。
与rnn类似,SSM在建模较长的序列时也会遇到梯度消失/爆炸的问题。为了解决这个问题,HiPPO[36]模型结合了递归记忆和最优多项式投影的概念,可以显著提高递归记忆的性能,这种机制对于SSM处理长序列和长期依赖关系非常有帮助
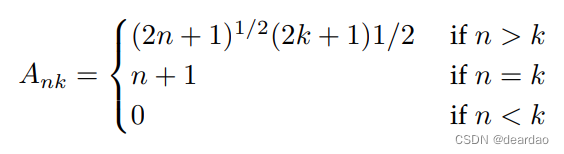
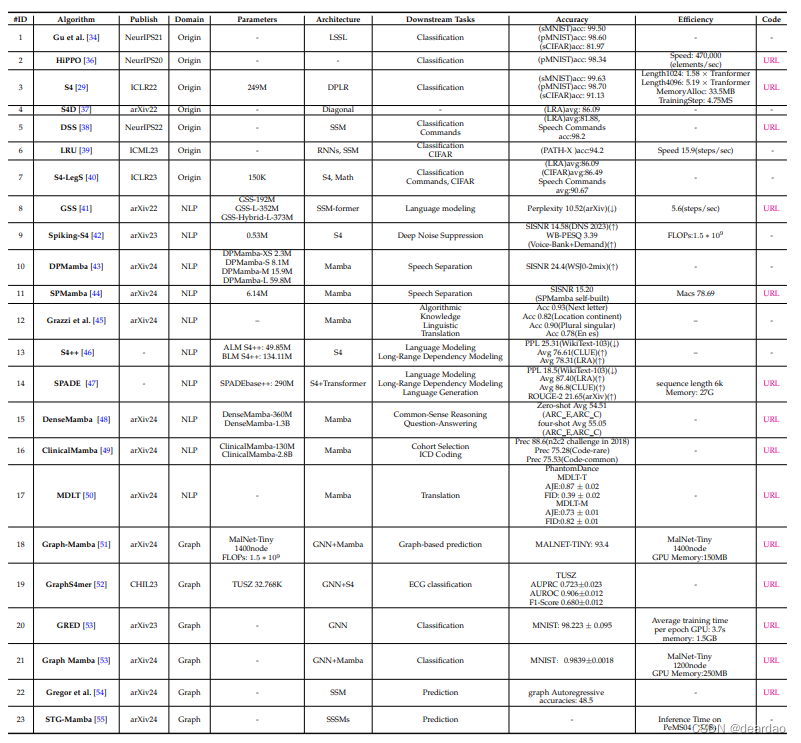
基于上述理论基础,Gu等[29]提出了结构化状态空间序列模型(S4),这是一种基于vanilla状态空间模型(SSM)的新的参数化方法。此外,Gu等人[40]引入了一种新的方法来训练状态空间模型,以捕获序列中的远程依赖关系,特别是通过结构化状态空间序列模型展示。通过设计HiPPO框架的广义解释,并采用各种基函数,如勒让德多项式和傅立叶变换,该研究显著提高了S4的性能,揭示了其理论基础和在机器学习任务中的实际应用。
Gu等人[122]也探讨了如何参数化和初始化对角状态空间模型(Diagonal State Space Models, DSSM),并系统地研究了如何参数化和初始化这些对角状态空间模型,证明了初始化对性能的重要性。此外,Gupta等人[38]提出了结构化状态空间(S4)模型的一个令人信服的替代方案,该模型进一步证明,即使没有低秩修正,对角线状态空间也可以获得相当的性能。对角状态空间(DSS)模型提供了简单的制定和实现,同时保持了捕获各种模式之间的远程依赖关系的有效性,使其成为机器学习任务中实际应用的有前途的途径。
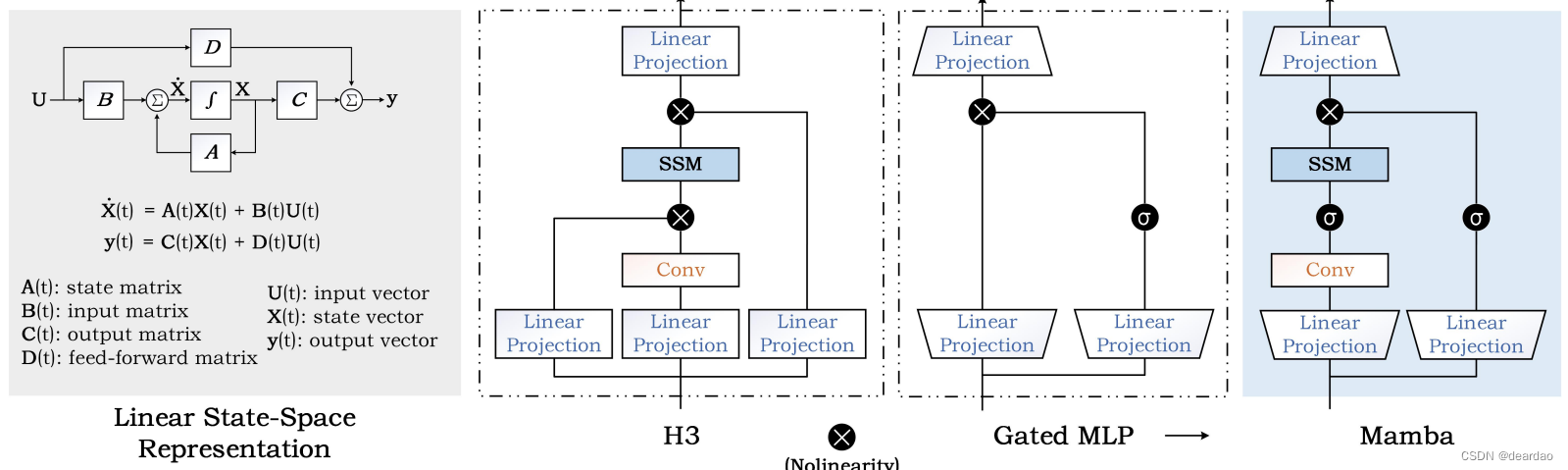
Mamba[12]是通过将以前的SSM架构设计与Transformer的MLP块相结合来简化架构来实现的。Mamba在结构化状态空间模型中引入了一种选择机制。除了这些模型之外,一些作品也可以被视为SSM,如RWKV[125]、Vision-RWKV、RetNet [127], Mega [128], H3 [129].
NLP
对于语言建模任务,[41]主要研究了门控状态空间在远程语言建模方向上的应用,并引入了一种新的方法GSS (gated state Space)。它可以用于长序列建模,有效地减少了参与者的数量。他们的实验表明,它比DSS快2-3倍[38]。Grazzi等人[45]利用曼巴在简单函数估计和自然语言处理的上下文学习任务中,验证了整体性能确实优于S4版本和比较。
S4++[46]发现了S4架构的两个问题,即非平稳状态(non-stationary state, NSS)和依赖偏差(dependency bias),提出了状态记忆回复(state Memory Reply, SMR)机制,将多状态信息整合到当前状态。他们还通过交互式交叉注意机制集成了复杂的依赖偏差,大量的实验结果表明,S4++在多个序列建模任务上优于S4,显示出显著的性能提升。
[47]综合状态空间模型和局部注意机制,减少内存消耗。首先利用局部注意力提取局部信息,然后利用状态空间模型提取局部注意力缺失的全局信息。[48]认为现有的状态空间模型虽然有效,但缺乏性能。作者认为,造成这种情况的原因是太多的状态转换使模型失去了浅层信息。因此,作者提出了一种设计,将前一层的隐藏状态集成到后续层中,以保留更多的浅层信息。最终,在Pile上进行预训练后,Zeroshot和four-shot在其他数据集上的实验结果得到了显著改善。对于语音任务,Du等[42]将脉冲神经网络的高效率和长距离建模的能力与状态空间模型S4结合起来,得到了尖峰神经网络,该网络参数数量少,但在深度噪声抑制任务中性能可与某些人工神经网络(ANN)相媲美。此外,对于语音分离任务,Jiang等人提出的DPMamba[43]使用选择性状态空间模型Mamba取代了传统的变压器架构。DPMamba通过选择性状态空间同时对语音信号的短期和长期前向和后向依赖关系进行建模,其结果可与双路Transformer模型Sepformer相媲美[134]。Li等人提出的SPMamba[44]使用TF-GridNet[135]作为基本框架,用双向Mamba模块代替Transformer模块,以捕获更大范围的语言信息。
在临床笔记理解任务中,Yang等人[49]利用曼巴的线性计算复杂性来模拟非常长的临床笔记序列,序列长度可达16k。作者使用MIMIC-III数据集对曼巴模型进行预训练,然后在队列选择任务和ICD编码任务上进行测试,与曼巴和临床羊驼模型相比,该模型在临床语言建模方面表现优异,特别是在较长的文本长度上。与Mamba和临床Llama模型相比,它在临床语言建模方面表现出卓越的性能,特别是在较长的文本长度上。在翻译任务中,[50]将生成舞蹈编排的问题表述为翻译任务,并提出了MDLT,利用现有数据集学习如何将音频序列翻译成相应的舞蹈姿势。
CV
近年来,状态空间模型的线性时间序列建模受到了广泛关注,在自然语言处理领域显示出强大的性能。受这些进展的启发,许多基于ssm的视觉模型被提出,包括分类任务[30],[57],[60],[61],[68],[76],[83],[92]-[96],[101],[112],[137],[138],检测任务[80],[109],[117],分割任务[70],[71],[82],[85],[89],[91],[106],[108],[111],医疗任务[63],[64],[69],[72],[87],[97]-[100],恢复任务[77],[110],生成任务[31]-[33],视频理解[56],[58],[90],跟踪任务[88],以及其他任务[32],[59],[62],[73],[75],[103],[105],[107],[116],[118],[120],[121]。
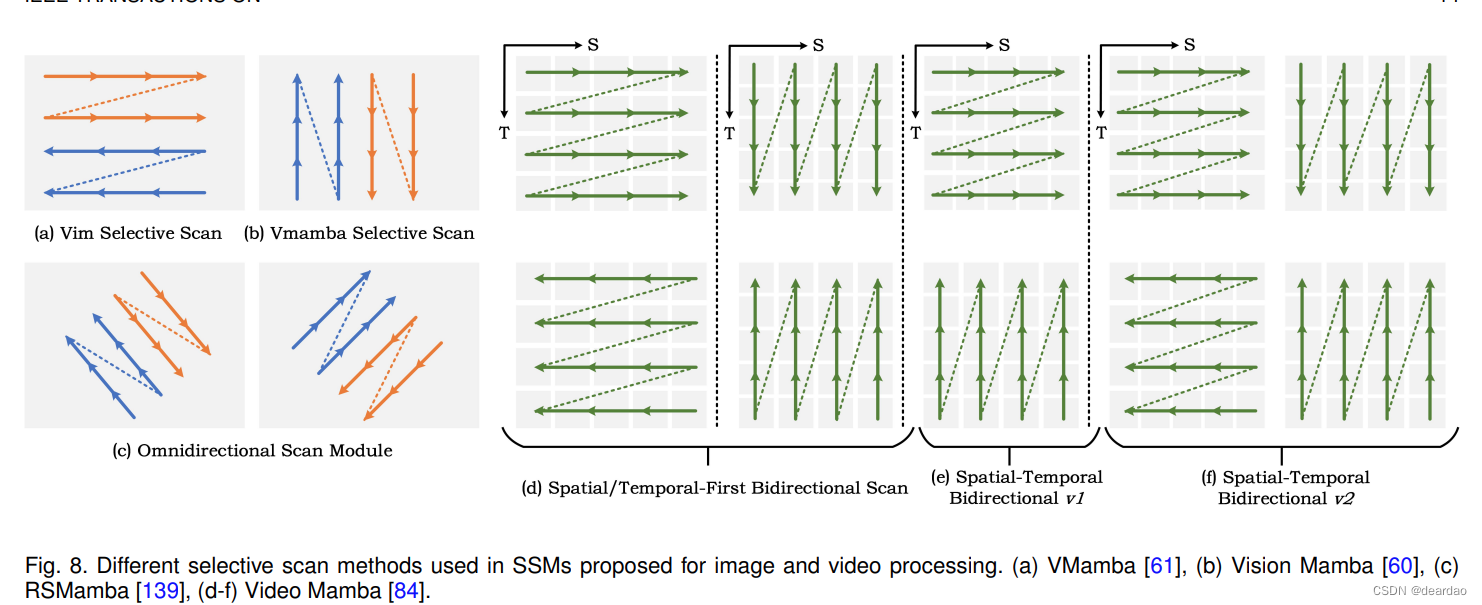
在分类任务中,S4nd[30]提出了多维多极图形组件,扩展了多维数据连续信号的建模能力,可以将大规模视觉数据建模为动态多维线性信号。vamba[60]利用线性复杂性来捕获全方位的感觉场,引入跨扫描块的空间信息遍历 (Why?),并将非因果视觉图像转换为有序的patch序列。Vim[61]使用双向状态空间模型压缩视觉表示信息,通过位置嵌入和视觉信息来理解全局上下文。Li等人提出了Mamba- nd[68],这是Mamba的扩展,旨在通过以行为主的顺序处理跨维度的输入数据来处理任意多维数据。[57]作者在S4的基础上设计S5,建立S5与S4之间的关系,利用多输入多输出SSM,利用并行扫描的状态空间层进行远距离序列建模。Baron等人[76]为空间感应偏置设计了一种新的二维状态空间层。该层的核心目标是实现二维位置感知、动态空间定位以及平移和对齐不变性。Chen等人[79]首次将残差整合到原始vamba中,并保持原始vamba固有的全局和局部状态特征,用于食物分类。
Yang等人[101]提出了PlainMamba,它进一步适应了Mamba的选择性扫描过程。该模型通过连续二维扫描过程提高空间连续性,更新方向感知,通过对方向信息进行编码来区分标签的空间关系,从而增强其从二维图像中学习特征的能力。Wang等提出了用于昆虫分类任务的entomtmamba[112],通过在混合状态空间模块中集成状态空间模型(State Space model)、卷积神经网络(convolutional neural network, CNN)、多头自注意机制(multi-head self-attention mechanism, MSA)和多层感知器(multilayer perceptrons, mlp)来提高模型的分类能力
Huang等人引入了LocalMamba[92],它提出了一种新的局部扫描策略来保持空间令牌的二维依赖性。他们在各种任务上进行了大量的实验,并证明LocalMamba在ImageNet分类上比Vim-T提高了+3.1%。Xu等人[93]介绍了一种名为MambaTalk的SSM模型,该模型专注于手势合成,支持长而多样的序列。Pei等人[94]通过加入额外的卷积分支提出了efficientvamba,并在ImageNet-1K和COCO检测数据集上进一步显著提高了基线。Du等人[95]从多个方面探讨了VMamba的鲁棒性,例如,他们使用全图像和特定补丁的方法研究了对对抗性攻击的弹性,揭示了与Transformer架构相比的卓越鲁棒性,但存在可扩展性弱点。他们还评估了vamba在不同情况下的总体稳健性。
Shi等人[96]提出了一种新的图像恢复方法vammbair,将线性复杂性的状态空间建模引入到综合图像恢复任务中,克服了传统方法的不足。Fang等人[83]提出了mamil框架来解决整个幻灯片图像的分类问题,这是第一个将选择性结构化状态空间模型(Mamba)和多实例学习(MIL)方法相结合的工作。在分类性能和内存使用方面,mamil优于现有的基于Transformer的最先进的MIL框架。Li等人介绍了一种名为HARMamba的可穿戴传感器人体活动识别(HAR)的新方法[137],该方法利用轻量级的选择性状态空间模型(SSM),旨在解决实时移动应用中典型的计算资源限制问题。Yang等人介绍了一种名为HSIMamba的新型高光谱图像分类框架[138],该框架旨在解决遥感高光谱成像数据的复杂性和高维性。所提出的框架结合了双向反向CNN来有效地提取光谱特征,以及用于空间分析的专门块。
检测任务
对于检测任务,Chen等[80]提出了一种Mambain-Mamba (MiM-ISTD)结构来探测红外小目标。在该结构中,将图像均匀划分为“视觉句子”(patch),并进一步细分为“视觉单词”(sub-patch),设计了一种纯基于mamba的MiM金字塔编码器来提取全局和局部特征。Chen等人[109]通过使用视觉曼巴作为能够完全学习全局上下文的编码器,探索了曼巴架构在遥感图像变化检测任务中的潜力。
分割任务
对于分割任务,提出了一种称为Semi-MambaUNet的半监督医学图像分割方法[70],该方法将基于视觉mambaunet架构与传统UNet相结合。它利用双网络生成伪标签,并相互交叉监督。此外,它采用自监督像素级对比学习策略来增强特征学习能力。P-Mamba[71]是为高效儿科超声心动图左心室分割而设计的,它解决了在儿科超声心动图中准确分割左心室的挑战。Liao[89]介绍了LightM-UNet,这是一个简化的框架,合并了Mamba和UNet来解决医学图像分割中的计算限制。它以线性计算复杂度提取深刻的语义特征并捕获广泛的空间依赖关系。对真实世界数据集的实证评估强调了LightM-UNet优于当前领先方法的优势,显示了参数计数和计算开销的大幅减少。Zhang等[91]提出了一种基于SSM的U-Net变体医学图像分割模型VM-UNetV2,该模型充分利用了SSM模型的能力。通过使用vamba预训练权值初始化编码器并采用深度监督机制,VM-UNetV2在多个数据集上展示了具有竞争力的分割性能。U-mamba[63]作为一种通用的CNN- ssm网络,通过整合CNN的局部特征和ssm的远程依赖关系来增强生物医学图像分割。利用基于imagenet的预训练,swan -umamba[64]是一种新的基于Mamba的模型,优于cnn、vit和现有的Mamba模型。结果表明,基于imagenet的预训练在提高mamba家族模型性能方面发挥了重要作用。
VM-UNet[65]建立了一个基线,作为第一个纯粹基于ssm的医学图像分割模型。它在ISIC17、ISIC18和Synapse数据集上有效竞争,为未来基于ssm的分段系统提供了见解。Gong等人[66]提出的nnMamba将cnn的详细特征提取与ssm的广泛依赖建模相结合,在3D医学图像任务中表现出色。提出了基于通道-空间暹罗学习(MICCSS)块的Mamba-In-Convolution模型来模拟体素之间的远程关系。在6个数据集的三维分割、分类和地标检测方面取得了优异的性能。LMa-UNet[85]是一种新型的基于大窗口的曼巴u形网络,与cnn和transformer相比,利用大窗口改进空间建模,在保持线性复杂性的同时保持效率。它引入了一个分层和双向曼巴块,以增强全局和局部空间建模。Tang等[82]使用三态空间融合空间和通道维度的特征,使用残差块提取密集的上下文特征。
Kazi等人[102]利用Mamba-UNet和较轻版本的分层上采样网络(HUNet),将卷积神经网络的局部特征提取能力与状态空间模型的远程依赖建模能力相结合。RS3Mamba[108]提出了一种新的双分支网络RS3Mamba,它将一种新的视觉状态空间(VSS)模型Mamba引入到遥感图像的语义分割任务中。RS3Mamba使用VSS块构建辅助分支,为主分支提供额外的全局信息,并引入协同完成模块(CCM)来增强和融合双编码器的功能。Hao等人[106]介绍了一种称为T-Mamba的牙齿三维CBCT分割方法,该方法通过融合共享位置编码和基于频率的特征,增强了空间位置保存和频域特征增强。T-Mamba是第一个将频率特征引入视觉曼巴架构的作品。Zhu等人[113]提出了一种新的基于Mamba架构的语义分割框架Samba,并专门针对高分辨率遥感图像进行了设计。Samba展示了Mamba架构在遥感图像语义分割方面的有效性和潜力,超越了当前最先进的CNN和基于vit的方法。Ma等人[108]提出了一种名为RS3Mamba的新型双分支网络,该网络利用VSS块构建辅助分支,为基于卷积的主分支提供额外的全局信息。此外,考虑到两个分支之间的特征差异,引入了协作补全模块(CCM)来增强和融合双编码器的特征。Archit等人[119]提出了一种新的医学图像分割网络架构ViM-UNet。它基于最新的视觉曼巴架构,并与传统的UNet和基于变压器的UNETR进行了比较。
恢复任务
对于恢复任务,Guo等人[77]提出了一种新的图像恢复模型,称为MambaIR,旨在探索曼巴在低水平视觉中的潜力,该模型利用了曼巴状态空间模型的远程依赖建模能力,同时结合了图像恢复任务特有的先验知识,如局部块重复和通道交互。Serpent[110]使用状态空间模型来维持一个具有线性缩放输入大小的全局接受域,这大大降低了计算资源和GPU内存的成本。
生成任务
对于生成任务,ZigMa[32]引入了一种基于Mamba结构的新的扩散模型,称为ZigMa,其目标是解决现有扩散模型的可扩展性和二次复杂度问题,特别是在Transformer结构中。DiffuSSM[31]是一种可扩展的状态空间模型,可以处理更高的分辨率,并且可以保留一个详细的图像表示整个扩散过程,因为它不使用全局压缩。DiS[33]是一种基于状态空间架构的新型扩散模型。它旨在训练图像数据的扩散模型,用在原始补丁或潜在空间上操作的状态空间主干取代传统的u - net类主干。
视频理解
对于视频理解,ViS4mer[56]利用多尺度时间结构化状态空间序列解码器进行长期推理。每个解码器层的时空特征分辨率和信道维数逐渐降低,可以学习复杂的远程时空依赖关系。Wang等人提出了LSMCL[58],它是一种长短掩模对比的学习方法,可以预测长程时空信息。Chen等人[90]评估了曼巴在视频理解中作为变形金刚替代品的潜力,探索了曼巴在视频建模中可以扮演的不同角色,并评估了其在不同视频理解任务中的表现。Li等[84]提出了一种基于状态空间模型的视频理解模型VideoMamba,可以有效地处理长视频。
为了保持双摄像头跟踪的一致性,并解决内窥镜尖端外观变化较大的问题,Zhang等[88]提出了一种跨摄像头互模板策略(cross-camera mutual template strategy, CMT),在跟踪过程中引入动态瞬态互模板。提出了一种基于mamba的运动引导预测头(MMH),以最大限度地减少内窥镜尖端光源大面积遮挡造成的干扰和畸变。
在其他任务中,随着越来越多的研究人员认识到曼巴的优势,这种模式已经在各个领域获得了牵引力。泛曼巴[73]代表了首次进军泛锐领域。它包括两个主要模块:通道交换曼巴和跨模态曼巴。通道交换曼巴的目的是融合和增强多样性的特点,从PAN通道和LRMS通道在一个轻量级和高效的方式。后一个模块,跨模态曼巴,部署在通道交换曼巴之后,通过门控机制过滤冗余的模态特征。
DreamerV3 [59]是一种基于世界模型的通用的、可扩展的方法,它克服了各个领域在数据的输入、维度和奖励等方面固定参数范围的限制。对于远程预测,Naman等人[74]引入了一种新的序列建模方法,称为谱态SSM,该方法基于使用谱滤波算法学习线性动态系统(LDS)。这种体系结构保证了稳定和高效的学习,即使对于边缘稳定的对称LDS也是如此。对于强化学习任务,HIEROS[75]是一种分层策略,旨在提高样本效率。HIEROS采用分层世界模型,特别是基于S5层的世界模型(S5WM)和高效的时间平衡采样方法。它在雅达利100k基准上的平均和中位数标准化人类得分方面优于现有方法,并展示了卓越的探索能力。Cheng等人[86]探索了现代状态空间模型Vim如何通过更广泛的激活区域增强卷积神经网络(CNN)和视觉变形器(ViT)在单幅图像超分辨率(SISR)领域的性能。VMRNN[103]是一种新的循环单元,将视觉曼巴块与LSTM相结合,实现精确高效的时空预测。Shen等人[104]介绍了一种基于单视图图像的端到端平摊三维重建模型Gamba。他们的主要发现包括利用大量的三维高斯来提高三维高斯溅射过程的效率。此外,他们还引入了基于mamba的顺序网络,支持上下文相关推理和序列(令牌)长度的线性可扩展性,旨在解决高内存需求和资源密集型渲染过程。Wang等人[105]介绍了一种新的基于mamba的视觉框架,称为VMambaMorph,它具有用于可变形3D图像配准的交叉扫描模块。Li等人[107]提出了一种名为SpikeMba的新方法来处理时间视频定位任务。SpikeMba集成了脉冲神经网络和状态空间模型(ssm),以有效捕获多模态特征之间的细粒度关系。邹等[116]提出了一种基于曼巴的新型远程光电容积脉搏波(rPPG)信号检测方法,称为RhythmMamba。RhythmMamba是一种端到端方法,采用多时间约束来捕获rPPG的周期性模式和短期趋势。此外,它利用频域前馈来增强Mamba稳健地解释准周期rPPG模式的能力。
图
除了标准的网格数据(如图像)外,结构化图数据在人工智能中也得到了广泛的研究,如社交网络和蛋白质结构数据。因为它的输入类型是顺序数据,所以我们可以应用ssm来处理图结构的数据。具体来说,GraphS4mer[52]利用结构化状态空间(S4)架构来捕获长期的时间依赖性,并引入图结构学习层来动态演化图结构,以适应数据随时间的空间相关性。gmn[53]是一类新的图神经网络(gnn)。该框架引入了一个连接节点级和子图级标记化的图标记过程,促进了图结构的高效学习。另一个并行工作图-Mamba[51]也是基于Mamba架构开发的。GraphMamba包含一个节点优先级技术,用于对重要节点进行优先级排序,以便更多地访问上下文,并使用基于排列的训练配方来最小化与序列相关的偏差。Ali Behrouz等人提出了GRED[53],这是一种新的图表示学习架构,对于给定的目标节点,它根据与目标的最短距离聚合其他节点。他们采用线性RNN对跳跃表示序列进行编码。Gregor等人[140]讨论了教师通过强制培训无法准确学习下一个令牌预测器的问题,并通过最简单的规划任务证明了Transformer和Mamba架构在多令牌预测训练中的失败。Li等人[55]引入了STG曼巴,这是第一次尝试使用强大的选择性状态空间模型来处理STG学习。
多模态
状态空间模型也可以适用于多模式/多媒体任务。具体而言,S4ND[30]将状态空间模型(State Space Models, ssm)扩展到多维信号,从而能够将大规模视觉数据建模为连续的多维信号。该方法已被证明在不同的维度(1D, 2D和3D)上是有效的,包括图像和视频分类的应用。Grazzi等人[45]评估Mamba具有与Transformer类似的情境学习(in-context learning, ICL)能力。分析表明,与Transformer一样,Mamba似乎通过逐步改进其内部表示(如迭代优化策略)来解决ICL问题。对于涉及较长输入序列的ICL任务,Mamba可以是Transformer的有效替代方案。Park等人[141]也评估了Mamba的表现,他们的结果表明,Mamba在标准回归ICL任务中的表现与Transformer相当。它在稀疏奇偶学习任务中表现较好。然而,它在涉及非标准检索功能的任务上表现不佳。MambaFormer[141]由Mamba和注意力块组成,用于解决上述挑战,在每个任务中都优于任何单一模型。Zucchet等人[142]揭示了RNN和Transformer之间更紧密的概念关系。实验结果证明,RNN和Transformer并不是完全排斥的模型。研究还表明,通过学习具有乘法交互的门通rnn,可以在理论和实践中实现线性自注意,从而弥合这两种架构之间的差距。Ali等人[143]探索了Mamba模型的学习机制,特别是如何捕获依赖关系以及它们与其他已建立的层(如RNN、CNN或注意力机制)的相似性。曼巴和自我注意层之间建立了一个重要的关系。阐明了曼巴模型的基本性质,表明它们依赖于隐式注意,通过一个独特的数据控制来实现线性算子,表明选择状态空间层是一个注意模型。利用所获得的注意矩阵,提出了一套基于这些隐注意矩阵的可解释性技术。MambaMIL[144]将Mamba框架集成到MIL中,以SR-Mamba为核心组件,擅长捕获分散的正实例之间的远程依赖关系。MambaMIL可以有效地捕获更多的判别特征,并减轻与过拟合和高计算开销相关的挑战,标志着Mamba框架在计算病理学中的首次应用。
运动曼巴[88]由分层时间曼巴(Hierarchical Temporal manba, HTM)和双向空间曼巴(Bidirectional Spatial manba, BSM)组成,是曼巴模型在运动生成领域的首次整合。HTM和BSM分别用于时间和空间建模,同时将选择性扫描机制集成到运动生成任务中。与之前基于扩散的运动相比,它主要使用变压器,运动曼巴实现了最先进的(SOTA)性能。请注意,推理速度也提高了四倍。VL-Mamba[145]是探索状态空间模型Mamba以解决多模态学习任务中Transformer架构中昂贵的计算开销的第一个努力。CMViM[146]专注于将多模态表示学习应用于3D高分辨率医学图像,特别是阿尔茨海默病(AD)。它基于MAE[150]框架开发,用Vim[61]模块代替了ViT[151]模块,从而将复杂度从二次级降低到线性级。此外,本文还引入了模态内和模态间的对比学习方法,以增强多模态Vim编码器对相同模态中判别特征的建模能力,并减轻模态间的不一致表征。Cobra[147]探索了语言模型与线性计算复杂性的结合。
时间序列
由于SSM是一种序列模型,采用SSM来处理多变量时间序列数据是非常直观和有效的[180],[184],[185]。具体来说,长期时间序列预测(LTSF)任务的主要挑战在于难以捕获长期依赖关系和较差的线性可扩展性。TimeMachine[180]通过引入一种方法来解决这些问题,该方法利用Mamba来捕获多变量时间序列数据中的长期依赖关系。timemmachine利用集成的架构与多个Mamba模块,有效地解决了与通道混合和通道独立性相关的挑战。这种方法可以选择性地预测不同尺度的全局和局部上下文信息。实验验证表明,timemmachine在保持良好可扩展性的同时显著提高了精度。

