
热门标签
热门文章
- 1Linux基础命令- echo_echo替换文件内容
- 2Vue中 ,vue-resource 设置请求超时(timeout)后,做出对应响应_vue-resource.esm.超时
- 3csdn专用必杀技----谷歌浏览器插件_csdn谷歌插件
- 4SASS的介绍和应用示例入门_sass应用实例
- 5天池龙珠SQL训练营日常 task3 打卡_10-1 创建视图,包含拥有属性值个数大于1的商品信息 分数 10 作者 冰冰 单位 广东
- 6前端进阶 | 如何写好JS(含实例+完整代码)_前端代码编写方法
- 7JSON parse error: Cannot deserialize value of type `java.time.LocalDateTime` from String异常的正确处理方法,嘿嘿
- 8测试老鸟6年面试心得:四种公司、四种问题_陕六建入职测评过不了
- 9js如何实现整除_auto js 怎么表示整除
- 10面试题收集(五)_一万个人抢 100 个红包,如何实现(不用队列),如何保证 2 个人不能抢 到同一个红包,
当前位置: article > 正文
NLP-预训练模型-2019-NLU+NLG:T5【Transfer Text-to-Text Transformer】【将所有NLP任务都转化成Text-to-Text任务】【 翻译、文本摘要..】_exploring the limits of transfer learning with a u
作者:Monodyee | 2024-05-26 08:43:55
赞
踩
exploring the limits of transfer learning with a unified text-to-text transf
《原始论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
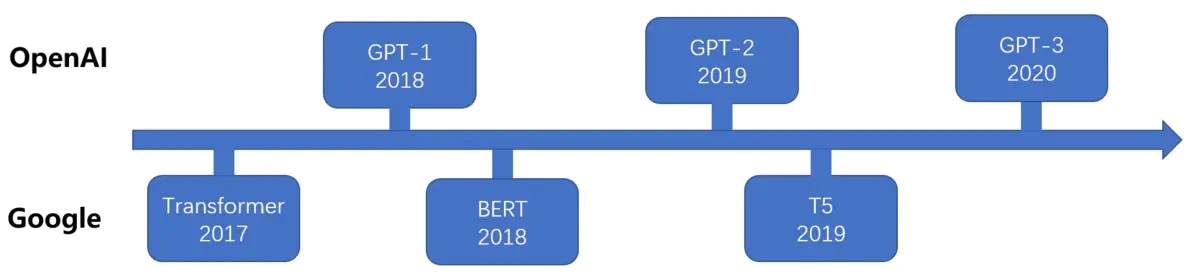
2019年10月,Google 在《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》这篇论文中提出了一个最新的预训练模型 T5(Text-To-Text Transfer Transformer),其参数量达到了 110 亿,完爆 Bert Large 模型,且在多项 NLP 任务中达到 SOTA 性能。有人说,这是一种将探索迁移学习能力边界的模型。
当然,最大的冲击还是财大气粗,bigger and bigger,但翻完它长达 34 页的论文,发现其中的分析无疑是诚意满满(都是钱)。类似这样的大型实验探索论文也有一些,首先提出一个通用框架,接着进行了各种比对实验,获得一套建议参数,最后得到一个很强的 baseline。而我们之后做这方面实验就能参考它的一套参数。
对于 T5 这篇论文,Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,无疑也是类似的论文。它的意义不在烧了多少钱,也不在屠了多少榜(砸钱就能砸出来),其中 idea 创新也不大,它最重
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/626028
推荐阅读
相关标签

