
- 1哈工大2021算法设计与分析期末试题_2021 秋哈工大算法设计与分析期末考试题(回忆版)
- 2一文详解扩散模型:DDPM_扩散模型ddpm
- 3Could not create tunnel: { Error: ngrok is not yet ready to start tunnels_could not create tunnel: error: ngrok is not yet r
- 4Java代码审计安全篇-XXE(XML外部实体注入)漏洞_java 处理xml时禁止引用外部实体
- 5xctf web之 command_execution
- 6考研复试 算法设计&数据结构_与确定性相对应的算法
- 7多示例学习(Multi-Instance Learning)_多实例学习
- 8v-md-editor和SSE实现ChatGPT的打字机式输出
- 9【AI绘画】Stable Diffusion中级教程03——局部重绘(利用SD进行换脸)_sd 区域重绘
- 10Poe 为 AI 机器人创建者引入了按消息定价的收入模式_poe forefront ai
T5:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(万字长文略解T5)
赞
踩
目录
Comparing Different Model Structures
Disparate High-level Approaches
Simplifying the Bert Objective
论文
T5![]() https://arxiv.org/pdf/1910.10683.pdf
https://arxiv.org/pdf/1910.10683.pdf
哈佛复现的Transformer代码:
The Annotated Transformer (harvard.edu)![]() http://nlp.seas.harvard.edu/2018/04/03/attention.html
http://nlp.seas.harvard.edu/2018/04/03/attention.html
Abstract
迁移学习就是模型先在一个数据丰富的任务上进行预训练,然后再在下游任务上进行微调。最近迁移学习在NLP中是一个很有力的技术。在本文中,我们通过介绍一个将基于文本的问题转换成文本到文本的统一框架,从而开发迁移学习在NLP中的应用。
Introduction
进行预训练是为了让模型获取通用的知识使得模型“理解”文本,从而使得在下游任务中表现得更好。我们收到统一框架的影响,例如QA、LM、span extraction等方法的影响,将每个文本处理问题作为一个“文本-文本”的任务,将文本作为输入然后产生新的文本作为输出,如下图所示。
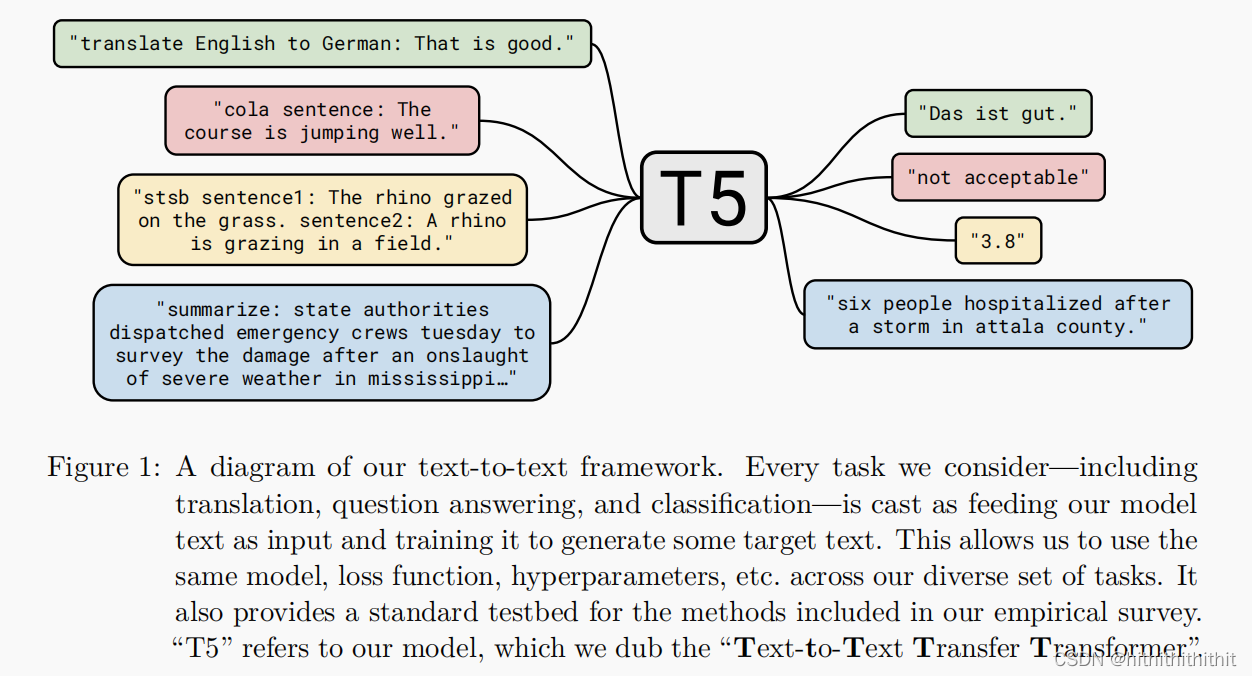
Setup
语料:Colossal Clean Crawled Corpus(C4)
Model
Transformer是一个seq2seq的结构,输入由序列的token映射成embedding组成,然后放入到encoder里面,encoder由自注意力和前馈网络两个模块堆叠而成。下图是原始的Transformer架构:
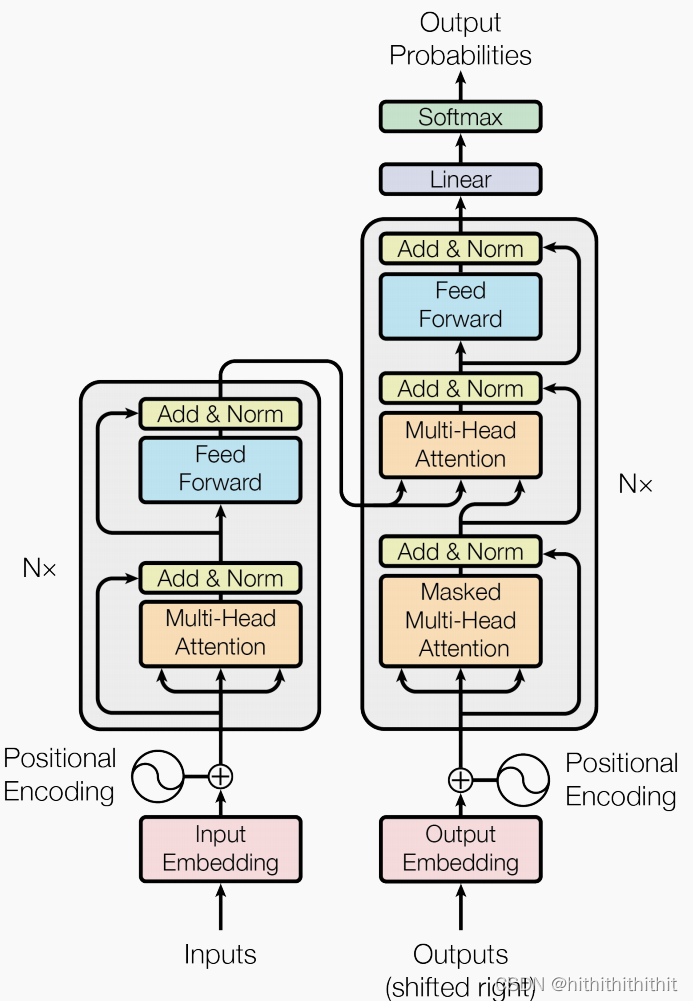
原始Transformer架构详见:[1706.03762] Attention Is All You Need (arxiv.org)
与原始网络架构的区别:
Layer Normalization应用于每个子模块的输出结果。这里使用的layer normalization仅用于缩放,没有偏置,且Layer normalization被应用于每个子模块输入的前面。在layer normalization之后,一个残差跳过连接被用于将每个子模块的输入和输出相加。
其中由于自注意力是顺序无关的,所以位置信息必须显式的表明在网络中,原始的网络中使用了正弦位置或者学习到的位置嵌入,最近开始使用相对的位置嵌入,主要是根据自注意力中比较键和查询之间的偏移量产生不同的嵌入。本文使用了一个简化的position embedding,每个位置嵌入都只是一个标量,它被添加到用于计算注意力权重的相应logit中。为了提高效率,我们还在模型中的所有层中共享位置嵌入参数,尽管在给定的层中,每个注意头使用不同的学习位置嵌入。
综上所述,我们的模型与Vaswani等人(2017)提出的原始变压器大致相同,除了去除层范数偏差,将层归一化放置在残差路径之外,并使用不同的位置嵌入方案。由于这些结构上的变化与我们在迁移学习的实证调查中考虑的实验因素正交,我们将其影响的消融留给了未来的工作。
Corpus
使用了Common Crwal中的公共的可获取的文本。由于获取到的数据中很大一部分不是文本,所以作者使用了以下的方法来清理网络提取文本:
1、只保留以终端标点符号结尾的行;2、丢弃了少于5个句子的页面,句子中至少包含3个单词;3、删除了Bad Words;4、 删除了带有JS警告的文本;5、删除了所有待占位符的界面;6、删除了带有{}括号的界面;7、为了去重,删除了数据集中所有连续三句出现一样的文本。
我们使用启发式的方法来过滤不是英文的文本,其中使用langdetect · PyPI来检测,要求为英文文本的概率至少为0.99。最终获得了一个750GB的数据集,包含合理的干净和自然的英语文本。
DownStream Tasks
本文的目标是为了测量通用的语言学习能力,总共研究了在以下benchmark中的表现:机器翻译,问答,摘要总结,文本分类。具体来说,我们测量了GLUE和SuperGLUE文本分类基准的性能;CNN/Daily Mail 摘要总结;广泛回答问题;以及WMT英语到德语、法语和罗马尼亚语的翻译。

Input and Output Format
为了在一个模型上训练不同的任务,我们使用了“文本-文本”的格式,一个任务模型是由条件式的用于“输入文本-输出文本”的生成。这种框架为预训练和微调提供了连续的训练目标。具体来说,就是使用了最大似然目标(teacher forcing )来进行训练而不管任务类型。为了让模型认识不同的任务,我们使用了文本前缀来标明不同类型任务输入。
例如在翻译任务中,需要让模型将“That is good.”翻译成德语,那么输出样例为:“translate English to German:That is good. ”
在文本分类任务中:推断一个假设中是否由蕴含、矛盾、中立三种关系。那么输入为“mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are fifilled with animosity.”和对应的目标词“entailment”。如果模型输出了除这三种关系意以外的标签,那么我们会判定模型的输出是错误的。
由于任务的描述(文本的前缀)的选择本质上是一个超参数,本文作者发现改变前缀文本对模型性能的提升是有限的(有没有可能是模型比较大?小模型相比大模型会有提升吧?),所以文本并没有基于不同的前缀进行广泛的实验。例如下图就是超参数的展示,详细的前缀文本请看原文的附录D部分,下图包含WMT English to German的任务前缀。

本文训练的模型专注于迁移学习而不是零样本学习,相比于span extraction的训练方式,我们还可以进行生成任务。对于一个相似度计算的任务(打分),我们将其转换为一个分类任务,使用数字间隔来表示不同的类别,比如1-5的相似度分数,被以0.2为间隔一共分成了21个类,如果在测试时模型的输出不在1-5之间,那么会被认为模型预测出错。
Experiments
NLP中最近在迁移学习方面的进步来自新的预训练目标、模型结构、未标注数据集等的发展。在本节中,我们对这些技术进行了实证调查,希望能梳理出它们的贡献和意义。然后,我们将结合所获得的见解,以便在我们所考虑的许多任务中获得最先进的水平。由于NLP的迁移学习是一个快速发展的研究领域,因此我们在实证研究中不可能涵盖所有可能的技术或想法。为了获得更广泛的文献综述,我们推荐Ruder等人(2019年)最近的一项调查。
下面将从基线设置方式、模型架构、无监督目标、预训练数据集、迁移方法、和缩放等几个方面进行经验的比较。
Baseline
基线的目标是反应典型的现代实践。我们使用去噪的目标去标准的Transformer架构进行预训练,然后分别对每个下游任务进行微调。
Model
我们发现使用标准的encoder-decoder结构可以在分类任务和生成任务上实现很好的性能。我们探索了不同的模型结构的性能。模型的encoder和decoder使用了和Bert-base相似的尺寸,encoder和decoder包含了12个堆叠块,前馈神经网络的输出层维度为3072,最终模型的参数有220million个,大约是Bert-base的两倍。自注意力共有12个头,每个头维度为64,隐藏层维度为768,使用了0.1的dropout。
BERT-base详见论文:[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
Training
如前面所述,所有任务都被表述为从文本到文本的任务。这使得我们总是使用标准的最大似然进行训练,即使用教师强迫和交叉熵损失。对于优化,我们使用AdaFactor。在测试时,我们使用贪婪解码(即在每个时间步长上选择最高概率的logit)。
AdaFactor优化器概念详见:AdaFactor优化器浅析(附开源实现) - 科学空间|Scientific Spaces
我们使用哦最大序列长度512和128的batch_size,那么每次模型可获得个tokens。我们在C4上一共进行了
步预训练。整个模型一共预训练了
个tokens。这远比BERT(137B)和RoBERT(2.2T)少。我们预训练的token数量获得了一个合理的计算消耗,但是仍然需要提供足够的预训练以获得可接受的性能。
个token仅仅占了C4语料的一部分,所以我们在预训练的时候不会重复训练数据。
我们还使用了“inverse square root”的学习率调度,其中n表示当前训练的迭代次数,k是warm-up步骤的数量(在实验中设为10000)。对于前10000个步骤中学习率设为0.01。然后以指数的方式衰减学习率,直到训练前结束。其中在已知训练步骤的情况下使用三角函数的效果会好一点,但是为了通用性还是使用了前面提到的学习率调度方法。
为了权衡低资源和高资源任务,我们的模型对所有的任务都进行了步微调,在微调中使用了长度为512,batch_size为128的输入。我们使用了0.001的恒定学习率。每5000步保存一个检查点然后比较性能,同时为每个任务独立的选择最佳检查点。
Vocabulary
我们使用SentencePiece对文本进行切割得到的token用于wordpiece。由于我们最终将英语模型调整为德语、法语和罗马尼亚语的翻译,因此我们还要求我们的词汇必须涵盖这些非英语语言。为了解决这个问题,我们将C4中使用的页面分为德语、法语和罗马尼亚语。然后,我们在10 part的英语C4数据上训练我们的句子片段模型,其中1 part数据分为德语、法语和罗马尼亚语。这个词汇表在我们的模型的输入和输出中都被共享了。请注意,我们的词汇表使我们的模型只能处理一组预先确定的、固定的语言集。
SentencePiece 与 WordPiece的概念详见:wordpiece和sentencepiece - 知乎 (zhihu.com)
Unsupervised Objective

Baseline Performance
在本节中,我们将使用上面描述的基线实验程序来展示结果,以了解我们在下游任务中取得什么样的性能。理论上,我们应该在一个任务上重复多次实验去获得一个置信区间。但是,这种做法十分昂贵,因为我们需要运行大量实验。作为代替,我们从头开始训练极限模型10次(采用不同的随机初始化和打乱数据集),假设基线模型的这些运行上的方差也适用于每个实验变量。我们不期望我们所做的大多数变化会对运行间的方差产生显著的影响,所以这应该提供一个关于不同变化的重要性的合理指示。另外,我们还测量了在没有预先训练的情况下,对所有下游任务进行 步(我们用于微调的相同数字)训练模型的性能。这让我们了解了预训练在基线设置中给模型带来的好处。以下是部分实验结果:
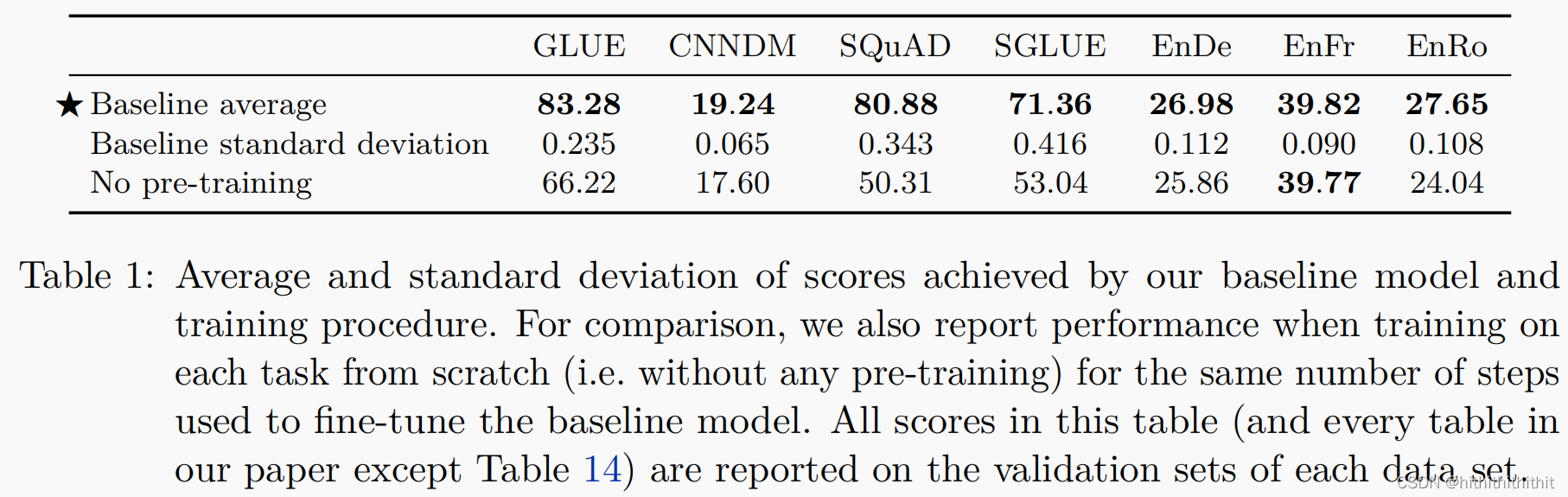
当在正文中报告结果时,我们只报告所有基准测试分数的子集,以节省空间和便于解释。对于GLUE和SuperGLUE,我们在“GLUE”和“SGLUE”的标题下报告所有子任务(根据官方基准测试的规定)的平均分数。对于翻译任务,使用BLUE作为评测标准,使用exp平滑和intl。对于摘要任务(CNN/Daily),使用ROUGE-1-F,ROUGE-2-F,ROUGE-L-F作为评测标准,上图仅使用ROUGE-2-F,SQuAD使用F1值作为评判标准。
Architecture
虽然变压器最初是通过编码器-解码器架构引入的,但许多关于NLP迁移学习的现代工作都使用了替代架构。在本节中,我们将回顾和比较这些架构变体。
Model Structures
不同架构的主要区别在于不同的注意力机制使用的“mask”。输出序列的每个条目都是通过计算输入序列的条目的加权平均值而产生的。例如,表示输出中的第i个元素,
表示输入序列中的第j个元素。
,其中
是由自注意力机制作为
和
的函数产生的缩放权重。然后,注意掩模被用来消除特定的权重,以限制在给定的输出时间步长可以注意输入的条目。由下图可知,因果掩码将
设置为0,如果
。

在本文中,我们首先考虑了一个encoder-decoder结构的模型,下图最左边的图表示这种架构。其中编码器部分使用了一个fully-visible的注意力矩阵,解码器中使用了一个因果掩蔽模式,当产生输出序列的第i个token时,因果掩蔽阻止模型关注输入序列的第j个token,因此模型在产生输出时不能看见未来。

在文本到文本的设置中使用语言模型的一个基本和经常被引用的缺点是,因果掩蔽迫使模型对输入序列的第i个token的表示只依赖于直到第i个token之前的条目。由于在文本到文本中我们使用了前缀,LM的前缀表示只依赖于前面的单词(也就是前缀当前token的前面token),所以这种表示是不利的,可能会影响到后面生成的结果。在transformer的结构中,这被完全抛弃了,因为我们使用一个编码器来fully-visible 前缀/上下文。这种前缀的Lm和Bert的区别在于,如果我们处理自然语言推断的任务。我们根据前提和假设来生成目标,在Bert中,我们使用分类器[CLS]来对文本进行分类,然后在Prefix LM中我们直接预测目标后面的词的类型为隐含、矛盾、中性等词来对文本进行分类。因此前缀LM和BERT的区别是分类器被集成到前缀LM transformer解码器的输出层中了。
Comparing Different Model Structures
我们对encoder-decoder、encoder-decoder shared、encoder-decoder, 6 layers、Language Model、Prefix LM等几种不同结构的模型进行了比较。对比结果如下图所示,其中P表示参数量,M表示计算代价。我们分别在MLM和LM两个训练目标对语言模型进行了训练。
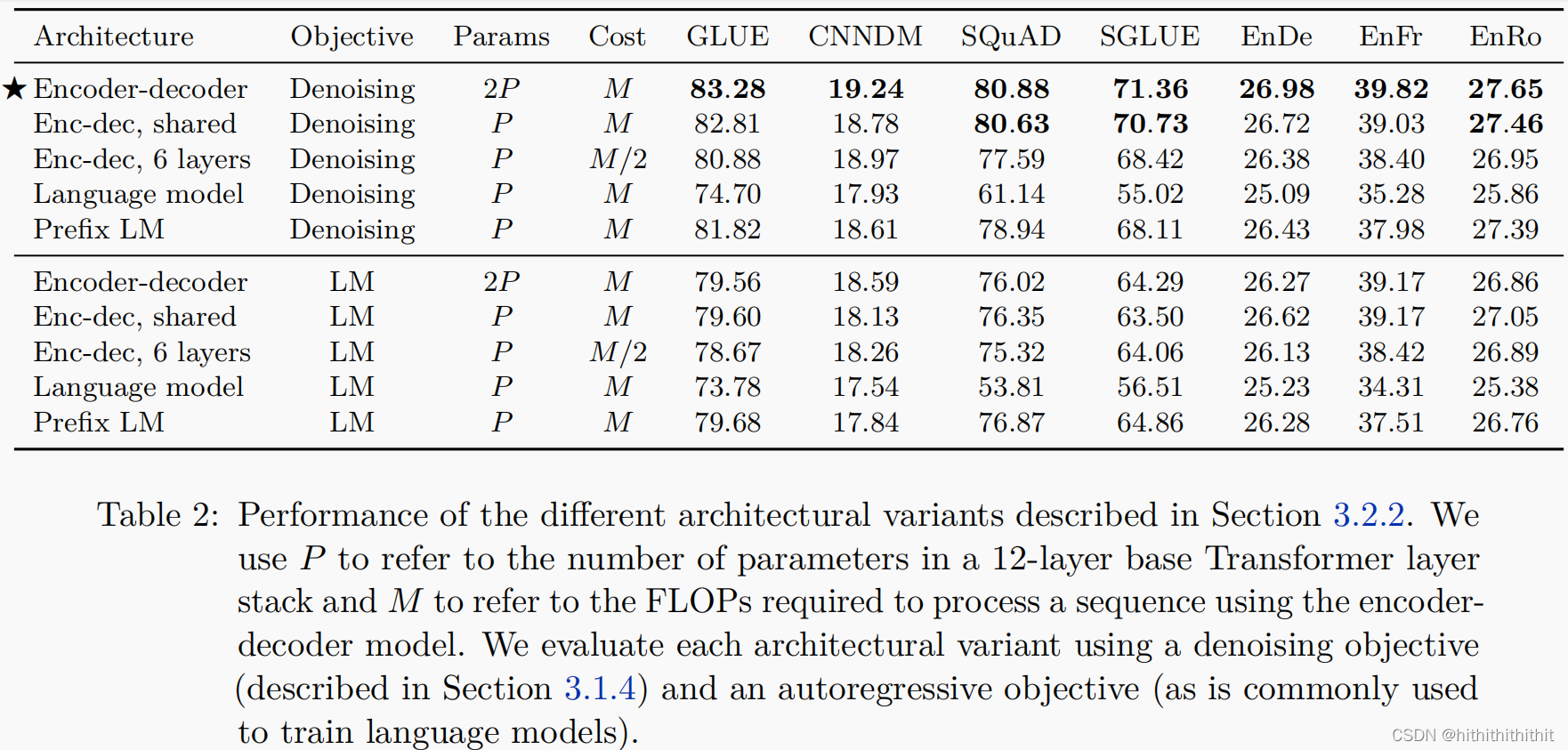
从上图中,我们得出了如下的一系列结论:
1、在所有的任务中,去噪的encoder-decoder架构表现最好;
2、encoder-decoder虽然参数量为2P,但是计算代价和参数量为P的模型一样;
3、共享参数的encoder-decoder几乎和正常的encoder-decoder一样好;
4、相比之下,将编码器和解码器堆栈中的层数减半会显著影响性能;
5、在不同块之间共享参数可以在不牺牲大量性能的情况下降低总参数的有效方法;
6、共享参数编解码器优于解码器前缀LM,这表明显式的编码器-解码器注意是有益的。
7、去噪的训练目标比语言模型目标性能更好;
Unsupervised Objectives
无监督目标的选择是非常重要的,因为它提供了模型获得通用知识以应用于下游任务的机制。
Disparate High-level Approaches
本文比较了三种不同的训练目标:1、LM;2、MLM(BERT-style);3、deshuffling objective:这种方法使用打乱的序列token,对其进行打乱,然后使用原始的标记序列作为目标。具体见下图前三行。

三种训练目标的实验结果如下图所示,MLM取得了最好的效果。

Simplifying the Bert Objective
为了进一步提高预训练阶段的性能,我们根据上面获得的最好的结果,继续在BERT-style的模型上进行改进。我们考虑使用一个简化的BERT-style的训练目标,其中并不包括随机交换token。所得到的目标只是简单地用掩码标记替换输入中15%的标记,并训练模型来重建原始的序列。Song等人(2019年)也使用了类似的掩蔽目标,并将其称为“MASS”,因此我们将这种变体称为“MASS风格”目标。其次,我们很感兴趣的是,看看是否有可能避免预测整个未损坏的文本跨度,因为这需要对解码器中的长序列进行自我注意。我们使用了两种策略来实现:首先,我们使用了唯一的掩码token来替换每个连续损坏的span,而不是使用mask token去代替一个损坏的token。其次,其次,我们还考虑了一个变体,其中我们简单地从输入序列中完全删除破坏的标记,并按照顺序重构删除的标记的模型。具体如上图Table3五六两行。
下图显示了原始bert风格目标与这三个备选方案的实证比较。我们发现,在我们的设置中,所有这些变体的表现都很相似。但是这两种变体不需要完整的原始序列,所有他们在训练的时候目标序列更短、训练速度更快。

Varying the Corruption Rate
我们比较了不同的破坏率对模型性能的影响,具体如下图所示,最终我们认为破坏率的改变对实验性能影响有限。50%的破坏率导致性能有显著地下降,使用更大地破化率会导致目标序列过长,从而降低训练的速度,最后我们还是采取了和BERT一样的15%的破坏率。

Corrupting Spans
现在我们打算通过预测短序列从而加速训练。对于每个token我们使用iid决定是否去进行破坏。当多个连续的token被破坏时,我们使用唯一的单个mask token去代替它。这样我们会获得一个更短的输入序列。由于我们使用iid决策,所有连续大量出现破坏token的情况比较少,所以我们会使用破坏span的方式来加速,预测破坏的span可以加速提高性能。我们使用参数化的目标去破坏15%的token和破坏的span总数。例如,对于500个token的序列,随机的破坏15%的token,也就是75个token,然后破坏25个span,那么被破坏span的平均长度为3。如下图所示,我们使用了2、3、5、10的被破坏的平均span长度。不同长度的被破坏的span性能如下:
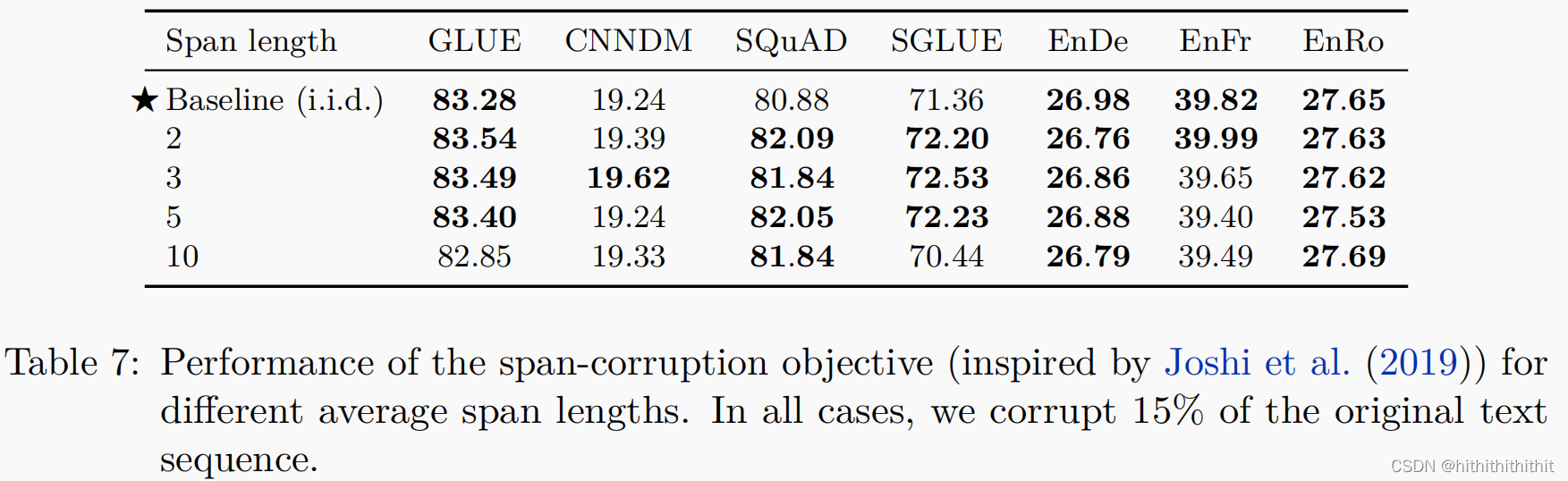
通过上表可以看出,不同长度被破坏span之间的性能差异不大,但是长的span会加速训练的时间。
Disscussion
如下图所示,我们对训练的目标,破坏的策略,破坏率和破坏span的长度进行了一系列比较。

图5显示了我们在探索无监督目标过程中所做选择的流程图。 我们观察到的最明显的改变是去噪的训练目标比语言模型和打乱顺序的方式要好。我们没有观察到一个显著的差异在许多我们探索的变种去噪目标。然而,不同的目标(或目标的参数化)可能导致不同的序列长度,从而导致不同的训练速度。这意味着在我们这里考虑的去噪目标中的选择应该主要根据它们的计算成本来进行。我们的研究结果还表明,对与我们在这里所考虑的目标类似的目标的额外探索可能不会给我们所考虑的任务和模型带来显著的收益。相反,探索完全不同的利用未标记数据的方法可能是偶然的。
Pre-training Data set
和无监督训练目标一样,预训练数据集本身也是迁移学习流程的关键部分。但是新的预训练训练集往往容易被忽视,通常我们在证明一种新方法或者模型的有效性时才会考虑到数据集。因此,对不同训练集的比较相对较少,也缺乏用于预训练的标准训练集。为了更深入研究预训练训练集对性能的影响,在本节中,我们比较累C4训练集的变体和其他潜在的预训练数据源。
Unlabelled data sets
在创建C4的时候,我们使用了不同的启发式方法来从Common Crawl中过滤抽取出来的网络文本。我们感兴趣的是,除了与其他过滤方法和常见的训练前数据集进行比较外,我们还需要测量这种过滤是否会提高下游任务的性能。为此,我们比较了预训练后的基线模型的性能:

Pre-Training Data Set Size
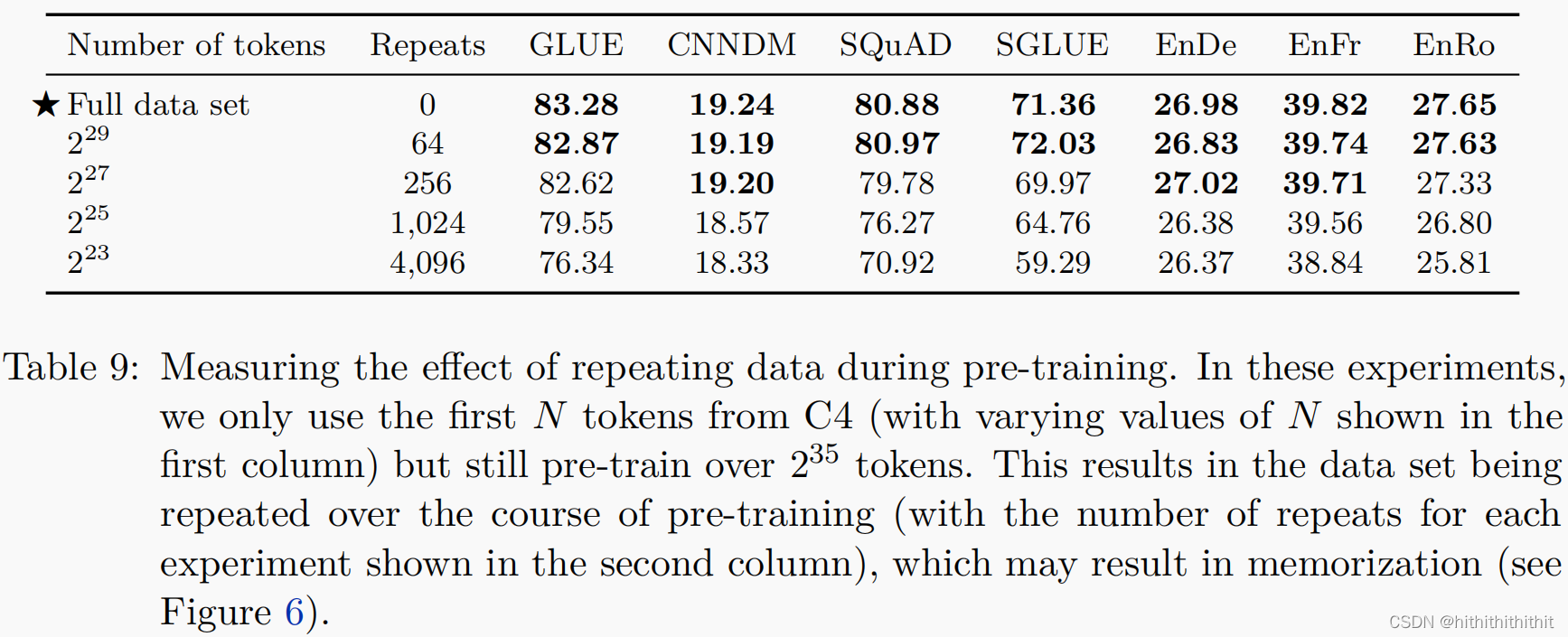
同时,本文还考虑了不同尺寸的数据对性能的影响。
Training Strategy
到目前为止,我们已经考虑了一个设置,即模型的所有参数都在无监督任务上进行预先训练,然后在单个监督任务上进行微调。虽然这种方法很简单,但已经提出了各种训练模型的下游/监督任务的替代方法。在本节中,我们除了在多个任务上同时训练模型的方法外,还比较了微调模型的不同方案。
Fine-tune Methods
文本分类任务的迁移学习结果主张只对分类器的参数进行微调,该分类器被喂入预训练模型产生的句子嵌入。这种方法不太适用于我们的编码器-解码器模型,因为整个解码器必须经过训练来输出给定任务的目标序列。相反,我们将关注两种可选的微调方法,它们只更新我们的编码器-解码器模型的参数的一个子集。
第一个可选的方法是使用adapter learning,在原始的预训练网络中添加一个adapter layer,然后我们只更新adapter的部分参数。具体做法是对Transformer中前缀神经网络后添加一个dense-ReLU-dense块。
第二个可选的方法是“gradual unfreezing”,随着时间的推移,会有越来越多的参数进行更新。采取的策略从末尾的网络块逐渐解冻到整个模型。为了将这种方法适应于我们的编码器-解码器模型,我们从顶部开始逐步开始解冻编码器和解码器中所有的层。由于我们的输入嵌入矩阵和输出分类矩阵的参数是共享的,所以我们在整个微调过程中更新它们。实验结果如下图所示:
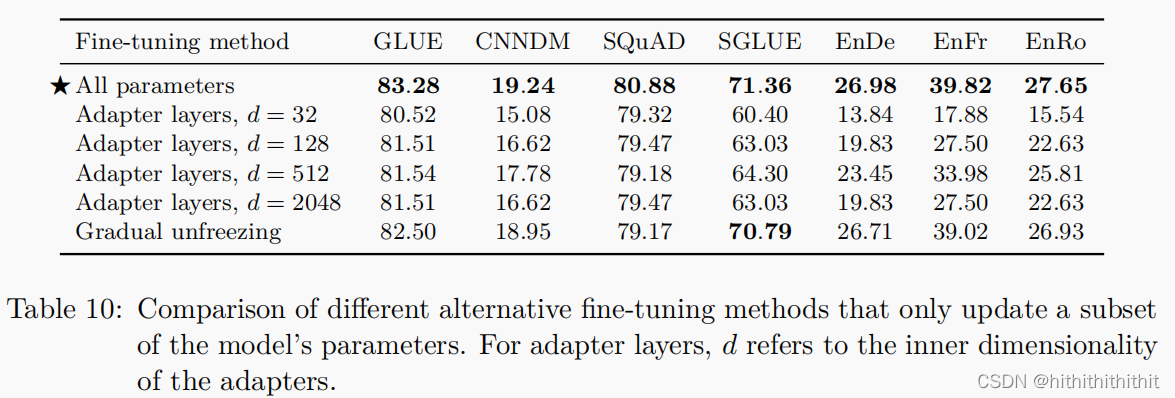
实验结果表明,像SQuAD这样的低资源任务在较小的d值下面工作良好,而高资源任务需要较大的维度才能实现更好的性能。在实验中,虽然逐渐解冻确实加快了训练的速度,但是导致了性能的轻微下降。
Multi-Task Learning
到目前为止,我们已经在一个单一的无监督学习任务上对我们的模型进行了预训练,然后在每个下游任务上单独进行微调。另一种方法,被称为“多任务学习”,一次在多个任务上训练模型。这种方法在每个任务中共享模型的参数,一次训练所有任务。由于我们使用的是统一的生成式框架,多任务学习只是简单的将所有的数据集混在一起。因此,在使用多任务学习时,我们可以通过将无监督任务作为混合在一起的任务之一,仍然可以对未标记数据进行训练。相比之下,多任务学习对NLP的应用增加了特定任务的分类网络或对每个任务使用不同的损失函数。多任务学习的一个重要因素是模型应该从每个任务中训练多少的数据。我们的目标是使模型在每个任务上表现得好,而不是过度训练或者不充分训练,也不是让模型见过多的数据。如何准确地设置来自每个任务的数据的比例可能取决于各种因素,包括数据集的大小、学习任务的“难度”,正则化等等。另一个潜在得因素使“任务推理”或者“消极迁移”,在某一个任务上性能好,可能会影响在其他任务上得性能。
Examples-proportional mixing 模型对给定任务的拟合速度的一个主要因素是数据集的大小。因此,一个常见的做法是设置每个任务数据集的比例。但是,请注意,我们包括了我们的无监督去噪任务,它使用的数据集比其他任务的数据集大几个数量级。由此可见,如果我们简单地按照每个数据集的大小进行抽样,模型看到的绝大多数数据将未标记,并且将在所有监督任务上训练不足。即使没有无监督的任务,某些任务的训练集还是很大,以至于其他任务训练不够。为了解决这个问题,我们在开始计算比例之前设置一个人工的“limit”在数据集的尺寸上面。例如,如果每个任务的例子有个,我们对第m个任务设置采样的概率
,其中K表示人工设置的数据集尺寸限制。K越大,越倾向于全部采样或者等比例采样,K越小越趋向于均等采样。

Scaling
机器学习的“痛苦教训”认为利用额外计算的方法会战胜人类专业知识的方法。最近的研究表明这在NLP的迁移学习中仍然是正确的。也就是说,它已经多次被证明,与更仔细设计的方法相比,扩展可以产生更好的性能。进行扩展的方法包括使用更大的模型,多次训练模型,以及集成模型。在这个部分,我们通过进行4倍于之前的计算性能来比较不同的方法。本实验中,我们使用了更大尺寸的模型, 更多次的训练步数以及更大的batch_size和4个集成的模型。实验结果如下:

Putting It All Together
我们通过系统的研究,从基础模型开始然后做出以下改变:
Objective:我们使用了IID来对span进行破坏。具体来说,我们使用的平均跨度长度为3,并破坏了原始序列的15%。我们发现,这个目标产生了略好的性能,但是由于目标序列长度较短,计算效率略高。
Longer training:我们的模型使用了相对小的预训练计算量。额外的训练对模型的性能确实是有用的,而且增加批处理的大小和增加训练步骤都可以增加性能。使用较小的C4变体进行重复的训练是有害的,数据集也很重要。
Model sizes:更大的模型可以有效的提高性能。在计算资源有限的情况下,使用更小的模型可能会有所帮助。基于这些因素,我们训练了如下尺寸的模型:
| 尺寸 | desc | d_model | d_ff | d_kv | head | layers |
| Base | bert-base(2.2亿) | 768 | 64 | 12 | 12 | |
| Small | 6千万 | 512 | 2048 | 64 | 8 | 6 |
| Large | bert-large(7.7亿) | 1024 | 4096 | 64 | 16 | 24 |
| 3B and 11B(30亿,110亿) | 1024, | 16384,65536 | 128 | 32,128 | 24 |
Coding
- from transformers import T5Tokenizer, T5ForConditionalGeneration
-
- """Training
- T5的训练使用Teacher Forcing,所以其训练时需要两个序列,一个是输入序列一个是目标序列,
- 输入序列以input_ids形式被喂入到模型中,
- 目标序列被转移到右边,也就是说,有一个起始序列的token预先准备,并使用解decoder_input_ids提供给解码器端
- 其中,目标序列使用<EOS>作为终止符,<PAD>作为起始序列的token
- 训练时只有同时拥有输入序列和目标序列才能计算损失,他们在目标序列的前面一个位置加一个开始序列标记
- (config.decoder_start_token_id),T5中是标记0
- """
-
- tokenizer = T5Tokenizer.from_pretrained("../model/t5-small")
- start_sequence_token = tokenizer.decode([0])
- print(start_sequence_token)
-
- """无监督去噪训练
- 在这种方法的设置下,输入序列的span被所谓的sentinel tokens或者unique mask tokens所遮掩
- 目标序列被同样的sentinel tokens和真实的被遮掩的tokens所组成
- 每一个sentinel token代表一个unique mask token,例如<extra_id_0>...<extra_ids_99>,
- T5的词表中只有99个这样的token,例如下面的代码
- """
-
- tokenizer = T5Tokenizer.from_pretrained("../model/t5-small")
- model = T5ForConditionalGeneration.from_pretrained("../model/t5-small")
-
- input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
- labels = tokenizer("<extra_id_0> silly dog <extra_id_1> silly <extra_id_2>", return_tensors="pt").input_ids
-
- # the forward function automatically creates the correct decoder_input_ids
- loss = model(input_ids=input_ids, labels=labels).loss
- print(loss.item())
-
- """监督训练
- 这是最常见的输入和输出句子都给全的例子,例如下面翻译的例子
- """
- tokenizer = T5Tokenizer.from_pretrained("../model/t5-small")
- model = T5ForConditionalGeneration.from_pretrained("../model/t5-small")
-
- input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
- labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
-
- target_tokens = tokenizer.decode([644, 4598, 229, 19250, 5, 1])
- input_tokens = tokenizer.decode([13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1])
- # print(input_tokens)
- # print(target_tokens) # Das Haus ist wunderbar.</s>
- output = model(input_ids=input_ids, labels=labels)
- # print(output)
-
- """
- 由于我们需要批次的将样例输入到模型中,所以我们需要定义一个最大源长度和最大目标长度
- 此外,我们使用attention_mask作为额外的输入去让模型在计算损失的时候忽略<pad>符号,或者使用-100去代替也可达到忽略的目的
- """
- import torch
-
- # tokenizer = T5Tokenizer.from_pretrained("../model/t5-small")
- # model = T5ForConditionalGeneration.from_pretrained("model/t5-small")
-
- # the following 2 hyperparameters are task-specific
- max_source_length = 512
- max_target_length = 128
-
- # Suppose we have the following 2 training examples:
- input_sequence_1 = "Welcome to NYC"
- output_sequence_1 = "Bienvenue à NYC"
-
- input_sequence_2 = "HuggingFace is a company"
- output_sequence_2 = "HuggingFace est une entreprise"
-
- # encode the inputs
- task_prefix = "translate English to French: " # it's important.
- input_sequences = [input_sequence_1, input_sequence_2]
-
- encoding = tokenizer(
- [task_prefix + sequence for sequence in input_sequences],
- padding="longest",
- max_length=max_source_length,
- truncation=True,
- return_tensors="pt",
- )
-
- input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
- print(attention_mask)
- # encode the targets
- target_encoding = tokenizer(
- [output_sequence_1, output_sequence_2], padding="longest", max_length=max_target_length, truncation=True
- )
- labels = target_encoding.input_ids
-
- # replace padding token id's of the labels by -100 so it's ignored by the loss
- labels = torch.tensor(labels)
- print(labels)
- labels[labels == tokenizer.pad_token_id] = -100 # 将<pad>置为0
- print(labels)
- # forward pass
- loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
- print(loss.item())
- """
- 当使用AdamW optimizer时,我们需要比默认设置中略高的学习率
- 1e-4和3e-4是较好的学习率用于大多数问题,特别指出T5预训练用的是AdaFactor optimizer
- 如果在TPU上进行训练最好将数据集中的所有样例pad到一样的长度或者,使用pad_to_multiple_of去预先定义输入尺寸
- TPU 不建议动态填充每个批次样本的最大长度,因为它会导致TPU在训练期间重新编译,从而大大减慢了训练的速度。
- """
-


