
[详细] -->
赞
踩
赞
踩
一张包含人像的照片和一段语音,如何让照片中的人物开口说话?
一段包含人物视频和一段语音,如何给视频配上语音,并使得视频中的人物口型和语音匹配?
如果你遇到以上两种场景,那么本教程或许可以帮到你,目前开源免费的主流嘴音同步AI工具主要有以下几个:
从易用性来讲,上述的提到的这几种嘴型同步工具,都只能通过源码搭建环境去运行使用,还是比较复杂的,有的提供了Stable Diffusion插件,对SD熟悉的小伙伴可以自行搜索安装
从生成效果上来讲,对比下来我个人觉得SadTalker效果还比较不错,而且同时支持视频和图片输入。所以本篇主要对SadTalker的环境搭建和使用做一个详细介绍。
觉得搭建环境麻烦的小伙伴可以下载我的整合包,点击【一键启动.bat】去运行,按照使用说明去修改运行参数。整合包获取方式如下:
点击打开我的个人博客网站扫码或者搜索关注公众号树袋熊AI,并回复关键词【SadTalker】获取
显卡驱动、Git、ffmpeg、Anaconda安装这些我就不再详细介绍了,可以参考Rope源码运行环境搭建这篇博客去安装这些基础软件。另外如果是window10/11的小伙伴可以使用 winget 在终端安装这些软件更加方便,可以在终端通过 “winget search 软件名字” 去搜素,复制id后通过 “winget install 软件id” 去安装。
打开Power Shell终端,按照以下步骤运行,注意windows下不要拷贝带#的注释
# 1. 下载源码,clone失败的话,可以去github下载压缩包解压代替这一步
git clone https://github.com/OpenTalker/SadTalker.git
# 2. 进入源码文件夹
cd SadTalker
# 3,创建conda虚拟环境
conda create -n sadtalker python=3.8
# 4,激活虚拟环境
conda activate sadtalker
# 5. 安装torch,一个深度学习框架
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# 6. 安装软件运行所需的依赖库
pip install -r requirements.txt
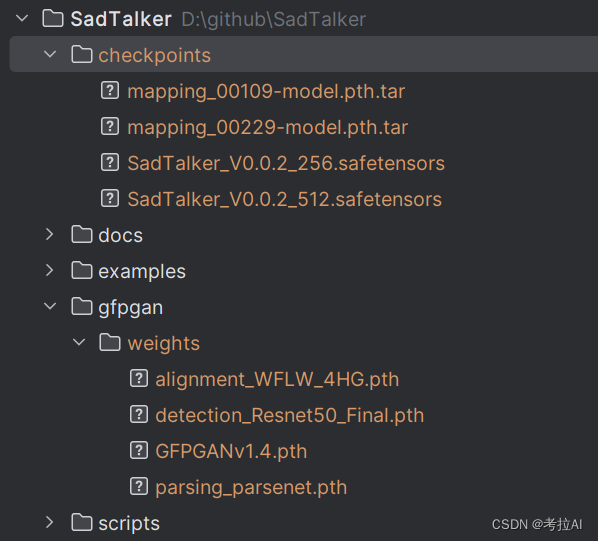
可以去github下载checkpoints模型放置到checkpoints文件夹中;下载weights模型放置到gfgan/weights文件夹中。也可以去我的百度网盘上下载打包好的,下载完成后模型列表如下:
打开Power Shell终端运行,注意windows下不要拷贝带#的注释
# 1. 进入源码文件夹
cd SadTalker
# 2,进入虚拟环境
conda activate sadtalker
# 3. 运行代码进行推理, examples中放置了测试资源, 全身视频,可以加--still参数
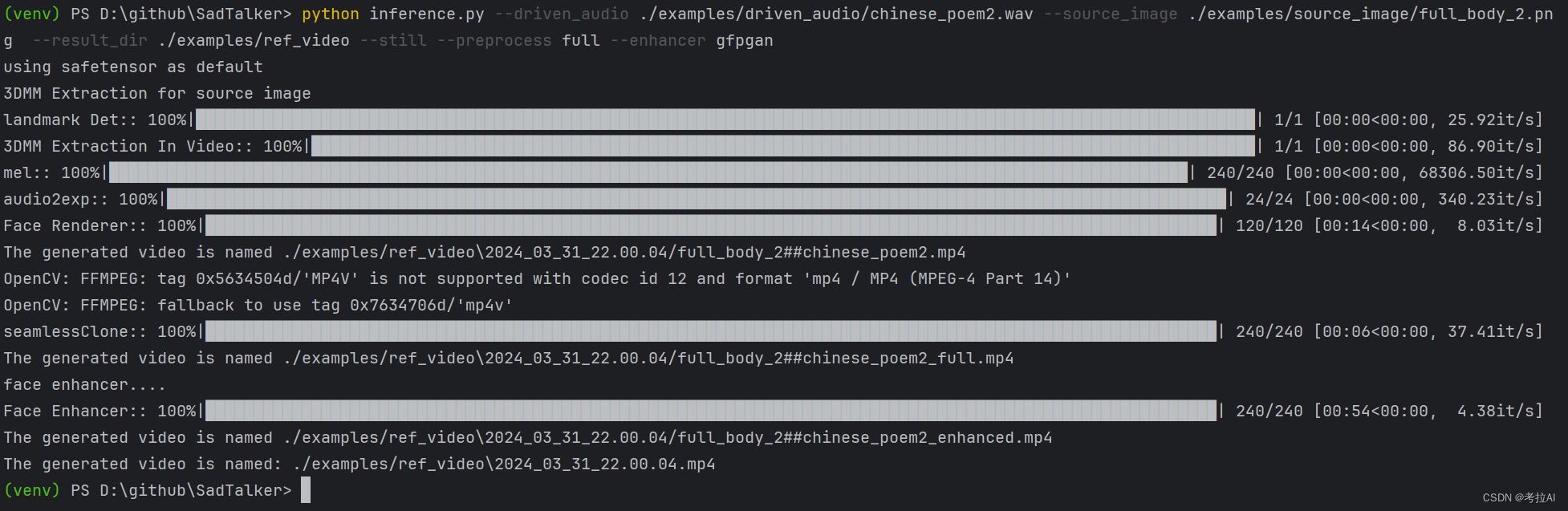
python inference.py --driven_audio ./examples/driven_audio/chinese_poem2.wav --source_image ./examples/source_image/full_body_2.png --result_dir ./examples/ref_video --still --preprocess full --enhancer gfpgan
主要参数解释:
运行成功后会出现以下界面
生成效果如下:
点击打开我的个人博客网站扫码或者搜索关注公众号树袋熊AI,并回复关键词【SadTalker】获取整合包
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

