
热门标签
热门文章
- 1Prompt Engineering入门教学(看这一篇就够!)_prompt engineering教程
- 2群晖Nas笔记_filestation5 删除
- 3kafka的ack机制,幂等性_kafka的重试机制和ack机制
- 4视频汇聚EasyCVR平台视图库GA/T 1400协议与GB/T 28181协议的区别
- 5Python中异常处理传递性_python异常的传递性
- 6Git安装教程超详细(Windows系统)
- 7nginx 编译和安装ssl模块_nginx安装编译ssl
- 8单链表的基本操作(全)
- 9力扣算法刷题顺序_力扣刷题题目类型顺序
- 10真实场景的双目立体匹配(Stereo Matching)获取深度图详解
当前位置: article > 正文
使用LLaMA-Factory微调大模型
作者:小蓝xlanll | 2024-05-30 20:56:28
赞
踩
使用LLaMA-Factory微调大模型
使用LLaMA-Factory微调大模型
github 地址
https://github.com/hiyouga/LLaMA-Factory
搭建环境
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
- 1
- 2
在 LLaMA-Factory 路径下 创建虚拟环境
conda create -p ./venv python=3.10
- 1
激活环境
conda activate ./venv
- 1
在虚拟环境中安装依赖
python -m pip install -e .
- 1
下载数据集
我这里使用自带的数据
LLaMA-Factory/data/glaive_toolcall_zh_demo.json
下载模型
我这里使用 Qwen-1_8B-Chat
本地路径 /media/wmx/soft1/huggingface_cache/Qwen-1_8B-Chat
启动 webui
我这里是本地电脑 显卡是 GTX-4070ti-super 16G ,单卡
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui
- 1
配置参数
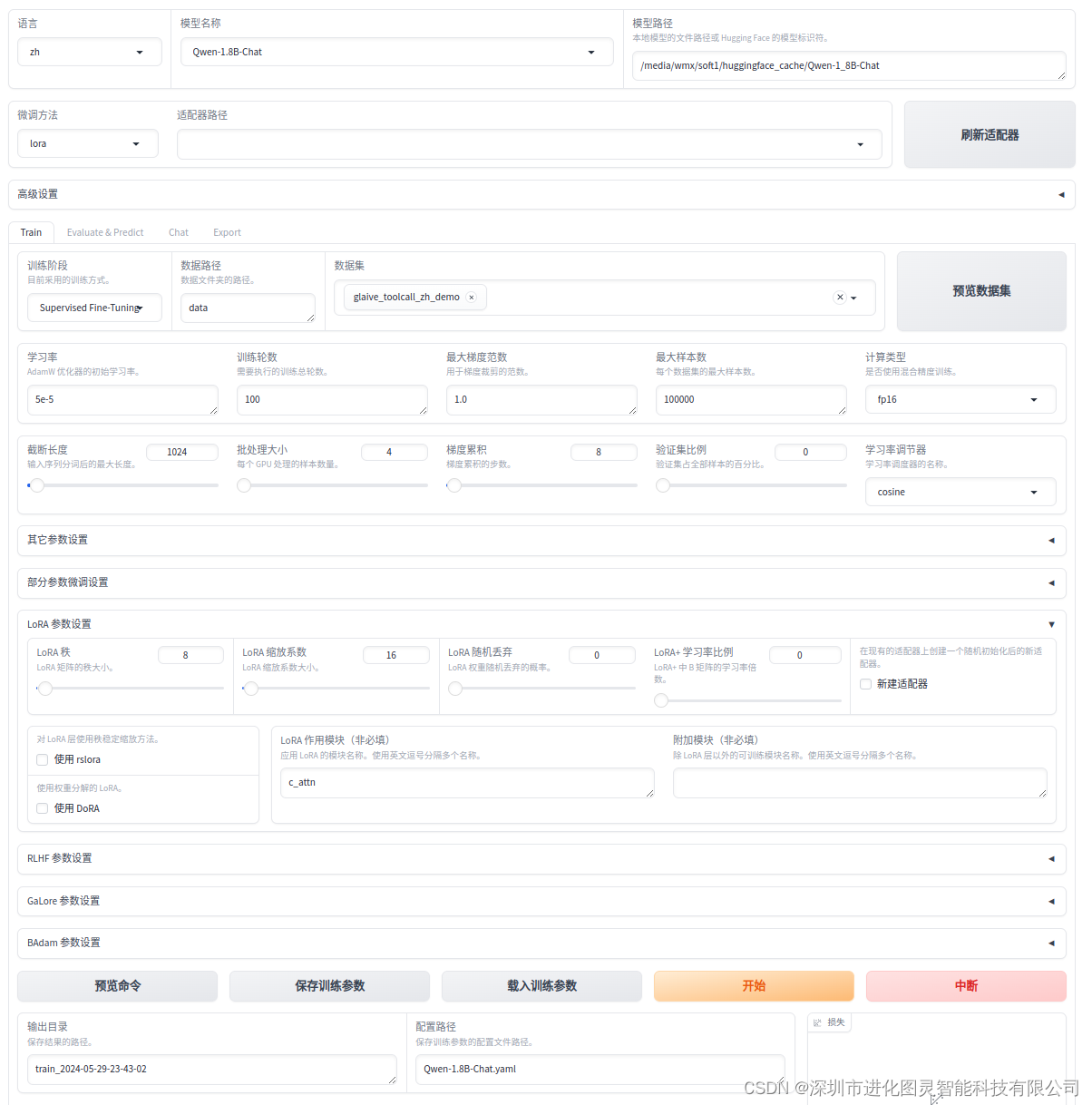
因为是Qwen模型,不是Qwen1.5及以后的模型 所以
train.lora_target: c_attn 这里必须这样,不然报错!!!
Qwen-1.8B-Chat.yaml:
top.adapter_path: []
top.booster: none
top.finetuning_type: lora
top.model_name: Qwen1.5-1.8B-Chat
top.quantization_bit: none
top.rope_scaling: none
top.template: qwen
top.visual_inputs: false
train.additional_target: ''
train.badam_mode: layer
train.badam_switch_interval: 50
train.badam_switch_mode: ascending
train.badam_update_ratio: 0.05
train.batch_size: 4
train.compute_type: fp16
train.create_new_adapter: false
train.cutoff_len: 1024
train.dataset:
- glaive_toolcall_zh_demo
train.dataset_dir: data
train.device_count: '1'
train.ds_offload: false
train.ds_stage: none
train.freeze_extra_modules: ''
train.freeze_trainable_layers: 2
train.freeze_trainable_modules: all
train.galore_rank: 16
train.galore_scale: 0.25
train.galore_target: all
train.galore_update_interval: 200
train.gradient_accumulation_steps: 8
train.learning_rate: 5e-5
train.logging_steps: 5
train.lora_alpha: 16
train.lora_dropout: 0
train.lora_rank: 8
train.lora_target: c_attn
train.loraplus_lr_ratio: 0
train.lr_scheduler_type: cosine
train.max_grad_norm: '1.0'
train.max_samples: '100000'
train.neftune_alpha: 0
train.num_train_epochs: '100'
train.optim: adamw_torch
train.packing: false
train.ppo_score_norm: false
train.ppo_whiten_rewards: false
train.pref_beta: 0.1
train.pref_ftx: 0
train.pref_loss: sigmoid
train.report_to: false
train.resize_vocab: false
train.reward_model: null
train.save_steps: 100
train.shift_attn: false
train.training_stage: Supervised Fine-Tuning
train.upcast_layernorm: false
train.use_badam: false
train.use_dora: false
train.use_galore: false
train.use_llama_pro: false
train.use_rslora: false
train.val_size: 0
train.warmup_steps: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
然后保存配置参数,然后点击开始微调
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/648574
推荐阅读
相关标签

