- 1Linux Centos 7 安装 redis_redisinsight centos7安装
- 2Ubuntu系统下载docker教程_ubuntu下载docker
- 3每日5题Day6 - LeetCode 26 - 30
- 4二叉树的详细实现 (C++)
- 5经验分享:C++ error:‘syscall’ was not declared in this scope
- 6【粉丝福利社】鸿蒙App开发全流程实战(文末送书-完结)_鸿蒙app开发方案
- 7【毕业设计】考试刷题小程序 基于微信小程序的考试刷题系统小程序_刷题小程序开发
- 8Spring事务管理下synchronized锁失效问题_@service synchronized
- 9OceanBase备份与恢复
- 10Python 在PyCharm中添加.gitignore文件_python gitignore file
通俗易懂的Stable Diffusion模型结构介绍_stable diffusion结构
赞
踩
目录
SD的发展历程
Stable Diffusion是一个的文本条件隐式扩散模型(text-conditioned latent diffusion model),可以根据文字描述生成效果极好的图像。
2021年12月提出了隐式扩散模型(Latent Diffusion Models,LDMs)的text-to-image模型。这个研究使得用扩散模型进行文字生成图片任务可以在普通显卡上执行,并且耗时较短。为一年后现象级的稳定扩散(Stable Diffusion)诞生奠定了基础。
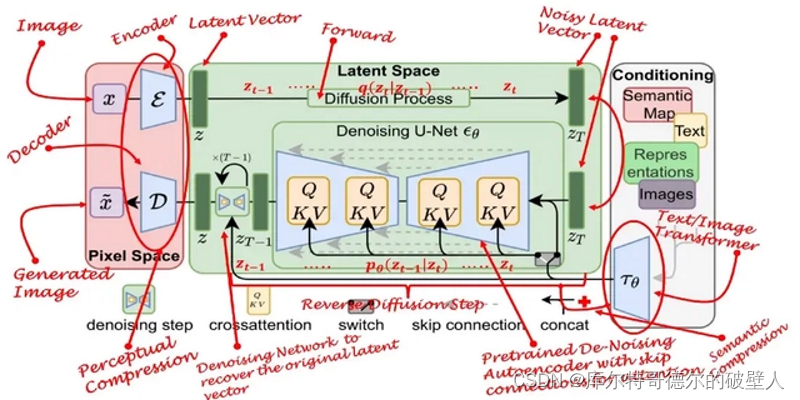
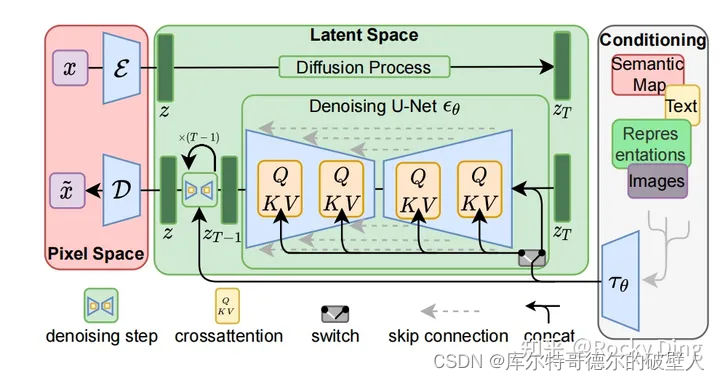
SD 模型的网络结构
主要包括三个部分:
ClipText 文本编码器
ClipText 文本编码器:用于解析提示词的 Clip 模型
文本编码器负责将提示词转换成电脑可以识别的文本向量
Diffusion 扩散模型
Diffusion 扩散模型:用于生成图像的 U-Net 和 Scheduler
扩散模型负责根据文本向量生成图像
VAE 模型
VAE 模型:用于压缩和恢复的图像解码器
而图像编码器则用于将生成的图像信息进行解码,以生成最终的图像输出
简化网络结构图

详细网络结构图
ClipText 文本编码器
为了导入提示词,我们首先需要为文本创建数值表示形式。
为此,Stable Diffusion使用了一个名为CLIP的预训练Transformer模型。
CLIP的文本编码器会将文本描述转换为特征向量,该特征向量可用于与图像特征向量进行相似度比较。

因此,CLIP非常适合从文本描述中为图像创建有用的表征信息。输入的文本提示语首先会被分词(也就是基于一个很大的词汇库,将句子中的词语或短语转换为一个一个的token),然后被输入CLIP的文本编码器,从而为每个token(分词)产生一个768维(针对Stable Diffusion 1.x版本)或1024维(针对Stable Diffusion 2.x版本)的向量。
CLIP模型
CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。
其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;
而Image Encoder主要用来提取图像的特征,可以使用CNN/vision transformer模型(ResNet和ViT)作为Image Encoder。与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
文本向量输入Unet
文本提示词转换为向量后将被输入扩散模型,用于引导图像的生成,这里使用的扩散模型是Unet网络。
文本向量如何输入UNet进行预测?
交叉注意力(cross-attention)机制
交叉注意力层贯穿了整个UNet结构,UNet中的每个空间位置都可以“注意”到文字条件中不同的token,以便从文本提示语中获取不同位置的相互关联信息。
下图展示了UNet不同层之间信息的传递
以文本为生成条件
将提示信息输入UNet,实现对图像生成的定向引导,这种方法称为条件生成。
UNet的原理
在预测过程中,通过反复调用UNet迭代降噪,将UNet预测输出的noise slice从原有的噪声中去除,从而生成高质量图像。(具体细节可以看:扩散模型思想及数学原理-CSDN博客 )
对于给定的“带噪”图像,可以使模型基于提示信息来预测“去噪”后的图像。在推理阶段,我们可以输入期望图像的文本描述,并将纯噪声数据作为起点,然后模型便开始全力对噪声输入进行“去噪”,从而生成能够匹配文本描述的图像。
具体到Stable Diffusion模型中,在推理阶段,我们可以输入期望图像的文本描述,并将纯噪声数据作为起点,然后模型便开始全力对噪声输入进行“去噪”,从而生成能够匹配文本描述的图像。

文本编码过程:将输入的文本提示语转换为一系列的文本嵌入(即图中的ENCODER_HIDDEN_STATES),然后输入UNet作为生成条件。
VAE模型
由Latent Diffusion提出
当输入图像尺寸变大时,生成图片所需的计算能力也会随之增加。这种现象在自注意力(self-attention)机制下的影响尤为突出,因为操作数会随着输入量的增加以平方关系增加。
例如:一张128×128像素的正方形图片拥有的像素数量是一张64×64像素的正方形图片的4倍,因此在自注意力层就需要16倍(42)于后者的内存和计算量。
这是高分辨率图像生成任务存在的普遍问题
为了解决这个问题,隐式扩散(Latent Diffusion)使用了一个独立的模型——VAE来压缩图片到一个更小的空间维度,VAE全称是 Variational Auto Encoder 变分自动编码器
VAE原理
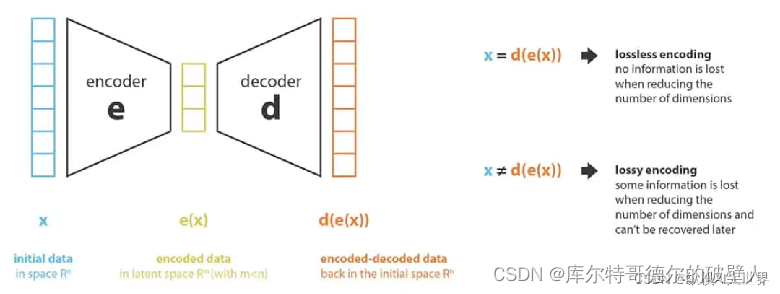
图片通常包含大量冗余信息,因此我们可以训练一个VAE(对其使用大量的图片数据进行训练),使其可以将图片映射到一个较小的隐式表征,并将这个较小的隐式表征映射到原始图片。
简单来说,它的作用就是将高维数据(像素空间)映射到低维空间(潜空间),从而实现数据的压缩和降维。
VEA组成
它由编码器(Encoder)和解码器(Decoder)两部分组成。 编码器用于将图像信息降维并传入潜空间中,解码器将潜在数据表示转换回原始图像,而在潜在扩散模型的推理生成过程中我们只需用到 VAE 的解码器部分。
SD对VAE的应用
Stable Diffusion中的VAE能够接收一张三通道图片作为输入,从而生成一个4通道的隐式表征,同时每一个空间维度都将减少为原来的八分之一。
例如,一张512×512像素的正方形图片将被压缩到一个4×64×64的隐式表征上。
作用
通过在隐式表征(而不是完整图像)上进行扩散,我们可以在使用更少的内存的同时减少UNet层数并加速图片的生成。与此同时,我们仍能把结果输入VAE的解码器,从而解码得到高分辨率图像。隐式表征极大降低了训练和推理成本。
总结图