
- 1三教父神仙打架!AI瓶颈问题的三个解决方案!_如何改进人工智能的泛化瓶颈
- 2使用香橙派并基于Linux实现最终版智能垃圾桶项目 --- 上_香橙派 ir-keytable_香橙派 面试
- 3bert-textcnn实现多标签文本分类(基于keras+keras-bert构建)_textcnn+bert文本分类
- 4JSONView下载安装
- 5【计算机网络】UDP协议详解_udp端口
- 6医学影像数据集汇总(持续更新)150个_pmc-oa数据集下载
- 7【详解】神经网络矩阵的点乘与叉乘(pytorch版)_pytorch点乘与叉乘
- 8github:fork的用途_github fork
- 9GitHub 搜索技巧:如何更有效地搜索 issue、repo 和更多信息
- 10GO语言-方法_go语言 方法前面加go
RedisCluster集群中的插槽为什么是16384个?_redis集群crc16
赞
踩
RedisCluster集群中的插槽为什么是16384个?
CRC16的算法原理。
- 1.根据CRC16的标准选择初值CRCIn的值
- 2.将数据的第一个字节与CRCIn高8位异或
- 3.判断最高位,若该位为0左移一位,若为1左移一位再与多项式Hex码异或
- 4.重复3至9位全部移位计算结束
- 5.重复将所有输入数据操作完成以上步骤,所得16位数即16位CRC校验码
CRC16算法最大值。
CRC16算法,产生的哈希值有16bit位,可以产生65535(2^16)个值,也就是说值分布在0~65535之间,这个时候疑问就来了,槽位总数为什么是16384?65536不可以吗?
作者问题回答链接
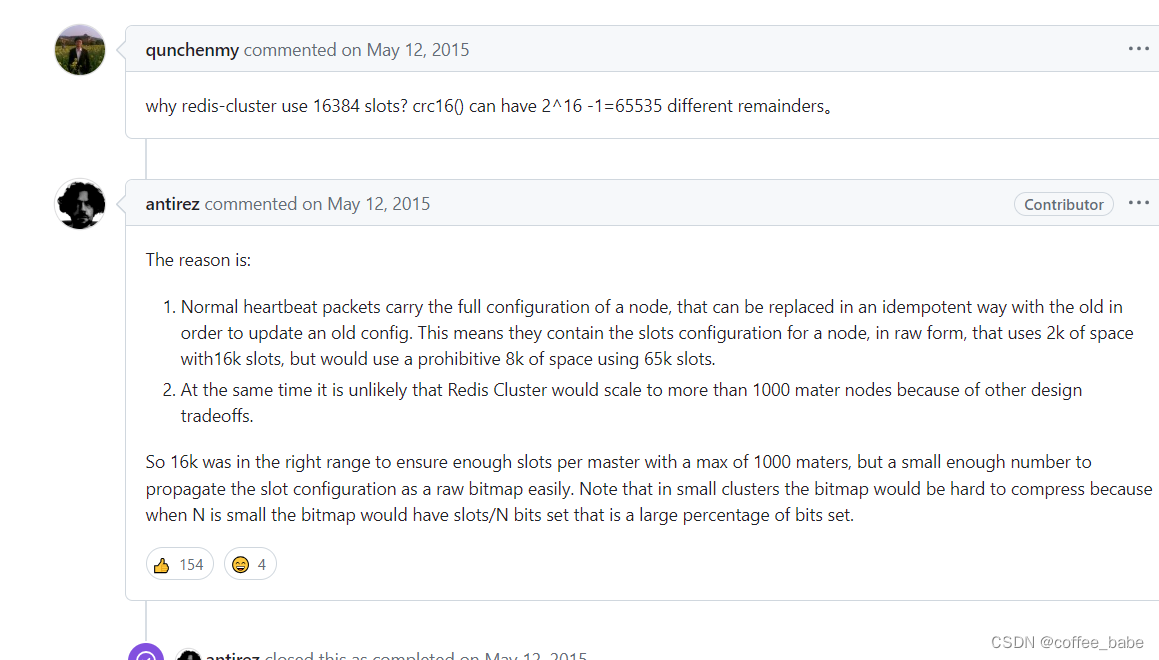
Antirez(Redis作者)大神做了回复,归纳起来就是:
- 1.正常的心跳数据包携带节点携带节点的完整配置,它能以幂等方式来更新配置,如果采用16384个插槽,占用空间为2KB(16384 / 8 / 1024 = 2KB),如果采用65536个插槽,占用空间8KB(65536 / 8 / 1024=8KB)
- 2.Redis Cluster不太可能扩展到超过1000个主节点,太多可能导致网络拥堵
- 3.16384个插槽范围比较合适,当集群扩展到1000个节点时,也能确保每个master节点有足够的插槽
8KB的心跳包看似不大,但是这个是心跳包每秒都要将本节点的信息同步给其他集群节点。
比起16384个插槽,头大小增加了4倍,ping消息的消息头太大了,浪费带宽。
Redis主节点的哈希槽配置信息是通过bitmap来保存的,也就是位数组,元素的值为0或1.在传输过程中,会对bigmap进行压缩,bitmap的填充率越低,压缩率越高。bitmap填充率 = slots / N(N表示节点数)
所以插槽数偏低的话,填充率就会降低,压缩率会升高
综合下来,从心跳包的大小、网络带宽、心跳并发、压缩率等维度考虑,16384个插槽更有优势且能满足业务需求
为什么bitmap填充率越低,压缩率就越高?
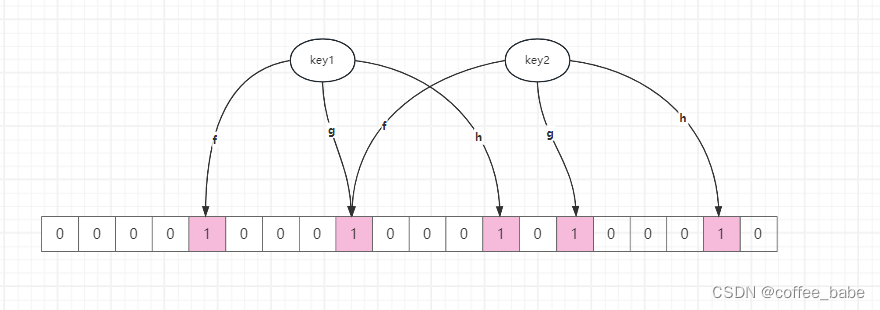
在Redis中,对bit数组进行压缩时,压缩率与填充的数(或者说是1的数量)的关系是成反比的,因为在压缩过程中,Redis使用的是基于运行长度编码(Run-Length-Encoding,RLE)的压缩算法。RLE是一种基本的压缩算法,它通过识别重复出现的连续数据来减少存储空间。如果数据中存在
大量的连续重复字符,RLE算法的随机效果会非常好,反之,如果数据中的字符分布较为随机,没有出现太多连续的重复字符,那么RLE的压缩效果就不明显,甚至可能使数据变大
RLE示例
RLE算法示例。
AAABBBCCDDEEEEEFF
- 1
按照RLE算法进行压缩:
1.扫描到连续的3个A,记录为(A,3)
2.接下来是连续的3个B,记录为(B,3)
3.然后是2个C,记录为(C,2)
4.接着是2个D,记录为(D,2)
5.然后是4个E,记录为(E,4)
6.最后是3个F,记录为(F,4)
压缩后的数据为:
(A,3)(B,3)(C,2)(D,2)(E,4)(F,3)
- 1
master节点间心跳数据包格式
消息格式分为:消息头+消息体。消息头包含发送节点自身状态数据,接收节点根据消息头就可以获取到发送节点的相关数据相关代码在src/cluster.h文件中以5.0版本为例,如代码所示,消息头中有一个myslots的char类型数组
unsinged char myslots[CLUSTER_SLOTES/8]
- 1
数组长度为16384/8=2048.底层存储其实是一个
bitmap,每一位代表一个插槽,如果该位为1,表示这个插槽是属于这个节点的。消息体中,会携带一定数量的其他节点信息用于交换,约为集群总节点数量的1/10,节点数量越多,消息体内容越大。10个节点的消息体大小约为1kb,char 在C语言中占用一个字节
typedef struct { char sig[4]; // 信号的标识 uint32_t totlen; // 信号的长度 uint16_t ver; // 版本信息 uint16_t port; // tcp端口信息 uint16_t type; // 消息类型,用于区分meet,ping,pong uint16_t count; // 消息体包含的节点数量,meet,ping,pong uint64_t currentEpoch; // 当前发送节点的配置纪元 uint64_t configEpoch; // 从节点的主节点配置纪元 uint64_t offset; // 复制的偏移量 unsigned char myslots[CLUSTER_SLOTS/8]; // 发送节点负责的插槽信息 char slaveof[CLUSTER_NAMELEN]; // 如果发骚那个节点是从节点,记录对应主节点的nodeId char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */ char notused1[34]; /* 34 bytes reserved for future usage. */ uint16_t cport; /* Sender TCP cluster bus port */ uint16_t flags; // 发送节点标识,区分主从是否下线 unsigned char state; // 发送系欸但所处的集群状态 unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */ union clusterMsgData data; } clusterMsg;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Master通信
master节点间心跳通讯。
Redis集群采用Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,类似流言传播
具体规则如下:
- 1.每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息
- 2.每隔100ms都会扫描本地节点列表,如果发现节点最近一次接收pong消息的时间大于
cluster-node-timeout/2
- 1
则立即发送ping消息
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出现故障、新节点加入、主从角色变化、插槽信息变更等事件发生时,通过不断地ping/pong消息通信,经过一段时间后所有节点都会知道整个集群 全部节点地最新状态,从而达到集群状态同步的目的

