- 1如何让大模型更聪明
- 2【2022最新Java面试宝典】—— MySQL面试题(40道含答案)_java mysql面试题
- 3浏览器在线浏览PDF文件之pdf.js_pdfjs稳定版
- 4git推送本地分支到远程分支[转发]_git 推送本地分支到远程分支失败
- 5特征筛选之特征递归消除法及Python实现_rfe算法
- 6oracle下interval类型的用法总结
- 7FPGA的工作原理是什么?_fpga芯片的工作原理
- 8java家教平台系统计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
- 9C语言简单的数据结构:单链表_c语言单链表
- 10Linux: Package:libaio-devel-0.3.109 (x86_64)
基于ChatGLM+Langchain离线搭建本地知识库(免费)_本地知识库 日记 离线
赞
踩
目录
简介
ChatGLM-6B是清华大学发布的一个开源的中英双语对话机器人。基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
LangChain提供了丰富的生态,可以非常方便的封装自己的工具,并接入到LangcChain的生态中,从而实现语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
服务部署
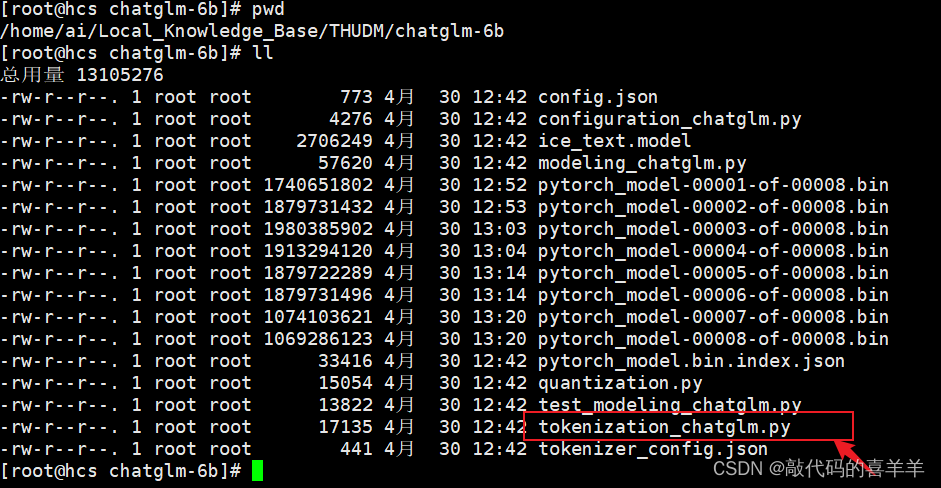
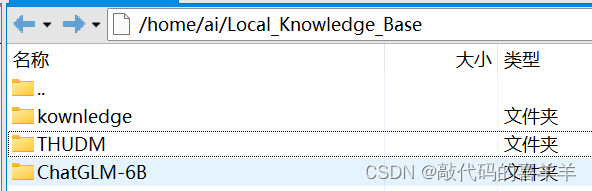
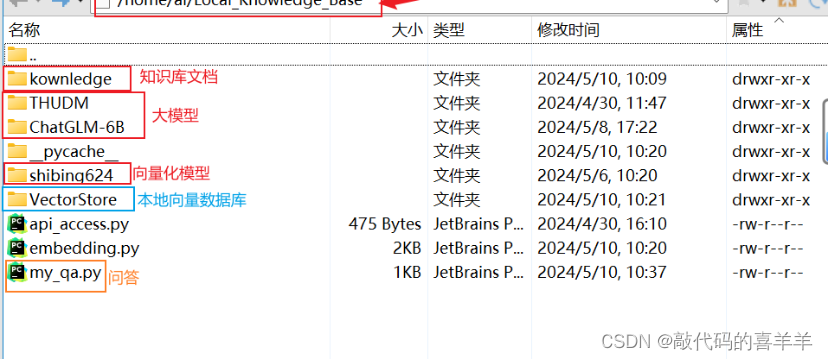
我是在一台离线服务器上,GPU内存16G,其中python3.10以上,torch1.10以上。首先github下载ChatGLM-6B(https://github.com/THUDM/ChatGLM-6B),方便调用接口,里面有一个 requirements.txt文件,直接安装里面环境即可,然后在Huggingface下载模型chatglm-6b(https://huggingface.co/THUDM/chatglm3-6b),最后将下载好的模型离线打包到离线服务器上。如下所示,其中kownledge文件夹里面包含了我要输入的知识文档(自己的一些文档、pdf、csv文件等)。
当环境搭建好之后,进入ChatGLm-6B文件夹下,打开api.py文件,将tokenizer和model的模型路径修改成从Huggingface下载下来的chatglm-6b模型路径,这里我用的是相对路径。

然后在服务器上运行api.py文件,服务在端口8000运行。

写一个测试代码api_access.py,看看服务是否能被正常使用。值得注意的是,如果你是在本地运行,这里的url写localhost:8000或者127.0.0.1:8000,如果是服务器运行,则写服务器的ip地址。
- import requests
-
- def chat(prompt, history):
- resp = requests.post(
- #url = 'http://127.0.0.1:8000',
- url = 'http://172.27.171.194:8000',
- json = {"prompt": prompt, "history": history },
- headers = {"Content-Type": "application/json;charset=utf-8"}
- )
- return resp.json()['response'], resp.json()['history']
-
-
- history = []
- while True:
- response, history = chat(input("Question:"), history)
- print('Answer:',response)
运行结果如下所示,说明该api服务能够正常使用。

实现本地知识库
首先在Huggingface下载向量化模型,我选择了text2vec-base-chinese(https://huggingface.co/shibing624/text2vec-base-chinese/tree/main)
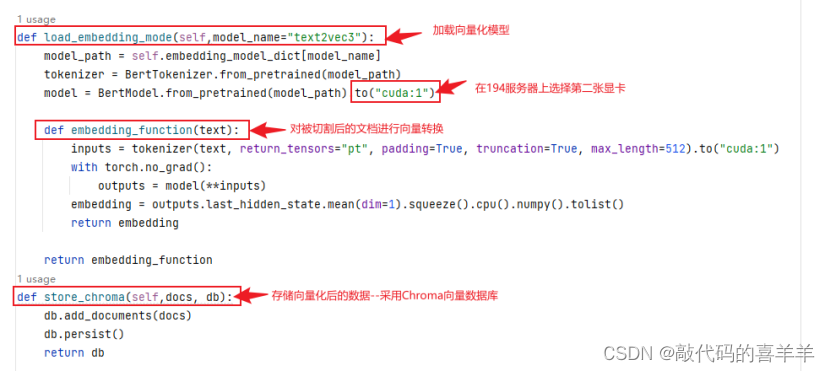
然后编写一个embedding.py文件,主要存放各种方法,完整代码如下所示。值得注意的是,由于我的服务器有多张显卡,因此我将cuda设置为1,你如果只有一张显卡,就直接是cuda:0。
- from langchain_community.document_loaders import Docx2txtLoader, PyPDFLoader
- from langchain.text_splitter import RecursiveCharacterTextSplitter
- from transformers import BertModel, BertTokenizer
- import torch
- import os
-
- # -*- coding: utf-8 -*-
-
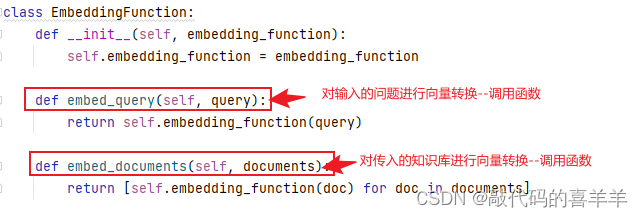
- class EmbeddingFunction:
- def __init__(self, embedding_function):
- self.embedding_function = embedding_function
-
- def embed_query(self, query):
- return self.embedding_function(query)
-
- def embed_documents(self, documents):
- return [self.embedding_function(doc) for doc in documents]
-
-
- class EmbeddingRetriever:
- def __init__(self):
- # 加载embedding
- self.embedding_model_dict = {
- "text2vec3": "shibing624/text2vec-base-chinese",
- "bert-base-chinese": "/home/ai/bert-base-chinese",
- }
-
- def load_documents(self,directory='kownledge'):
- documents = []
- for item in os.listdir(directory):
- if item.endswith("docx") or item.endswith("pdf"):
- split_docs = self.add_document(directory, item)
- documents.extend(split_docs)
- return documents
-
- def add_document(self, directory='kownledge', doc_name=''):
- file_path = os.path.join(directory, doc_name)
- if doc_name.endswith("docx"):
- loader = Docx2txtLoader(file_path=file_path)
- elif doc_name.endswith("pdf"):
- loader = PyPDFLoader(file_path=file_path)
- data = loader.load()
- text_spliter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
-
- split_docs = text_spliter.split_documents(data)
- return split_docs
-
- def load_embedding_mode(self,model_name="text2vec3"):
- model_path = self.embedding_model_dict[model_name]
- tokenizer = BertTokenizer.from_pretrained(model_path)
- model = BertModel.from_pretrained(model_path).to("cuda:1")
-
- def embedding_function(text):
- inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512).to("cuda:1")
- with torch.no_grad():
- outputs = model(**inputs)
- embedding = outputs.last_hidden_state.mean(dim=1).squeeze().cpu().numpy().tolist()
- return embedding
-
- return embedding_function
- def store_chroma(self,docs, db):
- db.add_documents(docs)
- db.persist()
- return db
简单解释如下,在load_documents和add_document方法中,由于我的知识文档是docx和pdf格式的,因此我就只写了两个类型,你如果有其他类型比如csv或者txt可以修改调用方式,如:
from langchain_community.document_loaders import TextLoader,CSVLoader

测试
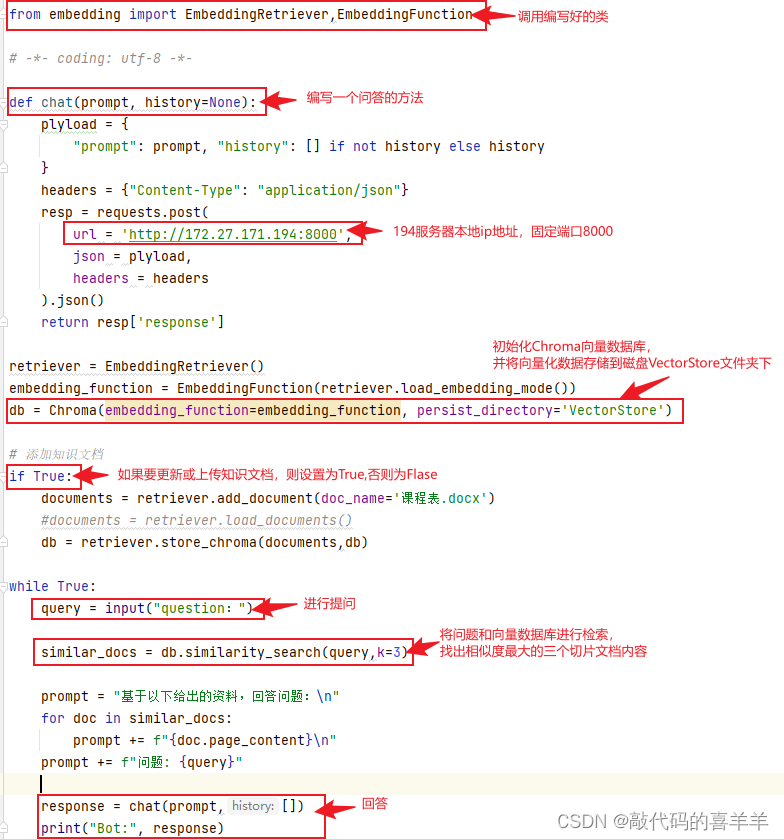
编写一个问答代码my_qa.py,完整代码如下所示,记得修改url地址。
- from langchain_community.vectorstores import Chroma
- import requests
- from embedding import EmbeddingRetriever,EmbeddingFunction
-
- # -*- coding: utf-8 -*-
-
- def chat(prompt, history=None):
- plyload = {
- "prompt": prompt, "history": [] if not history else history
- }
- headers = {"Content-Type": "application/json"}
- resp = requests.post(
- url = 'http://172.27.171.194:8000',
- json = plyload,
- headers = headers
- ).json()
- return resp['response']
-
- retriever = EmbeddingRetriever()
- embedding_function = EmbeddingFunction(retriever.load_embedding_mode())
- db = Chroma(embedding_function=embedding_function, persist_directory='VectorStore')
-
- # 添加知识文档
- if True:
- documents = retriever.add_document(doc_name='课程表.docx')
- #documents = retriever.load_documents()
- db = retriever.store_chroma(documents,db)
-
- while True:
- query = input("question:")
-
- similar_docs = db.similarity_search(query,k=3)
-
- prompt = "基于以下给出的资料,回答问题:\n"
- for doc in similar_docs:
- prompt += f"{doc.page_content}\n"
- prompt += f"问题: {query}"
-
- response = chat(prompt,[])
- print("Bot:", response)
-
简单解释如下:
在服务器上运行python my_qa.py,结果如下:

可以看到,准确度还是相当不错的。如果自己输入的知识库数量越多,回答越准确。
最后看看我的服务器上的文档位置。
可能出现的问题
1、解决transformers和sentence-transformers版本冲突问题
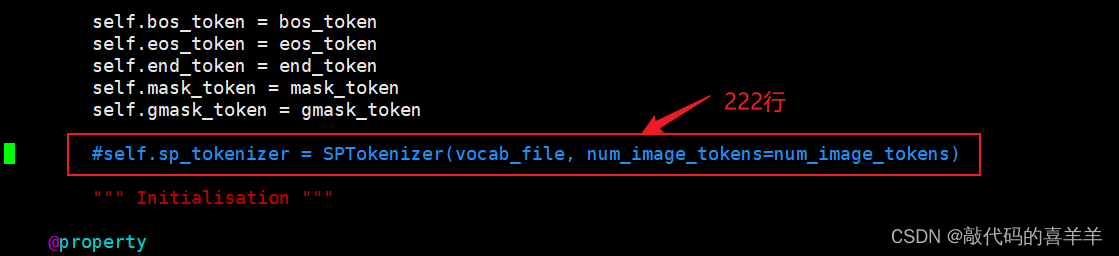
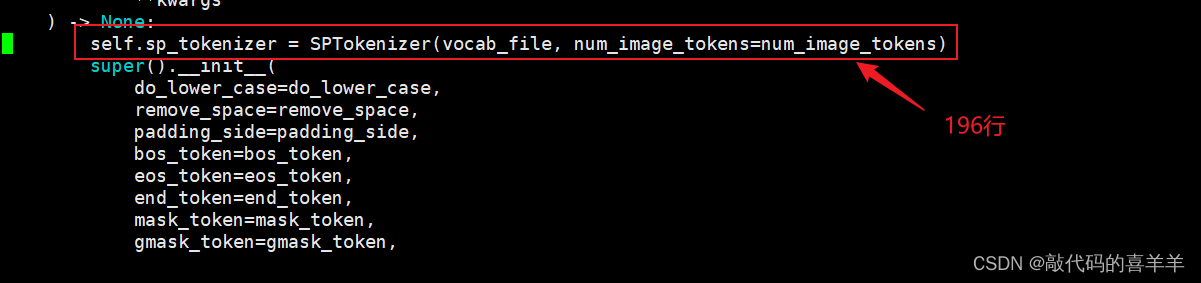
使用pip install -U sentence-transformers下载sentence-transformers时会下载最新版2.7.0并且把最新版的transformers4.39.3一起附带下载下来,但是在ChatGLM中要求的transformers版本是4.27.1,因此如果使用最新版的transformers在运行api.py接口时会报错提示没有xxxx属性。解决方式有两种,第一种就是手动降低版本(但可能会报出其他错误),第二种就是修改chatglm-6b的配置文件,如下所示:
就是将从Huggingface下载的模型chatglm-6b下的tokenization_chatglm.py文件进行修改,将第222行的代码注释,放在第196行,也就是super().__init__上面。