
- 1测试团队如何建设?_测试团队 建设
- 2一个git客户端配置多个git远程仓库账号_git 生成的密钥可以供多个远程库使用吗
- 3Python爬虫山西太原景点数据可视化和景点推荐系统 开题报告_山西旅游运营数据采集
- 4socket安装_socket库安装
- 5Kafka 客户端 Consumer 常用配置_kafka consumer常用配置
- 6matlab for Linux 安装_matlab for linux csdn
- 7从 0 搭建 Vite 3 + Vue 3 Js版 前端工程化项目_创建一个vue3+vite+js 的项目
- 8nginx负载均衡反向代理MySQL配置_反向代理mysql配置域名
- 9Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明
- 10森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型_paddlehub 手写数字识别
AI系统性学习—LangChain入门_langchain 入门
赞
踩
1、LangChain入门
1.1 简介
LangChain是一个开源的Python库,它提供了构建基于大模型的AI应用所需的模块和工具。通过LangChain,开发者轻松地与大语言模型(LLM)集成,完成文本生成、问答、翻译、对话等任务。LangChain降低了AI应用开发的门槛,让任何人都可以基于LLM构建属于自己的创建应用。LangChain特性如下:
- LLM和Prompt:LangChain对所有LLM大模型进行了API抽象,统一了大模型访问API,同时提供了Prompt提示模型管理机制。
- Chain:这些是对LLM或其他使用程序的调用序列。LangChain为链提供了标准接口,与各种工具集成,为流行应用提供了端到端的链。
- 数据增强:LangChain使链能够与外部数据源交互以收集生成步骤的数据。例如,它可以帮助总结长文本或使用特定数据源回答问题。
- Agents:Agents让LLM做出有关行动的决定,采取这些行动,检查结果,并继续前进直到工作完成。LangChain提供了代理的标准接口,多种代理可以选择,以及端到端的代理示例。
- 评估:很难用传统指标评估生成模型。这就是为什么LangChain提供提示和链来帮助开发者自己使用LLM评估他们的模型。
1.2 架构
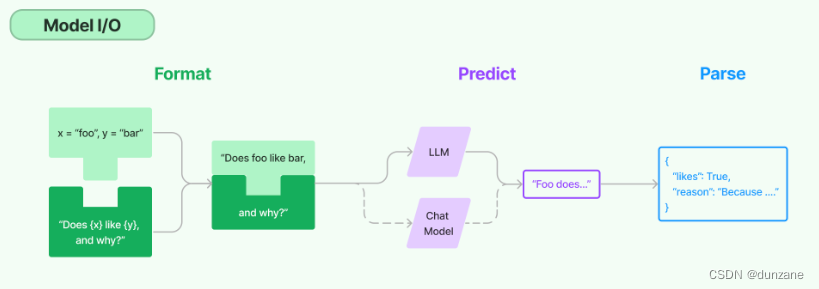
LangChain提供一套Pormpt提示词模版管理工具,负责处理提示词,然后传递给大模型处理,最后处理大模型返回的结果,目前对大模型的封装主要包括LLM和Chat Model两种类型:
- LLM - 问答模型,模型接受一个文本输入,然后返回一个文本结果。
- Chat Model - 接收一组对话消息,然后返回对话消息,类似聊天信息一样。
1.3 核心概念
- Components and Chains
在LangChain中,Component是模块化构建块,可以组合起来创建强大的应用程序。Chain是组合在一起以完成特定任务的一些列Components(或其他Chains)。例如,一个Chain可能包括一个Prompt模版、一个语言模型和一个输出解析器,他们一起工作以处理用户输入、生成响应并处理输出。 - Prompt Templates and Values
Prompt Template负责创建PromptValue,这是最终传递给语言模型的内容。提示词模版有助于将用户输入和其他动态信息转换为适合语言模型的格式。PromptValue是具有方法的类,这些方法可以转换为每个模型类型期望的确切输入类型(如文本或聊天类型)。 - Example Selectors
当你想要在Prompts中动态包含示例时,Example Selectors很有用。他们接受用户输入并返回一个示例列表以在提示中使用,使其更强大和特定于上下文。 - Output Parsers
Output Parsers 负责将语言模型响应构建为更有用的格式。它们实现了两种主要方法:一种用于提供格式化指令,另一种用于将语言模型的响应解析为结构化格式。这使得在您的应用程序中处理输出数据变得更加容易。 - Indexes and Retrievers
Index 是一种组织文档的方式,使语言模型更容易与它们交互。检索器是用于获取相关文档并将它们与语言模型组合的接口。LangChain 提供了用于处理不同类型的索引和检索器的工具和功能,例如矢量数据库和文本拆分器。 - Chat Message History
LangChain 主要通过聊天界面与语言模型进行交互。ChatMessageHistory 类负责记住所有以前的聊天交互数据,然后可以将这些交互数据传递回模型、汇总或以其他方式组合。这有助于维护上下文并提高模型对对话的理解。 - Agents and Toolkits
Agent 是在 LangChain 中推动决策制定的实体。他们可以访问一套工具,并可以根据用户输入决定调用哪个工具。Tookits 是一组工具,当它们一起使用时,可以完成特定的任务。代理执行器负责使用适当的工具运行代理。
1.2 快速入门
- 安装
pip install langchain
- 1
- 环境设置
设用openai提供的模型,注意设置openai的api key:
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="Replace By Your Key")
- 1
- 2
- 3
- 构建应用程序
基于Langchain实现聊天
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
# 基于Langchain实现聊天
# 定义模型:思考如果是其他的模型怎么引入?
chat = ChatOpenAI(openai_api_key="Replace By Your Key",temperature=0)
# 定义模版
template = "Your are helpful assistant that translates {input_language} to {output_language}"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt,human_message_prompt])
# 创建链条
chain = LLMChain(llm=chat,prompt=chat_prompt)
r = chain.run(input_language="English",output_language="French",text="i love programming!")
print(r)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
代理(Agent)
为了处理复杂的工作流程, 我需要执行一序列操作用于增强LLM(大模型)的能力。代理(Agents)简单的理解就是代替模型执行一些操作,大模型作为大脑用于决策,由大模型决定执行什么操作或者操作的顺序。代理可以访问工具,工具指的是封装好的一些操作/处理逻辑等,通过代理运行工具并观察输出, 直到它们得出最终答案。要加载一个代理,您需要选择一个:
- LLM/聊天模型: 驱动代理的语言模型。
- 工具: 执行特定任务的函数。这可以是以下事项:谷歌搜索、数据库查找、Python REPL、其他链。
代理名称: 用于引用代理类。对于此示例,我们将使用SerpAPI查询搜索引擎。
安装SerpAPI Python包:
from langchain.agents import AgentType,initialize_agent,load_tools
from langchain.llms import OpenAI
# 使用openai大模型
llm = OpenAI(openai_api_key="Replace By Your Key",temperature=0)
# 加载工具类
tools = load_tools(["serpapi","llm-math"],llm=llm)
# 通过工具类初始化代理
agent = initialize_agent(tools=tools,llm=llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
# 向AI进行提问
agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
记忆(Memory)
到目前为止,我们看到的链和代理都是无状态的,但是对于许多应用来说,参考过去的交互非常必要。这在聊天机器人中是十分明显的,您会希望它根据过去的消息来理解新的消息。
目前所有大模型都存在有限的上下文限制,简单的说大模型记不住曾经说过话、做过的事情,LangChain通过memory模块帮助记忆历史信息。
Memory模块为您提供了一种维护应用程序状态的方式。基本的内存接口很简单:它允许您根据最新运行的输入和输出更新状态,并允许您使用存储的状态修改(或上下文化)下一个输入。
有许多内置的memory系统。其中最简单的就是缓冲内存,它只是将最近的几个输入/输出追加到当前输入中 —— 我们将在下面的示例中使用它。
from langchain import OpenAI, ConversationChain
# model_provider = OpenAIModelProvider(model_name="text-davinci-004")
llm = OpenAI(openai_api_key="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",
temperature=0,)
conversation = ConversationChain(llm=llm,verbose=True)
# 第一运行
# r = conversation.run("你好")
# print(r)
# 第二次运行
r = conversation.run("我刚才说的是什么?")
print(r)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.3 安装
pip install langchain
- 1
2、LangChain Prompt Template
语言模型以文本作为输入 - 这个文本通常被称为提示词(prompt)。在开发过程中,对于提示词通常不能直接硬编码,不利于提示词管理,而是通过提示词模板进行维护,类似开发过程中遇到的短信模板、邮件模板等等。
2.1 什么是提示词模版
提示词模板本质上跟平时大家使用的邮件模板、短信模板没什么区别,就是一个字符串模板,模板可以包含一组模板参数,通过模板参数值可以替换模板对应的参数。
一个提示词模版可以包含下面内容:
- 发给大语言模型的指令
- 一组问答示例,以提醒LLM以什么样的风格返回请求
- 发给语言模型的问题
以下是一个提示词模版例子:
from langchain import PromptTemplate
# 提示词模板,内嵌了一个变量product
template = """\
You are a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate.from_template(template)
# 根据变量渲染模板
prompt.format(product="colorful socks")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.1 创建一个提示词模版
from langchain import PromptTemplate
# 没有输入变量的示例提示
no_input_prompt = PromptTemplate(input_variables=[], template="告诉我一个笑话。")
no_input_prompt.format()
# -> "告诉我一个笑话。"
# 一个输入变量的示例提示
one_input_prompt = PromptTemplate(input_variables=["adjective"], template="告诉我一个{adjective}的笑话。")
one_input_prompt.format(adjective="好笑的")
# -> "告诉我一个好笑的笑话。"
# 多个输入变量的示例提示
multiple_input_prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="告诉我一个{adjective}关于{content}的笑话。"
)
multiple_input_prompt.format(adjective="好笑的", content="鸡")
# -> "告诉我一个好笑的关于鸡的笑话。"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
也可以类似前面的模型加载方式:
template = "告诉我一个{adjective}的笑话,和{content}相关的"
# 通过from_template创建提示词模板
prompt_template = PromptTemplate.from_template(template)
# 打印模板参数,from_template会自动根据模板内容推断出具体关联的模板参数,不需要手动定义
prompt_template.input_variables
# -> ['adjective', 'content']
prompt_template.format(adjective="好笑的", content="鸡")
# -> 告诉我一个好笑的笑话,和鸡相关的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2 聊天消息提示词模版
聊天模型(Chat Model)以聊天消息列表作为输入,这个聊天消息列表的消息内容也可以通过提示词模板进行管理。这些聊天消息与原始字符串不同,因为每个消息都与“角色(role)”相关联。
例如,在OpenAI的Chat Completion API中,聊天消息可以与AI、人类(human)或系统(system)角色相关联。Openai的聊天模型,给不同的聊天消息定义了三种角色类型分别是AI、人类(human)或系统(system)角色:
- AI消息指的是当前消息是AI回答的内容
- 人类(human)消息指的是你发给AI的内容
- 系统(system)消息通常是用来给AI身份进行描述。
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
具体的使用方法就类似上面给出的例子
2.3 模版追加示例
提示词中包含交互样本的作用是为了帮助模型更好地理解用户的意图,从而更好地回答问题或执行任务。小样本提示模板是指使用一组少量的示例来指导模型处理新的输入。这些示例可以用来训练模型,以便模型可以更好地理解和回答类似的问题。
- 创建数据集:
examples = [
{
"question":"谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?",
"answer":
"""
这里需要跟进问题吗:是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:艾伦·图灵去世时多大?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer":
"""
这里需要跟进问题吗:是的。
跟进:craigslist的创始人是谁?
中间答案:craigslist由Craig Newmark创立。
跟进:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的祖父母中的母亲是谁?",
"answer":
"""
这里需要跟进问题吗:是的。
跟进:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
跟进:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer":
"""
这里需要跟进问题吗:是的。
跟进:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是Steven Spielberg。
跟进:Steven Spielberg来自哪里?
中间答案:美国。
跟进:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是Martin Campbell。
跟进:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 通过promptTemplate对象,简单的在提示词模版中插入样例。
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题:{question}\\n{answer}")
# 提取examples示例集合的一个示例的内容,用于格式化模板内容
print(example_prompt.format(**examples[0]))
- 1
- 2
- 3
- 4
- 将示例和格式化程序提供给FewShotPromptTemplate
通过FewShotPromptTemplate对象,批量插入示例内容。
# 接收examples示例数组参数,通过example_prompt提示词模板批量渲染示例内容
# suffix和input_variables参数用于在提示词模板最后追加内容
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="问题:{input}",
input_variables=["input"]
)
print(prompt.format(input="乔治·华盛顿的父亲是谁?"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 使用示例选择器
这里重用前一部分中的示例集和提示词模板。但是,不会将示例直接提供给FewShotPromptTemplate对象,把全部示例插入到提示词中,而是将它们提供给一个ExampleSelector对象,插入部分示例。
这里我们使用SemanticSimilarityExampleSelector类。该类根据与输入的相似性选择小样本示例。它使用嵌入模型计算输入和小样本示例之间的相似性,然后使用向量数据库执行相似搜索,获取跟输入相似的示例
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 可供选择的示例列表
examples,
# 用于生成嵌入的嵌入类,该嵌入用于衡量语义相似性
OpenAIEmbeddings(openai_api_key="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"),
# 用于存储嵌入和执行相似性搜索的BectorStore类
Chroma,
# 生成的示例数
k = 1
)
question = "乔治·华盛顿的父亲是谁?"
selected_examples = example_selector.select_examples({"question":question})
print(f"最相似的示例:{question}")
for example in selected_examples:
print("\\n")
for k, v in example.items():
print(f"{k}:{v}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3、语言模型
3.1 LLM基础模型
大语言模型(LLMs)是LangChain的核心组件,LangChain本身不提供大语言模型能力,LangChain封装了各种常见的大语言模型,提供一套操作大语言模型的标准接口,方便开发者。目前LangChain封装不少大语言模型,也支持自定义模型,开发者可以自己封装新的模型接口。
目前开源大模型和商业大模型有很多,考虑到成本&模型能力的差异,大家会有不同的选择,同时也可能会经常换模型,但是换模型又不想改动太多业务代码,这个时候LangCain的价值就体现出来了。
- LLM使用例子
LangChain封装了很多大模型接口 (例如:OpenAI, Cohere, Hugging Face等等) - LLM 基类就是面向各类模型接口的统一抽象,里面提供了一些基础的接口设计。前面的例子都是基于openai的LLM的使用例子。
3.2 LangChain聊天模型
聊天模型是语言模型的一种变体。虽然聊天模型在底层使用的也是语言模型,但它们所公开的接口有些不同。它们不是通过 “输入文本,输出文本” API 公开接口,而是通过 “聊天消息” 作为输入和输出的接口,聊天模型的整个交互过程类似互相发送聊天消息的过程。
3.3 自定义模型
目前AI模型领域百家争鸣,LangChain官方也没有对接好所有模型,有时候你需要自定义模型,接入LangChain框架。
自定义 LLM 需要实现以下必要的内容:
- _call方法:它需要接受一个字符串、一些可选的停用词,并返回一个字符串;
它还可以实现第二个可选的内容: - _identifying_params 属性,用于帮助打印此类。应该返回一个字典。
实现一个非常简单的自定义LLM,它只是返回输入的前N个字符
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
# 自定义模型类,实现基础的LLM接口
class CustomLLM(LLM):
n: int
@property
def _llm_type(self) -> str:
# 模型名称
return "custom"
# 在这里实现模型调用
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[: self.n]
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""返回模型信息,类似其他java的tostring函数,返回对象信息"""
return {"n": self.n}
# 实例化模型
llm = CustomLLM(n=10)
# 调用模型
print(llm("This is a foobar thing"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3.4 输出解析器
LLM语言模型输出内容是文本格式,但是开发AI应用的时候,我们希望能拿到的是格式化的内容,例如结果转成目标对象,数组等,方便程序处理。这就需要LangChain提供的输出解析器(Output parser)格式化模型返回的内容。
输出解析器作用是用于是格式化语言模型返回的结果。一个输出解析器必须实现两种必要的方法:
- “get_format_instructions”: 返回一个字符串,其中包含要求语言模型应该返回什么格式内容的提示词。
- “parse”: 将模型返回的内容,解析为目标格式。
3.4.1 Pydantic解析器
from langchain.prompts import PromptTemplate,ChatPromptTemplate,HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel,Field,validator
from typing import List
# 初始化大模型
model_name = "text-davinci-003"
temperature = 0
model = OpenAI(model_name=model_name,
temperature=temperature,
openai_api_key="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")
# 定义模型返回的数据结构
class Joke(BaseModel):
setup: str = Field(description="这是一个笑话的问题")
punchline: str = Field(description="回答解决笑话的问题")
# 您可以使用 Pydantic 轻松添加自定义验证逻辑。
@validator('setup')
def question_ends_with_question_mark(self, field):
if field[-1] != '?':
raise ValueError("问题不正确!")
return field
# 初始化解析器
parser = PydanticOutputParser(pydantic_object=Joke)
# 创建提示词模板,里面包含要求模型返回指定格式的提示词指令,返回格式提示词由parser.get_format_instructions(),解析器提供。
prompt = PromptTemplate(
template="回答用户查询。\\n{format_instructions}\\n{query}\\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# 提供一个查询参数,渲染提示词模板,获取最终的提示词。
joke_query = "讲个笑话。"
_input = prompt.format_prompt(query=joke_query)
# 调用模型
output = model(_input.to_string())
# 解析器解析后的结果,已经转换为前面定义的Joke对象
# Joke(setup='为什么鸡会穿越马路?', punchline='为了到达对面!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
4、本地数据处理
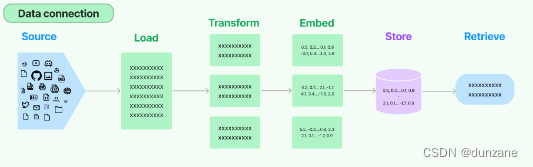
LLM训练出来虽然知道很多信息,但是对于企业私有数据,大语言模型还是不知道的,许多LLM应用程序都需要查询企业私有数据,然后把私有数据作为背景信息拼接到提示词里面,丢给大模型,让大模型根据背景信息回答问题。LangChain提供了加载、转换、存储和查询数据的框架组件。针对私有数据的处理组建包括:
- 文档加载器:支持从不同的来源加载文档数据;
- 文档转换器:拆分文档,将文档转换为Q&A格式,删除冗余文档等;
- 文本嵌入模型:将非结构化文本转换为特征向量;
- 向量存储器:存储和搜索向量数据;
- 检索器:查询你的数据;
4.1 加载文本
使用文档加载器,可以从各类数据源中加载数据,从数据源加载的数据在langchain使用Document对象代表一个文档。Document对象包含一段文本和相关元数据。文档加载器公开了一个“load”方法,用于从配置的数据源加载数据。它们还可选择实现“lazy load”,方便将数据延迟加载到内存中。
from langchain.document_loaders import TextLoader
# 定义文本加载器,读取指定位置下的文本
loader = TextLoader("./index.md")
loader.load()
- 1
- 2
- 3
- 4
- 5
4.2 加载CSV数据
from langchain.document_loaders.csv_loader import CSVLoader
# 定义csv加载器,加载指定csv文件
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv')
data = loader.load()
- 1
- 2
- 3
- 4
- 5
csv指定分隔符、字段
# csv指定分隔符、字段
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
data = loader.load()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同时可以指定一个列来标识文档来源。使用 source_column 参数指定每行创建的文档的来源。否则,file_path 将用作从 CSV 文件创建的所有文档的来源。
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', source_column="Team")
data = loader.load()
- 1
- 2
- 3
4.3 加载JSON数据
- 使用JSONLoader
from langchain.document_loaders import JSONLoader
# 加载json文件的数据
loader = JSONLoader(
file_path='./example_data/facebook_chat.json',
jq_schema='.messages[].content')
data = loader.load()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- JSON Lines file
如果你想从一个JSON Lines文件中加载文档,你需要传递json_lines=True并指定jq_schema,以从单个JSON对象中提取page_content。
loader = JSONLoader(
file_path='./example_data/facebook_chat_messages.jsonl',
jq_schema='.content',
json_lines=True)
data = loader.load()
- 1
- 2
- 3
- 4
- 5
- 6
5、文档处理
LangChain的文档转换器主要作用是分割文本内容,把一个大的文章内容,切割成多个小的内容片段。这么做的目的是因为大模型通常都有提示词长度限制,不能把所有的内容都丢给AI,即使有些大模型允许的提示词长度很大,从成本角度考虑实际应用也不会把那么长的内容传给AI,毕竟内容越长API调用费用越高(就算是本地部署的开源模型,内容越长需要的显存越高,推理越慢)。合理的做法是请求AI模型的时候把相关内容片段作为背景信息和提示词拼接在一起传给AI。
LangChain拥有许多内置的文档转换器,可轻松拆分、组合、过滤文档内容。
5.1 文本处理介绍
当你要处理大段文本时,必须将该文本拆分为块。虽然听起来很简单,但这里存在许多潜在的复杂性。理想情况下,你希望将语义相关的文本片段保持在一起。这里的“语义相关”意味着可能取决于文本类型。从高层次上讲,文本拆分器的工作方式如下:
- 将文本分成小的、语义上有意义的块(通常是句子)。
- 开始将这些小块组合成较大的块,直到达到一定的大小(由某个函数衡量)。
- 一旦达到该大小,将该块作为自己的文本片段,然后开始创建一个新的文本块,其中有一些重叠(以保持块之间的上下文)。
这意味着你可以沿着两个不同的轴自定义文本拆分器:
- 如何来分文本
- 如何衡量块的大小
开始使用文本拆分器:
默认推荐的文本拆分器是RecursiveCharacterTextSplitter。这个文本拆分器接受一个字符列表。它尝试基于第一个字符创建块,但如果任何块太大,则会继续移动到下一个字符,依此类推。默认情况下,它尝试拆分的字符是[“\\n\\n”, “\\n”, " ", “”]。除了控制可以拆分哪些字符外,还可以控制其他几个事项:
- length_function:如何计算块的长度。默认情况下,只计算字符数,但通常在此处传递令牌计数器。
- chunk_size:你的块的最大大小(由长度函数衡量)。
- chunk_overlap:块之间的最大重叠。保留一些重叠可以很好地保持块之间的连续性(例如,执行滑动窗口)。
- add_start_index:是否在元数据中包含每个块在原始文档中的起始位置。
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
# 先加载一个内容比较长的文档内容
with open("data.txt") as f:
data = f.read()
#定义文档拆分器
text_splitter = RecursiveCharacterTextSplitter(
# 设置非常小的块,仅用于演示
chunk_size=100,
chunk_overlap=20,
length_function=len,
add_start_index=True
)
# 指定分割符
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
# 拆分文档
texts = text_splitter.create_documents([data])
print(texts[0])
print(texts[1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
除了拆分文档,我们还可以对文档内容做其他转换操作。使用EmbeddingsRedundantFilter,我们可以识别相似的文档并过滤掉冗余内容。通过像doctran这样的集成,我们可以执行诸如将文档从一种语言翻译成另一种语言,提取所需的属性并将其添加到元数据中,以及将对话转换为一组Q/A格式的文档等操作。
5.2 按Token拆分
语言模型有token限制。你不应超过token限制。因此,将文本拆分成块时,最好计算token数。有许多token处理器(分词器)。在计算文本中的token数时,应使用与语言模型中使用的相同的token处理器。
5.2.1 tiktoken
tiktoken是OpenAI开源的快速BPE分词器。我们可以使用它来估算使用的token。对于OpenAI模型来说,他可能更准确。
- 文本如何拆分:按照传入的字符;
- 块大小如何测量:通过tiktoken分词器
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
# 先加载一个内容比较长的文档内容
with open("data.txt") as f:
data = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size = 600, # 一般设置为多少合适呢?
chunk_overlap=20
)
texts = text_splitter.split_text(data)
print(texts[0])
print("------------------------------")
print(texts[1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.2.2 Hugging Face tokenizer
首先Huggingface中有很多分词器,我们使用huggingface分词中的GPT2TokenizerFast来计算文本长度的token数。
from transformers import GPT2TokenizerFast
from langchain.text_splitter import CharacterTextSplitter
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# 定义文本拆分器,拆分文本
text_splitter = CharacterTextSplitter.from_huggingface_tokenizer(
tokenizer, chunk_size=512, chunk_overlap=128
)
texts = text_splitter.split_text(state_of_the_union)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实际操作中,chunk_size和overlap怎么设置呢?
- 针对chunk_size:指定每个分块的最大长度(以token数为单位)。将长文本分成多个不超过这个长度的块。通常可以设置为模型的最大序列长度(如512或1024)。
- chunk_overlap: 指定相邻两个分块之间的重叠tokens数。这样可以避免跨块边界时对上下文的丢失。通常设置为一个较小的正值,如64或128。
具体的设置取决于:
- 模型的最大序列长度限制
- 输入文本的长度分布
- 对上下文的需求程度
如果输入文本普遍不太长,可以将chunk_size设置为模型的最大序列长度,chunk_overlap设置为一个较小值,如64。如果输入文本较长,chunk_size可以适当减小一些,如512,chunk_overlap相应增加,如128,以获得更多的上下文重叠。一般而言,chunk_overlap的值不应超过chunk_size的1/4左右,以避免过多的冗余。可以根据实际任务的要求适当调整这两个参数,在获取足够上下文和控制计算量之间取得平衡。
6、文本处理
6.1 文本嵌入模型
6.2 向量存储
在这里我们以Qdrant为例

