- 1使用安装包安装飞桨寒武纪版本@启智(未通过)
- 2Java:ArrayList详解_arraylist类用数组实现了什么类和什么类接口
- 3C# NPOI Word操作_npoi操作word
- 4基于SpringBoot+Vue+协同过滤的就业推荐系统设计和实现(源码+LW+部署讲解)
- 5Spring Boot 整合 Spring AI 实现项目接入ChatGPT(OpenAl的调用,开发属于你自己Al,体验Al的乐趣)本文仅讲解聊天方式的实现,关于gpt的其他东西,参考接下来的文章_springboot 扩展springai
- 6Web 3超入门—踏上Web 3.0的征程:超入门探索指南【文末送书】_web3.0入门教程
- 7vue中后端做Excel导出功能返回数据流前端如何做处理_vue后端做excel导出功能返回数据流前端的处理操
- 8数据仓库重点_数据仓库dm层
- 9【自动化测试】Pytest框架 —— Pytest测试框架介绍_pytest框架详解(1)_关于pytest框架,以下说法正确的是
- 10常见的深度学习技术
BART: Bidirectional and Auto-Regressive Transformers_bart和bert
赞
踩
1 简介
BART: Bidirectional and Auto-Regressive Transformers.
本文根据2019年《BART: Denoising Sequence-to-Sequence Pre-training for Natural
Language Generation, Translation, and Comprehension》翻译总结。
BERT是双向encoder,GPT是left-to-right decoder。BART可以说是既有encoder,又有decoder,即BERT和GPT结合体。如下图:

BART输入的损坏文本可以使用任意噪声函数,然后模型来学习回复原始文本。所以BART是一个去噪autoencoder。
BART是一个sequence-to-sequence model,包括双向encoder(接受损坏的文本)和left-to-right 自回归(autoregressive)decoder。
BART和BERT的差异是:(1)decoder的每一层会额外的对encoder的最后隐藏层进行cross-attention;(2)BERT在word预测前使用了feed-forward network,而BART没有使用。总体来说,BART比BERT多10%左右的参数。
BART在Discriminative Tasks上,达到了RoBERTa类似的表现;在text generation tasks.取得了new state-of-the-art结果。
2 预训练BART
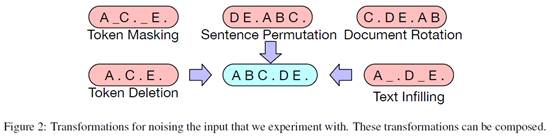
各种不同的输入情况:
Text Infilling:文本片段的一部分是被一个单独的[mask]替换,片段的长度从0到3等。
Sentence Permutation:根据句号分割句子,重新排列组合。
Document Rotation:随机找到一个token作为开始位置。
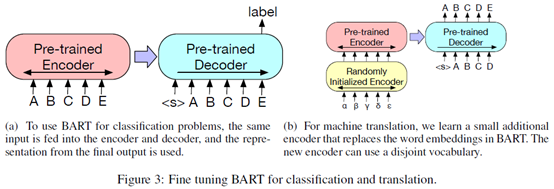
3 Fine-tuning BART
下面是分类和翻译的模型示例。翻译任务增加了一个随机初始化的encoder。
4 实验结果
可以看到test infilling的效果不错。其中Language Model(类似GPT),Permuted Language Model(基于XLNet)

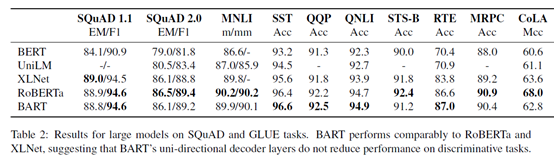
4.1 Discriminative Tasks
BART可以达到RoBERTa的效果。
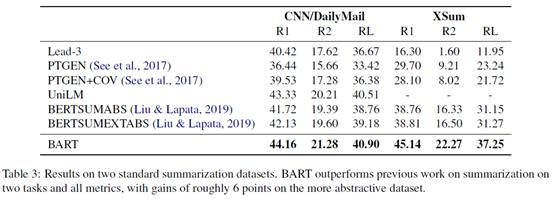
4.2 Generation Tasks
BART表现很好。