
- 1分组UITableVie
- 2tomcat+myeclipse+mysql环境搭建_搭建myeclipse+tomcat+mysql网站开发环境
- 3TCP/IP协议以及UDP(超详细,看这一篇就够了)_tcp/ip udp
- 4python import re_彻底搞懂Python 中的 import 与 from import
- 5分布式文件存储FastDFS_分布式文件存储选型 fastdfs
- 6RecylerView布局管理器LayoutManager(详解)_recyclerview layoutmanager
- 7重要开源协议的比较(BSD,Apache,GPL,LGPL,MIT) – 整理_bsd3
- 8python class类里给列表排序_Python sorted对list和dict排序
- 9python 数据库框架peewee_Python框架--Peewee使用
- 1023年最新版pycharm找不到conda可执行文件解决办法
机器学习:数据驱动的科学
赞
踩
引言:传统上,计算机会按照我们输入的指令一步步执行。而机器学习却是通过输入数据而不是指令来进行各种工作。
本文选自《深入浅出深度学习:原理剖析与Python实践》。
机器学习,也被称为统计机器学习,是人工智能领域的一个分支,其基本思想是基于数据构建统计模型,并利用模型对数据进行分析和预测的一门学科。
传统上,如果想让计算机工作,我们会编写一段指令,然后让计算机遵照这个指令一步一步执行下去。而机器学习则是采用另一种解决问题的思路,机器学习解决问题的方式不是通过输入指令逻辑,而是通过输入的数据,也就是说,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。
机器学习最基本的做法是使用算法来解析数据,从数据中学习到规律,并掌握这种规律,然后对真实世界中的事件做出决策或预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习的核心是使用大量的数据来训练,通过各种算法从数据中学习如何完成任务。机器学习直接来源于早期的人工智能领域,在模式识别和计算机学习理论的研究中逐渐发展,并最终形成一门新的学科。与人工智能类似,机器学习也是一个跨学科的领域,涉及多个基础学科,包括统计学、线性代数和数值计算等。
机器学习是基于训练数据构建统计模型,从而使计算机具有对新数据进行预测和分析的能力,机器学习方法按其实现的目标不同,可以分为:监督学习、无监督学习和强化学习。
监督学习(Supervised Learning):监督学习使用带有标签的训练数据集进行训练,输入的训练数据由物体的特征向量(输入)和物体的标签(输出)两部分构成,其中,若输出的标签是一个连续的值,则称为回归监督学习;若输出标签是一个离散的值,则称为分类监督学习。
监督学习涉及两个方面的工作:首先,根据提供的训练数据,选择一种合适的模型进行训练,直至模型的训练收敛。常见的监督学习模型包括:Logistic回归、决策树、SVM(Support Vector Machines,支持向量机)、KNN、朴素贝叶斯等。下图展示的是一个水果分类的例子,每一个样本数据的输入是由物体的特征构成的特征向量,如物体的颜色、大小、形状等,输出的是物体的类别,如苹果、葡萄、香蕉等。
监督学习模型训练,算法利用训练数据提供的特征信息,如颜色、大小、形状等,构建概率模型p(y|x)或非概率模型y=f(x)
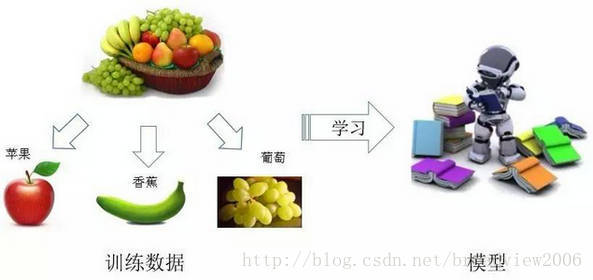
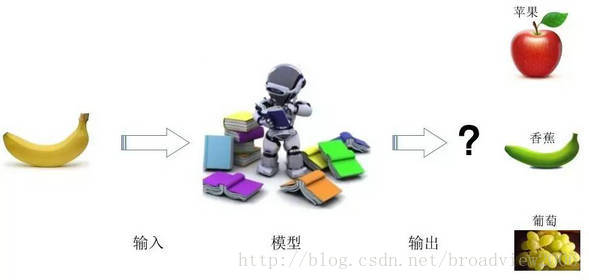
其次,当模型训练完毕,就可以把新的输入数据代入模型,模型将根据新数据的特征信息,找出最符合这种特征的输出结果,其过程如下。
模型预测
无监督学习(Unsupervised learning):无监督学习的训练样本数据没有任何的标签和输出,其目的是对原始数据结构进行深入分析,找出数据间存在的规律与关系。典型的无监督学习任务包括:聚类、降维、特征提取等。
两种常见的无监督学习,(a)数据聚类,(b)数据降维
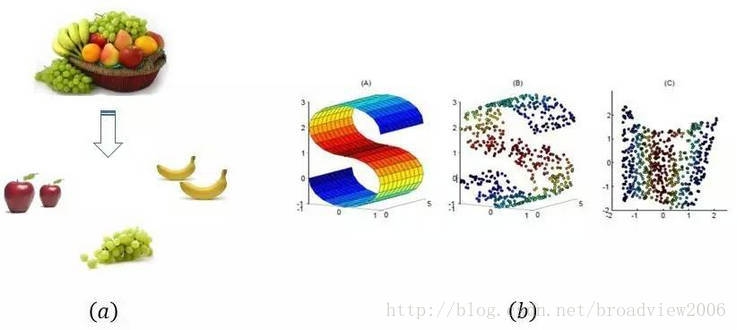
虽然监督学习的准确率更高,但在现实生活中,我们获取的大量数据一般是没有标签数据的,因此,我们不得不诉诸于无监督学习,但传统的无监督学习方法在特征提取上并不令人满意,而深度学习则被证明具有强大的无监督学习能力,特别是在计算机视觉领域,运用深度学习技术所达到的效果更是要远优于传统的机器学习。
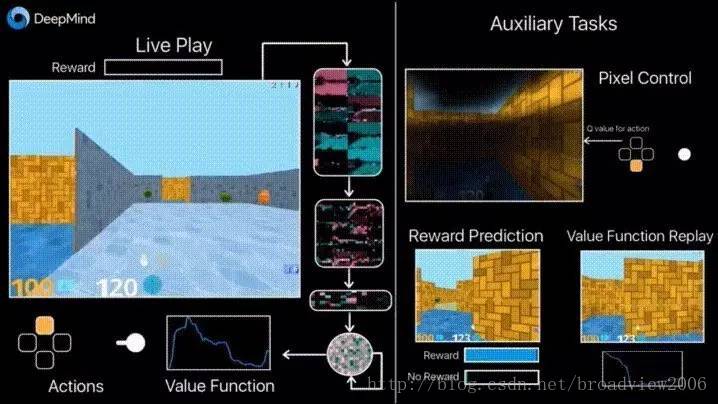
强化学习(reinforcement learning):强化学习也称为增强学习,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
强化学习与前面的监督学习、无监督学习之间的区别在于,它并不需要出现正确的输入输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索未知的领域和遵从现有知识之间找到平衡,它的学习过程是一个从实际环境中不断学习积累,不断进化的过程。因此,强化学习更接近生物学习的本质,也是有望让机器获得通用智能的一项技术。
DeepMind利用强化学习技术在迷宫游戏中执行搜索任务(图片摘自网络)
本文选自《深入浅出深度学习:原理剖析与Python实践》,点此链接可在博文视点官网查看此书。


