
- 1Qt5下载安装及环境变量配置详解_qt5安装教程及配置环境变量
- 2《游戏引擎架构》笔记十四
- 3input name[] js取值_js 获取input中 name的值
- 4Spring Boot + vue-element 开发个人博客项目实战教程(八、用户中心功能实现)_springboot项目使用 element-tiptap
- 5(附源码)springboot高校学生健康打卡系统的设计与实现 毕业设计021009_使用自选的数据库,在班级网站中增加健康打卡功能,创建rj20数据库,在库中创建自己
- 6ant-design tree 设置默认选中状态_win10 默认win快捷键汇总:助你提高使用效率
- 7【100%通过率】华为OD机试真题 Java 实现【不爱施肥的小布】【2023 Q1 | 100分】_真题-不爱施肥的小布测试用例
- 8Unity-HDRP-Sense-4
- 9英语单词词根词缀和词性转换_欧+美+亚+洲+a+v
- 10elementUI el-table表格列排序的三种方法_el-table 排序
使用深度学习的图像分割(综述)_第一个计算边界框坐标,第二个计算关联的类,第三个计算二进制掩膜以分割对象。mask
赞
踩
文章目录
前言
这是Image Segmentation Using Deep Learning :A Survey这篇英文文献的中文翻译,在这篇翻译文章中作者用不同颜色的文字对一些专业名词和本人不清楚的地方进行了描述,希望对需要这篇文献中文翻译的同志有所帮助。文献综述可以帮助相关专业的学习者快速熟悉相关话题的研究,以方便其检索已有的研究成果。本人也是一名深度学习领域的初学者,关于文中不当的地方还请各位多多包含。有什么好的建议或者意见欢迎评论区留言。本人在后续学习过程中也会将遇到的问题和经历分享给大家,希望对后来者有所帮助。最后希望各位读者能够进行友善的交流,谢谢大家。
摘要
图像分割是图像处理和计算机视觉的一个关键课题,可应用于场景理解、医学图像分析、机器人感知、视频监控、增强现实和图像压缩等。在文献中已经发展了各种图像分割算法。最近,由于深度学习模型在广泛的视觉应用中取得了成功,有大量的工作旨在开发使用深度学习模型的图像分割方法。在本调查中,我们对本文撰写时的文献进行了全面回顾,涵盖了语义和实例级分割的广泛先驱工作,包括全卷积像素标记网络、编码器-解码器架构、基于多尺度和金字塔的方法、循环网络、视觉注意模型和对抗环境下的生成模型。我们研究了这些深度学习模型的相似性、优势和挑战,研究了最广泛使用的数据集,报告了性能,并讨论了该领域未来有前途的研究方向。
关键词:图像分割,深度学习,卷积神经网络,编码器-解码器模型,循环模型,生成模型,语义分割,实例分割,医学图像分割。
1.引言
图像分割是许多视觉理解系统的重要组成部分。它涉及到将图像(或视频帧)划分为多个段或对象[1]。分割在广泛的应用中起着核心作用,包括医学图像分析(如肿瘤边界提取和组织体积测量)、自动驾驶汽车(如导航表面和行人检测)、视频监控和增强现实。许多图像分割算法已经在文献中,从最早的方法,如阈值[3],基于直方图的捆绑,注册[4],k均值聚类[5],流域[6],更先进的算法如主动轮廓[7],图削减[8],条件和马尔可夫随机场[9],基于稀疏的[10]- [11]方法。然而,在过去的几年里,深度学习(DL)模型已经产生了新一代的图像分割模型,它们具有显著的性能改进——通常在流行的基准测试上达到最高的准确率——这导致了该领域的范式转变。例如,图1展示了一个流行的深度学习模型DeepLabv3 [12]的图像分割输出。

图像分割可以表示为带有语义标签的像素的分类问题(语义分割)或单个对象的分割(实例分割)。语义分割对所有图像像素使用一组对象类别(如人、车、树、天空)进行像素级标记,因此通常比图像分类更难,图像分类预测整个图像的单一标签。实例分割通过检测和描述图像中的每个感兴趣的对象(例如,对个人的分割),进一步扩展了语义分割的范围。
我们的调查涵盖了关于图像分割的最新文献,并讨论了截至2019年提出的100多种基于深度学习的分割方法。我们提供了一个全面的回顾和不同见解在这些方法的各个方面,包括训练数据、网络架构的选择、损失函数、训练策略及其关键贡献。我们对所回顾的方法的性能进行了比较总结,并讨论了基于深度学习的图像分割模型的几个挑战和潜在的未来方向。
我们将基于深度学习的工作根据其主要技术贡献分为以下几类:
1)全卷积网络
2)卷积模型与图形模型
3)基于编码器解码器的模型
4)基于多尺度金字塔网络的模型
5)基于R-CNN的模型(用于实例分割)
6)扩张卷积模型和DeepLab家族
7)基于循环神经网络的模型
8)引起的模型
9)生成模型和对抗训练
10)具有活动轮廓模型的卷积模型
11)其他模型
本调查论文的一些关键贡献可以总结如下:
(1)本调查涵盖了目前关于分割问题的相关文献,并概述了截至2019年提出的100多种分割算法,分为10类。
(2)我们对使用深度学习的分割算法的不同方面进行了全面的回顾和深刻的分析,包括训练数据、网络架构的选择、损失函数、训练策略和它们的关键贡献。
(3)我们提供了大约20个流行的图像分割数据集的概述,分为2D、2.5D(RGBD)和3D图像。
(4)在流行的基准测试上,我们提供了对分割方法的属性和性能的比较总结。
(5)我们为基于深度学习的图像分割提供了几个挑战和潜在的未来发展方向。
本调查的其余部分组织如下:
第2节提供了流行的深度神经网络架构的概述,这些架构作为许多现代分割算法的主干。第3节提供了最重要的最先进的基于深度学习的分割模型的全面概述,到2020年,超过100个。我们也在这里讨论他们的优势和以前的贡献。第4节回顾了一些最流行的图像分割数据集及其特点。第5.1节回顾了用于评估基于深度学习的分割模型的常用指标。在第5.2节中,我们报告了这些模型的定量结果和实验性能。在第6节中,我们将讨论基于深度学习的分割方法的主要挑战和未来的发展方向。最后,我们在第7节中提出我们的结论。
DeepLab系列算法是谷歌团队提出的一系列语义分割算法
2.深度神经网络的概述
本节概述了计算机视觉领域使用的一些最突出的深度学习架构,包括卷积神经网络(CNNs)[13]、递归神经网络(RNNs)和长短期记忆(LSTM)[14]、编码-解码器[15]和生成对抗网络(GANs)[16]。近年来,随着深度学习的普及,其他一些深度神经结构已经被提出,如变压器、胶囊网络、门控循环单元、空间变压器网络等,这些将在这里不讨论。
值得一提的是,在某些情况下DL-model可以从头训练新应用程序/数据集(假设足够数量的标记训练数据),但在许多情况下没有足够的标记数据可以从头开始训练模型,可以使用迁移学习来解决这个问题。在迁移学习中,在一个任务上训练的模型被重新用在另一个(相关的)任务上,通常是通过对新任务的一些适应过程。例如,我们可以想象将在ImageNet上训练的图像分类模型适应于不同的任务,如纹理分类或人脸识别。在图像分割的情况下,许多人使用在ImageNet(比大多数图像分割数据集更大的数据集)上训练模型,如编码了网络的一部分,并从这些初始权重重新训练他们的模型。这里的假设是,这些预先训练的模型应该能够捕获分割所需的图像的语义信息,从而使它们能够用更少标记的标记样本训练模型。
迁移学习,通俗的讲就是将别人在上万张甚至几十万上百万张数据集上训练好的网络模型(包括权重值,各种参数及超参数)下载下来应用在我们自己的项目上,只需要对模型做出微调就可以满足我们的需求
2.1卷积神经网络(CNNs)
cnn是深度学习领域中最成功和应用最广泛的架构之一,特别是在计算机视觉任务中。cnn最初是由Fukushiman(福岛)在他关于“新神经”[17]的开创性论文中提出的,基于Hubel和Wiesel提出的视觉皮层的层次接受场模型。随后,Waibel等人[18]引入了时间接受域共享权重的CNN和音素识别反向传播训练,LeCun等人[13]开发了用于文档识别的CNN架构(图2)。
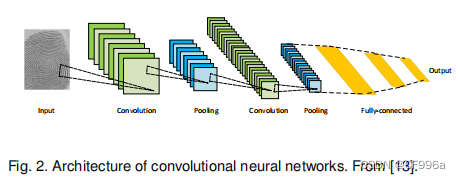
cnn主要由三种类型的层组成: i)卷积层,其中对权值的核(或滤波器)进行卷积以提取特征;ii)非线性层,对特征映射(通常是元素)应用激活函数,以便网络对非线性函数建模;iii)池化层,用一些统计信息(均值、最大等)替换特征映射的一个小邻域。关于邻域,降低了空间分辨率。各层的单元是局部连接的;也就是说,每个单元接收来自前一层单元的一个小邻域的加权输入。通过堆叠层形成多分辨率的金字塔,更高层次的层从越来越宽的接受域学习特征。cnn的主要计算优势是,一层中的所有接受域都共享权值,导致参数的数量明显少于全连接的神经网络。一些最著名的CNN架构包括: AlexNet [19],VGGNet [20],ResNet [21],[22] GoogLeNet[23],和, MobileNet[23],DenseNet [24]。
权值共享:卷积核的参数称为权值,我们使用一个卷积核在遍历一幅图像时,对于整幅图像的不同部分而言它被同一个卷积核进行卷积提取特征,因此权值是共享的。CNN由卷积层-非线性层(激活函数)-池化层连接组成
2.2递归神经网络(RNNs)和LSTM
RNNs [25]被广泛用于处理顺序数据,如语音、文本、视频和时间序列,其中任何给定时间/位置的数据都取决于以前遇到的数据。在每个时间戳中,模型收集来自当前时间Xi的输入和来自上一步hi−1的隐藏状态,并输出一个目标值和一个新的隐藏状态(图3)。
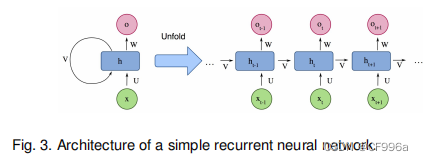
rnn对于长序列通常存在问题,因为它们不能在许多现实应用中捕获长期依赖关系(尽管它们没有表现出理论在这方面的限制),并经常遭受梯度消失或爆炸的问题。然而,一种称为长短期记忆(LSTM)[14]的rnn是为了避免这些问题。LSTM体系结构(图4)包括三个门(输入门、输出门、遗忘门),它们调节进出内存单元的信息流,并在任意时间间隔内存储值。
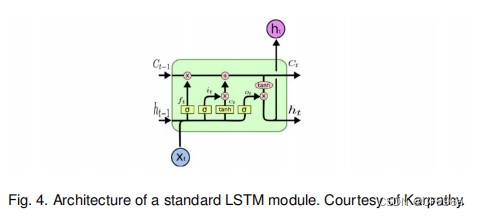
RNN网络可以理解为在每个时间节点都有两个输入两个输出,两个输入分别是输入层的输入和来自上一个时间节点的隐藏层的输出,两个输出分别是输出层的输出和隐藏层的输出,Fig3的U,W,V分别是输入层,隐藏层,输出层的权重矩阵。这样每个隐藏层都会有它前面的所有输入层的信息影响它的输出。LSTM:解决RNN梯度爆炸的问题,它可以看成每个记忆单元(cell)有三个输入三个输出,遗忘门ft控制上一时刻的内部状态Ct-1需要遗忘多少信息,输入门it控制当前时刻的候选状态Ct有多少信息需要保存,输出门Ot控制当前时刻的内部状态Ct有多少信息需要输出给外部状态ht。
2.3编码器-解码器和自动编码器模型
编码器-解码器模型是一组模型,它学习通过两阶段网络将数据点从输入域映射到输出域:编码器由编码函数z = f (x)表示,该编码器将输入压缩为潜在空间表示;解码器y=g(z)的目的是预测潜在空间表示[15],[26]的输出。这里的潜在表示本质上是指一个特征(向量)表示,它能够捕获对预测输出有用的输入的底层语义信息。这些模型在图像到图像的转换问题以及NLP中的序列到序列模型中都非常流行。图5展示了一个简单的编码器-解码器模型的方框图。这些模型通常通过最小化重建损失L(y,yˆ)来训练,它测量真实输出y和随后的重建yˆ之间的差异。这里的输出可以是图像的增强版本(如图像去模糊,或超分辨率),或分割地图。自动编码器是编码器-解码器模型的特殊情况,其中的输入和输出是相同的。
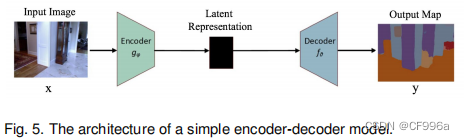
编码器-解码器:该模型被应用于机器翻译,简单的理解就是编码器负责将我们的输入处理成一种计算机或者模型容易处理的一种中间变量,解码器负责将模型处理后的这种中间变量处理成我们想要的形式。
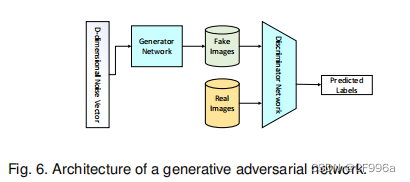
2.4生成式对抗性网络(GANs)
GANs是一个较新的深度学习模型[16]家族。它们由两个网络组成,一个生成器和一个鉴别器(图6)。传统GAN中的生成网络G = z → y学习从噪声z(具有先验分布)到目标分布y的映射,这与“真实”样本相似。鉴别器网络D试图区分生成的样本(“伪造的”)和“真实的”样本。GAN损失函数可以写成
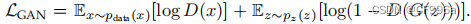
。我们可以把GAN看作G和D之间的极大极小博弈,其中D试图使其区分假样本和真实样本的分类误差最小化,从而使损失函数最大化,G试图使鉴别器网络的误差最大化,从而使损失函数最小化。在实践中,这个函数可能无法提供足够的梯度来有效地训练G,特别是在初始阶段(当D可以很容易地区分假样本和真实样本)。训练模型后,训练后的生成器模型为G∗==minGmaxD LGAN在实践中,该函数可能不能提供足够的梯度来有效训练G,特别是初始训练(当D可以很容易地区分假样本和真实样本时)。代替最小化Ez∼pz(z)[log(1−D(G(z)))],一个可能的解决方案是训练它最大化Ez∼pz(z)[log(D(G(z)))]
自GANs发明以来,研究人员一直在努力用几种方法来改进/修改GANs。例如,Radford等人[27]提出了一个卷积GAN模型,该模型在用于图像生成时比全连接网络效果更好。Mirza [28]提出了一种条件GAN模型,该模型可以生成基于类标签条件的图像,使人们能够生成具有指定标签的样本。Arjovsky等人[29]提出了一种新的基于瓦瑟斯坦(a.k.a.地球移动的距离),以更好地估计距离的情况下,真实和生成的样本的分布是不重叠的(因此库背-雷伯散度不是一个很好的测量距离)。有关其他作品,我们请读者参考[30]
GAN:生成对抗网络有两个重要部分生成器和判别器,step1固定判别器,训练生成器;step2固定生成器,训练判别器。生成器生成内容判别器判断真假,相互对抗达到纳什均衡。
3.基于DL的图像分割模型
本节详细回顾了截至2019年提出的100多种基于深度学习的分割方法,这些方法分为10个类别(基于它们的模型架构)。值得一提的是,在这些作品中有一些部分是常见的,如有编码器和解码器部分,跳跃连接,多尺度分析,以及最近使用的扩展卷积。正因为如此,很难提到每个作品的独特贡献,但更容易根据它们的底层架构贡献将它们进行分组。除了对这些模型进行架构分类外,我们还可以根据分割目标将它们分为:语义模型、实例模型、泛视模型和深度分割类别。但由于这些任务在工作量方面存在很大差异,我们决定遵循架构分组。
3.1全卷积网络
Long等人[31]提出了第一个深度学习的工作,使用全卷积网络Fully Convolutionnal Network(FCN)。一个FCN(图7)只包含卷积层,这使它能够拍摄任意大小的图像,并生成相同大小的分割地图。作者修改了现有的CNN架构,如VGG16和GoogLeNet,以管理非固定大小的输入和输出,通过用全卷积层替换所有完全连接的层。因此,该模型输出了一个空间分割图,而不是分类分数。
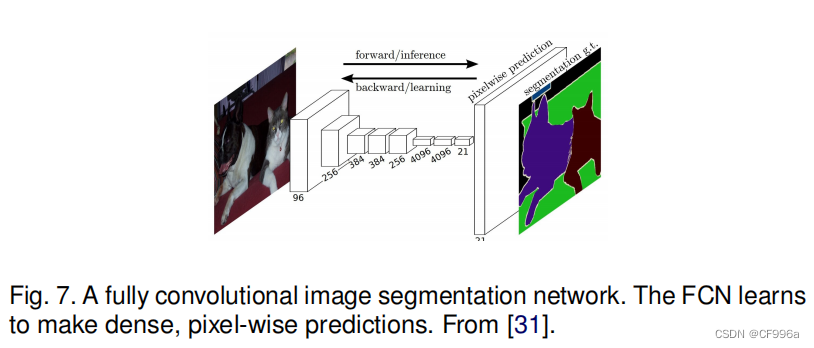
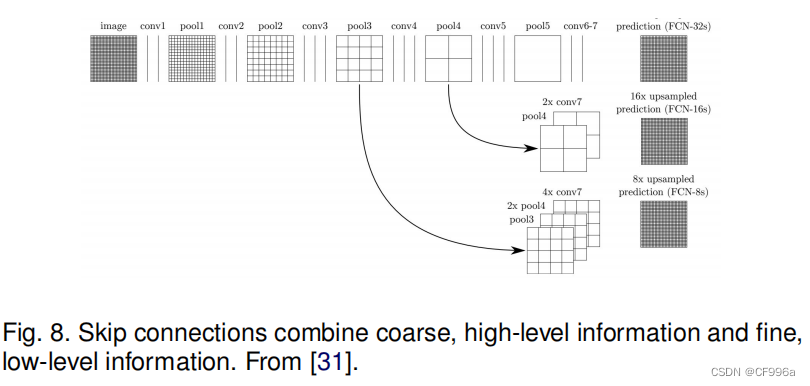
通过使用跳跃连接的功能使特征图从模型的最后一层上采样与早期层的特征图融合(图8),模型结合语义信息(从深、粗层)和外观信息(从浅、细层),以产生准确和详细的分割。该模型在PASCAL VOC、NYUDv2和SIFT Flow上进行了测试,并取得了最先进的分割性能。
这项工作被认为是图像分割的一个里程碑,证明了深度网络可以端到端训练进行语义分割。然而,尽管传统的FCN模型流行和有效,传统的FCN模型也有一些局限性——它不够快,无法进行实时推理,它没有以有效的方式考虑全局上下文信息,也不容易转移到3D图像上。一些努力已经试图克服FCN的一些局限性。
例如,Liu等人[32] 提出了一个名为ParseNet的模型,以解决FCN的一个问题——忽略全局上下文信息。ParseNet通过使用层的平均特性来增强每个位置的特征,向FCNs添加全局上下文。一个图层的特征映射被合并起来整个图像会产生一个上下文向量。这个上下文向量被规范化并未合并,以产生与初始向量具有相同大小的新特征图。然后将这些特征映射连接起来。简而言之,ParseNet是一个FCN,它用所描述的模块取代了卷积层(图9)。

FCNs已被应用于多种分割问题,如脑肿瘤分割[33]、实例感知语义分割[34]、皮肤损伤分割[35]和虹膜分割[36]。
全局上下文信息:语义上下文(可能性),空间上下文(位置),尺度上下文(尺寸),上下文就是图片中某个区域与周围区域的关系。
3.2具有图形模型的卷积模型
如前所述,FCN忽略了潜在的有用的场景级语义上下文。为了集成更多的上下文,一些方法将概率图形模型,如条件随机场(CRFs)和马尔可夫随机场(MRFs),合并到DL架构中。
Chen等人[37 ]提出了一种基于cnn和全连接CRFs组合的语义分割算法(图10)。他们表明,来自深度最后一层的cnn的响应没有足够地定位到精确的目标分割(由于不变性使cnn适合于高级任务,如分类)。为了克服深度CNN的差定位特性,他们将最终CNN层的响应与一个全连接的CRF结合起来。他们表明,他们的模型能够以比以前的方法更高的精度定位段边界。
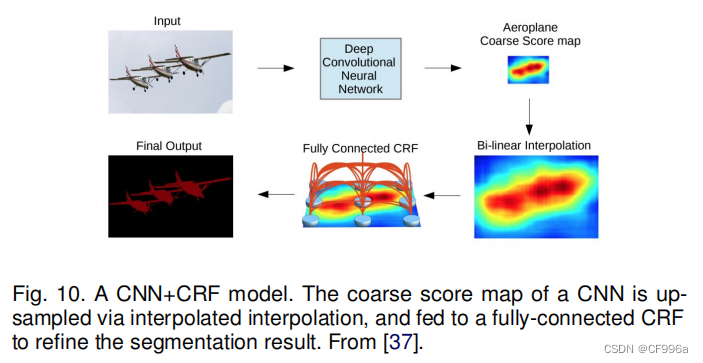
Schwing和Urtasun [38]提出了一种全连接的深度结构网络。他们提出了一种联合训练cnn和全连接crf进行语义图像分割的方法,并在具有挑战性的PASCAL VOC 2012数据集上取得了令人鼓舞的结果。在[39]中,Zheng等人提出了一种类似的语义分割方法,将CRF与CNN集成起来。
在另一项相关工作中,Lin等人[40]提出了一种基于上下文深度CRFs的有效语义分割算法。他们探索了“patch-patch”的背景(在图像区域之间)和“补丁-背景”上下文,通过使用上下文信息来改进语义分割。
Liu等人[41] 提出了一种语义分割算法,该算法将丰富的信息整合到mrf中,包括高阶关系和标签上下文的混合。与之前使用迭代算法优化mrf的工作不同,他们提出了一个CNN模型,即解析网络,它能够在单次向前传递中实现确定性的端到端计算。
条件随机场CRF:是一种鉴别式机率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或生物序列。马尔可夫随机场MRF:是指下一个时间点的值只与当前值有关系,与以前没有关系,即未来决定于现在而不是过去
3.3基于编码解码器的模型
另一个流行的图像分割深度模型家族是基于卷积编码器-解码器体系结构。大多数基于dl的分割工作都使用了某种编码器-解码器模型。我们将这些工作分为两类,用于一般分割的解码器模型和用于医学图像的分割(以更好地区分应用)。
3.3.1用于一般分割的编码器-解码器模型
Noh等人。[42]发表了一篇关于基于反褶积的语义分割的早期论文(a.k.a.转置卷积他们的模型(图11)由两部分组成,一个是使用VGG 16层网络中采用的卷积层的编码器,另一个是以特征向量作为输入,生成像素级类概率图。反褶积网络由反褶积层和非池化层组成,它们可以识别像素级的类标签并预测分割掩模。
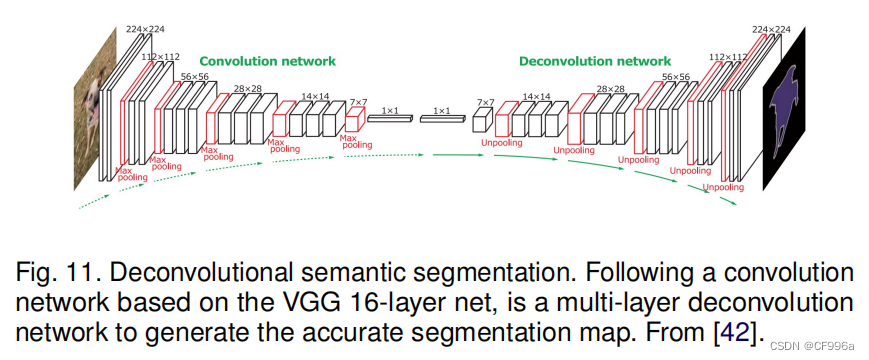
该网络在PASCAL VOC 2012数据集上取得了良好的性能,并在当时没有外部数据训练的方法中获得了最好的准确率(72.5%)。
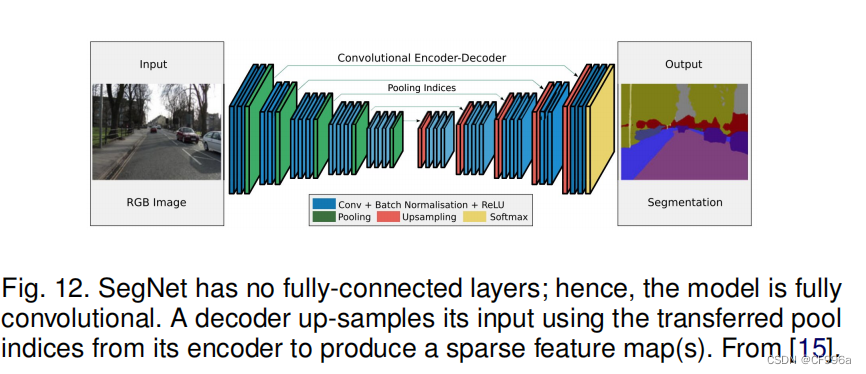
在另一项被称为SegNet的工作中,巴德里纳拉亚南等人[15]提出了一种用于图像分割的卷积编码解码器架构(图12)。与反褶积网络类似,SegNet的核心可训练分割引擎由一个与VGG16网络中的13个卷积层拓扑相同的编码器网络,以及一个相应的解码器网络,然后是一个像素级分类层。SegNet的主要新颖之处在于解码器对其低分辨率输入特征图进行上采样;具体来说,它使用相应编码器的最大池化步骤中计算的池化索引来进行非线性上采样。这就消除了学习上样本的需要。然后将(稀疏的)向上采样的映射进行卷积可训练的过滤器来生成密集的特征图。SegNet在可训练参数的数量上也明显小于其他竞争架构。同一作者还提出了一个SegNet的贝叶斯版本,以建模用于场景分割[43]的卷积编码器-解码器网络固有的不确定性。
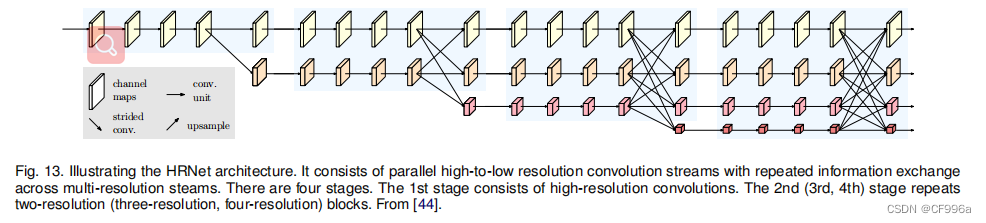
这一类中的另一个流行模型是最近开发的分割网络,高分辨率网络(HRNet)[44]图13。除了像在DeConvNet、SegNet、U-Net和V-Net中那样恢复高分辨率表示之外,HRNet通过并行连接高分辨率到低分辨率的卷积流,并跨分辨率重复交换信息,通过编码过程维护高分辨率表示。最近许多关于语义分割的工作都利用HRNet作为主干,通过利用上下文模型,如自我注意及其扩展。其他一些工作采用转置卷积,或编码解码器进行图像分割,如堆叠反卷积网络(SDN)[45],Linknet [46],W-Net [47],和局部敏感反褶积网络用于RGBD分割[48]。基于编码器-解码器的模型的一个限制是,由于在编码过程中丢失了高分辨率表示,导致图像的细粒度信息的丢失。然而,这个问题在一些最近的架构中得到了解决,如HR-Net。
转置卷积:转置卷积不是卷积的逆运算,在深度学习中DeConvolution指的是转置卷积。当填充为p步幅为s时
- 在行和列之间插入s-1行或列
- 将输入填充k-p-1(k是核窗口)也就是正常卷积里面的padding
- 将核矩阵上下、左右翻转
- 然后做正常的卷积
输入输出尺寸换算: - 输入高(宽)为n,核为k,填充p,步幅s
- 转置卷积:n’ = sn + k - 2p - s
- 卷积:n’ = (n - k + 2p) / s + 1
3.3.2医学和生物医学图像分割的编码器-解码器模型
有几种最初用于医学/生物医学图像分割的模型,它们受到FCN和编码-解码器模型的启发。U-Net [49]和V-Net [50]是两种著名的这样的架构,它们现在也在医疗领域之外使用。
罗内伯格等人[49]提出了用于分割生物显微镜图像的U-Net。他们的网络和训练策略依赖于使用数据增强来有效地从很少的注释图像中学习。U-Net架构(图14)包括两部分,一个是用来捕获上下文的收缩路径,另一个是能够实现精确定位的对称扩展路径。降采样或收缩部分有一个类似FCN的架构,可以通过3×3卷积提取特征。上采样或扩展部分使用上卷积(或反褶积),减少特征映射的数量,同时增加它们的维度。将网络下采样部分的特征映射复制到上采样部分,以避免丢失模式信息。最后,1×1卷积处理特征映射,生成分割映射,对每个映射进行分类输入图像的像素。U-Net对30张透射光镜图像进行了训练,并成功地赢得了2015年的ISBI细胞跟踪挑战。。
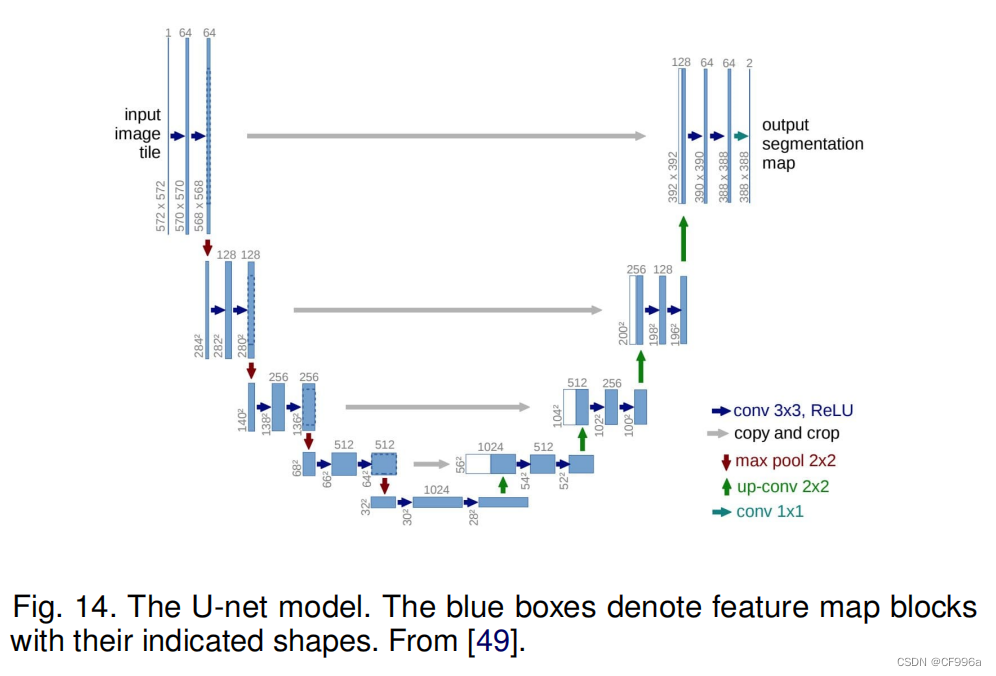
U-Net的各种扩展已经为不同类型的图像开发出了各种扩展。例如,Cicek [51]提出了一个针对三维图像的U-Net架构。Zhou等人[52]开发了一个嵌套式的U-Net体系结构。U-Net也被应用于其他各种问题。例如,Zhang等人开发了一种基于U-Net的道路分割/提取算法。
V-Net是另一个著名的、基于FCN的模型,由米勒塔里等人a.[50]提出,用于三维医学图像分割。在模型训练中,他们引入了一种新的基于骰子系数的目标函数,使模型能够处理前景和背景中体素数量之间存在强烈不平衡的情况。对前列腺MRI体积进行端到端训练,并学会同时预测整个体积的分割。其他一些关于医学图像分割的相关工作包括用于从胸部CT图像中快速和自动分割肺叶的渐进密集V-net(PDV-Net)等人,以及用于病变分割[54]的3D-CNN编码器。
3.4基于多尺度和金字塔网络的模型
多尺度分析是图像处理中的一个相当古老的思想,已被应用于各种神经网络架构中。这类最突出的模型之一是Lin等人[55]提出的特征金字塔网络(FPN),它主要用于目标检测开发,但也应用于分割。利用固有的深度cnn的多尺度金字塔层次来构建特征金字塔的边际额外成本。为了合并低分辨率和高分辨率的特征,FPN由一个自下而上的路径、一个自上而下的路径和横向连接组成。然后通过3×3卷积处理,产生每个阶段的输出。最后,自上而下路径的每个阶段生成一个预测来检测一个对象。对于图像分割,作者使用两个多层感知器(MLPs),来生成掩模。
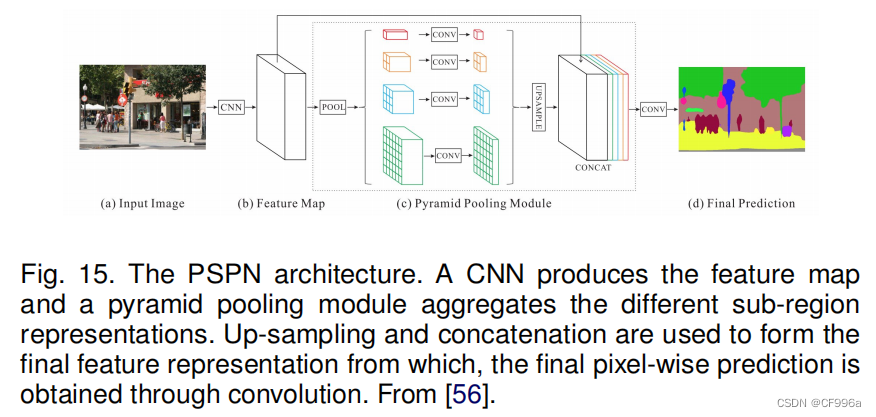
Zhao等人[56]开发了金字塔场景解析网络(PSPN),这是一个多尺度的网络,可以更好地学习场景的全局上下文表示(图15)。使用残差网络(ResNet)作为特征提取器,利用扩展网络,从输入图像中提取不同的模式。然后将这些特征映射输入一个金字塔池模块,以区分不同尺度的模式。它们被集中在四个不同的尺度上,每个尺度对应一个金字塔层,并由一个1×1的卷积层处理,以减少它们的尺寸。金字塔层的输出被上采样,并与初始特征映射连接起来,以捕获本地和全局上下文信息。最后,利用卷积层生成像素级预测。
Ghiasi和Fowlkes [57]开发了一种基于拉普拉斯金字塔的多分辨率重建架构,该架构使用来自高分辨率特征图的跳跃连接和乘法门控来依次细化从低分辨率地图重建的分段边界。他们表明,虽然卷积特征图的表观空间分辨率较低,但高维特征表示包含了显著的亚像素定位信息。
还有其他使用多尺度分析进行分割的模型,如DM-Net(动态多尺度滤波器网络)[58]、上下文对比网络和门控多尺度聚合(CCN)[59]、自适应金字塔上下文网络(APC-Net)[60]、多尺度上下文交织(MSCI)[61]和显著对象分割[62]。
多层感知机:其实就是人工神经网络,由输入层-隐层-输出层组成。
mask(掩模、掩码)是深度学习常见操作,简单而言,其相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素,因此常用于构建张量的过滤器。
3.5基于R-CNN的模型(例如分割)
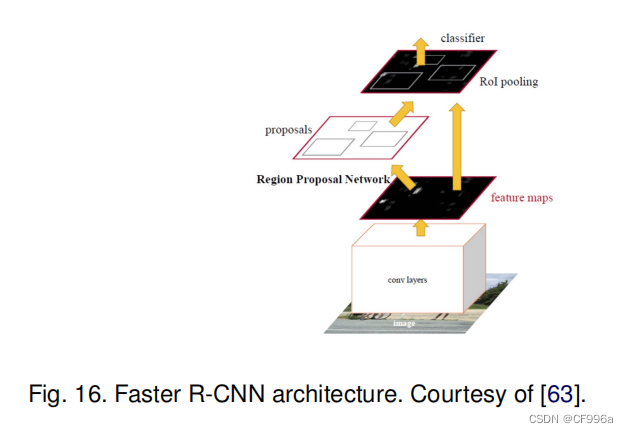
区域卷积网络(R-CNN)及其扩展(Fast R-CNN,Faster R-CNN,Maksed-RCNN)在目标检测应用中已被证明是成功的。特别是,为目标检测开发的更快的R-CNN [63]架构(图16)使用区域建议网络(RPN)来提出边界候选框。RPN提取感兴趣区域(RoI),而RoIPool层从这些建议中计算特征,以推断边界框坐标和对象的类。R-CNN的一些扩展已被大量用于解决实例分割问题;即,同时执行目标检测和语义分割的任务。
在该模型的一个扩展中,He等人[64]提出了一个用于对象实例分割的Mask R-CNN,它在许多COCO挑战中击败了之前的所有基准测试。该模型可以有效地检测图像中的对象,同时为每个实例生成一个高质量的分割掩模。Mask R-CNN本质上是一个有3个输出分支的更快速的RCNN(图17)——第一个计算边界框坐标,第二个计算相关的类,第三个计算二进制掩码来分割对象。Mask R-CNN损失函数结合了边界框坐标、预测类和分割掩码的损失,并联合训练。图18显示了一些示例图像上的Mask-RCNN结果。

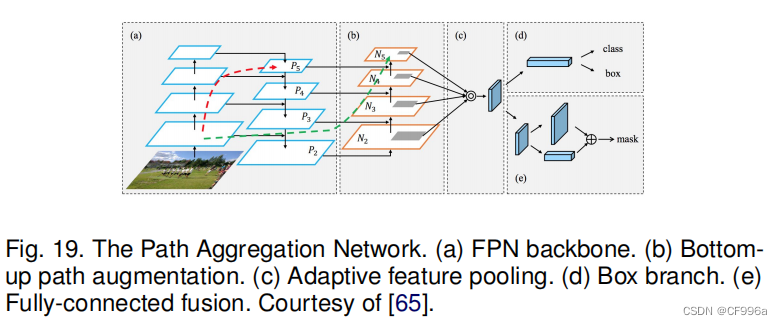
由Liu等人[65]提出的路径聚合网络(PANet)是基于Mask R-CNN和FPN模型的(图19)。该网络的特征提取器使用了一种FPN(特征金字塔)架构,它具有一种新的增强的自底而上的路径,改善了底层特征的传播。这第三条路径的每个阶段都将前一阶段的特征图作为输入,并使用3×3卷积层进行处理。使用横向连接将输出添加到自上而下路径的相同阶段特征图中,这些特征图输入下一个阶段。在Mask RCNN中,自适应特征池化层的输出提供了三个分支。前两个使用完全连接的层来生成边界框坐标和相关对象类的预测。第三个方法使用FCN处理RoI来预测对象掩码。
Dai等人[66]开发了一个用于实例感知语义分割的多任务网络,该网络由三个网络组成,分别是区分实例、估计掩码和分类对象。这些网络形成了一个级联结构,并被设计成共享它们的卷积特征。Hu等人[67]提出了一种新的部分监督训练范式,以及一种新的权重传递函数,可以训练实例分割模型,所有类别都有框注释,但只有一小部分有掩码注释。
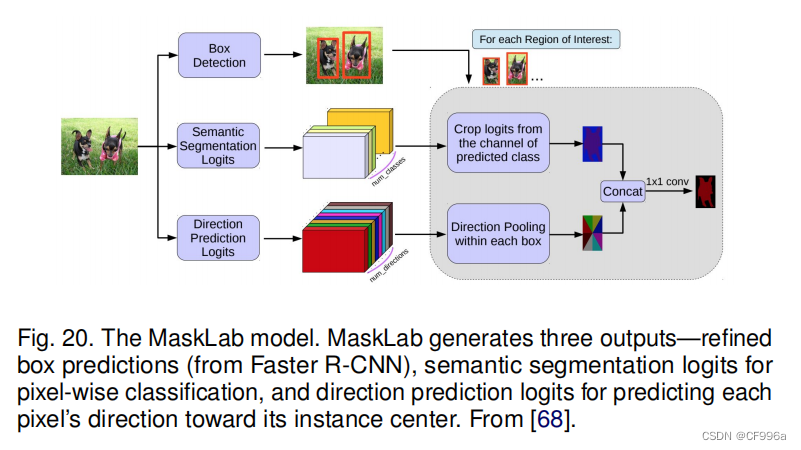
Chen等人[68]开发了一个实例分割模型MaskLab(图20),基于更快的R-CNN用语义和方向特征细化目标检测。该模型产生了盒子检测、语义分割和方向预测三个输出。建立在FasterRCNN对象检测器上,预测的盒子提供了对象实例的精确定位。在每个感兴趣的区域内,MaskLab通过结合语义和方向预测来进行前景/背景分割。
另一个有趣的模型是由Chen等人[69]提出的张量掩模,它基于密集滑动窗口实例分割,他们将密集实例分割作为四维张量的预测任务,并提出了一个通用框架,使在四维张量上有新的算子。他们证明了张量视图导致了对基线的巨大收益,并产生的结果与掩模R-CNN相当。张量掩模在密集目标分割上取得了很好的效果。
基于R-CNN开发了许多其他实例分割模型,比如那些为掩模建议开发的,包括R-FCN [70]、DeepMask [71]、偏振掩模[72]、边界感知实例分割[73]和中心掩模[74]。值得注意的是,还有另一个有前途的研究方向,尝试通过学习自下而上分割的分组线索来解决实例分割问题,如深度流域变换[75]、实时实例分割[76]和通过深度度量学习[77]进行语义实例分割。
3.6扩展的卷积模型和深度实验室系列
膨胀卷积(a.k.a.“膨胀”卷积)引入了另一个参数到卷积层,膨胀率。信号x (i)的扩张卷积(图21)被定义为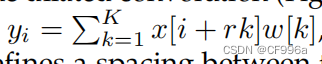
,其中r是定义核w的权值之间的间距的扩张率。例如,一个扩张率为2的3×3核与5×5核具有相同的大小,而只使用9个参数,从而扩大接受域而不增加计算成本。膨胀卷积在实时分割领域已经很流行,最近的许多出版物报道了这种技术的使用。其中最重要的包括DeepLab家族[78]、多尺度上下文聚合[79]、密集上采样卷积和混合扩展卷积(DUC-HDC)[80]、密集连接的区域空间金字塔池(DenseASPP)[81]和高效神经网络(ENet)[82]。
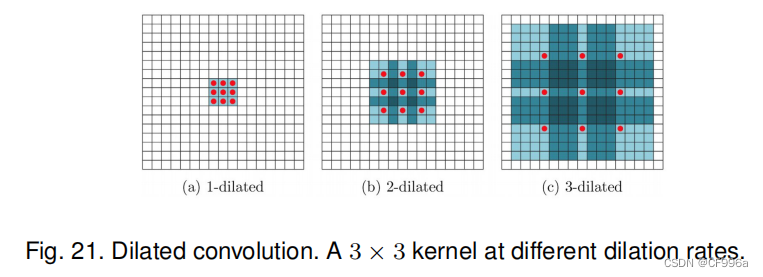
DeepLabv1 [37]和DeepLabv2 [78]是由Chen等人开发的一些最流行的图像分割方法之一。后者有三个关键特征。首先是使用扩展卷积来解决网络中分辨率的下降(由最大池化和步长造成的)。其次是空洞金字塔池化(ASPP),它在多个采样率下用滤波器探测传入的卷积特征层,从而在多个尺度上捕获对象和图像上下文,从而在多个尺度上稳健地分割对象。第三是通过结合深度cnn和概率图形模型的方法来改进对象边界的定位。最好的DeepLab(使用ResNet-101作为主干)在2012年帕斯卡VOC挑战中达到了79.7%,在帕斯卡环境挑战中mIoU分数为45.7%,在城市景观挑战中达到了70.4%的mIoU分数。图22说明了Deeplab模型,类似于[37],主要的区别是使用了扩张卷积和ASPP。
随后,Chen等人[12]提出了DeepLabv3,它结合了扩展卷积的级联和并行模块。并行卷积模块在ASPP中被分组。在ASPP中添加了一个1×1的卷积和批处理归一化。所有的输出被连接并通过另一个1×1卷积处理,以创建每个像素的最终输出。
2018年,Chen等人[83]发布了Deeplabv3+,它使用了编解码器架构(图23),包括可分离卷积,由深度卷积(输入的每个通道的空间卷积)和点态卷积(1×1卷积与输入的深度卷积)组成。他们使用DeepLabv3框架作为编码器。最相关的模型有一个改进的x初始主干,具有更多的层,扩展的深度可分离卷积,而不是最大池化和批处理归一化。在COCO和JFT数据集上预先训练过的最佳DeepLabv3+在2012年帕斯卡VOC挑战中获得了89.0%的mIoU分数。
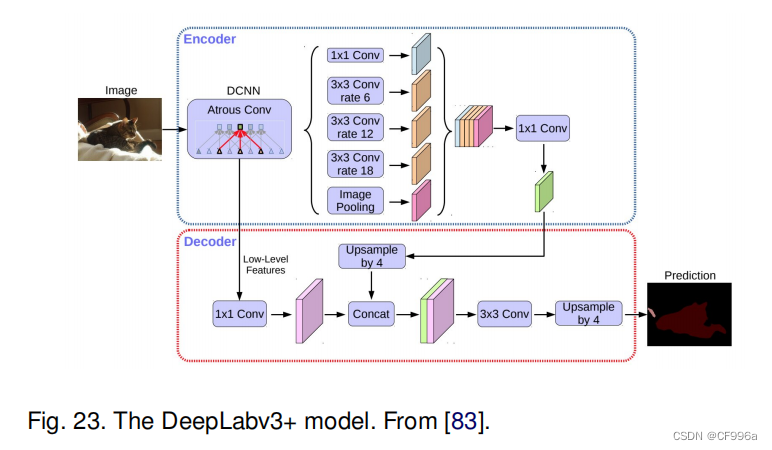
扩张卷积又称为空洞卷积或者膨胀卷积,其原理就是在像素点间填充0值像素,扩张率(dilation rate),指的是卷积核点的间隔数量,需要注意的是正常卷积核的扩张率为1。Conv做特征提取,Poling做特征聚合减少计算量。 空洞金字塔池化ASPP:用不同扩张率的卷积核对特征图进行卷积,然后将结果concat到一起,扩大通道数。深度可分离卷积(Depthwise separable convolution):分为两个过程分别是逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。逐通道卷积卷积核个数必须与输入通道数相等,生成的特征图通道数与输入通道数相同;逐点卷积是使用1x1xM的卷积核对逐通道卷积生成的M个特征图进行卷积。
3.7基于递归神经网络的模型
虽然cnn自然适合解决计算机视觉问题,但它们并不是唯一的可能性。rnn在建模像素之间的短期/长期依赖关系方面很有用,以(潜在地)改进分割图的估计。利用rnn,像素可以连接在一起并按顺序处理,以建模全局上下文和改进语义分割。然而,其中一个挑战是图像的自然二维结构。
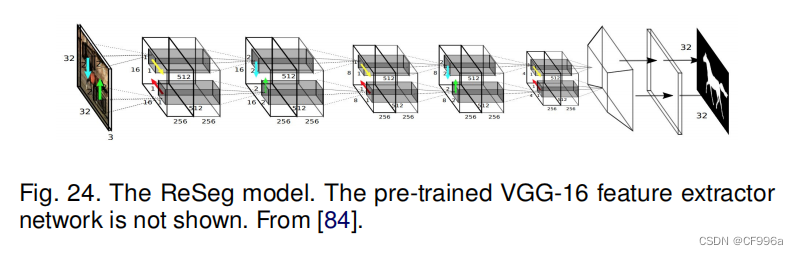
Visin等人,[84]提出了一个基于RNN的语义分割模型,称为ReSeg。这个模型主要是基于另一项工作,ReNet [85],这是开发为图像分类。每个ReNet层由四个rnn组成,它们在两个方向上水平和垂直扫描图像,编码补丁/激活,并提供相关的全局信息。为了使用ReSeg模型进行图像分割(图24),ReNet层堆叠在预先训练的VGG-16卷积层上,这些层提取一般的局部特征。然后,ReNet层之后是上采样层,以恢复最终预测中的原始图像分辨率。使用门控循环单元(gru)是因为它们在内存使用和计算能力之间提供了很好的平衡。
在另一项工作中,Byeon等人[86]开发了一种使用长-短期记忆(LSTM)网络对场景图像进行像素级分割和分类。他们研究了自然场景图像的二维(2D)LSTM网络,考虑到了标签复杂的空间依赖性。在这项工作中,分类、分割和上下文集成都是由二维LSTM网络进行的,允许在单个模型中学习纹理和空间模型参数。
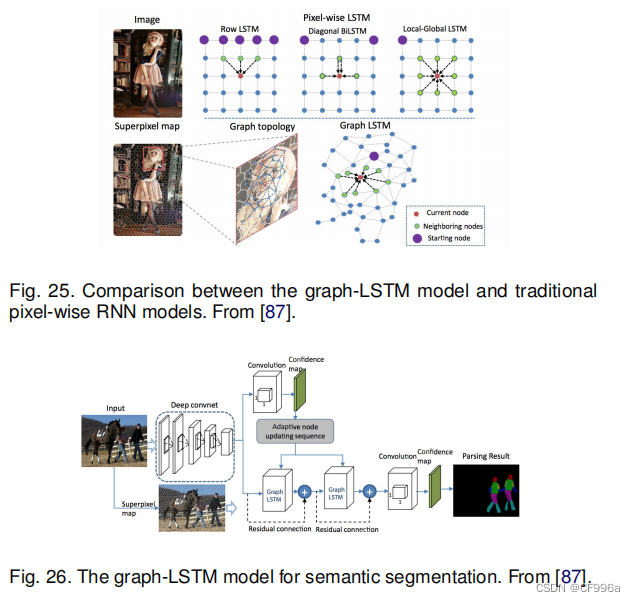
Liang等人[87]提出了一种基于图长短期记忆(Graph Long - Short-Term Memory,图LSTM)网络的语义分割模型,该网络将LSTM从顺序数据或多维数据推广到一般的图结构数据。在现有的多维LSTM结构(如行、网格和对角线LSTM)中,他们没有将图像均匀地划分为像素或斑块,而是将每个任意形状的超像素作为语义一致的节点,自适应地为图像构造一个无向图,其中超像素的空间关系自然被用作边缘。图25展示了传统的像素级RNN模型和graph-LSTM模型的可视化比较。 为使Graph LSTM模型适应语义分割(图26),将构建在超像素特征图上的LSTM层附加在卷积层上,以增强具有全局结构上下文的视觉特征。卷积特征通过1 × 1卷积滤波器为所有标签生成初始置信度映射。后续图LSTM层的节点更新序列由基于初始置信图的置信驱动方案确定,然后图LSTM层可以依次更新所有超像素节点的隐藏状态。
Xiang和Fox[88]提出了数据关联循环神经网络(DA-RNNs),用于联合3D场景映射和语义标记。da - rnn使用一种新的循环神经网络架构对RGB-D视频进行语义标记。该网络的输出与Kinect-Fusion等映射技术相结合,以便将语义信息注入到重构的3D场景中。da - rnn使用一种新的循环神经网络架构对RGB-D视频进行语义标记。该网络的输出与Kinect-Fusion等映射技术相结合,以便将语义信息注入到重构的3D场景中。
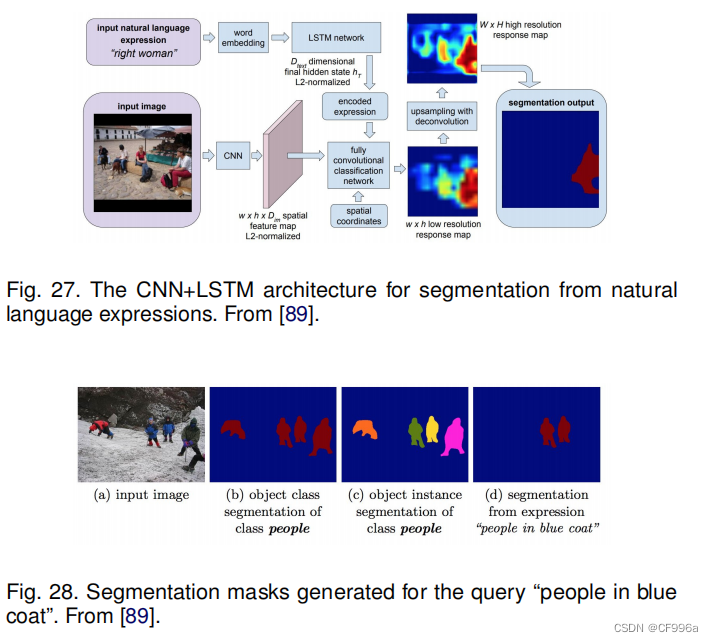
Hu等人[89]开发了一种基于自然语言表达的语义分割算法,使用CNN结合LSTM对图像和自然语言描述进行编码。这与传统的预定义类的语义分割不同,例如,短语“两个人坐在右边的长凳上”要求只把两个人分割在右边的长凳上,而没有人站或坐在另一个长凳上。为了生成语言表达的像素级分割,他们提出了一个端到端可训练的循环和卷积模型,该模型联合学习处理视觉和语言信息(图27)。在所考虑的模型中,使用循环LSTM网络将引用表达式编码为向量表示,并使用FCN从图像中提取空间特征图,并输出目标对象的空间响应图。该模型的一个示例分割结果(对于查询“穿蓝色外套的人”)如图28所示。
基于RNN的模型的一个限制是,由于这些模型的顺序性质,它们将比CNN对应的模型慢,因为这种顺序计算不容易并行化。
3.8注意力机制模型
多年来,注意机制在计算机视觉中不断被探索,因此,发现将这种机制应用于语义分割的出版物也就不足为奇了。
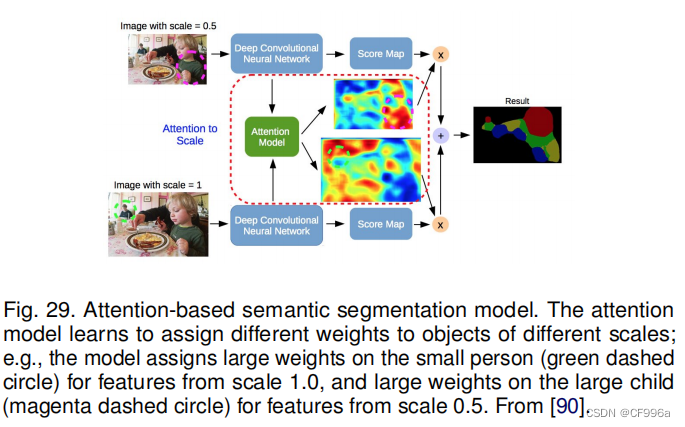
Chen等人[90]提出了一种注意机制,可以学习在每个像素位置对多尺度特征进行软加权。他们采用了强大的语义分割模型,并与多尺度图像和注意力模型联合训练(图29)。注意机制优于平均池化和最大池化,使模型能够在不同位置和尺度上评估特征的重要性。
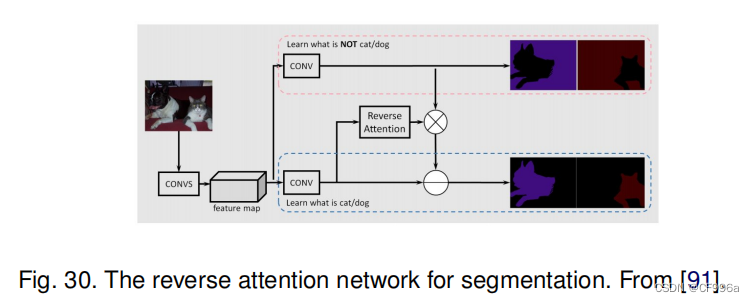
与其他训练卷积分类符来学习被标记对象的代表性语义特征的工作相比,Huang等人[91]提出了一种使用反向注意机制的语义分割方法。他们的反向注意网络(RAN)体系结构(图30)也训练模型来捕获相反的概念(即,与目标类没有关联的特性)。RAN是一个三分支网络,它同时执行直接注意学习和反向注意学习过程。
Li等人[92]开发了一个用于语义分割的金字塔注意网络。该模型利用了全局上下文信息对语义分割的影响。他们结合了注意机制和空间金字塔,提取精确的密集特征用于像素标记,而不是复杂的扩张卷积和人工设计的解码器网络。
最近,Fu等人[93]提出了一种用于场景分割的双注意网络,该网络可以基于自注意机制捕获丰富的上下文依赖关系。
具体来说,他们在一个扩展的FCN上附加了两种类型的注意模块,该FCN分别模拟了空间维度和通道维度上的语义相互依赖关系。位置注意模块通过所有位置的特征的加权和,有选择地聚合每个位置的特征。
各种其他的工作探索语义分割注意机制,如OCNet [94]提出了一个对象上下文池化受自注意机制激励,期望最大化注意(EMANet)[95],交叉注意网络(CCNet)[96],端到端实例分割循环注意[97],点态空间注意网络场景解析[98],和鉴别特征网络(DFN)[99],它包括两个子网络:一个平滑网络(包含一个信道注意块和全局平均池来选择更有区分性的特征)和一个边界网络(使边界的双边特征可区分)。
3.9生成模型和对抗性训练
自引入gan以来,它已被广泛应用于计算机视觉领域的许多任务中,也被用于图像分割。
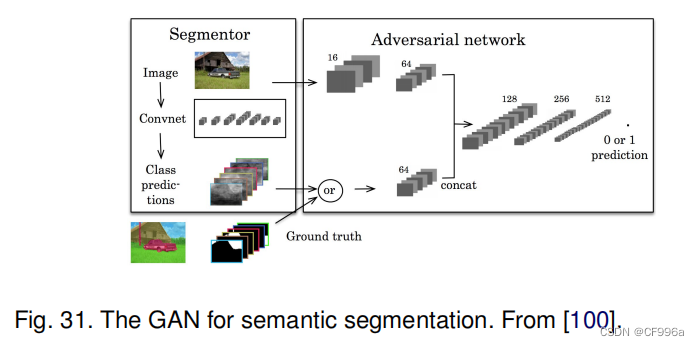
Luc等人[100]提出了一种用于语义分割的对抗性训练方法。他们训练了一个卷积语义分割网络(图31),以及一个对抗性网络,该网络可以区分真实分割图和由分割网络生成的分割图。他们表明,对抗性训练方法可以提高Stanford Background和PASCAL VOC 2012数据集的准确性。
Souly等人[101]提出使用GANs进行半监督语义分割。它由一个生成器网络组成,为多类分类器提供额外的训练示例,在GAN框架中充当鉴别器,从K个可能的类中为样本分配标签或将其标记为假样本(额外类)。
在另一项工作中,Hung等人[102]开发了一个使用对抗性网络的半监督语义分割框架。他们设计了一个FCN鉴别器,来区分预测的概率图和地面真实分割分布,考虑到空间分辨率。该模型所考虑的损失函数包含三项:分割地面真相上的交叉熵损失、鉴别器网络的对抗性损失和基于置信图的半监督损失;即鉴别器的输出。
Xue等人提出了一种多尺度L1损失的对抗网络用于医学图像分割。他们利用FCN作为分割器生成分割标签图,提出了一种新的具有多尺度L1损失函数的对抗性批评网络,迫使批评器和分割器学习全局和局部特征,捕捉像素之间的长期和短期空间关系。
其他各种出版物也报道了基于对抗性训练的分割模型,如使用GANs [104]进行细胞图像分割,以及物体[105]的不可见部分的分割和生成。
半监督:同时用有标签和无标签的数据进行训练,先用一个规模较小的有标签数据训练一个teacher模型,再用这个模型对无标签的数据进行预测,生成伪标签,作为student模型的训练数据。弱监督:用带有噪声的有标签数据进行训练。
3.10具有活动轮廓模型的CNN模型
FCNs与主动轮廓模型(ACMs)[7]之间的协同作用的探索最近引起了研究的兴趣。一种方法是制定受ACM原理启发的新的损失函数。例如,受[106]的全球能量公式的启发,Chen等人[107]提出了一个监督损失层,该层包含了FCN训练过程中预测掩模的面积和大小信息,并解决了心脏MRI中的心室分割问题。
一种不同的方法最初试图利用ACM仅仅作为FCN输出的后处理程序,并通过预先训练FCN尝试适度的联合学习。用于自然图像语义分割任务的ACM后处理程序的一个例子是Le等人[108]的工作,其中水平集ACM被实现为rnn。Rupprecht等人的深度活动轮廓[109]是另一个例子。对于医学图像分割,
Hatamizadeh等人[110]提出了一种集成的Deep Active病灶分割(DALS)模型训练FCN主干预测一个新的局部参数化水平集能量泛函数的参数函数。在另一项相关研究中,Marcos等人[111]提出了深度结构化活动轮廓(DSAC),它结合了ACMs和预训练一个结构化预测框架中的FCNs,用于在航空图像中构建实例分割(尽管需要手动初始化)。对于同样的应用,Cheng等人[112]提出了深度主动射线网络(DarNet),它与DSAC相似,但基于极坐标的显式ACM公式不同,以防止轮廓自交。哈塔米扎德等人[113]最近推出了一种真正的端到端反向传播可训练的、完全集成的FCN-ACM组合,称为深度卷积活动轮廓(DCAC)。
3.11其他模型
除了上述模型之外,还有其他几种流行的用于分割的DL架构,例如:上下文编码网络(EncNet)使用一个基本的特征提取器,并将特征映射输入到上下文编码模块[114]。RefineNet[115]是一种多路径细化网络,它明确地利用了下行采样过程中的所有可用信息,通过远程残差连接实现高分辨率预测。Seednet[116],它引入了一种带有深度强化学习的自动种子生成技术,可以学习解决交互式分割问题。”“对象-上下文表示”(OCR)[44],它在基础真理的监督下学习对象区域,并计算对象区域表示,以及每个像素与每个物体区域之间的关系,并用物体上下文表示的方法来扩充表示像素。然而,其他模型包括BoxSup[117],图卷积网络[118],Wide ResNet [119], Exfuse(增强低层和高层特征融合)[120],前馈网[121],测地视频分割的显著性感知模型[122],双图像分割(DIS) [123], FoveaNet(透视感知场景解析)[124],Ladder DenseNet[125],双边分割网络(BiSeNet)[126],场景解析的语义预测指导(SPGNet) [127],门化形状CNNs[128],自适应上下文网络(AC-Net)[129],动态结构化语义传播网络(DSSPN)[130],符号图推理(SGR)[131],级联网络(CascadeNet)[132],尺度自适应卷积(SAC)[133],统一感知解析(UperNet)[134],再训练和自训练分割[135],密集连接神经结构搜索[136],分层多尺度注意[137]。
全景分割[138]也是另一个越来越受欢迎的有趣的分割问题,在这个方向已经有一些有趣的工作,包括
泛视特征金字塔网络[139],用于泛视分割的注意引导网络[140],无缝场景Segmentation [141], panoptic deeplab[142],统一的泛光分割网络[143],高效的泛光分割[144]。
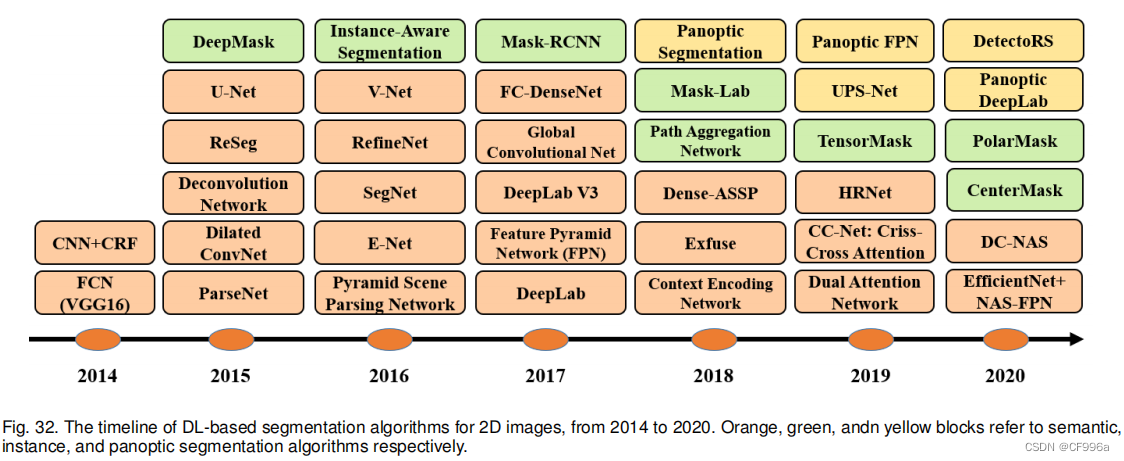
图32展示了自2014年以来流行的基于dl的语义分割和实例分割工作的时间线。鉴于在过去的几年中发展起来的大量作品,我们只展示了一些最具代表性的作品。
4.图像分割数据集
在本节中,我们将总结出一些最广泛使用的图像分割数据集。我们将这些数据集分为3个类别——2D图像、2.5DRGB-D(彩色+深度)图像和3D图像——并提供关于每个数据集特征的详细信息。所列出的数据集具有像素级标签,可用于评估模型性能。
值得一提的是,其中一些工作是,使用数据增强来增加标记样本的数量,特别是那些处理小数据集的样本(如在医疗领域)。数据增强可以通过对图像(即输入图像和分割图)应用一组转换(在数据空间或特征空间,有时两者都有)来增加训练样本的数量。一些典型的转换包括平移、反射、旋转、翘曲、缩放、颜色空间的移动、裁剪和在主组件上的投影。数据增强已被证明可以提高模型的性能,特别是在从有限的数据集学习时,如那些在医学图像分析中。它还可以有利于产生更快的收敛,减少过拟合的机会,并增强泛化。对于一些小的数据集,数据增强已被证明可以提高模型性能的20%以上。
4.1 2D数据集
大多数的图像分割研究都集中在二维图像上;因此,有许多二维图像分割数据集可用。以下是一些最受欢迎的产品:
PASCAL Visual Object Classes (VOC) [145]是计算机视觉中最受欢迎的数据集之一,带有注释的图像可用于5个任务:分类、分割、检测、动作识别和人员布局。文献中几乎所有报道的流行的分割算法都在这个数据集上进行了评估。在分割任务中,有21类对象标签——车辆、家庭、动物、飞机、自行车、船、公共汽车、汽车、摩托车、火车、瓶子、椅子、餐桌、盆栽植物、沙发、电视/监视器、鸟、猫、牛、狗、马、羊和人(如果像素不属于这些类别,像素被标记为背景)。该数据集分为训练和验证两组,分别有1464张和1449张图像。有一个针对实际挑战的私人测试集。图33显示了一个示例图像及其像素级标签。

PASCAL Context [147]是PASCAL VOC 2010检测挑战的扩展,它包含了所有训练图像的像素级标签。它包含400多个类(包括最初的20个类加上背景PASCAL VOC细分),分为三个类别(物体,东西和混合物)。这个数据集的许多对象类别过于稀疏;因此,通常会选择59个频繁类的子集进行使用。
Microsoft Common Objects in Context (MS COCO)[148]是另一个大规模的目标检测、分割和字幕数据集。COCO包括复杂的日常场景的图像,包含在其自然环境中的公共物体。这个数据集包含91种对象类型的照片,在328000张图像中,总共有250万个标记实例。图34显示了给定样本图像的MS-COCO标签与之前的数据集之间的差异。检测挑战包括80多个类,提供超过82000图像用于训练,40500图像用于验证,以及超过80000图像用于其测试集。

Cityscapes [149]是一个专注于对城市街道场景进行语义理解的大型数据库。它包含了50个城市街景中记录的各种立体视频序列,500k帧的高质量像素级标注,以及20k个弱标注帧。它包括30个类的语义和密集的像素注释,分为8个类别——平面、人、车辆、结构、物体、自然、天空和空洞。图35显示了来自该数据集的四个样本分割图。

ADE20K /MIT Scene Parsing (SceneParse150)为场景解析算法提供了一个标准的训练和评估平台。这个基准测试的数据来自ADE20K数据集[132],它包含超过20000的场景中心图像,详尽地注释了对象和对象部分。基准测试被分成20000的图像进行训练,2000张图像用于验证,另一批图像用于测试。在这个数据集中有150个语义类别。
SiftFlow [150]包括来自LabelMe数据库子集的2688张注释图片。这些256 × 256像素的图像基于8个不同的户外场景,其中包括街道、山脉、田野、海滩和建筑物。所有的图像都属于33个语义类中的一个。
Stanford background [151]包含来自现有数据集的户外场景图像,如LabelMe、MSRC和PASCAL VOC。它包含715个图像和至少一个前景对象。该数据集是像素级注释的,可用于语义场景理解。该数据集的语义和几何标签是使用亚马逊的机械土耳其语(AMT)获得的。
Berkeley Segmentation Dataset (BSD) [152]包含来自30个人类受试者的1,000个Corel数据集图像的12,000个手工标记分割。它旨在为图像分割和边界检测的研究提供经验依据。一半的分割来自向受试者呈现彩色图像,另一半来自呈现灰度图像。
Youtube-Objects [153]包含从YouTube收集的视频,其中包括来自十个PASCAL VOC类别的物品(飞机、鸟、船、汽车、猫、牛、狗、马、摩托车和火车)。原始数据集不包含像素级的注释(因为它最初是为对象检测而开发的,带有较弱的注释)。然而,Jain等人的[154]手动注释了126个序列的子集,然后提取了一个帧的子集来进一步生成语义标签。在这个数据集中,总共有大约10,167个带注释的480x360像素的帧可用。
KITTI [155]是移动机器人技术和自动驾驶领域最受欢迎的数据集之一。它包含了数小时的交通场景视频,用各种传感器模式(包括高分辨率RGB、灰度立体摄像机和3D激光扫描仪)录制。原始数据集不包含用于语义分割的基本事实,但研究人员已经为研究目的手动注释了部分数据集。例如,Alvarez等人[156]从道路探测挑战中生成了323张图像,包括道路、垂直和天空。
Other Datasets也可用于图像分割的目的,如Semantic Boundaries Dataset (SBD)[157], PASCAL Part [158], SYNTHIA [159], and Adobe’sPortrait Segmentation [160].
4.2 2.5D数据集
随着廉价的范围扫描仪的可用性,RGB-D图像已经成为流行的研究和工业应用。以下RGB-D数据集是一些最流行的:
NYU-D V2 [161]由各种室内场景的视频序列组成,由RGB和微软Kinect的深度摄像机录制。它包括1449对密集标记的对齐RGB和深度图像,它们来自来自3个城市的450多个场景。每个对象都被标记有一个类和一个实例号(例如,cup1、cup2、cup3等)。它还包含了407,024个未标记的帧。与其他现有数据集相比,该数据集相对较小。图36显示了一个样本图像及其分割图。

RGB-D = RGB + Depth Map. RGB:三通道彩色图像,描述物体的表观、颜色、纹理信息。 Depth:描述物体的形状、尺度、几何空间信息。 Depth Map类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。
SUN-3D [162]是一个大规模的RGB-D视频数据集,包含为41个不同建筑中的254个不同空间捕获的415个序列;8个序列被注释,未来将会有更多的注释。每个带注释的帧都带有场景中对象的语义分割,以及关于相机姿态的信息。
SUN RGB-D [163]提供了一个RGB-D基准,以提高所有主要场景理解任务的先进水平。它由四个不同的传感器捕获,并包含10,000张RGB-D图像,其规模类似于PASCAL VOC。整个数据集被密集地注释,包括146,617个2D多边形和58,657个具有精确对象方向的3D边界框,以及场景的3D房间类别和布局。
UW RGB-D Object Dataset [164]包含300个常见的使用Kinect风格的3D相机记录的家用物品。这些对象被组织成51个类别,使用WordNet超对称-下义性关系(类似于ImageNet)进行排列。该数据集是使用Kinect风格的3D相机记录的,该相机记录了同步和对齐的640×480像素的RGB和30 Hz的深度图像。该数据集还包括8个带注释的自然场景视频序列,其中包含来自数据集(UWRGB-D场景数据集)的对象。
ScanNet [165]是一个RGB-D视频数据集,包含超过1500次扫描的250万视图,注释了3D相机姿态、表面重建和实例提升语义分割。为了收集这些数据,我们设计了一个易于使用和可扩展的RGB-D捕获系统,其中包括自动表面重建,语义注释是众包的。使用这些数据有助于在一些三维场景理解任务上实现最先进的性能,包括三维对象分类、语义体素标记和CAD模型检索。
4.3 3D数据集
三维图像数据集在机器人、医学图像分析、三维场景分析和构建应用中非常流行。三维图像通常通过网格或其他体积表示来提供,如点云。在这里,我们将提到一些流行的3D数据集。
Stanford 2D-3D:该数据集提供了来自2D、2.5D和3D域的多种相互注册的模式,具有实例级的语义和几何注释[166],并收集在6个室内区域。它包含超过70,000张RGB图像,以及相应的深度、表面法线、语义注释、全局XYZ图像以及相机信息。
ShapeNet Core:ShapeNetCore是完整的ShapeNet数据集[167],具有单一干净的3D模型和手动验证的类别和对齐注释[168]。它涵盖了55个常见的对象类别,约51,300个独特的3D模型。
Sydney Urban Objects Dataset:这个数据集包含了各种各样的城市道路物品,收集在澳大利亚悉尼的中央商业区。有631个人对车辆、行人、标志和树木的物品进行扫描[169]。
3D数据集将2维平面的检测框转换成了具有立体效果的立方体
5 PERFORMANCE REVIEW(性能评估)
在本节中,我们首先提供了一些用于评估细分模型性能的流行指标的摘要,然后我们提供了在流行数据集上有希望的基于dl的分割模型的定量性能。
5.1 Metrics For Segmentation Models(分割模型度量)
理想情况下,应该在多个方面评估模型,如定量精度、速度(推理时间)和存储需求(内存占用)。然而,目前大部分的研究都是为了评估模型的准确性而关注的。下面我们总结了评估分割算法准确性的最流行的指标。虽然定量指标用于比较不同模型的基准,但模型输出的视觉质量在决定哪个模型是最好的方面也是很重要的(人类是计算机视觉应用开发的许多模型的最终消费者)。
Pixel accuracy简单地发现像素的比例适当地分类,除以像素的总数。对于K + 1类(K前景类和背景)像素精度定义为Eq 1:
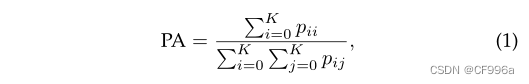
pij是本属于第i个类别却被分为第j类的像素数量,pii表示被正确分类的像素数量。
Mean Pixel Accuracy (MPA)是扩展版的PA,在其中,正确的像素比按每个类的方式计算,然后平均除以类的总数,如Eq 2:
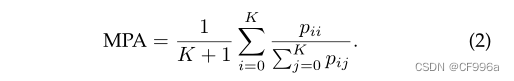
Intersection over Union (IoU)or the Jaccard Index是在语义分割中最常用的指标之一。它被定义为预测分割图和真实分割图之间的交叉区域,除以预测分割图和真实分割图之间的结合区域:
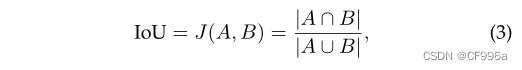
A和B分别表示真实区域和预测区域,IoU又称交并比是两个区域的交集比并集的值
Mean-IoU是另一个受欢迎的度量,它被定义为所有类的平均IoU。它广泛应用于现代分割算法的表现。
Precision / Recall / F1 score是流行的指标,以报告许多经典图像分割的准确性模型。对于每个类,以及在聚合级别上都可以定义精度和内存,如下:
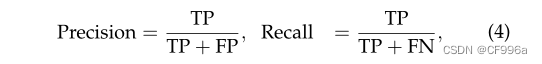
TP真阳性,FP假阳性;TN真阴性,FN假阴性。真阳性:本来为正类被预测为正类,假阳性:本来为负类被预测为正类,真阴性:本来为负类被预测为负类,假阴性,本来为正类类被预测为负类。
TP指的是真实正分数,FP指的是假正分数,FN指的是假阴性分数。通常我们对精确和召回率的组合感兴趣。一个流行的度规叫做F1分数,它被定义为精度和回忆的低均值:
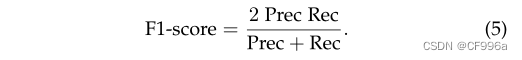
Dice coefficient是另一个受欢迎的图像分割的标准(在医学图像分析中更常用),它可以被定义为预测和真实的重叠区域的两倍,除以两个图像的像素总数。骰子系数与IoU非常相似:
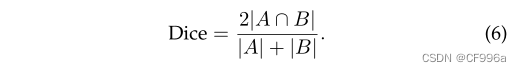
应用于布尔数据时,二进制分割映射并将其作为一个正类,骰子系数与F1分数基本相同,定义为Eq 7:
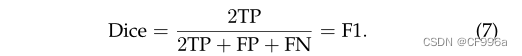
5.2 Quantitative Performance of DL-Based Models
在本节中,我们将之前讨论的几个算法的性能进行了分页,讨论了受欢迎的细分基准。值得一提的是,尽管大多数模型都报告了他们在标准数据集上的性能,并使用标准指标,但其中一些却没有做到这一点,使得全面的比较变得困难。此外,只有一小部分的出版物提供了额外的信息,如执行时间和内存占用,以一种可重复的方式,这对分割模型的工业应用(如无人机、自动驾驶汽车、机器人等)的工业应用是重要的,它可能会在内置的消费设备上运行,具有有限的计算能力和存储能力,使快速、轻量级的模型变得至关重要。
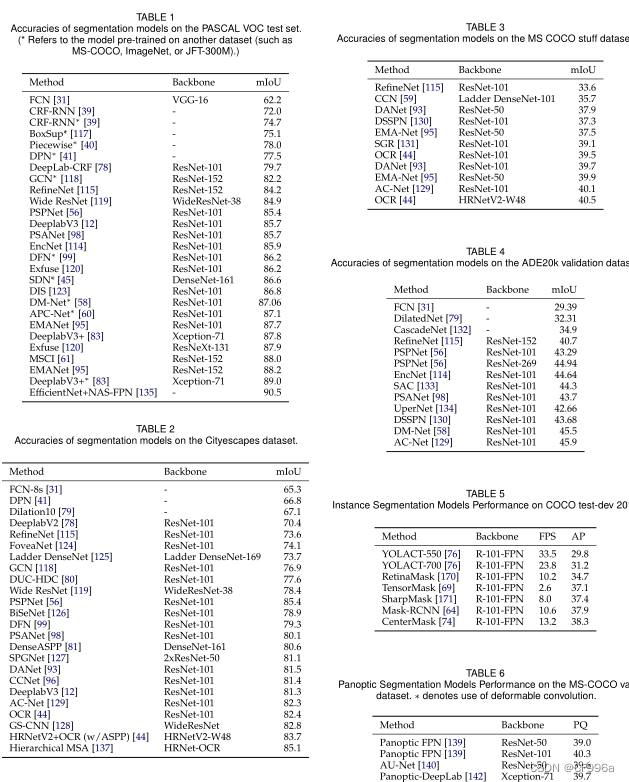
下面的表总结了一些著名的基于dl的细分模型在不同数据集上的性能。表1集中于PASCAL VOC测试集。显然,自FCN引入以来,模型的准确性有了很大的提高,这是第一个基于数字的图像分割模型。表2关注的是Cityscape测试数据集。最新的模型有在这个数据集上的初始FCN模型中,23%的相对增益。表3集中于COCO stuff测试集。这个数据集比PASCAL VOC更具有挑战性,而city逃逸则是最高的mIoU大约40%。表4集中于ADE20k验证集。这一数据集也比PASCAL VOC和citydoddatasets更具挑战性。
6 CHALLENGES AND OPPORTUNITIES
毫无疑问,图像分割从深度学习中获益良多,但前方有几个挑战。接下来,我们将介绍一些有前途的研究方向,我们认为这将有助于进一步推进图像分割算法。
6.1 More Challenging Datasets
为语义分割和实例分割创建了几个大规模的图像数据集。然而,仍然需要更具挑战性的数据集,以及不同类型图像的数据集。对于仍然存在的图像,有大量对象和重叠对象的数据集将非常有价值。这可以启用更好地处理密集对象场景的培训模型,以及在现实世界中常见的对象之间的重叠。
随着3D图像分割的普及,特别是在医学图像分析中,对大规模3D图像数据集也有很强的需求。这些数据集比底层的数据集更难以创建。现有的三维图像分割数据集通常不够大,有些是合成的,因此更大更具有挑战性的三维图像数据集可能非常有价值。
6.2 Interpretable Deep Models
虽然基于dl的模型在具有挑战性的基准上取得了良好的性能,但对于这些模型仍然有开放性的问题。例如,什么是深层模型学习?我们应该如何解释这些模型所了解的特征?什么是最小的神经结构,可以在给定的数据集上实现特定的分割精度?虽然有一些技术可以可视化这些模型的卷积内核,但对这些模型的基本行为/动力学的具体研究是缺乏的。更好地理解这些模型的理论方面可以使更好的模型的开发对不同的分割场景进行约束。
6.3 Weakly-Supervised and Unsupervised Learning
弱监督(a.k.a.很少的射击学习)[182]和无监督学习[183]正在成为非常活跃的研究领域。这些技术对图像分割具有特殊的价值,作为分割问题的标记样本在许多应用领域都是有问题的,特别是在医学图像分析中。迁移学习方法是在一组标记样本(可能来自公共基准)上对一组大的图像分割模型进行训练,然后从特定的目标应用程序中对一些样本进行微调。自我监督学习是另一个有希望的方向,在不同领域吸引了很多吸引力。在自我监督的学习的帮助下,可以捕捉到的图像中有很多细节,可以被捕获来训练一个细分模型,在训练样本中,训练样本的数量要少得多。基于强化学习的模型也可能是另一个潜在的未来方向,因为他们几乎没有被注意到图像分割。例如,MOREL[184]在视频中引入了一种深入的强化学习方法来移动物体分割。
6.4 Real-time Models for Various Applications
在许多应用中,准确性是最重要的因素;然而,有一些应用程序,在实时或至少接近普通相机帧率(至少25帧每秒)的分割模型中,这也是至关重要的。这对于计算机视觉系统是有用的,例如,部署在自动驾驶汽车上。大多数目前的模型远非这种框架率。,FCN -处理一个低分辨率图像需要大约100毫秒。基于扩张卷积的模型可以在一定程度上提高分割模型的速度,但仍有很大的改进空间。
6.5 Memory Efficient Models
许多现代的分割模型甚至在推理阶段都需要大量的内存。到目前为止,为了提高这些模型的准确性,已经做出了很多努力,但为了使它们适应特定的设备,如移动电话,网络必须被简化。这可以通过使用更简单的模型,或者使用模型压缩技术,甚至是训练一个复杂的模型,然后使用知识蒸馏技术将其压缩到一个更小、内存高效的网络,模拟复杂的模型。
6.6 3D Point-Cloud Segmentation(3D点云分割)
许多作品都集中在2D图像分割上,但很少有关于3D点云分割的文章。然而,对pointcloud分割的兴趣越来越大,它有广泛的应用范围,在三维建模、自动驾驶汽车、机器人、建筑建模等方面。处理3D无序和非结构化数据,如点云会带来几个挑战。例如,在点云上应用CNNs和其他古典深度学习架构的最好方法尚不清楚。基于图形的深层模型可以是点云分割的潜在探索领域,为这些数据提供额外的工业应用。
6.7 Application Scenarios(应用场景)
在本节中,我们简要地研究了最近的基于dl的分割方法的一些应用场景,以及前面的一些挑战。最明显的是,这些方法已经成功地应用于遥感领域的卫星图像[185],包括城市规划技术[186]或精密农业[187]。机载平台收集的遥感图像[188]和无人机[189]也采用dl技术进行分割,提供了解决气候变化等重要环境问题的机会。分割这种图像的主要挑战与数据的非常大的维度有关(通常是由图像光谱仪收集的,有数百个甚至数千个光谱波段)和有限的地面真相信息,以评估通过分割算法获得的结果的准确性。一种基于DLbased分割的重要应用领域是医学成像[190]。在这里,一个机会是设计标准化的图像数据库,可以用来评估快速传播新的疾病和流行病。最后,我们也应该提到基于dl基于算法的生物学[191]和建筑材料评价[192],这提供了一个机会来解决高度相关的应用领域,但将受到与相关图像数据的大量数据和验证目的的有限参考信息相关的挑战。
7 CONCLUSIONS
我们已经调查了100多个基于深度学习模型的图像分割算法,这些模型在不同的图像分割任务和基准中取得了令人印象深刻的性能,分组到10个类别,如:CNN和FCN,RNN,R-CNN,放大的CNN,基于注意力的模型,生成和对战模型,以及其他。我们在一些流行的基准上总结了这些模型的定量性能分析,如PASCAL VOC、COCO、Cityscapes和ADE20k数据集。最后,我们讨论了在未来几年可以探索的一些开放挑战和潜在的图像分割研究方向。
ACKNOWLEDGMENTS
The authors would like to thank Tsung-Yi Lin from Google Brain, and Jingdong Wang and Yuhui Yuan from MicrosoftResearch Asia, for reviewing this work, and providing very
helpful comments and suggestions.

