
运行时游戏性基础系统
游戏性基础系统的组件
如果可以合理地画出游戏与游戏引擎的分界线,那么游戏性基础系统就是刚刚位于该线之下。理论上,我们可以建立一个游戏性基础系统,其大部分是各个游戏皆通用的。实际上不同引擎之间有许多共有模式,以下列出一些常用组件,后续的文章就会逐渐记录这些组件的功能和设计方法。
- 运行时游戏对象(runtime game object)模型
- 实时更新对象模型
- 关卡管理及串流
- 目标及游戏流程管理
- 消息及事件处理
- 脚本
- 目标及游戏流程管理
运行时对象模型分为
- 动态地产生及消灭的游戏对象
- 联系底层引擎系统
- 实时模拟对象行为
- 定义新游戏对象类型
- 唯一对象标识符
- 游戏对象查询
- 游戏对象引用
- 有限状态机的支持
- 网络复制
- 存档及载入游戏、对象持久性
各种运行时对象模型架构
以对象为中心的架构
这种架构中每个逻辑游戏对象会实现为类的实例,或一组互相连接的实例。然而单纯使用继承和多态会导致一系列类层次结构的问题。
使用面向对象架构的问题
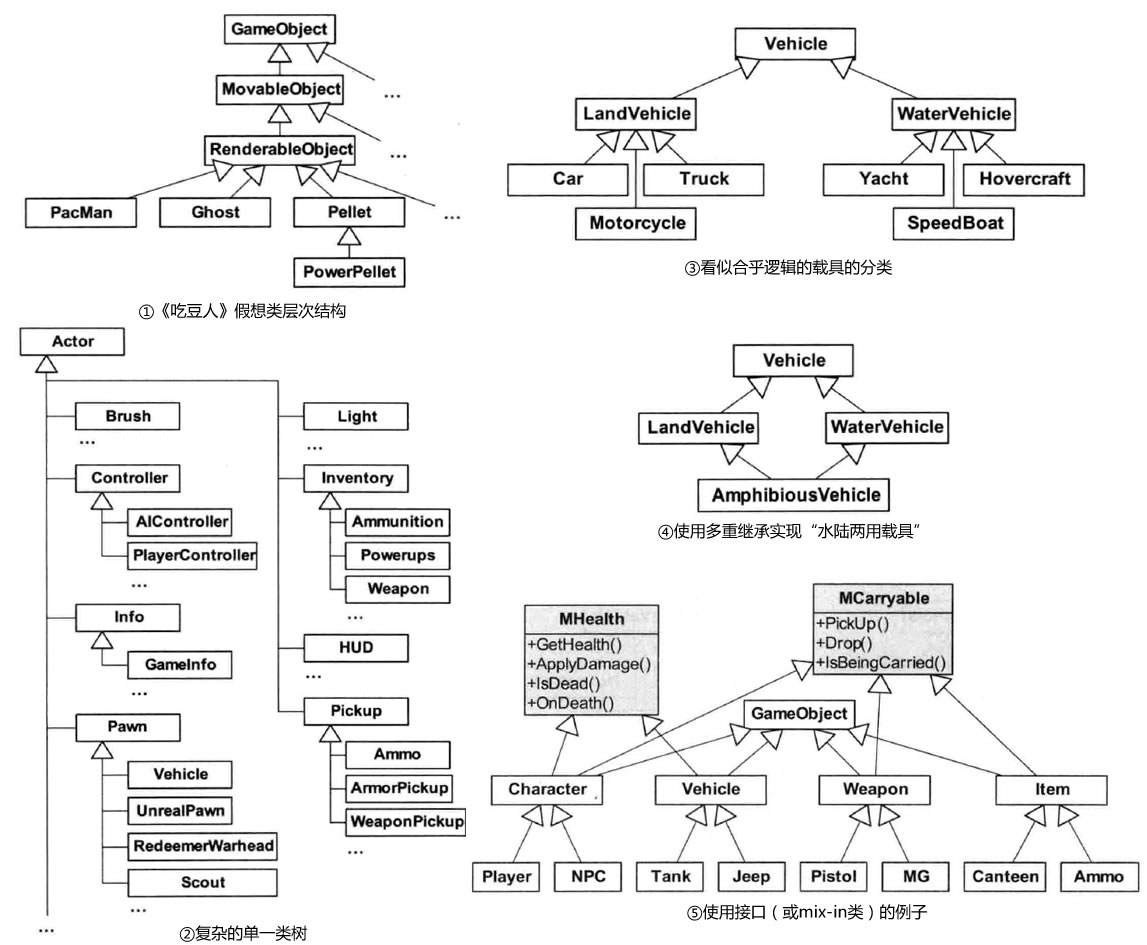
类层次结构逐渐变得单一庞大。如下图①实现《吃豆人》(PacMan)的一种简单类结构,随着功能增长,该结构会同时往纵、横方向发展,并出现以下问题:
- 类难以理解、维护及修改:要理解一个类,就要理解其所有父类(例如在派生类中修改一个看似无害的虚函数,就可能会违背了众基类中某个基类的假设),参考下图②复杂的单一类树节选
- 不能表达多维分类:继承有着“是一个”的语义,导致在分类对象时只能从一个维度去设计。如下图③,各类载具的分类看似合乎逻辑,但如果再加入一种“水陆两用载具”则无从下手
- 多重继承的弊端:解决“水陆两用载具”的解决方法之一就是使用C++的多重继承,如下图④。然而多重继承有其严重弊端,此处不再赘述
- 使用接口:像C#或Java类只能继承一个类,但可以实现多个接口,这样共用的功能就能抽出来(也称为mix-in类)。如下图⑤,任何继承MHealth的类会有血量信息,并可以被杀
- 冒泡效应:当游戏加入越来越多的功能,程序员很容易不断把若干个类中公用但与基类无关的代码上升到基类中(即为了所谓的复用利用了继承的便利),这种趋势会令功能代码沿层次结构上移到基类(冒泡),从而违背类职责应该保持单一的原则
使用“合成”来简化层次结构
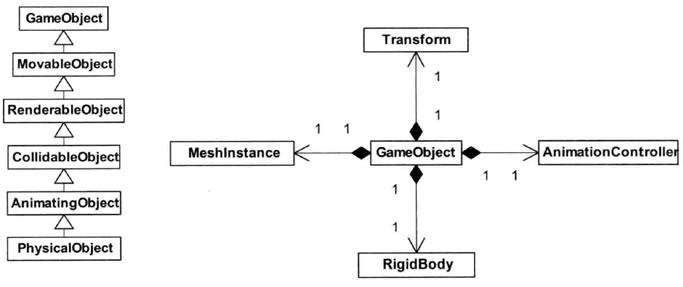
面向对象设计中过度使用“是一个(is-a)”关系,会限制了我们创造新游戏类型的设计选择,而且难以扩展现存类的功能。若像下图左边的继承结构,希望一个游戏对象类有碰撞功能,它必须要继承自CollidableObject ,即使它可能是隐形的而并不需要RenderableObject的功能。若把不同的功能分离为独立的“组件”类,它们互不相干,由一个轻量的GameObject采用“有一个(has-a)”关系持有并管理,如下图右边,则可以大大简化。Unity便是运用这种思想的例子。
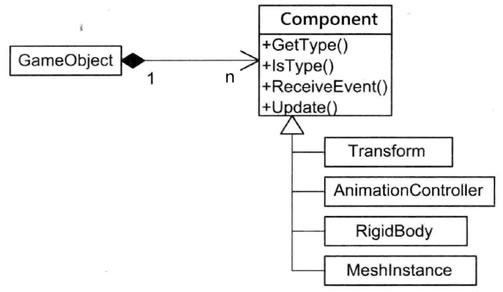
对于GameObject管理其组件声明周期的具体实现,具体的做法是GameObject持有所有可能组件的指针并默认为空,而具体的游戏对象继承GameObject后,自行初始化所需的基本组件,并实现自己的特殊组件。但是当需要扩展新组件时,都要修改GameObject类,不符合开闭原则,因此更好的做法是以下这种GameObject持有Component链表的结构。
以属性为中心的架构
以对象为中心,会自然地关注对象属性和行为。以属性为中心,则是先定义所有属性,再为每个属性键表存储关联该属性的对象,像数据库表就是这种设计。
这种设计的优点是趋向更有效地使用内存,因为只需储存实际上用到的属性;也更容易使用数据驱动的方式来建模。最后是比以对象为中心的模型更加缓存友好,因为有些游戏硬件的内存存取成本远高于执行指令和运算。把数据连续储存于内存之中,能减少或消除缓存命中失败。这种数据布局方式称为数组的结构(struct of array)。以下代码展示了与传统结构之数组(array of struct)的对比。
static const U32 MAX_GAME_OBJECTS = 1024;
// 传统结构的数组方式
struct GameObject
{
U32 m_uniqueId;
Vector m_pos;
Quaternion m_rot;
};
GameObject g_AllGameObjects[MAX_GAME_OBJECTS];
// 对缓存更友好的数组的结构方式
struct AllGameObjects
{
U32 m_UniqueId[MAX_GAME_OBJECTS];
Vector m_Pos[MAX_GAME_OBJECTS];
Quaternion m_Rot[MAX_GAME_OBJECTS];
}
AllGameObjects g_allGameObjects;
这种设计的缺点是单凭凑齐一些细粒度的属性去实现一个大规模的行为,并非易事。这种系统也可能更难以除错,因为程序员不能一次性地把游戏对象拉到监视视窗中检查它的属性。
世界组块的数据格式
- 把一组游戏对象存储到磁盘的方法:
- 把每个对象的二进制映像写入文件,映像和对象在内存中的样子完全相同。
- 序列化,可以存储为更方便更可携的格式。缺点:它由对象运行时实现所定义的,因此世界编辑器需要知道游戏引擎运行时实现才能运作。
- 生成器,游戏对象轻量仅含数据的表示方式,可用于运行时实例化和初始化对象。优点:简单、富弹性和健壮性。
游戏世界的加载和串流
- 简单的加载方式,一次加载一个关卡。他不能实现辽阔、连续、无缝的世界。
- 阻隔室,将内存分为两个大小不同的块,大块加载游戏世界组块,小的作为阻隔室。当要加载下一块时,进入阻隔室,让玩家做点别的,同时异步加载下一块。
- 串流,游戏的同时,也在加载新数据,卸载旧数据。但是会导致内存碎片。
- 为相同大小的对象设置内存池,这样会有很多池分配器,所以可以允许在大于对象的大小的池中分配。
- 内存重定位
对象引用与世界查询
对象引用方法
指针
每个游戏对象通常需要某种唯一标识符以便互相区分,并且能在运行时或工具方(世界编辑器)找到所需的对象,也可用该标识符作为对象间通信的目标。当通过查询找到一个游戏对象时,需要以某种方式引用它。C/C++中最常见的做法就是使用指针,因为指针是实现对象引用最快、最高效并最容易使用的方式。但使用指针很容易出现孤立对象、过时指针、无效指针等问题,所以开发引擎的团队制定严格的编程惯例,或使用安全的约束方法如智能指针。
智能指针是一个小型对象,行为与指针非常接近,但其扩展了规避原始C/C++指针所衍生的问题。关于智能指针可参考C++的一些高级书目,此处不赘述,仅建议尽量不要在项目中尝试自己实现恶心的智能指针,如果必须使用,尽量选用像Boost这样的成熟实现。
句柄
句柄就是某全局句柄表的整数索引,而句柄表则储存指向引用对象的指针。下图说明了此数据结构。
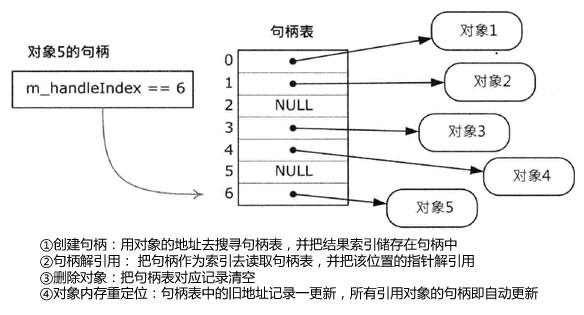
虽然句柄可以实现为原始整数,但句柄表的索引通常会包装成一个简单类,以提供更方便创建句柄和解引用的接口。以下是一种简单实现(省略其他与句柄无关的实现)。
/* GameObject类储存了它的句柄索引,当要创建新句柄时就不用以地址搜寻句柄表了 */
class GameObject
{
private:
GameObjectId m_uniqueId; // 对象唯一标识符
U32 m_handleIndex; // 供更快地创建句柄
friend class GameObjectHandle; // 让它访问id及索引
public:
GameObject()
{
m_uniqueId = AssignUniqueObjectId();
m_handleIndex = FindFreeSlotInHandleTable();
}
}
// 定义句柄表的大小,以及同时间的最大对象数目
static const U32 MAX_GAME_OBJECTS = ...;
// 全局句柄表,只是简单的数组,储存游戏对象指针
static GameObject* g_apGameObject[MAX_GAME_OBJECTS];
/* 句柄封装类 */
class GameObjectHandle
{
private:
U32 m_handleIndex;
GameObjectId m_uniqueId;
public:
explicit GameObjectHandle(GameObject& object) :
m_handleIndex(object.m_handleIndex),
m_uniqueId(object.m_uniqueId) {}
// 句柄解引用
GameObject* ToObject() const
{
GameObject* pObject = g_apGameObject[m_handleIndex];
if (pObject != NULL && pObject->m_uniqueId == m_uniqueId)
return pObject;
return NULL;
}
}
对象查询方法
取决于具体的游戏设计,开发者需要根据业务来查询不同种类的对象,例如找出玩家视线范围内的所有敌人角色,找出所有血量少于80%的可破坏游戏对象等等。游戏团队通常要判断,在游戏开发过程中哪些是可能最常用到的查询类型,并实现专用的数据结构加速查询。以下列举了一些可用于加速某类游戏对象查询的专门的数据结构。
- 以唯一标识符搜寻:游戏对象的指针或句柄可储存于以唯一标识符为键的散列表或二叉查找树
- 对合乎某条件的所有对象进行迭代:可预先以某种条件排序,并把结果储存在某个列表(例如不断维护一个在玩家某半径范围内的所有对象的列表来加速查询实现范围内的敌人)
- 搜寻抛射体路径或对某目标点视线内的所有对象:通常会利用碰撞系统实现,多数碰撞系统会提供一些极快的光线投射功能
- 搜寻某区域或半径范围内的所有对象:用一些空间散列数据结构去储存游戏对象,如四叉树、八叉树、kd树等等
实时更新游戏对象
一种最简单但不可行的实现方式是,每个游戏对象都有一个虚函数virtual void Update(float dt),游戏主循环在每一帧遍历全体游戏对象集合并逐一调用Update。每个Update所做的事情大致是更新对象自身的逻辑数据,然后逐个更新其组件(如动画、渲染、粒子、声音组件)。
性能限制与批次式更新
低阶引擎系统都有极严竣的性能限制,把多个游戏对象的同个子系统更新组合起来批次处理,要比上述多个游戏对象交错更新子系统更高效,如下图所示。像渲染引擎就是使用批次式更新的典型例子。
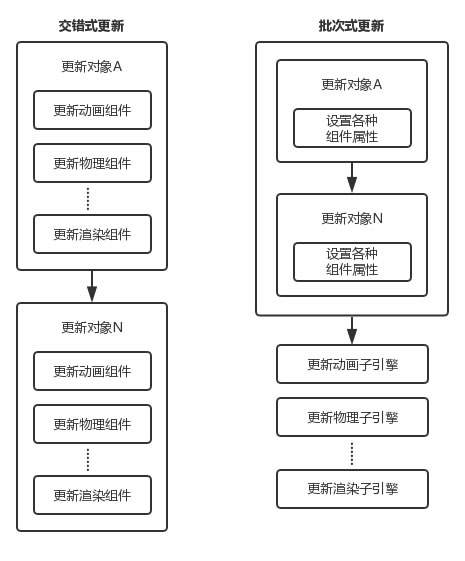
批次式更新带来很多性能效益,包括但不限于:
- 最高的缓存一致性:子系统能把各对象的所需数据分配到一个连续的内存区里
- 最少的重复运算:可以先执行整体的运算,之后在各对象更新中重用,无须每次在对象中重新计算
- 减少资源再分配:交错式更新处理每个对象时须释放及再分配资源,批次式更新则只需每批次一次
- 高效的流水线:在某些硬件上可以做一些优化,利用硬件特设的资源并行计算
性能优势并不是使用批次式更新的唯一原因,一些引擎子系统从根本上不能以对象单位进行更新。例如,若一个动力学系统里有多个刚体进行碰撞决议时,孤立地逐一考虑对象,一般不能找到满意的解。
对象及子系统的相互依赖
要正确运行游戏,游戏对象更新的次序是重要的(例如计算某物体的局部坐标需要先计算其父节点的世界坐标)。除了对象之间有依赖关系,各子系统也有依赖关系,而且不是简单的先后关系,例如布娃娃物理模拟系统须与动画系统协同更新。可以在主循环中明确编写各个子系统的更新顺序。
主循环通常不能简化成每帧每对象调用一次Update,游戏对象可能需要使用多个引擎子系统的中间结果。很多游戏引擎容许游戏对象在1帧中的多个时机编写对应的虚函数“挂钩”进行更新,像Unity GameObject的Update、FixedUpdate、LateUpdate等。游戏对象可按需增加更多更新阶段,但要小心带来多余的调用空的虚函数开销可能很高。
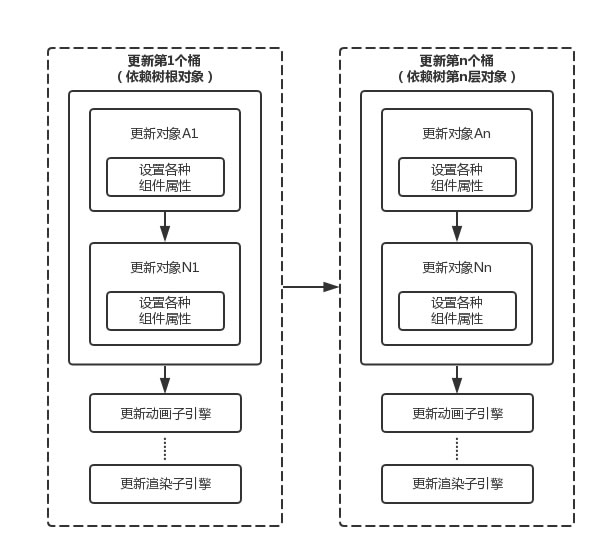
桶式更新
当存在对象间的依赖时,可能会抵触更新次序的规则,有时要轻微调整上述的批次式更新技巧。即不要一次性批处理所有游戏对象,而是把对象按依赖关系分为若干群组(或称为桶bucket),即没有任何依赖关系的对象(依赖树的根)放到第1个桶,依赖树第2层的所有对象放到第2个桶……然后按依赖次序更新每个桶,桶中使用批次式更新,如下图所示。游戏引擎可以明确为依赖树林的深度设限,这样就可以使用固定数目的桶以提高性能。
对象状态及“差一帧”延迟
更新游戏对象可视为这样一个过程:每个对象根据t1时刻的状态决定t2(t2 = t1+Δt2 = t1 + Δt)时刻的状态。理论上,所有游戏对象的状态是瞬间及并行地从时刻t1t1更新至t2t2的。但实际上主循环会逐个更新对象,在一轮循环中间中断时则有一些对象处于部分更新的状态(例如某个对象可能已执行姿势动画混合,却未计算物理及碰撞决议)。
游戏对象在两帧之间状态不一致是混淆和bug的主要来源。当有对象依赖时(如对象B需要根据对象A的速度来决定当前帧自身的速度),程序员必须弄清楚需要的是对象A的之前的状态还是新状态。若需要新状态,而对象A却未更新,就会产生一个更新次序问题,会导致一类称为“差一帧”延迟的bug。解决这个问题通常有以下做法:
- 桶式更新:上面已描述,但是必须保证同一个桶内的对象不会互相查询状态。
- 对象状态缓存:更新时不要就地覆写新的状态,而是保留之前的状态变量,并把新的状态写到另一个变量。这样任何对象都可安全地查询其他对象的之前状态;而且就算是在更新的过程中,它保证永远有一个完全一致的状态;还能通过线性地向前后两个状态插值。这种方法的缺点是多耗一倍内存,而且只能保证在t1状态一致,而t2状态不一定一致。
- 加上时戳:给每个对象加时戳可轻易分辨对象的状态是在之前还是当前时间
事件与消息泵
游戏本质上是事件驱动的。事件是游戏过程中发生、希望关注的事情,例如发生爆炸、玩家被敌人看见、拾取补血包等等。游戏通常需要一些方法做两件事——当事件发生时通知关注该事件的对象,以及让那些对象回应所关注的事件。事件系统采用的设计模式便是知名的观察者模式,本文将介绍事件系统的一些基本原理,以及事件排队的扩展机制。
为了通知游戏对象一个事件己发生,最简单的方法是调用该对象的方法,更进一步的是调用欲通知对象的虚函数。虚函数的后期绑定在某种程度上降低了实现的弹性,实际上,使用静态类型的虚函数作为事件处理程序,会导致GameObject基类需要声明游戏中所有可能出现的事件!这样会令创建新事件变得困难,也阻止了以数据驱动方式产生事件,也违背了让某些类仅注册自己希望关注的事件的初衷。
把事件封装成对象
事件实质上由两个部分组成:类型及参数,其中参数为事件提供细节。因此可以把这两个部分封装成事件对象,伪代码如下所示。有些游戏引擎称这种事件结构为消息(message)或命令(command),这些名称强调了本质上,把事件通知对象等于向对象发送消息或命令。
struct Event
{
const U32 MAX_ARGS= 8;
EventType m_type;
U32 m_numArgs;
EventArg m_aArgs[MAX_ARGS];
};
把事件封装为对象有这些好处:
- 仅需单个事件处理函数:任何数量的事件类型都可以表示为单个类的实例,仅需要单个虚函数处理所有事件类型(如
virtual void OnEvent(Event& event) - 持久性:事件对象把其类型及参数储存为数据,因此具有持久性,可用于储存队列稍后处理,或者复制及广播至多个接收者等
- 盲目地转发事件:对象可以转发事件至另一对象,而不需要知道事件的内容
事件类型
最简单的方法是使用一个全局的枚举,把每个事件类型映射至一个唯一整数。此方法的优点在于简单及高效,缺点是游戏中所有事件类型都要集中在一起(有点破坏封装的意味,见仁见智);事件类型是硬编码的,意味着新的事件类型不可通过数据驱动的方式来定义;枚举是索引,有时在中间插入新类型可能会引起一些次序相关的问题。
另一个事件类型编码方法是使用字符串。此方法是完全自由形式,但问题是有较大机会产生事件名称冲突,也有机会因拼错字而导致不能正常运作,字符串所消耗的内存也较多。不过可以做一些辅助工具来规避字符串带来的风险。在实际项目中,以上两种方法都有被使用,关键还是要权衡其利弊及项目的实际情况。
事件参数
事件的参数通常与函数的参数很相似,而且理论上可以支持任意种类和任意数量的参数。例如上面的代码的EventArg,如果是在C#/Java中,可以将任意类型参数封箱为object发送。但如果是在C/C++中,则只能使用void*指针来模拟,或者使用C++的template模拟。书中还描述了一种用C/C++ union实现的可以容纳多种类型的Variant数据结构,但通用性较弱,此处不赘述。
事件参数采用以索引为基础的集合,有个问题是参数的意义取决于储存的次序,发送方及接受方都必须理解事件以什么次序储存参数,这可能会导致混淆及bug。可以采用键值对的数据结构来封装一系列事件参数,并通过有实际意义命名的key来提取参数。
注册事件与事件处理器
大部分游戏对象只会关注很小的事件集合,每次都多播或广播事件是很低效的事情。为了提高事件处理的效率,可以让对象注册它们所关注的事件。例如,每个事件类型维护一个链表,内含关注该事件类型的对象,当特定事件触发时只需遍历列表逐个通知即可。
当游戏对象接收到一个事件,需要以某种方式做出回应,此过程称为事件处理,并通常实现成称为事件处理器(event handler)的函数。在一些高级语言中,可以通过存储函数指针(C/C++)或委托(C#)来注册回调函数,并在收到特定事件时调用。随后,取出EventArg并拆箱还原为原来的参数类型,对其进行处理。
游戏对象之间经常有依赖性,事件有时需要沿着依赖链传递下去。通常,事件传递的次序是预先由开发者决定的,在事件处理器中通过返回一个布尔值以表示该对象是否处理了该事件,以及是否继续往下转发。支持职责链的事件处理器大概如下所示:
virtual bool SomeObject::OnEvent(Event& event)
{
// 先调用基类的处理器
if (BaseClass::OnEvent(event))
return true; // 基类处理器已处理了事件,返回true表示不再转发
switch (event.GetType())
{
case EVENT_ATTACK:
ResponseToAttack(event.GetAttackinfo());
return false; // 可以转发事件给其他对象
case EVENT_HEALTH_PACK:
AddHealth(event.GetHealthPack().GetHealth());
return true; // 消化了事件,不再转发
// ......
default:
return false; // 无法识别该事件,转发给其他对象
}
}
即时事件处理器可能导致非常深的调用堆栈,例如对象A向对象B发送一个事件,然后B的事件处理器又发出另一个事件,如此反复。在逻辑有误或使用不当的情况下,极深的调用堆栈有可能会用尽堆栈空间(尤其是造成无限循环的事件发送)。关键还是要遵循一些编码原则,并把事件处理器实现为完全可重入函数,即以递归方式调用事件处理器并不会有任何不良副作用。
事件排队
上述的事件机制都是在发送事件时便马上被处理,有的引擎也会容许把事件排队留待未来某刻才进行处理。事件排队有以下好处:
- 控制事件处理的时机:让开发者多一道措施确保事件在安全及合适的时机获得处理
- 往未来投递事件的能力:可以设置事件的触发时间(例如下一帧、数秒后),这样就相当于实现了一个定时器。具体实现方式:把队列中的事件按送达时间排序,在每帧中先检查队列中首个事件的送达时间,若还未到送达时间,就可立即终止处理(排序保证了之后的事件也是未到时间的)
- 处理同时刻事件的优先次序:事件的送达时间通常会量化为整数帧,因此存在同一帧处理多个事件而无法确定顺序的问题。解决方法是为事件设置优先次序(根据需要用整型或若干档枚举表示),当同帧多事件触发时按优先级排序。
使用事件队列需要考虑的问题:
- 增加事件系统的复杂度:给系统加上此功能会增加开发时间和维护成本
- 深度复制事件及其参数:若事件是触发后即时处理的,事件参数所占用堆栈内存在事件消费完即销毁。但如果使用事件队列,则需要将整个事件对象(包括参数)深度复制到队列,这样才能确保没有仅对发送者作用域数据的悬垂引用,并且容许事件无限期储存
- 为队列中的事件做动态内存分配:要注意考虑深度复制导致的动态内存分配开销,可以考虑快速且不会造成碎片的池分配器或其他小型内存分配器
- 调试困难:不能在调试器的调用堆栈看出事件从何而来,以及检查发送者的状态和发送时的环境情况。调试延时事件会变得棘手,若事件会被对象转发的话调试会更加困难

