
- 1Java+springboot+Thymeleaf前后端分离项目:电影院在线选座购票售票系统答辩PPT参考
- 2GitHub Actions 定时运行代码:每天定时百度链接推送
- 3重新在jupyter notebook中安装pytorch_jupyter notebook安装pytorch
- 4nexus最全使用教程_nexus使用教程
- 5VNC实现Windows远程访问Ubuntu 16.04_vnc希望别人访问我
- 6对ListView滚动状态的监听_winform listbox监听滚动
- 7halcon 测量_9f0.kkmoes.xn--com-l27g
- 8什么是非抢占式和抢占式调度方式?抢占式调度方法和非抢占式调度方法有哪些?_抢占式调度和非抢占式调度
- 9Android Studio 中使用assets目录读取失败的问题_assetstudio无法读取数据
- 10元宇宙之XR(02)VR概念解读 & 分类说明_xr02
【Python入门指北】 Python计算机二级知识点_python二级 知识
赞
踩
Python计算机二级知识点
文章目录
- Python计算机二级知识点
- 一、turtle库
- 1.10 单元小结
- 二、基本数据类型
- 三、time库的使用
- 四、random库
- 五、 lambda函数
- 六、集合
- 七、 元祖
- 八、 列表
- 九、字典
- 十、jieba库
- 十一、文件
- 十二、wordcloud库

保留字
| and | elif | import | raise | global |
|---|---|---|---|---|
| as | else | in | return | nonlocal |
| assert | except | is | try | True |
| break | finally | lambda | while | False |
| class | for | not | with | None |
| continue | from | or | yield | |
| def | if | pass | del |
温度转换代码
#TempConvert.py
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F','f']:
C = (eveal(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:
F = 1.8*eval(TempStr[0:-1]) +32
print("转换后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
一、turtle库
1.1 turtle库概述
turtle库概述:turtle(海龟)库是turtle绘图体系的Python实现
1.turtle绘图体系:1969年诞生,主要用于程序设计入门
2.Python语言的标准库之一
3.入门级的图形绘制函数库
1.2 turtle原理
turtle(海龟)是一种真是的存在
1.有一只海龟,其实在窗体正中心,在画布上游走
2.走过的轨迹形成了绘制的图形
3.海龟有程序控制,可以变换颜色、改变宽度等
1.3 标准库

1.4 turtle的绘图窗体
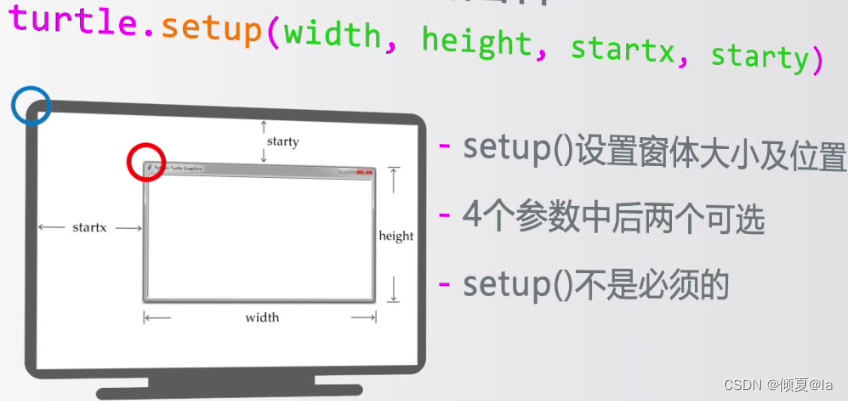
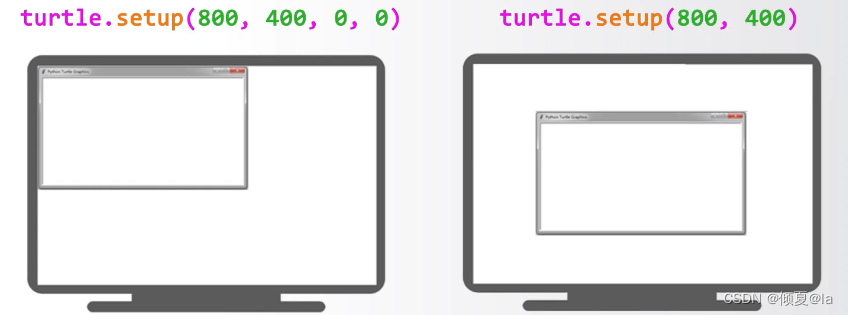
由于没有指定它左上角在屏幕的位置,那么系统会默认该窗口在该屏幕的正中心
1.5 turtle空间坐标体系

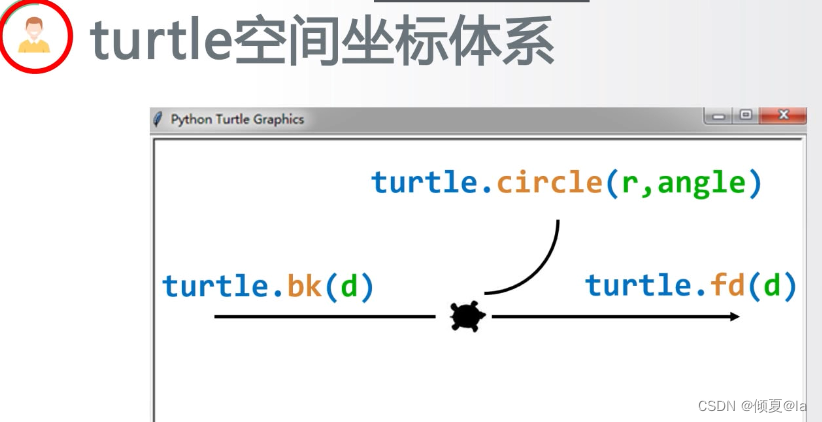
circle表示以海龟当前位置左侧的某一个点为圆心进行曲线运行
fd指的是向海龟的正前方向运行
bk指的是向海龟的反方向运行
对于绝对坐标来讲,turtle也就是海龟最开始在画布的正中心,那么正中心的坐标就是(0,0)
海龟的运行方向向着画布的右侧,所以整个的窗体的右方向是X轴,上方向是Y轴,由此构成了一个绝对坐标

1.6 turtle角度坐标体系

在空间坐标体系中X轴表示0度或360度,Y轴的正方向表示90度或-270度
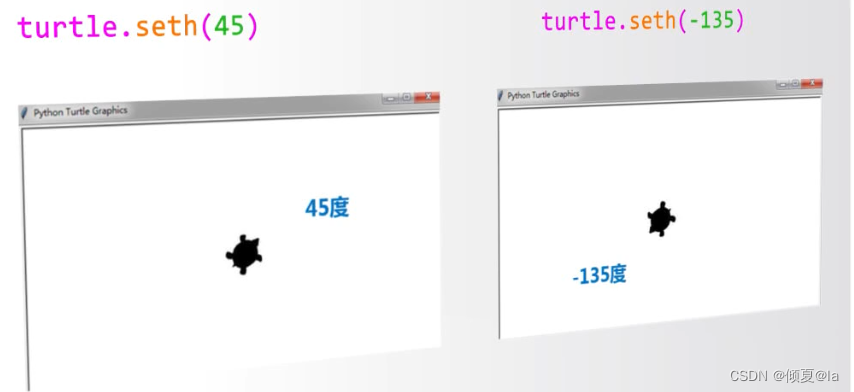

turtle提供了turtle.left(angle)和turtle.right(angle)两个函数,跟别让点前海龟向左或者向右去改变运行方向
Z型线段例子
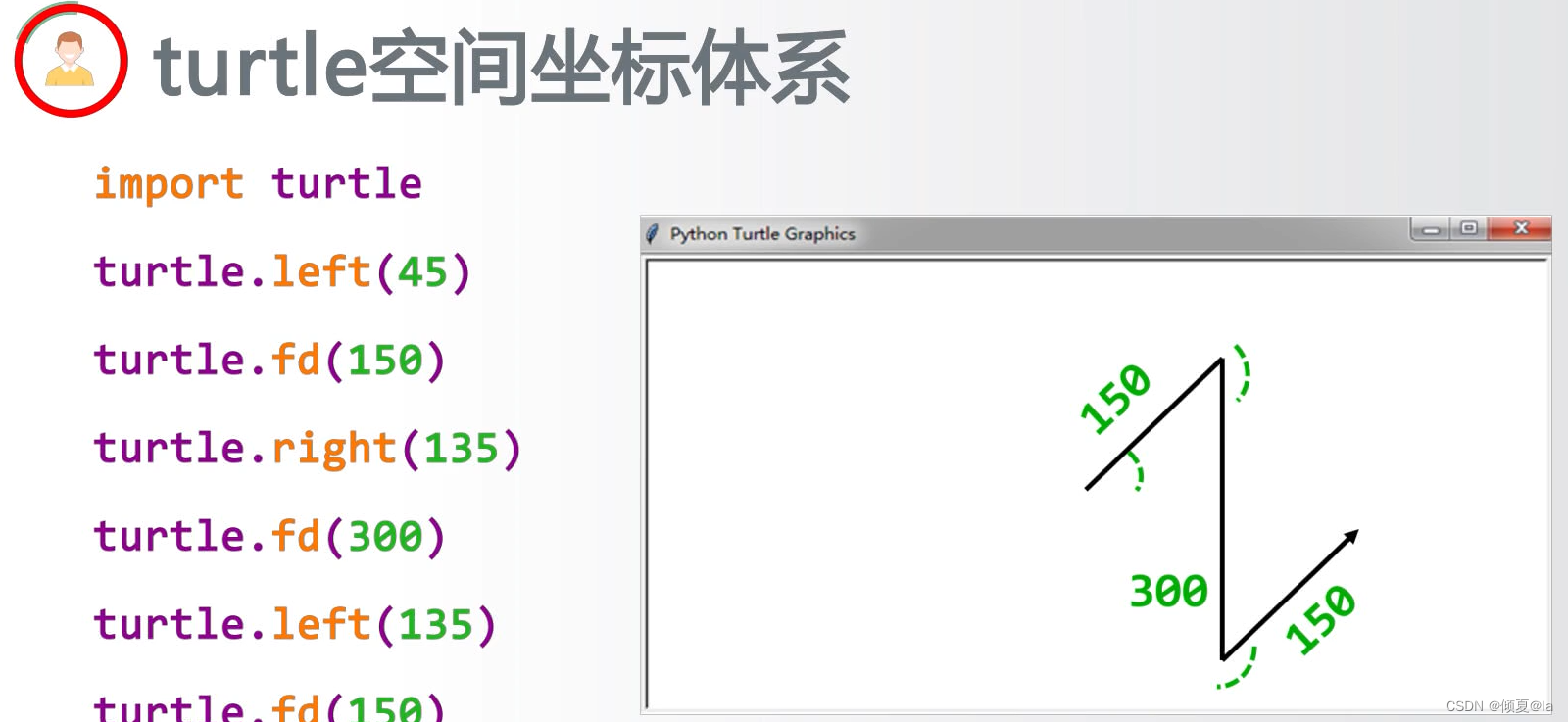
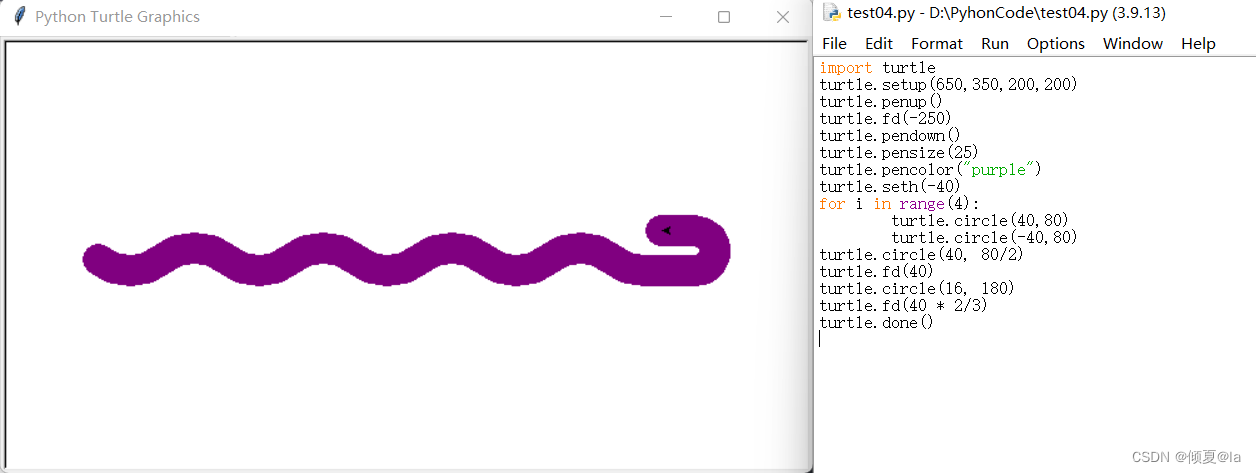
1.7 蟒蛇绘制实例
#PythonDraw.py import turtle turtle.setup(650,350,200,200) turtle.penup() turtle.fd(-250) turtle.pendown() turtle.pensize(25) turtle.pencolor("purple") turtle.seth(-40) for i in range(4): turtle.circle(40,80) turtle.circle(-40,80) turtle.circle(40, 80/2) turtle.fd(40) turtle.circle(16, 180) turtle.fd(40 * 2/3) turtle.done()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.8 RGB色采模式
由三种颜色构成的万物色
— RGB指红绿蓝三个通道的颜色组合
— 覆盖视力所能感知的所有颜色
— RGB每色的取值范围为0~255整或0-1小数

RGB常用色
| 英文名称 | RGB整数值 | RGB小数值 | 中文名称 |
|---|---|---|---|
| seashell | 255,245,238 | 1,0.96,0.93 | 海贝色 |
| gold | 255,215,0 | 1,0.84,0 | 金色 |
| pink | 255,192,203 | 1,0.75,0.80 | 粉红色 |
| brown | 165,42,42 | 0.65,0.16,0.16 | 棕色 |
| purple | 160,32,240 | 0.63,0.13,0.94 | 紫色 |
| tomato | 255,99,71 | 1,0.93,0.28 | 番茄色 |
| white | 255,255,255 | 1,1,1 | 白色 |
| yellow | 255,255,0 | 1,1,0 | 黄色 |
| megenta | 255,0,255 | 1,0,1 | 洋红色 |
| cyan | 0,255,255 | 0,1,1 | 青色 |
| blue | 0,0,255 | 0,0,1 | 蓝色 |
| black | 0,0,0 | 0,0,0 | 黑色 |
turtle库默认采用RGB的小数来表示颜色,当然也可以使用整数值来表示颜色

1.10 单元小结
1.turtle库的海龟绘图法
2.turtle.setup()调整绘图窗体在电脑屏幕中的布局
3.画布上以中心为原点的空间坐标系:绝对坐标&海龟坐标
4.画布上以空间x轴为0度的角度坐标系:绝对角度&海龟角度
5.RGB色彩体系,整数值&小数值,色彩模式切换
二、基本数据类型
2.1 数字类型及其操作
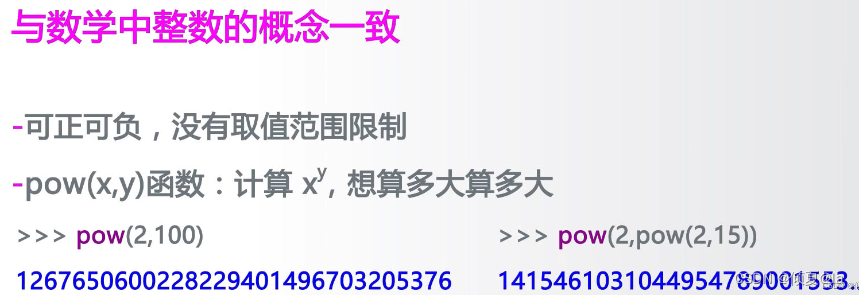
2.1.1 整数类型

2.1.2 浮点类型


为什么计算机会出现不确定位数的问题呢?其实不确定位数不仅是在Python中存在,在其他的很多编程语言也都存在,它涉及到了计算机对数字运算的内部实现原理
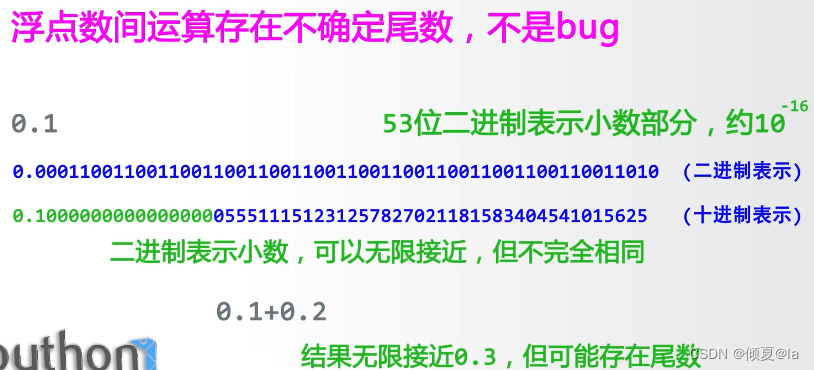
由于计算机中二进制与十进制之间,不存在严格的对等关系,所以0.1再用二进制表示的时候它是一个无限的小数,那么计算机只能截取其中的53位,无限接近0.1,但它并不是真正的等于0.1


2.1.3 复数类型


2.2数值运算操作符
操作符是完成运行算的一种符号体系
| 操作符及使用 | 描述 |
|---|---|
| x+y | 加,x与y之和 |
| x-y | 减,x与y之差 |
| x+y | 乘,x与y之积 |
| x*y | 减,x与y之差 |
| x/y | 除,x与y之商 10/3结果是3.333333333333335 |
| x//y | 整数除,x与y之整数商 10//3结果是3 |
操作符是完成运算的一种符号体系

二元操作符有对应的增强赋值操作符

数字类型的关系

2.3 数值运算函数
一些以函数形式提供的数值运算功能
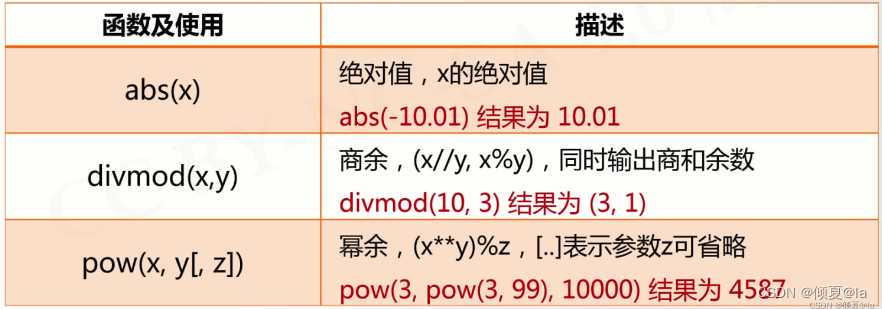
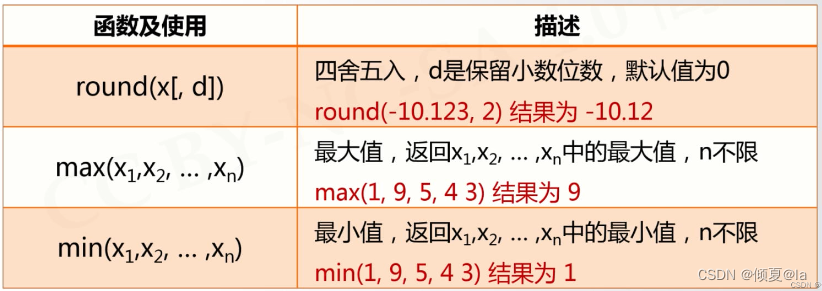
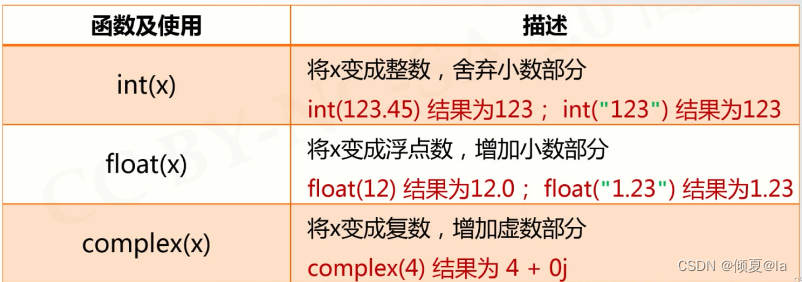
2.4 实列:天天向上的力量

#DayDayUpQ1.py
dayup = pow(1.001, 365)
daydown = pow(0.999,365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
- 1
- 2
- 3
- 4
问题2:千分之五和百分之一的力量
##DayDayUpQ2.py
dayfactor = 0.005 #dayfactor = 0.01
dayup = pow(1+dayfactor, 365)
dayup = pow(1-dayfactor, 365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
- 1
- 2
- 3
- 4
- 5

##DayDayUpQ3.py
dayup = 1.0
dayfactor = 0.01
for i in range(365):
if i % 7 in [0,6]:
dayup = dayup*(1-dayfactor)
else:
dayup = dayup*(1+dayfactor)
print("工作日的力量:{:.2f}".format(dayup)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

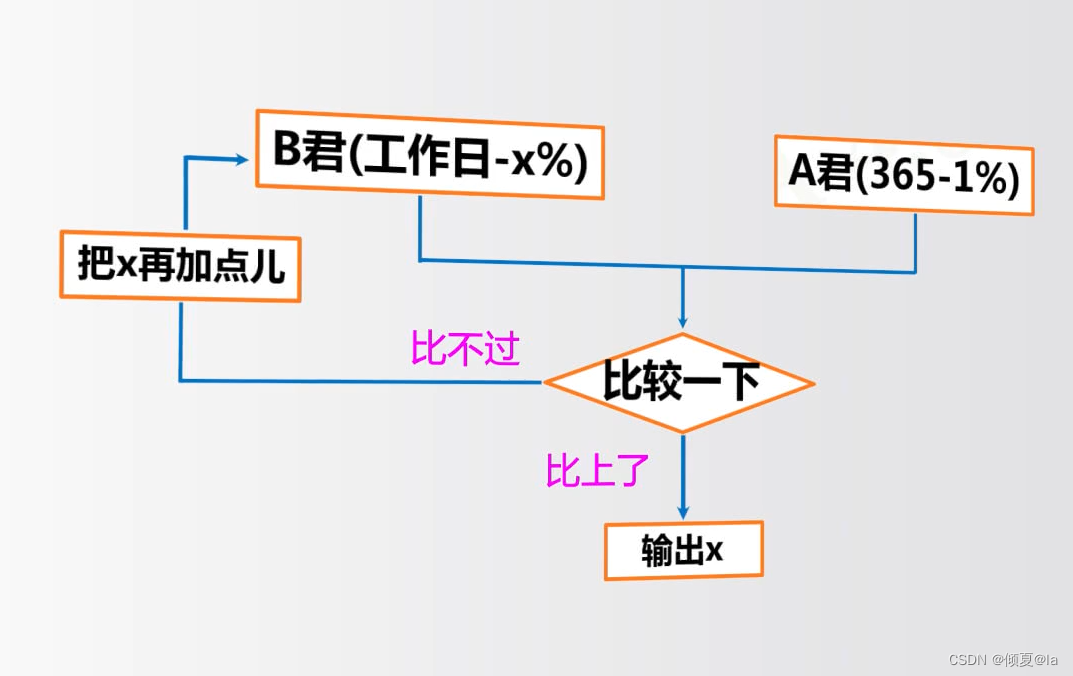
##DayDayUpQ4.py
def dayup(df):
dayup = 1
for i in range(365):
if i % 7 in [0,6]:
dayup = dayup*(1-df)
else:
dayup = dayup*(1+df)
return dayup
dayfactor = 0.01
while dayup(dayfacrot) < 37.78:
dayfactor += 0.001
print("工作日的努力参数:{:.3f}".format(dayfactor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

2.4字符串类型及其操作
2.4.1 字符串



如果在字符串中出现双引号,那么最外层的引号就要使用单引号,这样中出现的双引号就被当做字符处理。
反之如果在字符串中,希望使用单引号那么两侧可以使用双引号来表示字符串,这样其中的单引号就变成了字符。
如果希望字符串中既有单引号右有双引号,可以使用三个单引号括起来
字符串的序号

2.4.2 字符串的使用
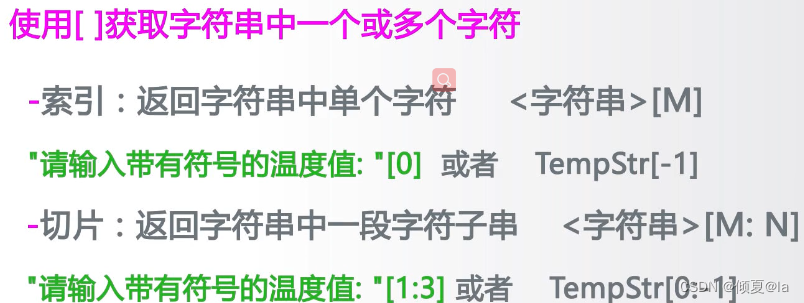
2.4.3 字符串切片高级用法

2.4.4 字符串的特殊字符

2.4.5 字符串的操作符
字符串的操作符:由0个或者多个字符组成的有序字符序列

2.4.6 实例:获取星期字符串
–输入:1-7的整数,表示星期几
–输出:输入整数对应的星期字符串
–列如:输入3,输出 星期三
获取星期字符串
#WeekNamePrintV1.py
weekStr = "星期一星期二星期三星期四星期五星期六星期日"
weekId = eval(input("请输入星期数字(1-7:)"))
pos = (weekId - 1 ) * 3
print(weekStr[pos:pos+3])
- 1
- 2
- 3
- 4
- 5
#WeekNamePrintV2.py
weekStr = "一二三四五六日"
weekId = eval(input("请输入星期数字(1-7:)"))
print("星期" + weekStr[weekId-1])
- 1
- 2
- 3
- 4
2.4.7字符串处理函数
字符串处理函数:一些以函数形式提供的字符串处理功能

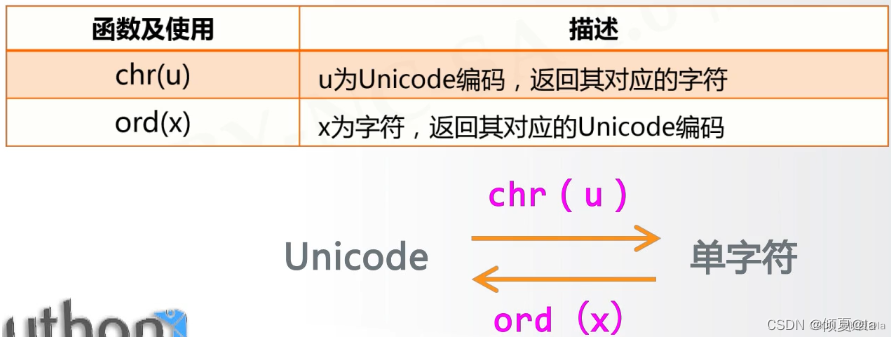
2.4.8 Unicode编码
Python字符串的编码方式
1.统一字符串的编码方式
2.从0到1114111(0x10FFFF)空间,每个编码对应一个字符
3.Python字符串中每个字符都是Unicode编码字符
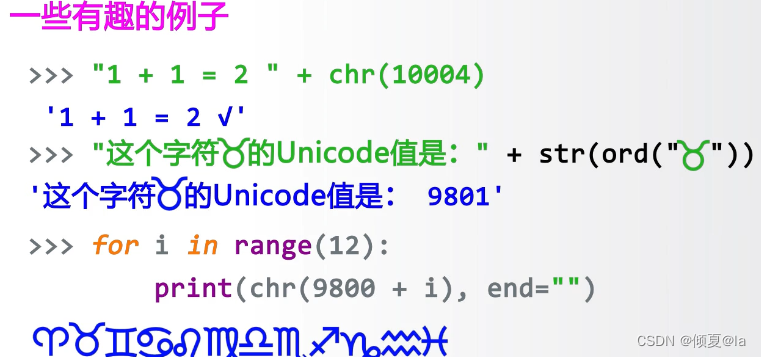
2.4.9 字符串处理方法
字符串处理方法:一些以方法形式提供的字符串处理功能



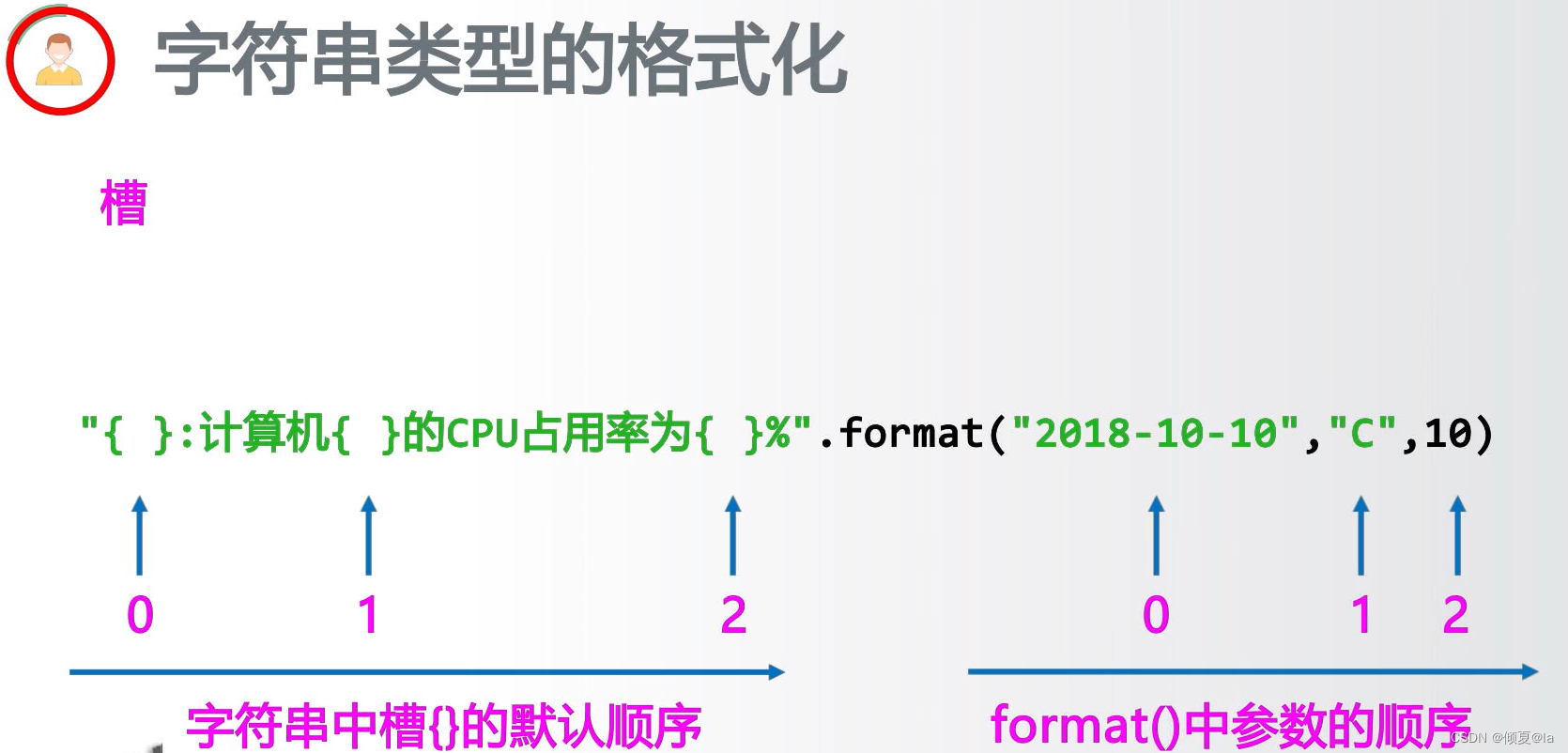
2.4.10 字符串类型的格式化
格式化是对字符串进行格式表达的方式
--字符串格式化使用 .format() 方法,用法如下:
<模板字符串>.format(<逗号分隔的参数>)
- 1
- 2



三、time库的使用
3.1 time库的概述
time库是 Python 中处理时间的标准库
--计算机时间的表达式
--提供获取系统时间并格式化输出功能
--提供系统级精确计时功能,用于程序性能分析
- 1
- 2
- 3
import time
time.< b >()
- 1
- 2
- 3
time 库包括三类函数
--时间获取 :time() ctime() gmtime()
--时间格式化 :strftime() strptime()
--程序计时 :sleep() perf_counter()
- 1
- 2
- 3

时间戳是一个很长的浮点数,他表示从1970年1月1日0:00开始到当前这一时刻为止的一个以秒为单位的数值

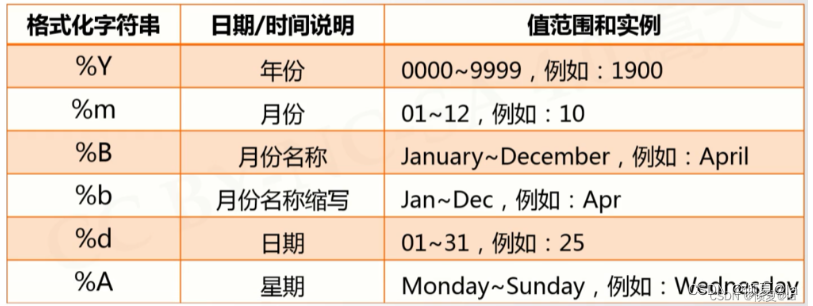
3.2 时间格式化
将时间以合理的方式展示出来
--格式化 : 类似字符串格式化,需要有展示模板
--展示模板有特定的格式化控制符组成
--strftime()方法
- 1
- 2
- 3

>>>t = time.gmtime()
>>>time.strftime("%Y-%m-%d %H:%M:%S",t) #对应时间>>>'2022-10-30 13:35:10'
>>>timeStr = '2022-10-30 13:35:10'
>>>time.strptime(timeStr,"%Y-%m-%d %H:%M:%S")
- 1
- 2
- 3
- 4
- 5

strptime的作用是将一个字符串转换为一个计算机内部可以操作的时间,也可以将时间转换为计算机内部表达的一个时间浮点数
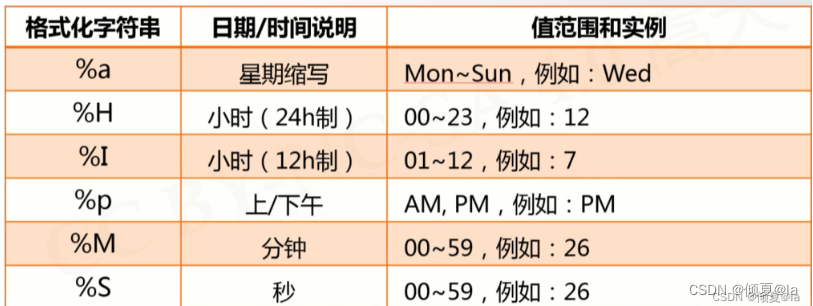
3.3 程序计时
--程序计时是指测量起止动作所经历时间的过程
--测量时间:per_counter()
--产生时间:sleep()
- 1
- 2
- 3


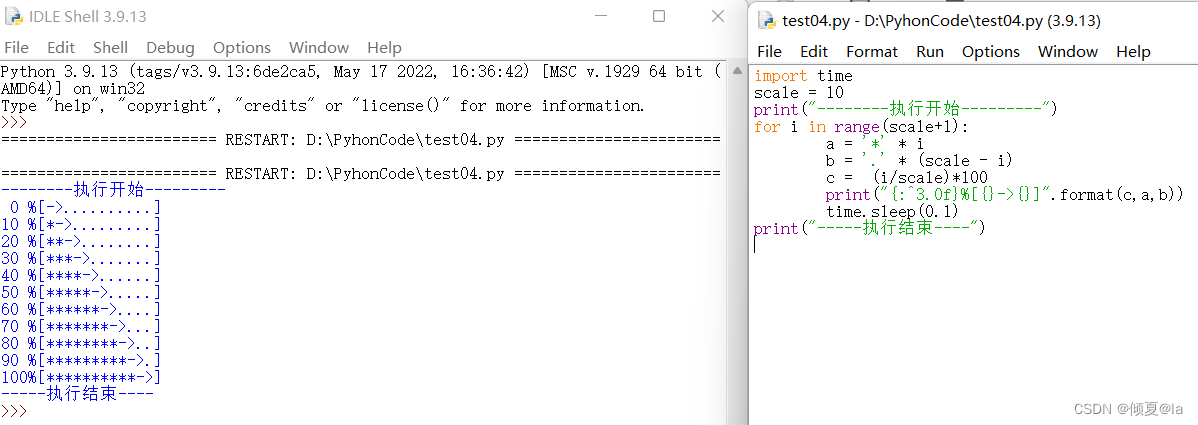
3.4 实列:文本进度条
#TextProBarV1.py
import time
scale = 10
print("--------执行开始---------")
for i in range(scale+1):
a = '*' * i
b = '.' * (scale - i)
c = (i/scale)*100
print("{:^3.0f}%[{}->{}]".format(c,a,b))
time.sleep(0.1)
print("-----执行结束----")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
单行动态刷新
刷新的关键是\r
--刷新的本质是:用后打印的字符覆盖之前的字符
--不能换行:print()需要被控制
--能回退:打印后光标退回到之前的位置\r
- 1
- 2
- 3
#TextProBarV1.py
import time
for i in range(101):
print("\r{:3}%".format(i),end="")
time.sleep(0.1)
- 1
- 2
- 3
- 4
- 5
文本进度条
#TextProBarV3.py
import time
scale = 50
print("执行开始".center(scale//2,"."))
start = time.perf_counter()
for i in range(scale+1):
a = '*' * i
b = '.' * (scale - i )
c = (i/scale)*100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->]{:.2f}s".format(c,a,b,dur),end='')
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'.'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.5 程序的控制结构
3.5.1 单分支结构
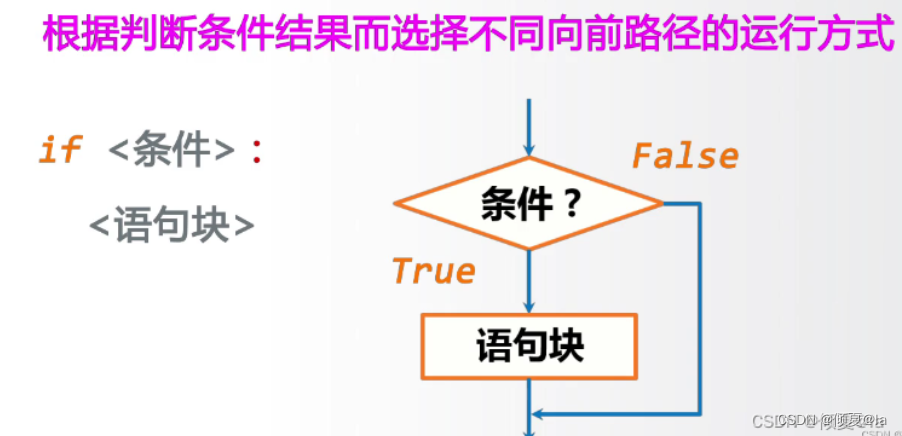
单分支示列
guess = eval(input())
if guess == 99: if True:
print("猜对了") print("条件正确")
- 1
- 2
- 3
3.5.2 二分支结构
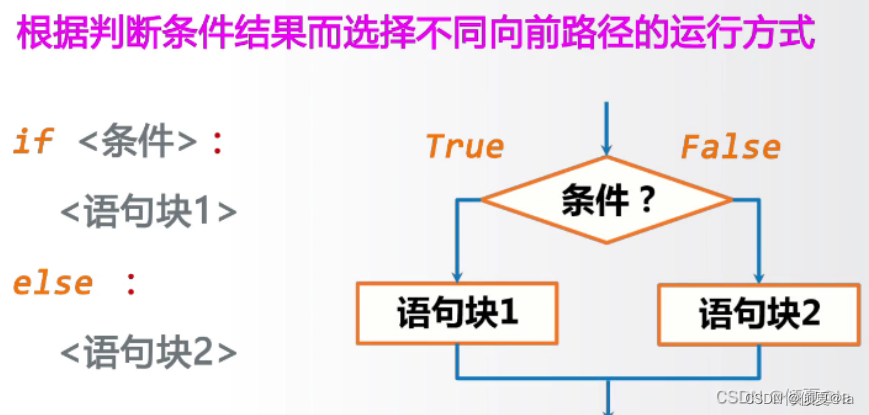
二分支示列
guess = eval(input())
if guess == 99: if True:
print("猜对了") print("语句块1")
else: else:
print("猜错了") print("语句块2")
- 1
- 2
- 3
- 4
- 5
紧凑形式: 适用于简单表达式的二分支结构
< 表达式1 > if < 条件 > else < 表达式2 >
guess = eveal(input())
print("猜{}了".format("对" if gues == 99 else "错"))
- 1
- 2
- 3
- 4
3.5.3 多分支结构
对不同分数分级的问题
score = eveal(input())
if score >= 60:
grade = 'D'
elif score >= 70:
grade = 'C'
elif score >= 80:
grade = 'B'
elif score >= 90:
grade = 'A'
print("输入成绩属于级别{}".format(grade))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.6 条件判断
操作符

3.7 条件组合
用于条件组合的三个保留字

3.8 条件判断及组合实列:
示列
guess = eval(input())
if guess > 99 or guess < 99:
print("猜错了")
else:
print("猜对了")
if not True:
print("语句块1")
else:
print("语句块2")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.9 异常处理

异常处理的基本使用
try: try:
< 语句块1 > < 语句块1 >
except: except < 异常类型 >:
< 语句块2 > < 语句块2 >
- 1
- 2
- 3
- 4
示列-2
try:
num = eval(input("请输入一个整数:"))
print(num**2)
except NameError: 标注异常类型后,仅响应该异常
print("输入的不是整数") 异常类型的名字等同于变量
- 1
- 2
- 3
- 4
- 5
异常处理的高级使用
try:
< 语句块1 >
except:
< 语句块2 >
else: --finally对应语句块4一定执行
< 语句块3 > --else对应语句块3在不发生异常时执行
finally:
< 语句块4 >
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.10 示列:身体质量指数BMI
国际:世界卫生组织 国内:国家卫生健康委员会

思路方法
--难点在于同时输出国际和国内对应的分类
--思路1:分别计算并给出国际和内BMI分类
--思路2:混合计算并给出国际和国内BMI分类
- 1
- 2
- 3

#CalBMIv1.py
height, weight = eval(input("请输入身高(米)和体重\(公斤)[逗号隔开]:"))
bmi = weight / pow(height, 2)
print("BMI 数值为:{:.2f}".format(bmi))
who = ""
if bmi < 18.5:
who = "偏瘦"
elif 18.5 <= bmi < 25:
who = "正常"
elif 25 <= bmi < 30:
who = "偏胖"
else:
who = "肥胖"
print("BMI 指标为:国际'{0}'".format(who))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
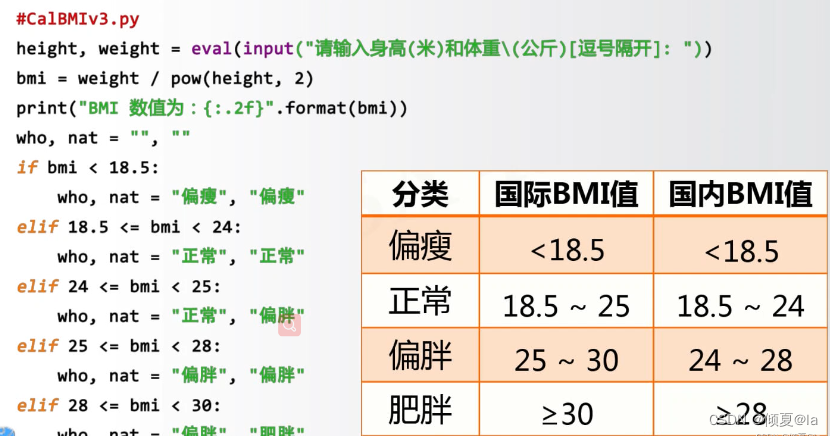
#CalBMIv3.py height, weight = eval(input("请输入身高(米)和体重\(公斤)[逗号隔开]:")) bmi = weight / pow(height, 2) print("BMI 数值为:{:.2f}".format(bmi)) who,nat = "" if bmi < 18.5: who, nat = "偏瘦","偏瘦" elif 18.5 <= bmi < 24: who, nat = "正常","正常" elif 24 <= bmi < 25: who, nat = "正常","偏胖" elif 25 <= bmi < 28: who, nat = "偏胖","偏胖" elif 28 <= bmi < 30: who, nat = "偏胖","肥胖" else: who, nat = "肥胖","肥胖" print("BMI 指标为:国际'{0}',国际'{1}'".format(who,nat))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.11 程序的循环结构
3.11.1 遍历循环

3.11.2 循环遍历的应用
计数循环(N次)
for i in range(N):
< 语句块 >
--遍历由range()函数产生的数字序列,产生循环
- 1
- 2
- 3
- 4
>>>for i in range(5): >>>for i in range(5):
print(i) print("Hello:",i)
0 hello: 0
1 hello: 1
2 hello: 2
3 hello: 3
4 hello: 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
for i in range(M,N,K): #k为步长
< 语句块 >
--遍历由range()函数产生的数字序列,产生循环
- 1
- 2
- 3
- 4
>>>for i in range(1,6): >>>for i in range(1,6,2):
print(i) print("Hello:",i)
0 hello: 1
1 hello: 3
2 hello: 5
3
4
5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.11.3 字符串遍历循环
for c in s:
< 语句块 >
--s是字符串,遍历字符串每个字符,产生循环
- 1
- 2
- 3
>>>for c in "Python":
print(c,end=",")
P,y,t,h,o,n,
- 1
- 2
- 3
- 4
3.11.4 列表编历循环
for item in ls:
< 语句块 >
--ls是一个列表,遍历其每个元素,产生循环
- 1
- 2
- 3
- 4
for item in [666,"python",999]:
print(item,end=",")
666,python,999,
- 1
- 2
- 3
- 4
3.11.5 文件编历循环
for line in fi:
< 语句块 >
--fi是一个文件表示符,遍历其每行,产生循环
- 1
- 2
- 3
- 4

3.12 无限循环
由条件控制的循环运行方式
while <条件>:
<语句块>
反复执行语句块,直到条件不满足时结束
- 1
- 2
- 3
- 4
无限循环的应用
无限循环的条件
a=3 a=3
while a>0: while a>0:
a = a - 1 a = a + 1
print(a) print(a)
2 4
1 5
0 ... (Ctrl + C 退出执行)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.13 循环控制保留字
| 循环控制保留字 | |
|---|---|
| break | break跳出并结束当前整个循环,执行循环后的语句 |
| continue | continue结束当次循环,继续执行后续次数循环 |
| break和continue可以与for和while循环搭配使用 |
3.14 循环的高级用法
break 和 continue
>>>for c in "PYTHON": >>>for c in "PYTHON":
if c == "T": if c == "T":
continue break
print(c,end="") print(c,end="")
PYHON PY
- 1
- 2
- 3
- 4
- 5
- 6
- 7
continue的含义指:在当次循环体执行的时候,如果遇到了continue保留字,那么当次循环就结束,去做下一次循环
break的含义指:如果遇到了break保留字,整个循环结束
s = "PYTHON" s = "PYTHON"
while s != "": while s != "":
for c in s: for c in s:
print(c,end="") if c == "T":
s = s[:-1] break
print(c,end="")
s = s[:-1]
--break仅跳出当前最内层循环
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
PYTHONPYTHOPYTHPYTPYP | PYPYPYPYPYP
一个break只能跳出一层循环
3.15 循环的拓展
循环与else
1.当循环没有被break语句退出时,执行else语句块
2.else语句块作为"正常"完成循环的奖励
3.这里else的用法与异常处理中else用法相似
- 1
- 2
- 3
for c in "PYTHON": for c in "PYTHON":
if c == "T": if c == "T":
continue break
print(c,end="") print(c,end="")
else: else:
print("正常退出") print("正常退出")
PYTHON正常退出 PY
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
四、random库
4.1 random库概述
random 库是使用随机数的Python标准库
--伪随机数:采用梅森旋转算法生成的(伪)随机序列中元素
--random 库主要用于生成随机数
--使用random库: import random
- 1
- 2
- 3
random 库包括两类函数,常用共8个
--基本随机数函数:seed(), random()
--拓展随机数函数:randint(),getrandbits(),uniform(),randrange(),choice(),shuffle()
- 1
- 2
4.2 基本随机函数


>>>import random
>>>random.seed(10)
>>>random.random()
0.5714025946899135
>>>random.random()
0.4288890546751146
....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
种子只需给一次,那么随机数就会随着每次调用产生不同的随机数
4.3 拓展随机数函数



4.4 实列:圆周率的计算

#CalPiV1.py
pi = 0
N = 100
for k in range(N):
pi += 1/pow(16,k)*( \
4/(8*k+1) - 2/(8*k+4) - \
1/(8*k+5) - 1/(8*k+6))
print("圆周率值是:{}".format(pi))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

#CalPiV2.py
from random import random
from time import perf_counter #perf_counter对程序运行进行计时
DARTS = 1000 * 1000 #DARTS指的是我们当前区域中抛撒点的总数量
hits = 0.0 #hits指的是目前在圆内部的点的数量
start = perf_counter() #当前系统时间的一个值
for i in range(1, DARTS+1):
x, y = random(), random() #random函数返回的是0到1之间的小数值
dist = pow(x ** 2 + y ** 2, 0.5) #用点到圆心的距离是否等于1,来判断点是否在圆内
if dist <= 1.0: #如果条件成立则说明点在圆内
hits = hits + 1
pi = 4 * (hits/DARTS)
print("圆周率值是: {}".format(pi))
print("运行时间是: {:.5f}s".format(perf_counter() - start))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.5 函数和代码复用
4.5.1 函数的定义与使用
4.5.1.1 函数的定义

函数是一段代码的表示
def <函数名>(<参数(0个或多个)>):
<函数体>
return <返回值>
- 1
- 2
- 3
案例:计算n!
def fact(n): #fact()函数名 n为参数
s = 1
for i in range(1,n+1):
s *= i
return s #返回值
- 1
- 2
- 3
- 4
- 5
4.5.1.2 函数调用
调用是运行函数代码的方式
def fact(n):
s = 1 #--调用时要给出实际参数
for i in range(1,n=1): #--实际参数替换定义中的参数
s *= i #--函数调用后得到返回值
return s
fact(10) #函数调用
- 1
- 2
- 3
- 4
- 5
- 6
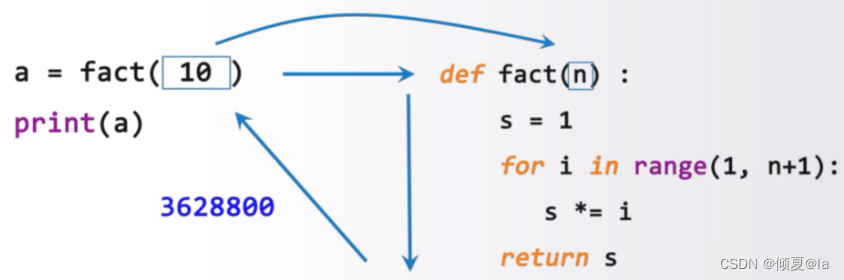
4.5.2 参数个数
函数可以有参数,也可以没有,但必须保留括号
def <函数名>():
<函数体>
return <返回值>
def fact():
print("我是函数")
- 1
- 2
- 3
- 4
- 5
4.5.3 可选参数
函数定义式可以为某些参数指定默认值,构成可选参数
def <函数名>(<非可选参数>,<可选参数>):
<函数体>
return <返回值>
- 1
- 2
- 3
计算 n!//m
def fact(n,m=1): >>>fact(10)
s = 1 3628800
for i in range(1,n+1):
s *=i >>>fact(10,5)
return s//m 725760
- 1
- 2
- 3
- 4
- 5
4.5.4 可变参数
函数定义时可以设计可变数量参数,及不确定参数总数量
def <函数名>(<参数>, *b):
<函数体>
return <返回值>
- 1
- 2
- 3
4.5.5 参数传递的两种方式
函数调用时,参数可以按照位置或名称方式传递
def fact(n,m=1): >>>fact(10,5) #按位置传递
s = 1 725760
for i in range(1,n+1):
s *=i >>>fact(m=5,n=10) #按名称传递
return s//m 725760
- 1
- 2
- 3
- 4
- 5
4.5.6 函数的返回值
函数可以返回0个或多个结果
--return 保留字用来传递返回值
--函数可以有返回值,也可以没有,可以有return,也可以没有
--return可以传递0个返回值,也可以传递任意多个返回值
- 1
- 2
- 3
def fact(n,m=1): >>>fact(10,5)
s = 1 (725760,10,5) #元组类型
for i in range(1,n+1):
s *=i >>>a,b,c = fact(10,5)
return s//m,n,m >>>print(a,b,c)
725760 10 5
- 1
- 2
- 3
- 4
- 5
- 6
4.6 局部变量和全局变量

规则1:局部变量和全局变量是不同变量
--局部变量是函数内部的占位符,与全局变量可能重名但不相同
--函数运算结束后,局部变量被释放
--可以使用global保留字在函数内部使用全局变量
- 1
- 2
- 3




五、 lambda函数
5.1 lambda函数
lambda 函数返回函数名作为结果
--lambda函数是一种匿名函数,即没有名字的函数
--使用lambda保留字定义,函数名是返回结果
--lambda函数用于定义简单的、能够在一行表示的函数
- 1
- 2
- 3
<函数名> = lambda <参数>:<表达式>
等价于
def <函数名>(<参数>):
<函数体>
return <返回值>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
>>>f = lambda x,y : x + y
>>>f(10,15)
25
>>>f = lambda : "lambda函数"
>>>print(f())
lambda函数
- 1
- 2
- 3
- 4
- 5
- 6
5.2 lambda函数的应用
谨慎使用lambda函数
--lambda函数主要用作一些特定函数或方法的参数
--函数有一些固定使用方式,建议逐步掌握
--一般情况,建议使用def定义的普通函数
- 1
- 2
- 3
5.3 实列:七段数码管绘制
基本思路
--步骤1:绘制单个数字对应的数码管
--步骤2:后的一串数字,绘制对的数码管
--步骤3:获得当前系统时间,绘制对应的数码管
- 1
- 2
- 3
5.4 代码复用与函数递归
5.4.1 代码复用

5.4.2 模块化设计
分而治之
--通过函数或对象封装将程序划分为模块间的表达
--具体包括:主程序,子程序和子程序间关系
--分而治之:一种分而治之,分层抽象,体系化的设计思想
1.紧耦合:两个部分之间交流很多,无法独立存在
2.松耦合:两个部分之间交流较少,可以独立存在
3.模块内部紧耦合、模块之间松耦合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5.4.3 递归
递归的定义:函数定义中调用函数自身的方式

5.4.4 递归函数的调用过程
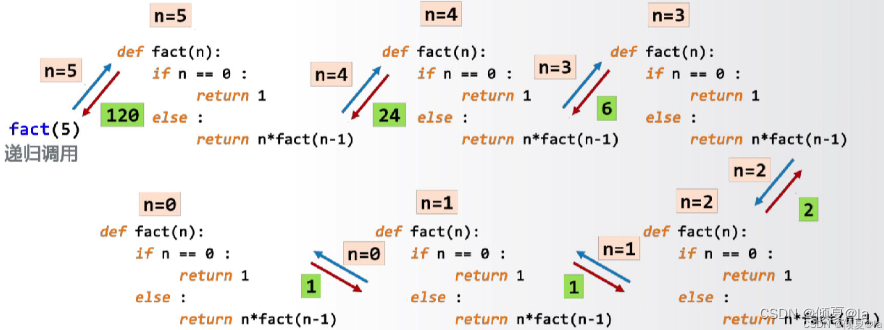
5.5 斐波那契数列
公式 F(n) = F(n-1) + F(n-2)
def f(n):
if n == 1 or n == 2: #--函数 + 分支结构
return 1
else: #--递归链条
return f(n-1) + f(n-2) #递归基例
- 1
- 2
- 3
- 4
- 5
5.6 PyInstaller库的使用
5.6.1 PyInstaller库概述


5.6.2 PyInstaller库的安装
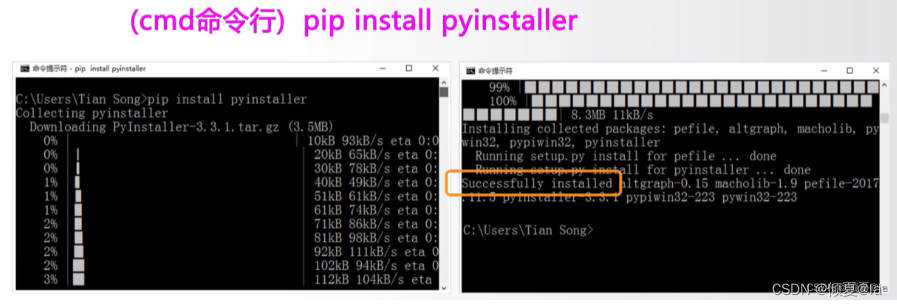
5.6.3 PyInstaller库简单的使用

5.6.4 PyInstaller库的常用参数
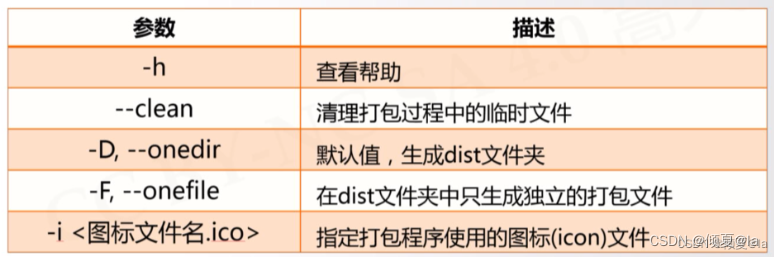
5.6.5 使用举例

六、集合
6.1 集合类型的定义
集合是多个元素的无序组合
--集合类型与数学中的集合概念一致
--集合元素之间无序,每个元素唯一,不存在相同元素
--集合元素不可更改,不能是可变数据类型 为什么?
--集合用大括号 {} 表示,元素间用逗号分隔
--建立集合类型用 {} 或者 set()
--建立空集合类型,必须用set() 。因为 {} 用来创建空元组,已经被元组使用
- 1
- 2
- 3
- 4
- 5
- 6
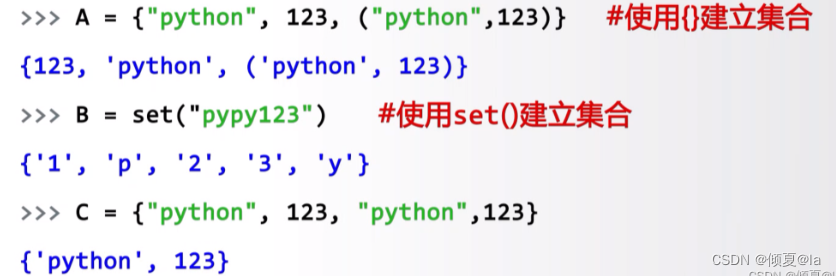

重点:
1.集合用大括号{}表示,元素间用逗号分隔
2.集合中每个元素唯一,不存在相同元素
3.集合元素之间无序
- 1
- 2
- 3
6.2 集合操作符
| 操作符及应用 | 描述 |
|---|---|
| S | T | 返回一个新集合,包括在集合S和T中的所有元素 |
| S - T | 返回一个新集合,包括在集合S但不在T中的元素 |
| S & T | 返回一个新集合,包括同时在集合S和T中的元素 |
| S ^ T | 返回一个新集合,包括在集合S和T中的非相同元素 |
| S <= T 或 S <T | 返回True/False,判断S和T的子集关系 |
| S >= T 或 S > T | 返回True/False,判断S和T的包含关系 |
6.3 集合处理方法
| 操作函数或方法· | 描述 |
|---|---|
| S.add(x) | 如果x不在集合S中,将x增加到S |
| S.discard(x) | 移除S中元素x,如果x不在集合S中,不报错 |
| S.remove(x) | 移除S中元素x,如果x不在集合S中,产生KeyError异常 |
| S.clear() | 移除S中所有元素 |
| s.pop() | 随机返回S的一个元素,更新S,若S为空产生KeyError异常 |
| S.copy() | 返回集合S的一个副本 |
| len(S) | 返回集合S的元素个数 |
| x in S | 判断S中元素x,x在集合S中,返回True,否则返回False |
| x not in S | 判断S中元素x,x不在集合S中,返回True,否则返回False |
| set(x) | 将其他类型变量x转变为集合类型 |
>>>A = {"p","y",123}
>>>for item in A:
print(item,end="")
p123y
>>>A
{123, 'p', 'y'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
>>>A = {"p","y",123}
>>>for item in A:
try:
while True:
print(A.pop(),end="")
except:
pass
py=123y
>>>A
set()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.4 集合类型应用场景
数据去重:集合类型所有元素无重复
>>>ls = ["p","p","y","y",666]
>>>s = set(ls) #利用了集合无重复元素的特点
{'p','y',666}
>>>lt = list(s) #将集合转换为列表
['p','y',666]
- 1
- 2
- 3
- 4
- 5
6.5 序列类型及操作
6.5.1 序列类型通用操作符
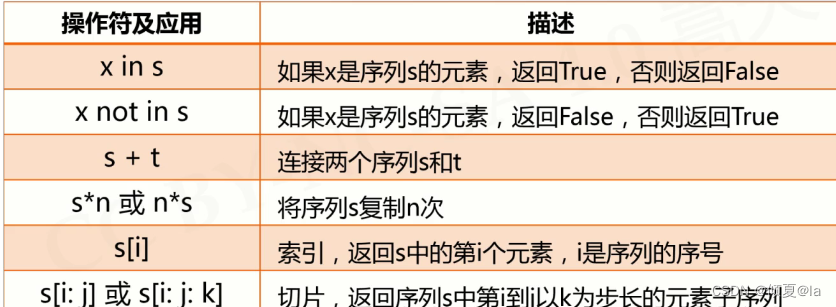
6.5.2 函数和方法
| 函数和方法 | 描述 |
|---|---|
| len(S) | 返回序列S的长度 |
| min(S) | 返回序列s的最小元素,s中元素需要可比较 |
| S.index(x)或S.index(x,i,j) | 返回序列S从i开始到j位置中第一次出现元素x的位置 |
| S.count(x) | 返回序列S中出现x的总次数 |
6.5.3 序列类型操作实列
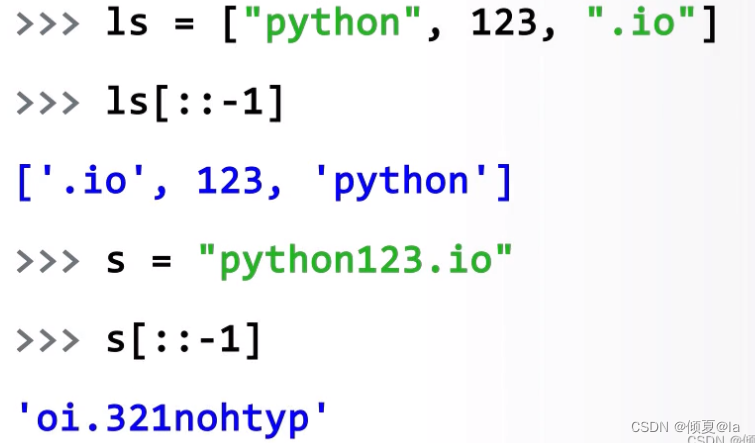
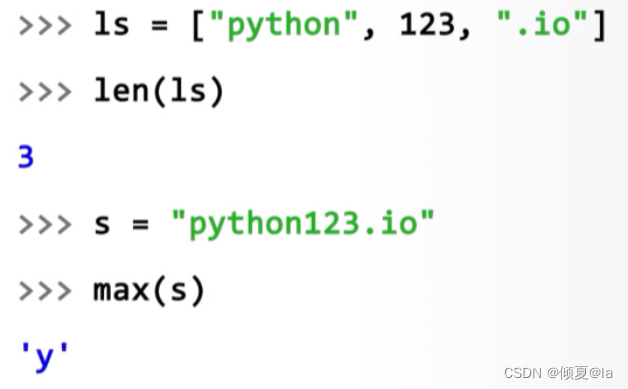
七、 元祖
7.1 元祖类型定义


7.1 元祖类型操作

八、 列表
8.1 列表类型定义

8.2 列表类型操作函数和方法

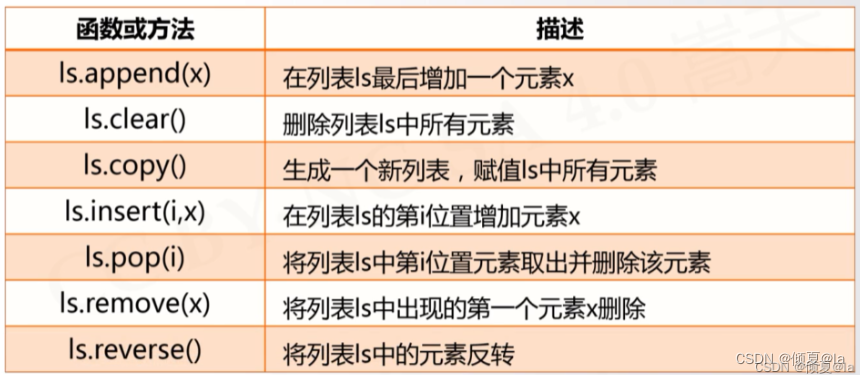
8.3 列表类型操作


8.4 列表功能



8.5 序列类型应用场景


8.6 序列类型及操作

8.7 基本统计值
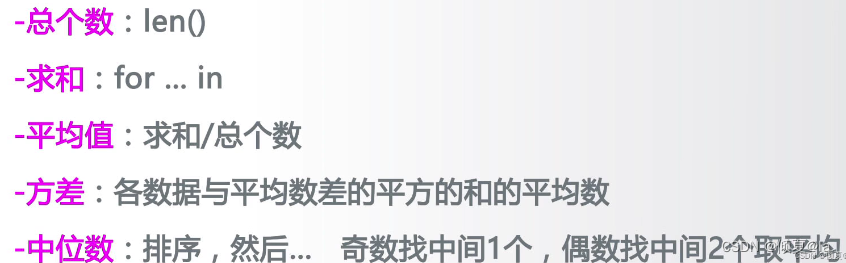
8.7.1 基本统计值计算





九、字典
9.1 字典类型定义


9.2 字典类型定义和使用

9.3 字典类型操作函数和方法

9.4 字典类型操作

9.5 列表类型操作函数和方法

9.6 字典类型操作

9.7 字典功能

9.8 字典类型应用场景

十、jieba库
10.1 jieba库的安装
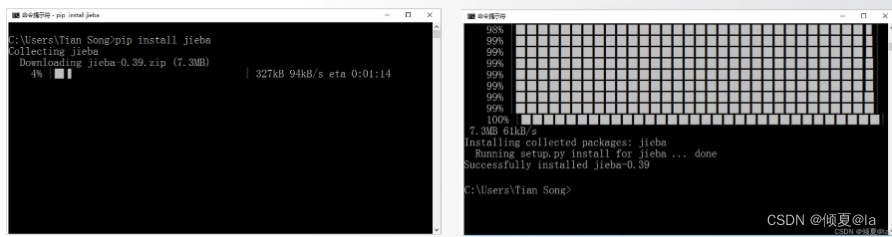
10.2 jieba分词的三种模式

10.3 jieba库常用函数


10.4 实例
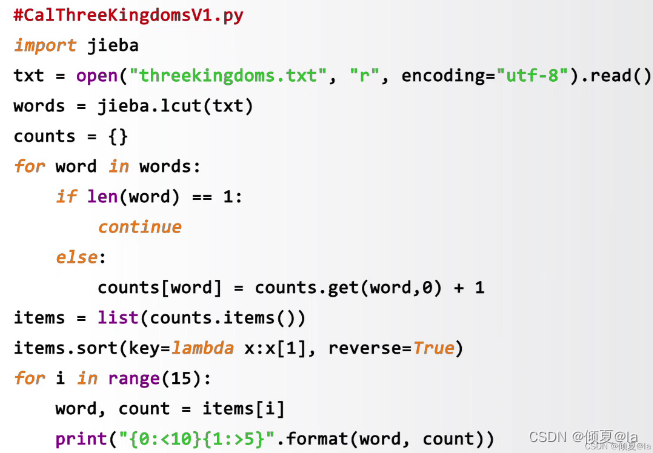
统计红楼梦出现最多的词语
#example.py def getText(): txt = open("honglou.txt","r").read() txt = txt.lower for ch in '!@#$%^&*[]{}()~`?/;:>,<.\|"': txt = txt.replace(ch, "") return txt honglouTxt = getText() words = honglouTxt.split() count = {} for word in words: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(10): word, count = items[i] print("{0:<10}{1:>5}".format(word, count))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
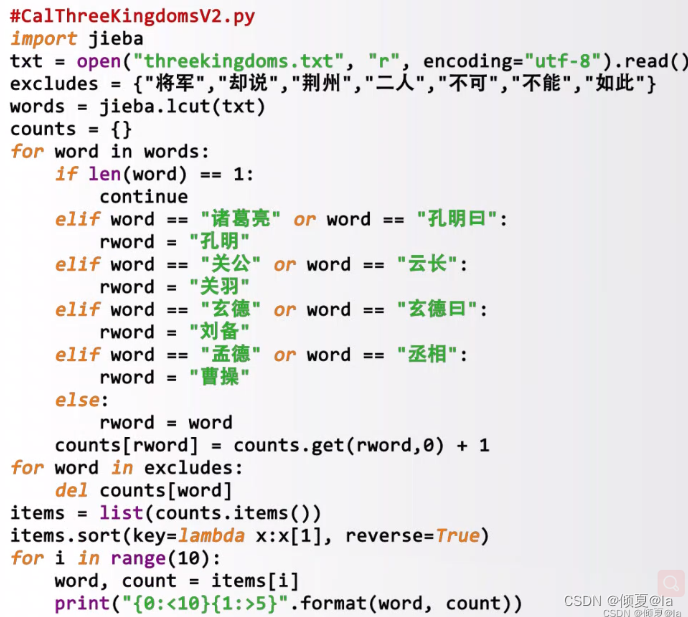
统计《三国演义》人物出场统计
升级版
十一、文件
11.1文件的理解
文件是数据的抽象和集合
1.文件是存储在辅助存储器上的数据序列
2.文件是数据存储的一种形式
3.文件展现形态:文本文件和二进制文件
文本文件 vs 二进制文件
1.文本文件和二进制文件只是文件的展示方式
2.本质上,所有文件都是二进制形式存储
3.形式上,所有文件采用两种方式展示
11.2 文本文件
文件是数据的抽象和集合
1.由单一特定编码组成的文件,如UTF-8编码
2.由于存在编码,也被看成是存储着的这长字符串
3.适用于列如:.txt文案、.py文件
11.2 文本文件
文件是数据的抽象和集合
1.直接由比特0和1组成,没有统一字符编码
2.一般存在二进制0和1的组织结构,即文件格式
3.适用于列如:.png文件、.avi文件等



11.3 文件的打开关闭

11.3.1 文件的打开

11.3.2 文件的路径

11.3.3 文件的打开模式


11.3.4文件的使用

11.3.5 文件内容的读取
| 操作方法 | 描述 |
|---|---|
| <f>.read(size=-1) | 读出全部内容,如果给出参数,读入前size长度 |
| >>>s = f.read(2) | |
| 中国 | |
| .readline(size=-1) | 读入一行内容,如果给出参数,读入该行前size长度 |
| >>>s = f.readline() | |
| 中国是一个伟大的国家! | |
| .readlines(hint=-1) | 读入文件所有行,以每行为元素形成列表 |
| 如果给出参数,读入前hint行 | |
| >>>s = f.readlines() |
11.4 文件的全文本操作

缺点:如果遇到文本文件的体量特别大,比如这个文件有250GB,我们一次性将文件读入内存,将会耗费非常多的时间和资源。因此,对于大文件来讲,一次性读入文件的代价很大,但是我们可以分批分阶段来处理

11.5 文件的逐行操作

除了全文本处理,对于文本文件来说,逐行处理是一种力度更粗、更常用的方法。对于文本文件来讲,一般都是会进行分行存储的,每一行结束都会有一个回车到下一行。对于分行存储的文件,采用逐行遍历的方法最为常见。

11.6 数据的文件写入




当我们信息写入到文件的时候,当前文件处理的指针在哪里呢?它在文件的最后面,也就是写过信息之后,指针指向文件的后面,指向下一次可能写入信息的位置,此时如果我们在调用for in 的方式去遍历一行并且打印输出的时候,它指的是从当前位置文件的结尾处取出其中的每一行并且打印出来。在这个时候我们已经写过的信息,它在指针的上方并不在指针的下方。因此我们之前的6行代码,它并不能输出我们已经写过的信息,为了需要将我们写过的信息输出,需要调整当前写入后的指针,回到文件的初始位置。那么从初始位置开始在进行逐行遍历,就能够把文件的全部信息打印输出
11.7 一维数据

11.8 二维数据
二维数据:由多个一维数据构成,是一维数据的组合形式
1.表格是典型的二维数据
2.其中,表头是二维数据的一部分
| 排名 | 学校名称 | 省市 | 总分 | 生源质量 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 94 | 100.0 |
| 2 | 北京大学 | 北京 | 81.2 | 96.1 |
| 3 | 浙江大学 | 浙江 | 77.8 | 87.2 |
| 4 | 上海交通大学 | 上海 | 77.5 | 89.4 |
| 5 | 复旦大学 | 上海 | 71.1 | 91.8 |
| 6 | 中国科技术大学 | 安徽 | 65.9 | 91.9 |
| 7 | 南京大学 | 江苏 | 65.3 | 87.1 |
| 8 | 华中科技大学 | 湖北 | 63.0 | 80.6 |
| 9 | 中山大学 | 广东 | 62.7 | 81.1 |
| 10 | 哈尔滨工业大学 | 黑龙江 | 61.6 | 76.4 |
11.9 多维数据
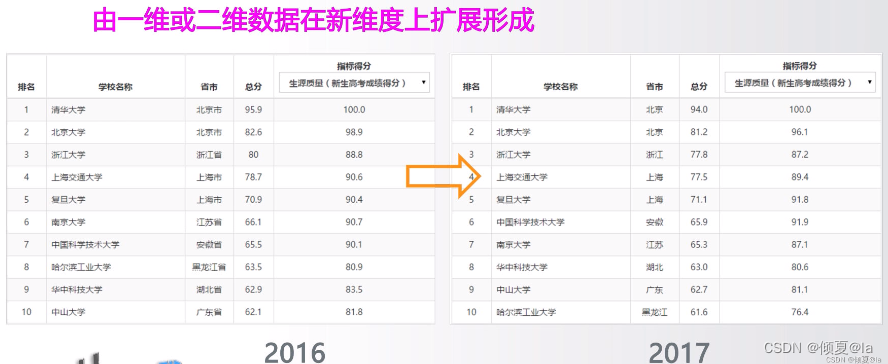
11.10 高维数据

11.11 数据的操作周期
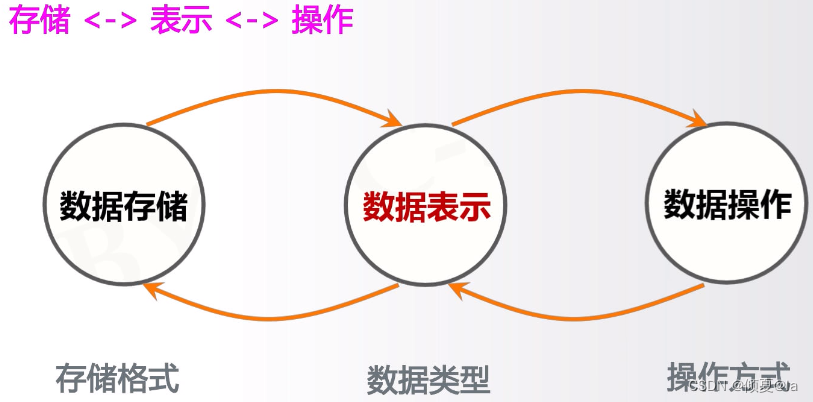
数据存储指的是:数据在磁盘中的存储状态,在这一部分我们关心的是数据存储所使用的的格式
数据表示指的是:程序表达数据的方式,在数据表示中,我们关心的是数据类型
如果数据能够由程序中的数据类型,进行很好的表达,我们就可以借助这样的数据类型,对数据进行操作。那具体操作又有相关操作方式和算法来体现
11.12 数据的处理
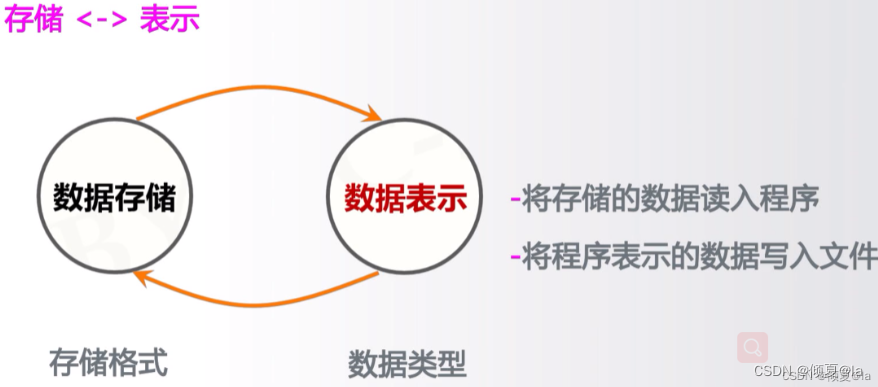
11.13 一维数据的读入处理


11.14 一维数据的写入处理

11.15 二维数据的表示
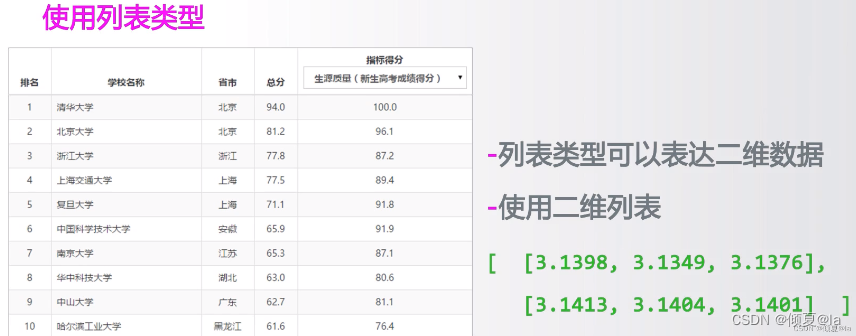
二维列表指的是:它本身是一个列表,二列表中的每一个元素又是一个列表,其中列表中每一个元素可以代表二维数据的一行或一列,若干行、若干列组织起来就构成我们所说的二维列表
11.16 二维数据的表示

11.17 CSV数据存储格式




11.18 二维数据的读入处理

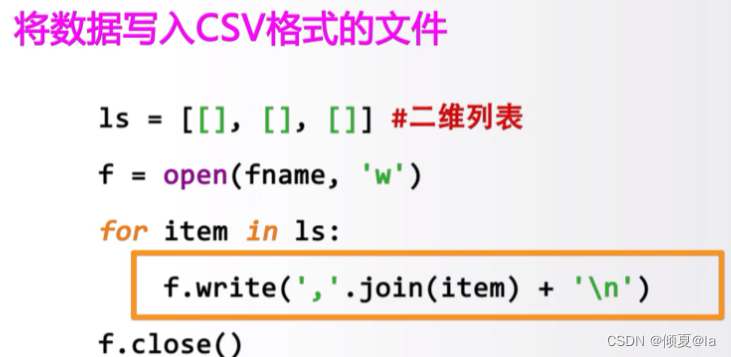
11.19 二维数据的逐一处理

十二、wordcloud库
12.1 wordcloud库概述

12.2 wordcloud库安装
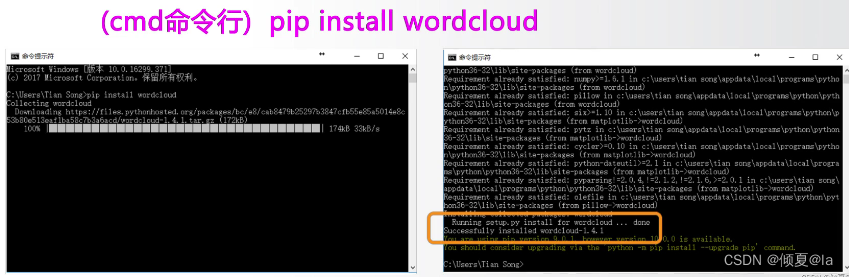
12.3 wordcloud库基本使用

12.4 wordcloud库常规方法
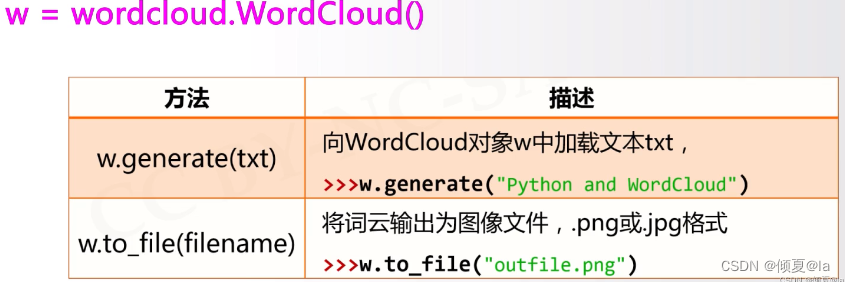


图片默认宽度为400像素,高度为200像素
12.5 wordcloud库配置参数对象




12.6 wordcloud应用实列


12.7 实例:政府工作报告词云

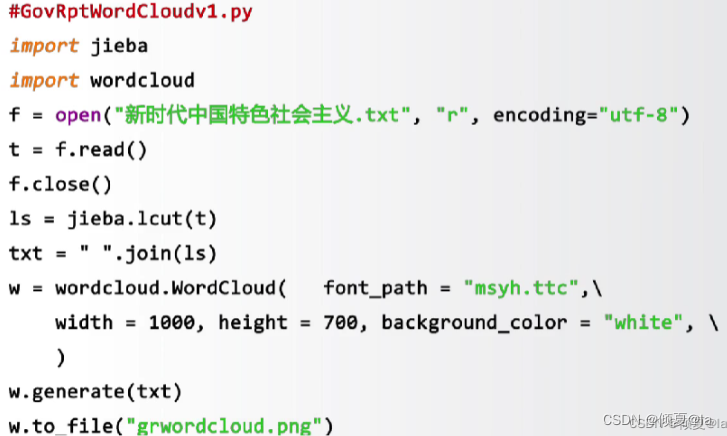

wordcloud库提供了mask参数通过覆盖的方法可以生成任意形状的词云。比如,想生成五角星的形状,你需要提供背景是白的五角星图片。为了加载图片,我们需要引入一个库from scipy.misc import imread
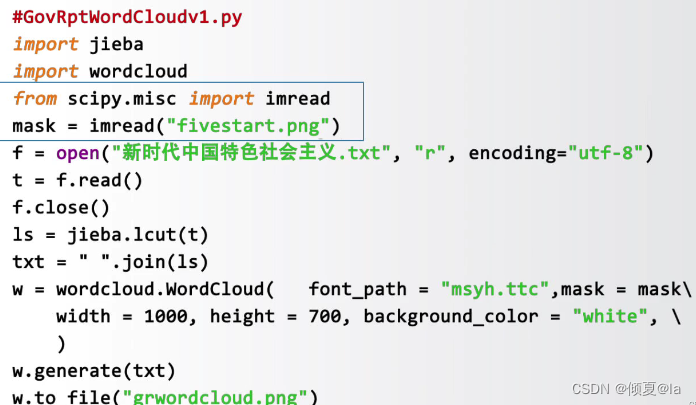

12.7 自顶向下

12.8 自底向上(上)

12.9 Python社区


12.10 安装Python第三方库

12.11 pip安装方法
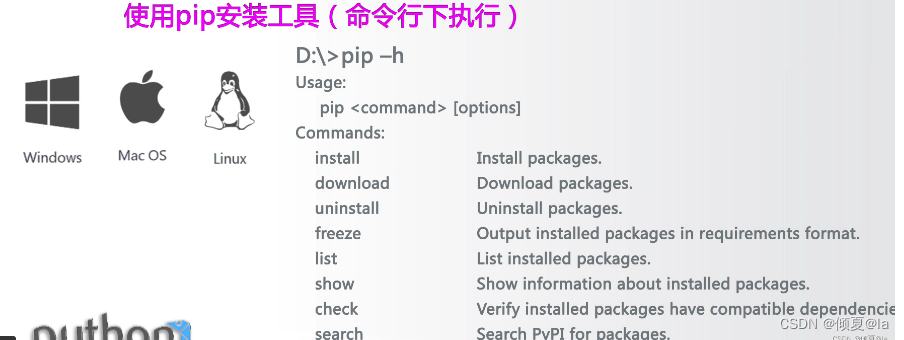

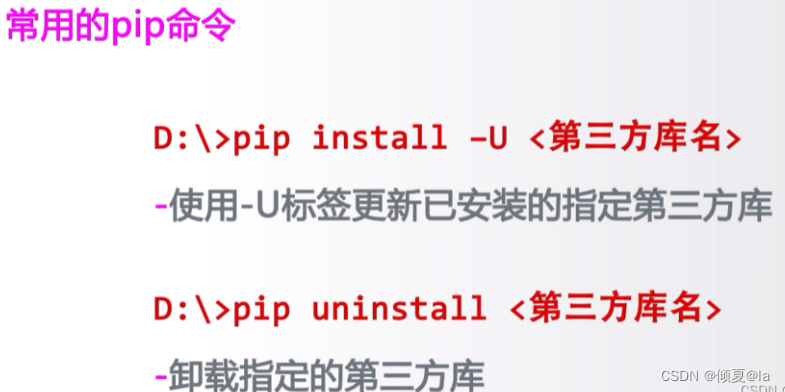



12.12 文件安装方法

12.13 os库基本介绍

12.14 路径操作

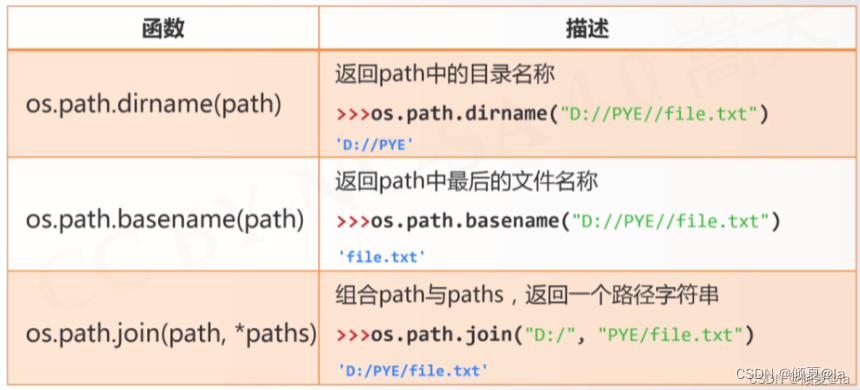


access(访问)、modify(修改)、create(创建)

12.15 进程管理
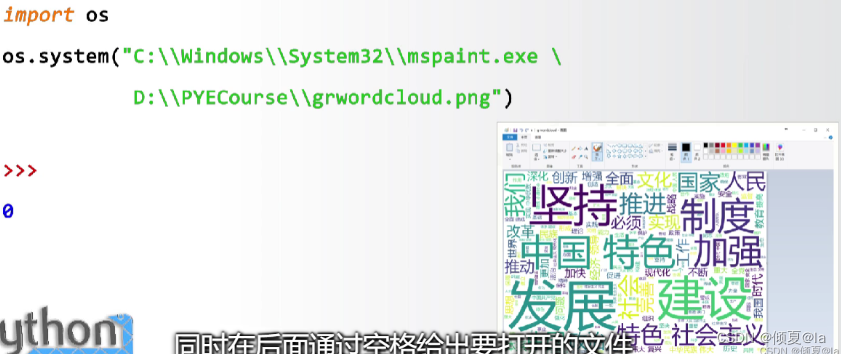
12.16 环境参数
| 函数 | 描述 |
|---|---|
| os.chdir(path) | 修改当前程序操作的路径 >>>os.chdir(“D:”) |
| os.getcwd() | 返回程序的当前路径 >>>os.getcwd() ‘D:\’ |
| os.getlogin() | 获得当前系统登录用户名称 >>>os.getlogin() ‘Tian Song’ |
| os.cpu_coutn() | 获得当前系统的CPU数量 >>>os.cpu_count 8 |
| os.urandom(n) | 获得n个字节长度的随机字符串,通常用于加解密码运算 >>>os.urandom(10) |
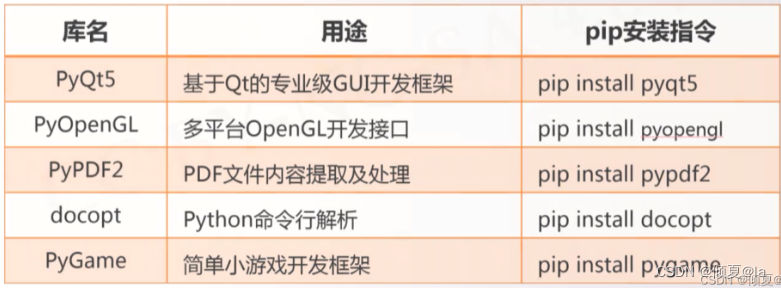
12.17 第三方库自动安装脚本
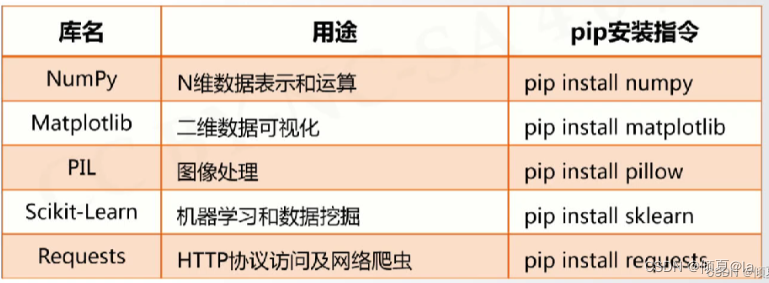
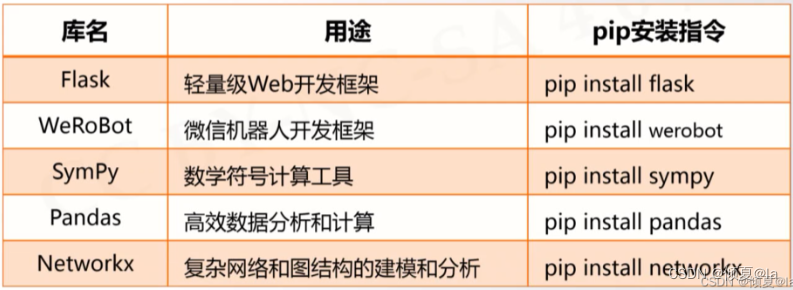
| 库名 | 用途 | pip安装指令 |
|---|---|---|
| Jieba | 中文分词 | pip install jieba |
| Beautiful Soup | HTML和XML解析器 | pip install beautifulsoup4 |
| Wheel | Python第三方库文件打包工具 | pip install wheel |
| PyInstaller | 打包Python源文件为可执行文件 | pip install pyinstaller |
| Django | Python最流行的Web开发框架 | pip install Django |
12.18 实列:第三方库安装脚本源代码
#BatchInstall.py
import os
libs = {"numpy","matplotlib","pillow","sklearn","requests",\
"jieba","beautifulsoup4","wheel","networkx","sympy",\
"pyinstaller","django","flask","werobot","pyqt5",\
"pandas","pyopengl","pypdf2","docopt","pygame"}
try:
for lib in libs:
os.system("pip3 install "+lib)
print("Successful")
except:
print("Failed Somehow")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

