
热门标签
热门文章
当前位置: article > 正文
基于ERNIR3.0文本分类的开发实践
作者:很楠不爱3 | 2024-03-06 11:48:48
赞
踩
基于ERNIR3.0文本分类的开发实践
参考:基于ERNIR3.0文本分类:(KUAKE-QIC)意图识别多分类(单标签) - 飞桨AI Studio星河社区 (baidu.com)
https://zhuanlan.zhihu.com/p/574666812?utm_id=0
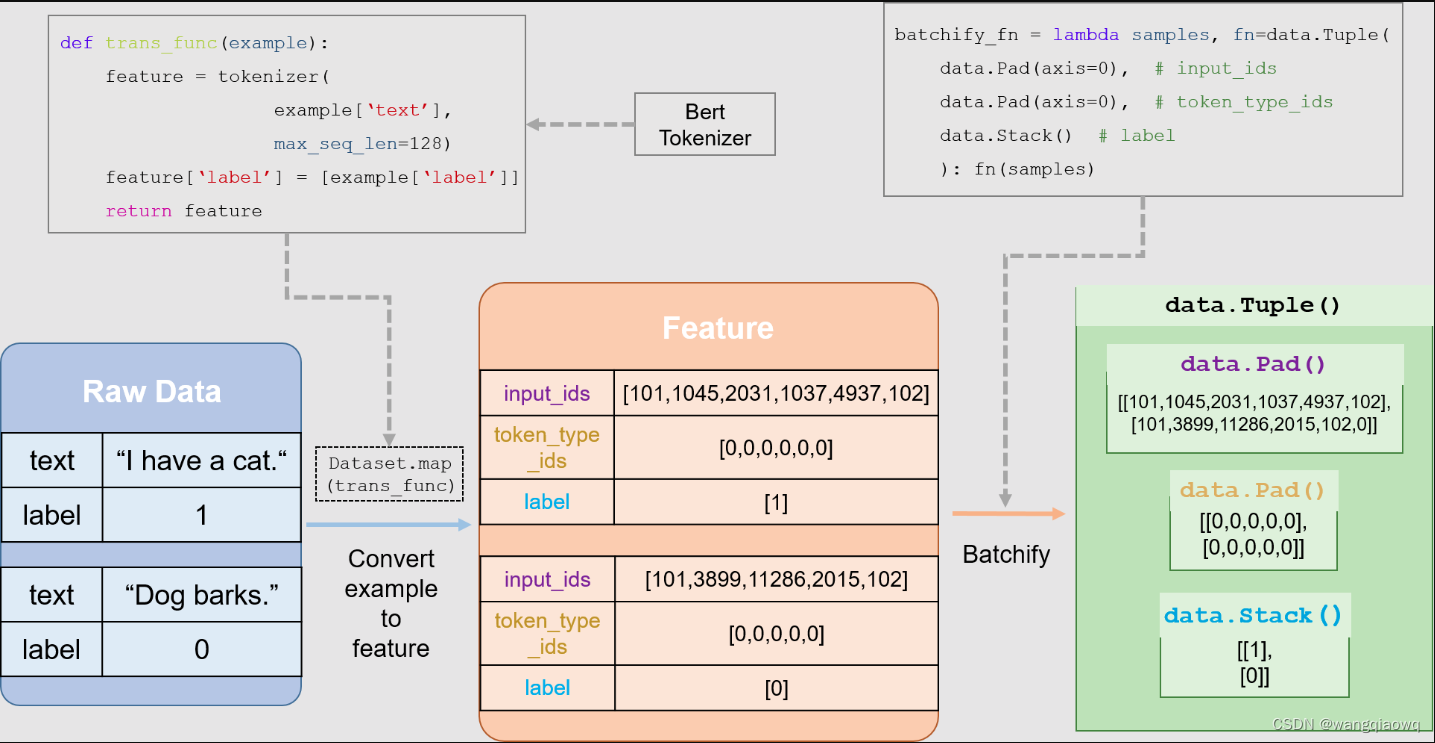
遇到的问题:如下 采用paddleNLP下文本分类实例进行分类训练后发现 生成的模型分类不准。打算自己开发脚本进行分类计算再进行服务化部署。
基于ERNIR3.0文本分类任务模型微调
PaddleNLP采用AutoModelForSequenceClassification, AutoTokenizer提供了方便易用的接口,可指定模型名或模型参数文件路径通过from_pretrained() 方法加载不同网络结构的预训练模型,并在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。Transformer预训练模型汇总包含了如 ERNIE、BERT、RoBERTa等40多个主流预训练模型,500多个模型权重。下面以ERNIE 3.0 中文base模型为例,演示如何加载预训练模型和分词器:
- from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
- num_classes = 10
- model_name = "ernie-3.0-base-zh"
- model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/198552?site
推荐阅读
相关标签

