
- 1node.js后端框架介绍_node.js后端框架及作用
- 2【ubuntu20.04上openvino安装及环境配置】_[setupvars.sh] openvino environment initialized
- 3python requests post线程安全_关于python requests库中session线程安全方面问题的小疑问...
- 4怎么防止跨站脚本攻击(XSS)?
- 5送给女朋友表白的小爱心,用Python这样画就对了_python 手机点开文件显示python的爱心效果
- 6小布助手,身入大千世界
- 7Attension注意力机制综述(一)——自注意力机制self_attention(含代码)_attension计算公式
- 8postgresql 查找慢sql之二: pg_stat_statements_可以使用pg_stat_statements去查询运行时间长的sql语句。
- 9传统行业被裁,奋战一年成功逆袭!做好这四个环节,轻轻松松斩下腾讯Offer!
- 10js之es新特性
基于协同过滤算法的电影推荐系统_电影推荐中主成分分析
赞
踩
前言
电影推荐系统是数学建模培训中一次例题,网上对相同类型的模型已有答案,但相关代码跑起来仍然存在些许bug,本文基于同类型的基础上能帮助后来的学习者。
电影推荐系统即通过用户的历史观影记录,结合相同爱好用户集群,在海量的影视资源中精确对每一位用户推荐电影。本文调用R语言Recommenderlab包做电影推荐系统。
R语言 电影推荐系统
实际上,在R语言的Recommenderlab保中,对电影进行推荐,是对用户没有看过的电影做一个预测评分,通过TOP-N部电影,选取所需要的电影数量推荐表。
案例及代码
数据准备
电影数据来源于http://grouplens.org/datasets/movielens/ 网站,本文分析的数据是ml-latest-small中Ratings.csv文件,总共有100,836个评分,来自610用户对9724部电影评分。
首先安装R语言的程序包:做推荐系统的Recommenderlab包,画图的ggplot2包,数据处理的reshape包。
需要注意的是Recommenderlab针对RealRatingMatrix数据类型,总共提供了6种模型:基于项目协同过滤(IBCF), 主成分分析(PCA), 基于流行度推荐(POPULAR),随机推荐(RANDOM),奇异值分解(SVD),基于用户协同过滤算法(UBCF)。
我在这里只用了三种,感兴趣的可以将6种都比较一下,然后选取误差值最小的作为最优解。
数据预处理
调用程序包,读取数据ratings.csv,
library(recommenderlab)
library(reshape)
library(ggplot2)
mydata<-read.csv("C:\\Users\\HP\\Desktop\\ratings.csv",header = FALSE,stringsAsFactors = TRUE)
- 1
- 2
- 3
- 4
数据总共4列,usersId,MoviesId,ratings还有timestamp,timestamp是一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。使用数字签名技术产生的数据, 签名的对象包括了原始文件信息、 签名参数、 签名时间等信息。广泛的运用在知识产权保护、 合同签字、 金融帐务、 电子报价投标、 股票交易等方面。
这是百度百科的含义,简单来讲就是把年月日的计日方式变成了十进制数据,这里提供一个网站进行转义https://tool.lu/timestamp
时间列是我们不需要的,剔除,还剩三列。
mydata<-mydata[,-4] #剔除时间戳列
- 1
看一下前6行的评分
head(mydata)
- 1
V1 V2 V3
1 1 1 4.0
2 5 1 4.0
3 7 1 4.5
4 15 1 2.5
5 17 1 4.5
6 18 1 3.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
看一下评分(rating)的总体占比情况
prop.table(table(mydata[, 3]))
summary(mydata[, 3])
- 1
- 2
0.5 1 1.5 2 2.5 3 3.5
0.01358642 0.02787695 0.01776151 0.07488397 0.05503987 0.19880797 0.13027093
4 4.5 5
0.26595660 0.08480106 0.13101472
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.500 3.000 3.500 3.502 4.000 5.000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
数字太多了,看看饼图
gplot(mydata,x=V3,aes(x=factor(1),fill=factor(V3)))
+geom_bar(width = 1)+coord_polar(theta="y")‘
+ggtitle("评分分布图")
+labs(x="",y="")+guides(fill=guide_legend(title = '评分分数'))
- 1
- 2
- 3
- 4
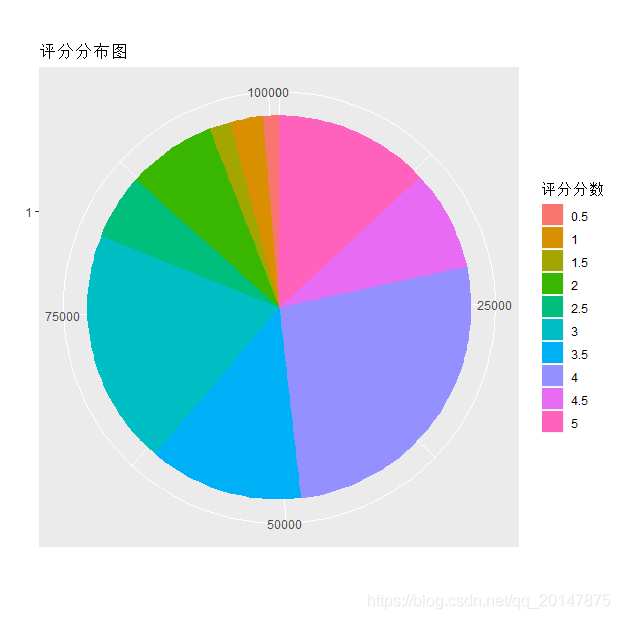
图中可以看出来,打1、2分的人很少,3,4分的占了6成左右。
建立模型
调用reshape包的cast()函数将数据转换为usersId为行,moviesId为列的矩阵,删除第一列数据序号列,这个时候的数据包含两种类型:cast_df,data.frame,其中cast_df是不能直接转换为matrix的,因此需要去掉这个类属性,只保留data.frame 也就是数据框
注意转换后是一个610*9724的超大矩阵,导致数据源评分矩阵是一个非常稀疏、含有许多空缺值的矩阵但并不影响我们的后续操作。为了让数据成为Recommenderlab包能够处理的类型,转换为RealRatingMatrix。
mydata<-cast(mydata,V1~V2,value="V3",fun.aggregate=mean) #生成一个以v1为行,v2为列的矩阵,使用v3进行填充
mydata<-mydata[,-1] #第一列数字为序列,可以删除
class(mydata)
class(mydata)<-"data.frame" #只选取data.frame
mydata<-as.matrix(mydata)
mydata<-as(mydata,"realRatingMatrix")
mydata
- 1
- 2
- 3
- 4
- 5
- 6
- 7
给生成的矩阵的列命名"M_moviesId"表示电影编号,调用Recommenderlab的UBCF(基于用户的协同过滤算法)模型
补个知识点:协同过滤主要分为两个步骤,首先依据目标用户的已知电影评分找到与目标用户观影风格相似的用户群,然后计算该用户群对其他电影的评分,并作为目标用户的预测评分,协同过滤算法的具体细节请参考文献。
colnames(mydata)<-paste0("M",1:9726,sep="")
mydata.model <- Recommender( mydata[1:610], method = "UBCF")
- 1
- 2
数据处理完毕,接来下是进行预测,以编号为233的用户为例,预测他对前6部电影的评分(看过的电影不会再预测,显示为NA)
mydata.predict <- predict(mydata.model,mydata[414], type="ratings")
as(mydata.predict,"matrix")[1,1:6]
M1 M2 M3 M4 M5 M6
NA 3.282566 3.263601 3.308725 3.332142 3.308725
- 1
- 2
- 3
- 4
- 5
现在你可以命令R给编号为233的用户推荐5部预测评分高的电影表
mydata.predict2 <- predict( mydata.model, mydata[233], n=5) #n指推荐电影数量
as(mydata.predict2,"list")
$`233`
[1] "M1067" "M969" "M1218" "M977" "M2611"
- 1
- 2
- 3
- 4
- 5
到这里整个推荐系统模型已经建立好了。

