
热门标签
热门文章
- 1当我第一次接触grad_cam(一)_安装pytorch_grad_cam
- 2Kubernetes 编排神器之 Helm_helmchart可视化编排工具
- 3没有初中毕业证可以学计算机吗,读技校要初中毕业证吗 没有毕业证可不可以读技校...
- 4java面试题-异常关键字_java\声明异常时使用下列哪个关键字
- 5Android 点击悬浮窗后台启动Activity问题及方案_vivo后台启动activity
- 6华为鸿蒙系统失败,世界首富很无奈,第三大手机系统失败,华为鸿蒙会成功吗...
- 7数据结构——有向无环图(AOV网、AOE网)_aov网名词解释
- 8tomcat的wget链接_tomcat配置解决不带www跳转到www域名方案
- 9c++ 局域网远程开机(wol、魔术包)_{"c":"jwoii"}
- 10linux centos系统启动失败:VFS:Unable to mount root fs on unknown-block
当前位置: article > 正文
【Python】动态页面爬取:获取链家售房信息(学堂在线 杨亚)_爬虫 学堂在线
作者:很楠不爱3 | 2024-03-07 07:44:26
赞
踩
爬虫 学堂在线
一、内容来源
任务:学会爬取一个网站的部分信息,并以".json"文件形式保存
课程来源:大数据分析师(第一期)(北邮 杨亚)
二、准备工作
对于准备阶段,可参考:
【Python】Scrapy入门实例:爬取北邮网页信息并保存(学堂在线 杨亚)
1、创建工程
在cmd.exe窗口,找到对应目录,通过下列语句创建工程
scrapy startproject lianjia
- 1
2、创建begin.py文件
主要用于在Pycharm中执行爬虫工程(创建位置可参考后文工程文件层次图来理解)
from scrapy import cmdline
cmdline.execute("scrapy crawl lianjia".split())
- 1
- 2
3、修改items.py文件
import scrapy
class MyItem(scrapy.Item):
name = scrapy.Field()
desp = scrapy.Field()
price = scrapy.Field()
pass
- 1
- 2
- 3
- 4
- 5
- 6
4、修改setting.py文件
ITEM_PIPELINES = {'lianjia.pipelines.MyPipeline': 300,}
- 1
5、修改piplines.py
若无特殊保存格式需求,实际上所有爬虫的保存方式都一样
import json class MyPipeline (object): def open_spider (self, spider): try: #打开json文件 self.file = open("Lianjia_MyData.json", "w", encoding="utf-8") except Exception as err: print (err) def process_item(self, item, spider): dict_item = dict(item) # 生成字典对象 json_str = json.dumps(dict_item, ensure_ascii = False) +"\n" #生成 json串 self.file.write(json_str) # 将 json串写入到文件中 return item def close_spider(self, spider): self.file.close() #关闭文件

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三、爬虫核心
新建一个spider.py文件
import scrapy from lianjia.items import MyItem class mySpider(scrapy.spiders.Spider): name = "lianjia" allowed_domains = ["lianjia.com"] start_urls = ["https://bj.lianjia.com/ershoufang/"] start_urls = [] for page in range(1,4): url = "https://bj.lianjia.com/ershoufang/pg{}/".format(page) start_urls.append(url) def parse(self, response): item = MyItem() for i in range(32): item['name'] = response.xpath( '//*[@id="content"]/div[1]/ul/li[{}]/div[1]/div[2]/div/a/text()'.format(i+1)).extract() item['desp'] = response.xpath( #'//*[@id="content"]/div[1]/ul/li[{}]/div[1]/div[2]/div/text()' '//*[@id="content"]/div[1]/ul/li[{}]/div[1]/div[3]/div/text()'.format(i+1)).extract() item['price'] = response.xpath( '//*[@id="content"]/div[1]/ul/li[{}]/div[1]/div[6]/div[1]/span/text()'.format(i+1)).extract() if (item['name'] and item['desp'] and item['price']): # 去掉值为空的数据 yield (item) # 返回item数据给到pipelines模块 else: print(":::::::::error::::::::::",i+1,item['name'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这里细节就不介绍了,但愿我若干年以后需要用到相关知识的时候还能记起吧!
四、补充资料
1、工程文件层次图
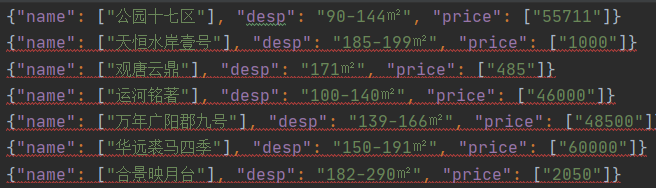
2、部分结果:

五、附加实验(作业)

spider.py
import scrapy from lianjia2.items import MyItem class mySpider(scrapy.spiders.Spider): name = "lianjia2" allowed_domains = ["lianjia.com"] #start_urls = ["https://bj.fang.lianjia.com/loupan/nhs1"] start_urls = [] for page in range(1,6): url = "https://bj.fang.lianjia.com/loupan/nhs1pg{}/".format(page) start_urls.append(url) def parse(self, response): item = MyItem() for i in range(10): item['name'] = response.xpath( '/html/body/div[4]/ul[2]/li[{}]/div/div[1]/a/text()'.format(i+1)).extract() item['desp'] = response.xpath( '/html/body/div[4]/ul[2]/li[{}]/div/div[3]/span/text()'.format(i+1)).extract() item['price'] = response.xpath( '/html/body/div[4]/ul[2]/li[{}]/div/div[6]/div[1]/span[1]/text()'.format(i+1)).extract() if (item['name'] and item['desp'] and item['price']): # 去掉值为空的数据 yield (item) # 返回item数据给到pipelines模块 else: print(":::::::::error::::::::::",i+1,item['name'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
piplines.py进行一定修改,删除小部分重复的数据(不写也行)
dict_item['desp'] = dict_item['desp'][0][3:]
- 1
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

