
- 1大数据采集方法
- 2以括号形式输出二叉树_用括号法打印输出二叉树
- 3Android 常用的intent Action整理
- 4A*算法简介-matlab篇_matlab a星算法
- 5RTL8852BE网卡驱动安装及modprobe: ERROR: could not insert ‘8852be‘: Invalid argument问题解决_modprobe: error: could not insert 'rtw_8852ce': in
- 6Leaflet 自定义修改Marker点标记样式_l.marker
- 7哔哩哔哩怎么调节屏幕亮度_安卓手机看b站视频自动亮度
- 8用Android Studio制作一个简易的计算器,Android开发经验的有效总结_android studio计算器报告
- 9sm2国密算法的纯c语言版本,使用于单片机平台(静态内存分配)_sm2算法c语言
- 10士兰微SC7A20E三轴加速度计规格书_sc7a20e规格书
机器学习利器——决策树和随机森林
赞
踩
更多深度文章,请关注:https://yq.aliyun.com/cloud
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。决策树是一种基本的分类和回归方法,学习通常包含三个步骤:特征选择、决策树的生成和决策树的剪枝。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。分类树(决策树)是一种十分常用的分类方法。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来做预测。
一个简单的决策树分类模型:红色框出的是特征。
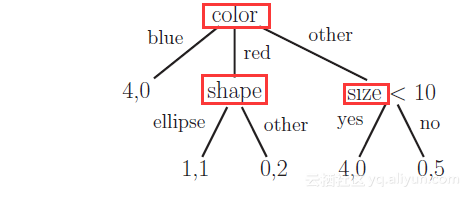
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。Leo Breiman和Adele Cutler发展出推论出随机森林的算法。随机森林在过去几年一直是新兴的机器学习技术。它是基于非线性的决策树模型,通常能够提供准确的结果。然而,随机森林大多是黑盒子,经常难以解读和充分理解。在这篇博客中,我们将深入介绍随机森林的基本原理,以更好地了解它们。我们首先看看决策树和随机森林的构建块。这项工作是由Ando Saabas(https://github.com/andosa/treeinterpreter)完成。可以在我的GitHub上找到在这个博客中所需的代码。
决策树如何工作?
决策树以迭代地方式将数据分解成不同的子集来工作:对于回归树,选择它们来最小化所有子集中的MSE(均方误差)或MAE(平均绝对误差)是个不错的选择;对于分类树,选择分解数据以便最小化所得到的子集中的熵或基尼杂质。所得到的分类器将特征空间分成不同的子集。根据观察到的子集进行观察的预测:
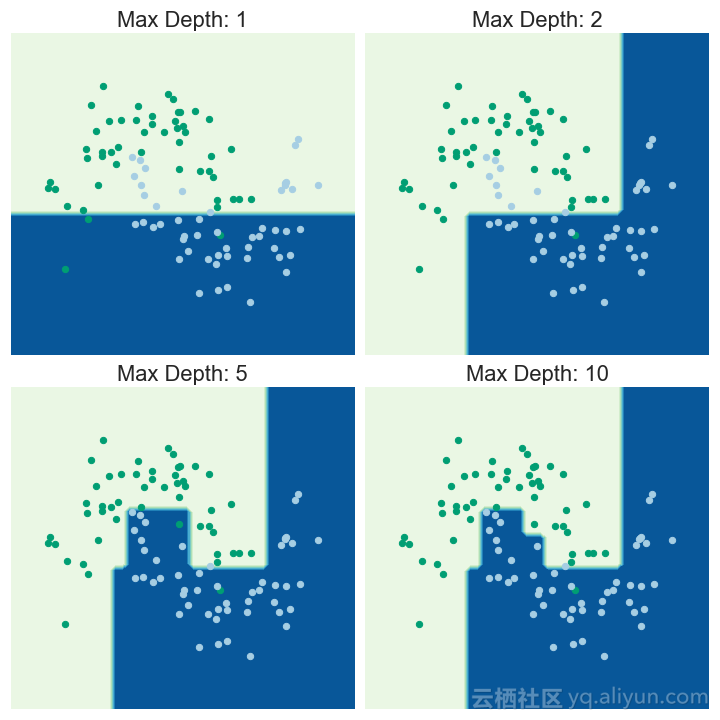
图为:决策树的迭代
决策树的贡献值
以鲍鱼数据集为例。我们将尝试基于贝壳重量,长度,直径等变量来预测其头数。为了说明的目的,我们拟合一个浅层决策树。我们通过将树的最大深度限制为3级来实现。
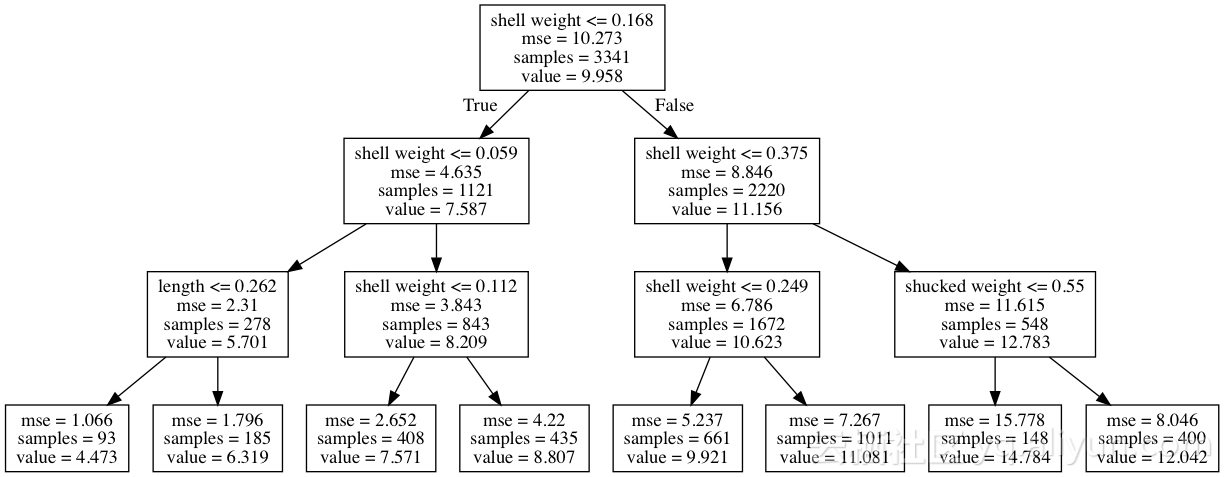
图为:用于预测环数的决策树路径
为了预测鲍鱼的头数,决策树将沿着树向下移动,直到达到叶。每个步骤将当前子集分成两部分。对于特定的分割,确定分割的变量的贡献值(contributions)被定义为平均数量的变化。
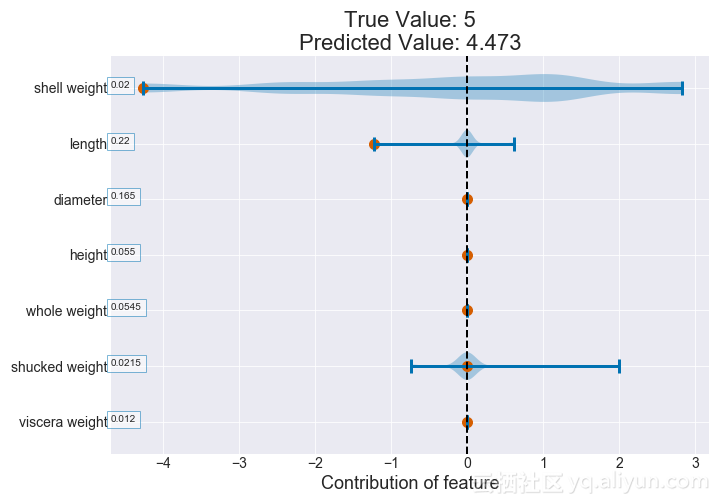
例如,如果我们拿一个贝壳重量为0.02和长度为0.220的鲍鱼,它将落在最左边的叶子中,预计的头数为4.4731。
壳重的贡献值(contributions)结果是:
(7.587 - 9.958) + (5.701 - 7.587) = -4.257
长度的贡献值(contributions)结果:
(4.473 - 5.701) = -1.228
这些贡献值(contributions)结果意味着特定的壳体重量和长度值可以预测其鲍鱼的头数。
我们可以通过运行以下代码获得这些贡献值(contributions)结果。
- from treeinterpreter import treeinterpreter as ti
- dt_reg_pred, dt_reg_bias, dt_reg_contrib = ti.predict(dt_reg, X_test)
该变量dt_reg是sklearn分类器对象,X_test是一个Pandas DataFrame或numpy数组,其中包含我们希望得出预测和贡献值的特征。dt_reg_contrib是具有(n_obs,n_features)的2d numpy数组,其中n_obs是观察n_features次数。
我们可以为给定的鲍鱼绘制这些影响元素,以查看哪些特征最能影响其预测头数。从下图可以看出,这个特定的贝壳的体重和长度值对预测的头数有很大的影响。
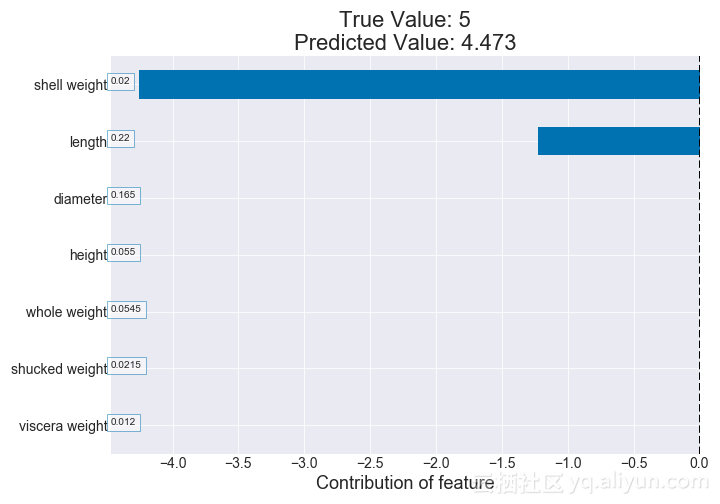
图为:例子的贡献值图(决策树)
我们可以通过使用小提琴图比较特征对鲍鱼头数预测的影响。这将内核密度估计覆盖到图上。在下图中,我们看到鲍鱼的体重对其头数的影响最大。实际上,壳重量值给它带来了更大的影响。
图为:小提琴贡献值图(决策树)
上述情节虽然有洞察力,但仍不能充分了解具体变量如何影响鲍鱼的头数。相反,我们可以绘制给定特征对其值的影响程度。如果我们绘制壳重量与其影响程度的关系,我们可以获得增加壳重量会增加影响程度的见解。
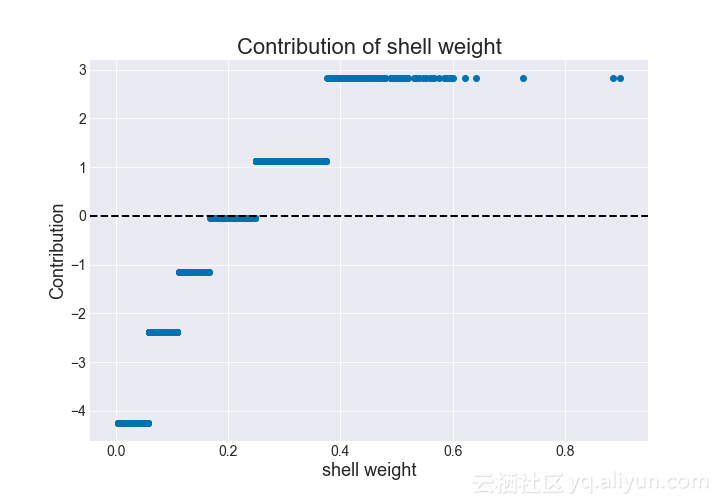
图为:贡献值与壳重的关系(决策树)
我们可以看到,减轻壳重量与影响程度具有非线性,非单调关系。
扩展到随机森林
确定特征贡献的过程当然可以通过对森林中所有树木的变量进行平均贡献来扩展到随机森林。
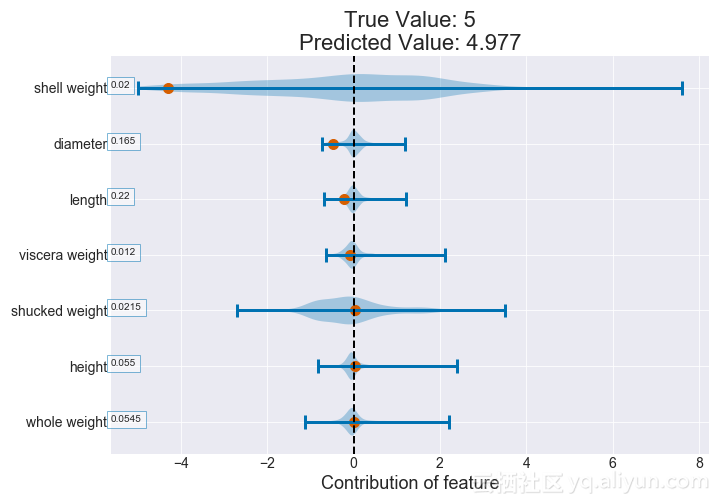
图为:小提琴贡献值图(随机森林)
因为随机森林本身是随机的,所以在给定的壳体重量上有贡献的变化。然而,平滑的黑色趋势线显示出增长趋势。与决策树一样,我们看到增加的壳体重量对应于更高的贡献值。
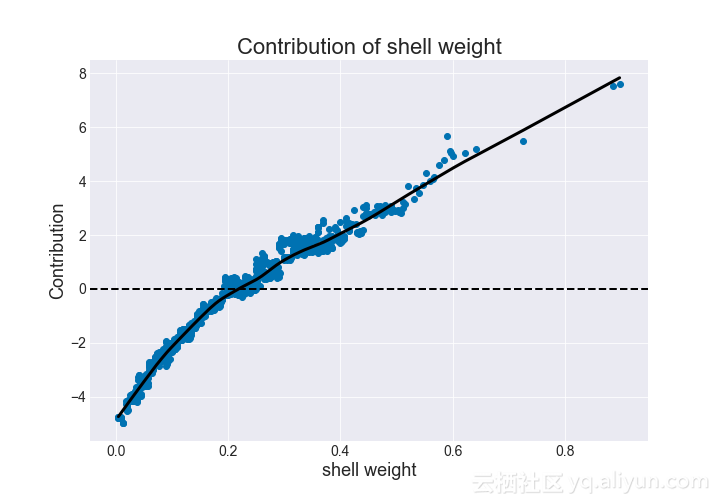
图为:贡献值与壳重的关系(随机森林)
再次,我们可能会看到复杂的,非单调的趋势。直径似乎在约0.45的贡献下降,在0.3和0.6附近的贡献峰值。除此之外,直径和环数之间似乎有越来越大的关系。
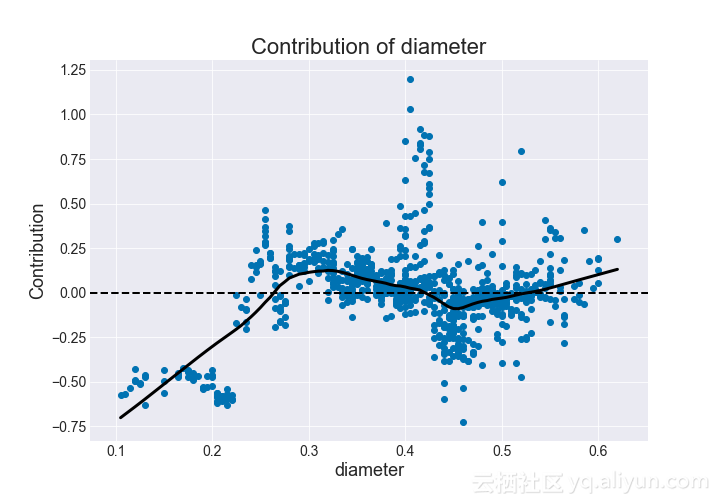
图为:贡献值与直径的关系(随机森林)
分类
我们已经表明,回归树的特征贡献值来源于它在连续分裂中的变化。我们可以将其扩展到二项式和多项式中分类,而不是看每个子集中某个类的观察的百分比。特征的贡献值是观察从该特征引起的百分比的总体变化。
这个例子更容易解释。假设我们试图预测性别,即鲍鱼是公还是母,婴幼儿还是成年?
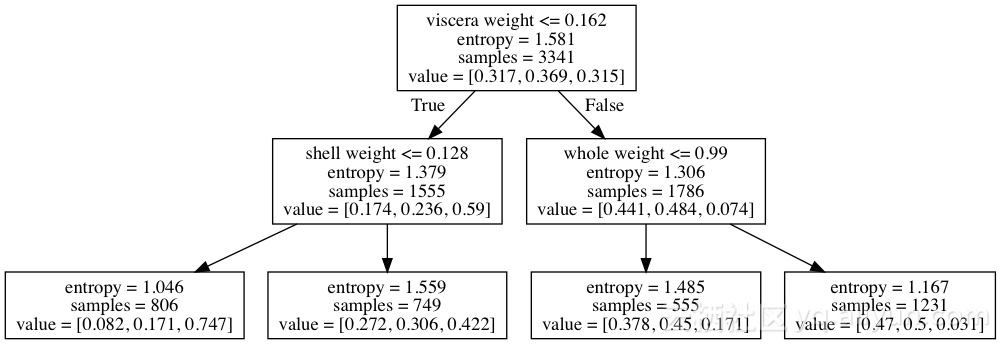
图为:多项式分类的决策树路径
每个节点具有3个值,子集中的雌雄,雄和婴幼儿的百分比。内脏重量为0.1和壳重量为0.1的鲍鱼最终落在最左侧的叶中(概率为0.082,0.171和0.747)。
内脏重量对婴儿鲍鱼的贡献值是:
(0.59 - 0.315) = 0.275
壳重量的贡献值是:
(0.747 - 0.59) = 0.157
我们可以为每个贡献值类绘制一个贡献图。以下是我们为婴儿类分析的结果。
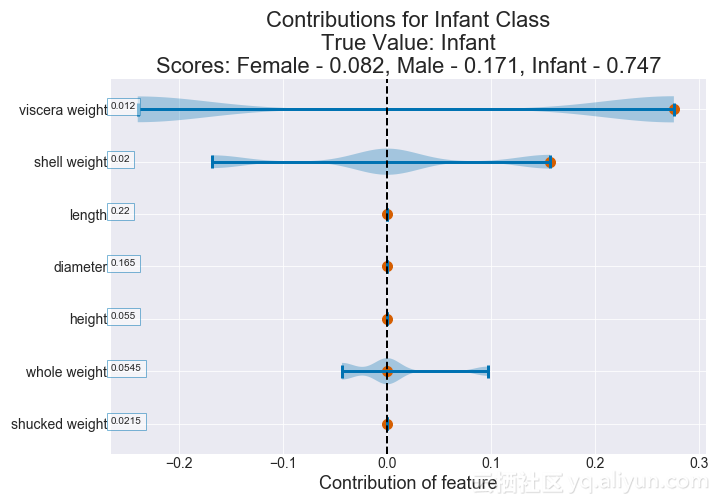
图为:观察的婴儿小提琴的贡献值图(多类决策树)
和以前一样,我们还可以绘制每个特征类的贡献。随着壳重量的增加,鲍鱼是母的几率就增加,而作为婴儿的几率则下降。对于公的,当壳重超过0.5时,几率最初增加,然后减小。
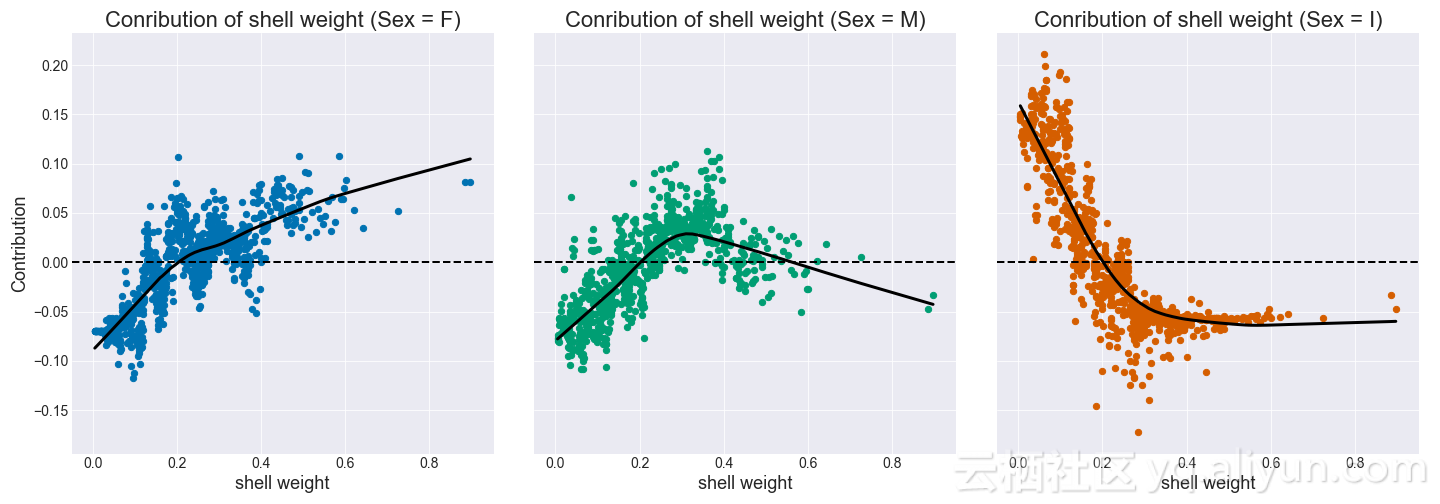
图为:每个特征类的贡献值与壳体重量(随机森林)
总结:
我们可以在这篇博客中看到,通过查看路径,我们可以更深入地了解决策树和随机森林。这是特别有用的,因为随机森林是一个非常难理解的结构,通常是高性能的机器学习模型。为了满足业务需求,我们不仅需要提供高预测性的模型,而且也是一个可以解释的模型。也就是说,我们不想提供一个黑盒子。这个要求其实很重要,因为我们的模型可以合规性的传递下去,让更多的人使用。
本文由北邮@爱可可-爱生活老师推荐,@阿里云云栖社区组织翻译。
文章原标题《interpreting-decision-trees-and-random-forests》
作者:Greg Tam Pivotal工程师 博客地址: http://engineering.pivotal.io/authors/gtam/
译者:袁虎 审阅:
文章为简译,更为详细的内容,请查看原文

