
语音合成论文优选:多模态Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary_speech2vedio
赞
踩
声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary
本文是Baidu Research, USA在2021.04.29更新的文章,主要工作为多模态的talking-head,把text转成video,具体的文章链接
https://arxiv.org/pdf/2104.14631.pdf
demo https://www.youtube.com/watch?v=d5MFzHxeOTs
(看了demo,感觉还是怪怪的~)
1 研究背景
目前talking-head主要采用方案主要分为speech2video和text2video。其中speech2video相较于text2video需要大量的训练数据,而且灵活性较低。本文也是text2video的方案,本文的方案具有需要的数据少,训练和推理速度快的有点。
2 详细设计
本文的架构如图1所示,先把text经过tts生成音频,然后通过alignment获取时间戳,接下来获取音素-姿态序列,最后通过vid2vid gan生成视频。其中对音素之间的pose进行差值处理如图2所示。
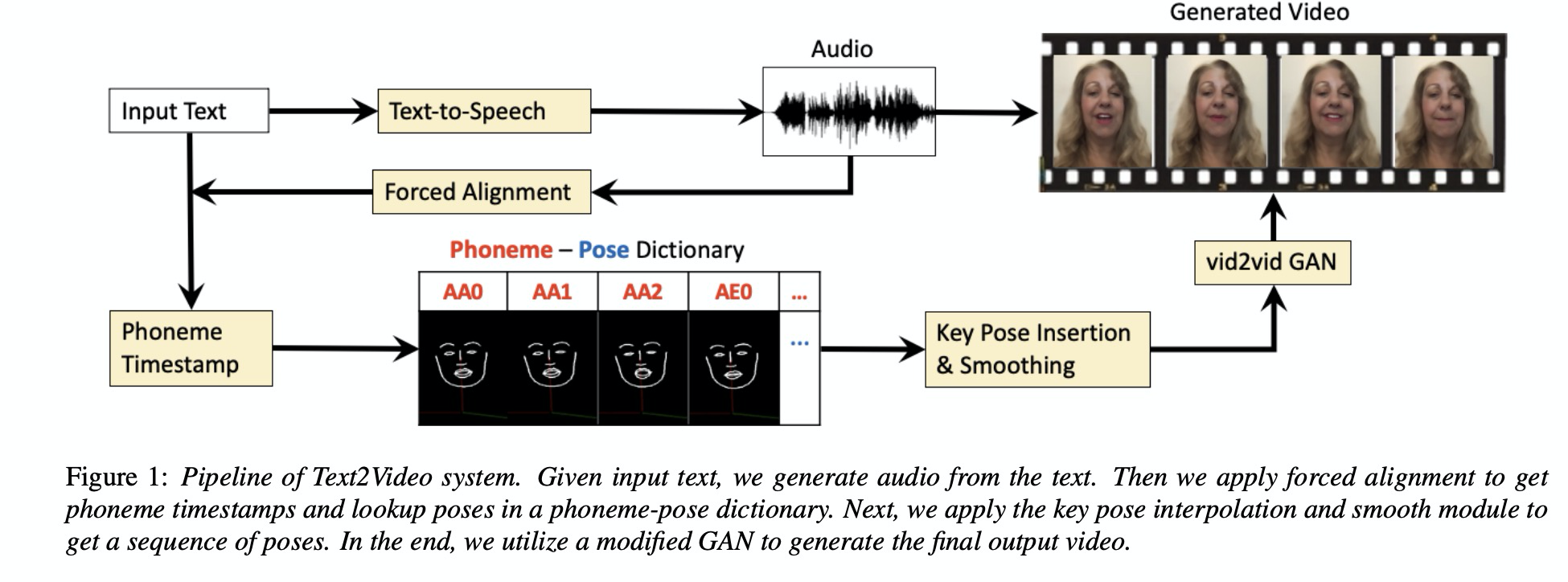

3 实验
本文的实验数据为table 1所列,本文与现有方案对比如table2所示,其中本文的text2video在主观测试值最高。table3主要展示tts合成音频质量对结果的影响。

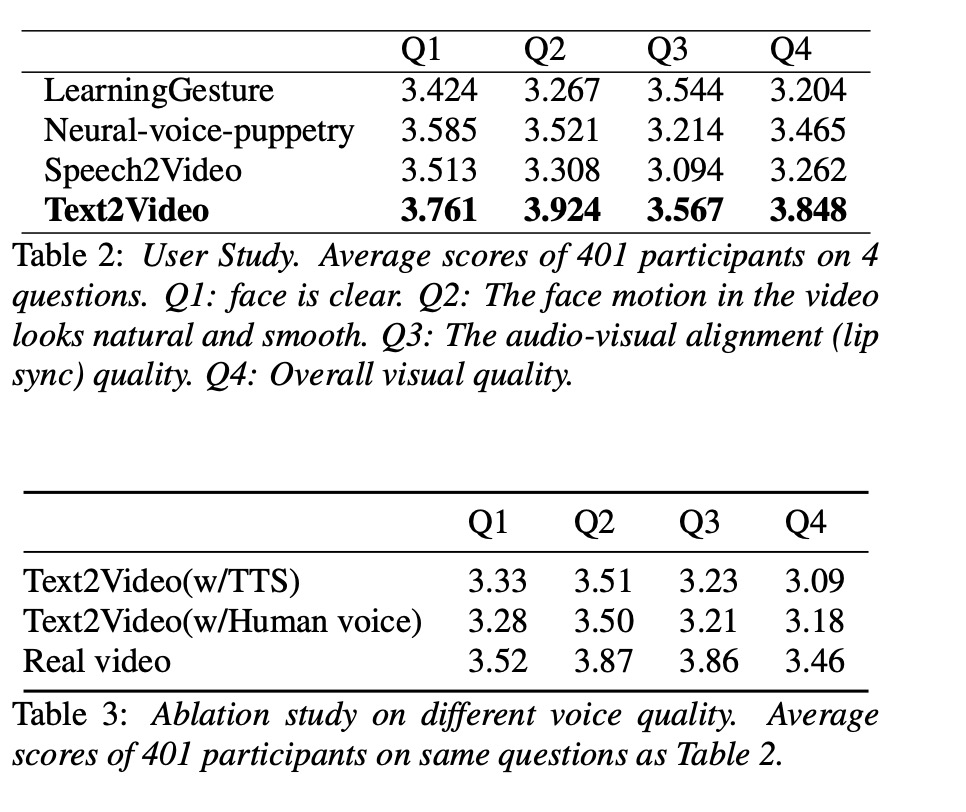
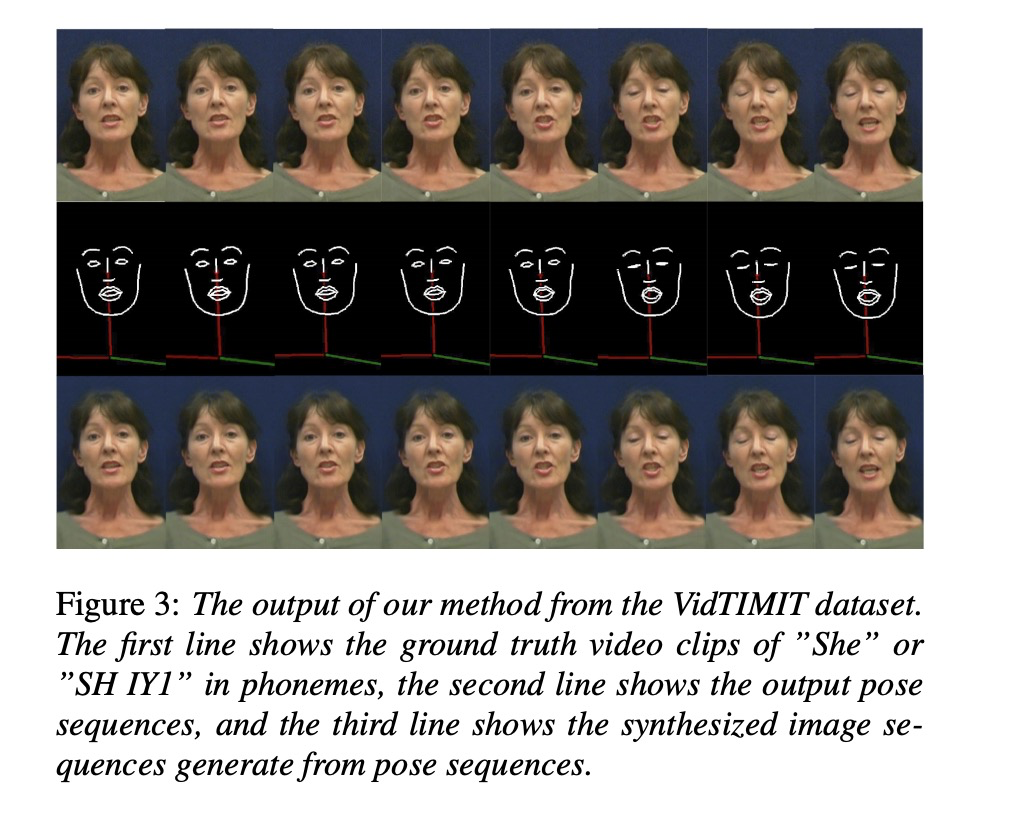
4 总结
本文提出text2video的方案,可以很好地生成视频。(论文评测很好,但demo看还是有点怪,需要对整个面部表情做处理)

