
- 1人工智能大模型赋能医疗健康产业白皮书
- 2阿里云GPU云服务器使用AIGC文本生成3D模型教程!_aigc 三维模型
- 3[深度学习-实战篇]情感分析之卷积神经网络-TextCNN,包含代码
- 4DGDML-SR:使用深度信息的zero shot超分辨率方法_zero-shot image super-resolution with depth guided
- 5计算机毕业设计(33)java毕设作品之疫情资讯和实时数据系统_计算机毕设新闻网站有时间线和新闻
- 6【干货】娃哈哈集团企业文化手册.pdf(附下载链接)
- 7人工智能产业应用--具身智能
- 8NLP实战9:Transformer实战-单词预测_transformer预测
- 9fastdfs原理及过程_fastdfs原理与过程
- 10BERT系列-浅谈_bert的位置向量是否参与训练
关于AI图像知识扫盲集合_ai 图片认识
赞
踩
这篇文章专门是给我这样的机器学习小白扫盲的,主要摘录各位勤奋的AIer的博客,我会针对每一个记录的博客,后面加上评论语,这样告诉自己真正看过,毕竟,能看懂并且用自己的话讲出来的内容,才是真的懂得了。
1.目标检测中的AP,mAP output : learning.
2.如何利用pytorch搭建自己的卷积神经网络
这篇博客写的非常清晰易懂,只有掌握最基本的搭建网络,才能知道复杂的网络都是怎么搭建和运行的。
搭建顺序:
① 数据集定义与加载,dataset与dataloader
②定义网络
③ 定义优化器、学习率
④ 定义损失函数loss
⑤ 开始epoch
step4.1 清空优化器的梯度信息(很容易忘记)
step4.2 输入input开始forward正向传播
step4.3 计算loss
step4.4 误差反向传播loss.backward()
step4.5 更新参数optimizer.step()
3.何为Tensor
Tensor是深度学习的基础,有监督学习的计算全部围绕着Tensor进行。图片、声音的输入,都是转化为了张量,通过与Target计算loss,反向传播更新参数,最后将各节点的weights保留下来,下次再有tensor进来,直接可以通过weights,计算得到输出结果,从而达到识别、检测的目的。
其本质就是多维数组,三维向量想象成一个立方体,以此为基础,再往高维升。
引用下网上的图:

结合到计算机,tensor的shape属性:
维度,例如tensor.shape = (1,3,3),意味着这是一个三维张量,结合上面的图像,就是具有一个长方体,长方体一共有3层,每层有3个元素,如果是(2,3,4,5)呢?从右往左看比较容易一些,先有一列5个数据,然后这5列数据X4行数据,组成一张矩阵,再由3张矩阵,构成一个长方体,最后有2个长方体。

4.切片操作
彻底搞懂Python切片操作
在看源码时候,有太多地方用到切片方法了,在这个扫盲博客里面,基本都解释清楚了,最关键的就是一句[startIndex : endindex : direction]
起始、结束index,把这个搞清楚了,啥问题都解决了,各位就能愉快地理解源码切片了。
5.上采样/下采用
上采样和下采样
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
对图像的缩放操作并不能带来更多关于该图像的信息, 因此图像的质量将不可避免地受到影响。然而,确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量的。
下采样原理:对于一副图像I尺寸为MN,对起进行s倍下采样,即得到(M/s)(N/s)尺寸的分辨率图像,当然,s应该是M和N的公约数才可以,如果考虑是矩阵形式的图像,就是把原始图像s*s窗口内的图像编程一个像素,这个像素点的值就是窗口内所有像素的均值。
Pk = Σ Ii / s2
上采样原理:图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
插值算法还包括了传统插值,基于边缘图像的插值,还有基于区域的图像插值。
6.梯度爆炸与梯度消失
均为神经网络训练过程中的产生的问题,
梯度消失,顾名思义:下着下着楼梯,不再下降了,就是loss不再变化了。
比如激活函数:sigmoid,z值极大或者极小时,其图像接近平的,可知导数接近于0,在梯度下降公式里看到,几乎就不再减少了。
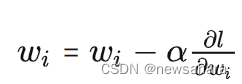
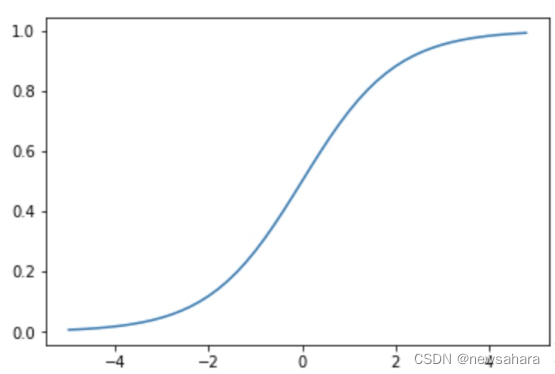
如果激活函数求导后与权重相乘的积大于1,随着层数增多,求出的梯度更新信息将以指数形式增加,即发生梯度爆炸;
如果此部分小于1,随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生梯度消失。
7.梯度消失和爆炸问题的解决方法
——引用自这里:https://zhuanlan.zhihu.com/p/180568816
(1)采用Relu激活函数:其思想是,如果激活函数的导数为1,那么就消除了激活函数偏导数的影响,只需考虑权值即可。
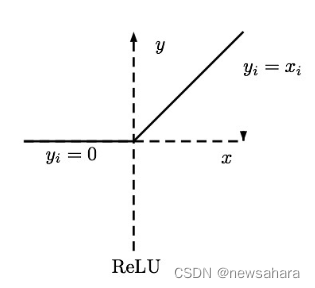
(2)采用Batch Normal
为了梯度下降的收敛速度更快,相当于把数据都拉到中间的位置了,有这个就不需要Dropout,Relu等等。BN使得每层输出信号满足均值为0,方差为1的分布,而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入,从而保证整个网络的稳定性。简而言之,BN包括两点:归一化+缩放平移。
(3)使用残差网络结构

