
重构输入和少样本学习:变分自动编码器_变分变分自动编码器
赞
踩

概述
变分自动编码器 (VAE) 是一种深度学习模型,可以生成新的数据样本。它由编码器网络和解码器网络两部分组成。编码器网络将输入数据映射到低维潜在空间,解码器网络将潜在表示映射回原始数据空间。
变分自动编码器简介
变分自动编码器 (VAE) 是生成模型,用于学习数据集的基础概率分布并生成新样本。它们使用编码器-解码器体系结构,其中编码器将输入数据映射到潜在表示,解码器尝试从此潜在表示中重建原始数据。VAE 经过训练,可以最小化原始数据和重建数据之间的差异,使其能够学习数据的基础分布并生成遵循相同分布的新样本。
VAE 的主要优势之一是它们可以生成类似于训练数据的新数据样本。这是因为 VAE 学习的潜在空间是连续的,这使得解码器能够生成新的数据点,这些数据点在训练数据点之间平滑插值。
VAE 有一些应用,包括图像生成、文本生成和密度估计。它们还被用于各个领域,包括计算机视觉、自然语言处理和金融。
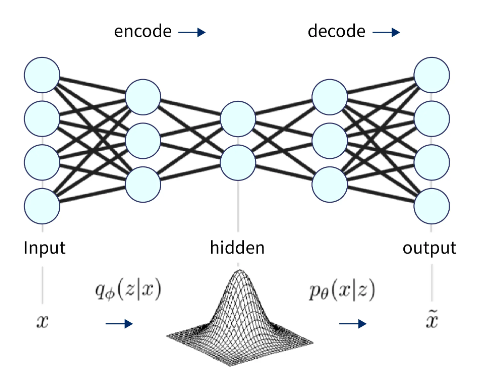
变分自动编码器的架构
VAE的架构通常由编码器网络和解码器网络组成。编码器网络将输入数据映射到较低维的潜在空间,通常称为“潜在代码”。解码器网络将潜在代码作为输入,并尝试重建原始数据。
编码器网络可以是任何神经网络,例如全连接神经网络或卷积神经网络。编码器网络的输出是高斯分布的均值和方差,用于对潜在代码进行采样。
解码器网络也可以是任何经过训练的神经网络,用于从潜在代码中重建原始数据。
以下是VAE架构的简单示例:

在此体系结构中,编码器网络将输入数据映射到潜在代码,解码器网络将潜在代码映射回重建的数据。然后对VAE进行训练,以最小化输入数据和重建数据之间的重建误差。
关于正则化的直觉
除了架构之外,VAE 的另一个重要方面是应用于潜在代码的正则化。在 VAE 中,使用具有固定均值和方差的高斯分布对潜在代码进行正则化。这种正则化通过鼓励潜在代码具有平滑分布而不是记忆训练数据来帮助防止过度拟合。
这种正则化还允许 VAE 生成新的数据样本,这些样本在训练数据点之间平滑插值。这使得 VAE 成为生成类似于训练数据的新数据样本的强大工具。此外,VAE中的正则化也会阻止解码器网络完美地重建输入数据。取而代之的是,解码器网络被迫学习更通用的数据表示,这有助于提高VAE生成新数据样本的能力。
以下是在 VAE 中以数学方式表述正则化的一种方法:
编码器网络输出潜在代码的高斯分布参数,通常是均值和对数方差(或标准差)。然后从该高斯分布中采样潜在代码。该分布与先验分布(通常假定为标准正态分布)之间的 KL 散度作为正则化项添加到 VAE 的损失函数中。
损失函数中的 KL 散度项将鼓励学习到的潜在变量具有与先验相似的分布。
KL背离公式:
![]()
总体而言,VAE 中的正则化有助于提高模型生成新数据样本的能力,并防止过度拟合训练数据。
VAE的数学细节
概率框架和假设
VAE 的概率框架通常定义如下:
- 潜在变量: z,假定它遵循先前的分布p(z)(例如,高斯)。
- 观察到的变量: x,假设遵循似然分布p(x∣z)(例如,伯努利)。
- 观测变量和潜在变量的联合分布为: p(x,z)= p(x∣z) p(z)
VAE 的主要目标是在给定观测变量的情况下学习潜在变量的真实后验分布,这些变量定义为p(z∣x)。VAE使用编码器网络通过学习近似来近似真实的后验分布q(z∣x)来实现这一点。
有向图形模型可以表示 VAE 的图形表示,如下所示:
- z <-------- p(z) (prior)
- |
- |
- v
- x <-------- p(x|z) (likelihood)
哪里x是观测到的变量,并且z是潜在变量。VAE 通过最大化证据下限 (ELBO) 来学习模型的参数,该下限定义为
![]()
等式右侧的第一项是重建项,它衡量 VAE 重建输入数据的能力。第二项,KL 散度,衡量近似后验分布和先验分布之间的差值。
VAE 使用概率框架对数据进行建模,方法是假设输入数据是根据某些概率分布从潜在空间生成的。目标是通过最大化输入数据的可能性来学习真正的后验分布。
变分推理公式
VAE 的变分推理公式通常定义如下:
- 近似后部分布:q(z∣x)
- 真正的后验分布:p(z∣x)
目标是找到近似的后验分布q(z∣x)最接近真实后验分布p(z∣x)关于KL背离。
两个分布之间的 KL 散度定义为
![]()
VAE 经过训练,通过最大化证据下限 (ELBO) 来最小化 KL 差异,定义为
![]()
等式右侧的第一项是重建项,它衡量 VAE 重建输入数据的能力。第二项,KL 散度,衡量近似后验分布和真实后验分布之间的差异。
有向图形模型可以表示具有变分推理的 VAE 的图形表示,如下所示:
- z <-------- p(z|x) (true posterior)
- |
- |
- v
- x <-------- p(x|z) (likelihood)
-
- z <-------- q(z|x) (approximate posterior)
哪里x是观测到的变量,并且z是潜在变量
总体而言,VAE 使用变分推理通过最小化变分分布和真实后验分布之间的 KL 散度并尽可能准确地重建输入数据,以更简单的分布来近似潜在空间上的真实后验分布。
模型中的神经网络
VAE 可以使用编码器和解码器的神经网络来实现。编码器网络将输入数据映射到低维潜在空间,解码器网络将潜在代码映射回原始数据空间。
在训练过程中,VAE优化了编码器和解码器网络的参数,以最小化重构误差以及变分分布与真实后验分布之间的KL散度。这通常使用优化算法(如随机梯度下降)来完成。
变分自动编码器的实现
在实现变分自动编码器之前,建立理解基础非常重要。需要注意的是,实现变分自动编码器可能是一个复杂的主题;但是,通过遵循合乎逻辑和清晰的结构,我们可以使学习体验更易于理解和理解。
我们将首先介绍基本概念,并使用带有示例的实践方法了解实现细节。
数据准备
您提供的代码将加载 MNIST 数据集,该数据集广泛用于机器学习和计算机视觉任务。该数据集包含 60,000 张 28x28 灰度图像,包括手写数字 (0-9) 及其对应的标签(图像中写入的数字)。
图像位于 x_train 和 x_test 变量中,而其标签位于 y_train 和 y_test 中。然后,该代码通过将所有像素值除以 255 并调整输入数据的形状以添加批处理维度来规范化输入数据。这是机器学习中输入数据的常见预处理步骤,它是一种确保数据格式正确,以便训练模型的方法。
- import tensorflow as tf
- import numpy as np
-
- (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
-
- # Normalize the input data
- x_train = x_train / 255.
- # Reshape the input data to have an additional batch dimension
- x_train = x_train.reshape((-1, 28*28))
- x_test = x_test.reshape((-1, 28*28))
模型定义
VAE模型由编码器、解码器以及两者的组合组成。编码器使用 ReLU 激活函数通过两个密集层将输入图像映射到潜在空间。解码器映射潜在向量,通过两个密集层重建原始图像。
定义“输入”维度、“隐藏”维度和“潜在”维度:
- input_dim = 28*28
- hidden_dim = 512
- latent_dim = 128
定义编码器架构:
- encoder_input = tf.keras.Input(shape=(input_dim,))
- encoder_hidden = tf.keras.layers.Dense(hidden_dim, activation='relu')(encoder_input)
- latent = tf.keras.layers.Dense(latent_dim)(encoder_hidden)
- encoder = tf.keras.Model(encoder_input, latent)
定义解码器架构:
- decoder_input = tf.keras.Input(shape=(latent_dim,))
- decoder_hidden = tf.keras.layers.Dense(hidden_dim, activation='relu')(decoder_input)
- decoder_output = tf.keras.layers.Dense(input_dim)(decoder_hidden)
- decoder = tf.keras.Model(decoder_input, decoder_output)
定义VAE架构:
- inputs = tf.keras.Input(shape=(input_dim,))
- latent = encoder(inputs)
- outputs = decoder(latent)
- vae = tf.keras.Model(inputs, outputs)
训练模型
VAE 使用 Adam 优化器和二元交叉熵损失函数进行训练。训练是小批量完成的,计算损失并反向传播每个图像的梯度。该过程重复一定数量的纪元。
- # Define the loss function and the optimizer
- loss_fn = tf.keras.losses.BinaryCrossentropy()
- optimizer = tf.keras.optimizers.Adam()
-
- # Train the VAE
- num_epochs = 50
- for epoch in range(num_epochs):
- for x in x_train:
- # Add batch dimension
- x = x[tf.newaxis, ...]
-
- with tf.GradientTape() as tape:
- # Forward pass
- reconstructed = vae(x)
-
- # Compute the loss
- loss = loss_fn(x, reconstructed)
-
- # Backward pass and optimize
- grads = tape.gradient(loss, vae.trainable_variables)
- optimizer.apply_gradients(zip(grads, vae.trainable_variables))
-
- # Print the loss every epoch
- print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.numpy():.4f}')

输出:
- Epoch 1/10, Loss: 0.3559
- Epoch 2/10, Loss: 0.3550
- Epoch 3/10, Loss: 0.3677
- Epoch 4/10, Loss: 0.3559
- Epoch 5/10, Loss: 0.3550
- Epoch 6/10, Loss: 0.3540
- Epoch 7/10, Loss: 0.3542
- Epoch 8/10, Loss: 0.3441
- Epoch 9/10, Loss: 0.3311
- Epoch 10/10, Loss: 0.3240..........
生成样本
在此代码中,latent_samples 变量现在定义为 (5, latent_dim) 的形状,因此它将生成 5 个随机样本而不是 10 个。for 循环也迭代了 5 次,显示 5 个生成的样本,而不是 10 个。子绘图函数也已更新,以 1 行和 5 列的网格显示生成的样本。
- # Generate samples
- latent_samples = tf.random.normal(shape=(5, latent_dim))
- generated_samples = decoder(latent_samples)
-
- # Plot the generated samples
- import matplotlib.pyplot as plt
-
- for i in range(5):
- plt.subplot(1, 5, i+1)
- plt.imshow(generated_samples[i].numpy().reshape(28, 28), cmap='gray')
- plt.axis('off')
-
- plt.show()
输出:
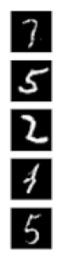
此代码的输出将是一个图形,该图形显示五个生成的图像,类似于 MNIST 测试集中的图像。图像将显示在 5 列和 1 行的网格中,每列和 1 行都是灰度的,使用不带轴的“灰色”颜色图。
潜在空间的可视化
要可视化 VAE 的潜在空间,您可以先使用 VAE 将训练数据点编码到潜在空间中,然后使用 t-SNE 等降维技术将潜在空间映射到可以绘制的 2D 空间。
- import tensorflow as tf
- from sklearn.manifold import TSNE
-
- # Use the VAE to encode the training data points into the latent space
- latent_vectors = encoder(x_train).numpy()
-
- # Use t-SNE to map the latent space to a 2D space
- latent_2d = TSNE(n_components=2).fit_transform(latent_vectors)
-
- # Plot the latent space
- plt.scatter(latent_2d[:, 0], latent_2d[:, 1], c=y_train, cmap='viridis')
- plt.colorbar()
- plt.show()
-
输出:
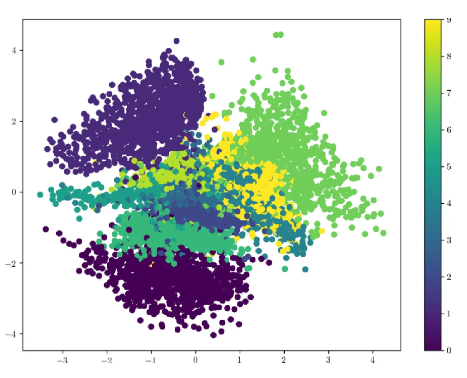
可视化变分自动编码器 (VAE) 的潜在空间有助于理解训练 VAE 的数据的结构和组织。
变分自动编码器作为生成模型
VAE 可以用作生成模型,这意味着它们可以学习生成类似于训练数据集的新样本。这是通过学习数据的潜在表示并从该潜在空间中采样以生成新样本来实现的。
为了使用 VAE 生成新样本,我们首先将给定的输入样本编码到潜在空间中,然后从编码样本定义的分布中采样一个新的潜点。该潜在点通过解码器网络以生成输出样本。

由于 VAE 经过训练可以重建输入数据,因此它学会了连续、平滑地将潜在点映射到数据分布。因此,我们可以在潜在点之间进行插值,以生成新样本,这些样本是输入数据的平滑变化。
结论
- VAEs是一个生成模型,可以学习从给定的数据集中重建和生成新样本。
- VAE 使用潜在空间连续、平滑地表示数据,从而允许生成输入数据的平滑变化。
- VAE 由将输入数据映射到潜在空间的编码器网络、将潜在空间映射回数据空间的解码器网络以及结合重建损失和正则化项的损失函数组成。
- VAE 已用于图像生成、异常检测和半监督学习任务。

