
- 1python层次聚类选择类别_不写代码,教你用聚类算法,刻画一个升级版的RFM模型......
- 2鸿蒙ArkTS开发工具安装,环境配置
- 3uni-app网络请求封装跨域_前端面试准备---浏览器和网络篇(一)
- 4LangChain:Prompt Templates介绍及应用_langchain prompttemplate
- 5自然语言处理中的RoBERTa模型:BERT的进化
- 6Android——Paint.setXfermode(Xfermode xf)相关_android开发者 xfermode 参数说明
- 7无人机采集图像的相关知识
- 8【Android签名机制详解】一:密码学入门_安卓公钥 dsa rsa
- 910、HTML基础——列表元素_列表元素不显示原点和编号
- 1002-线性结构2 一元多项式的乘法与加法运算(把两个变量一个放入数组下标里面,一个放入数组值里面)_数组下标相乘
【视频】马尔可夫链蒙特卡罗方法MCMC原理与R语言实现|数据分享
赞
踩
原文链接:http://tecdat.cn/?p=2687
在贝叶斯方法中,马尔可夫链蒙特卡罗方法尤其神秘(点击文末“阅读原文”获取完整代码数据)。
它们肯定是数学繁重且计算量大的过程,但它们背后的基本推理,就像数据科学中的许多其他东西一样,可以变得直观。这就是我的目标。
相关视频
那么,什么是马尔可夫链蒙特卡罗(MCMC)方法?简短的回答是:
MCMC 方法用于通过概率空间中的随机抽样来近似感兴趣参数的后验分布。

在这篇文章中,我将解释这个简短的答案。
首先,一些术语。感兴趣的参数只是总结我们感兴趣的现象的一些数字。通常我们使用统计数据来估计参数。例如,如果我们想了解成年人的身高,我们感兴趣的参数可能是平均身高。分布是我们参数的每个可能值的数学表示,以及我们观察每个值的可能性。最著名的例子是钟形曲线:
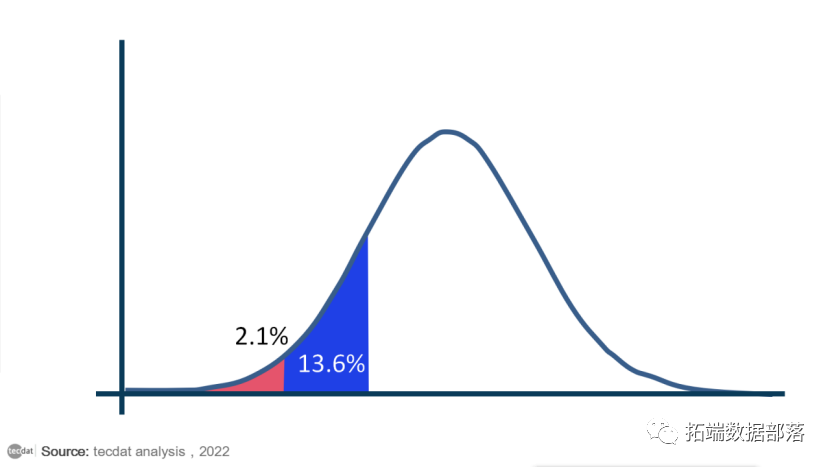
在贝叶斯统计方法中,分布有额外的解释。贝叶斯不仅表示参数的值以及每个参数成为真实值的可能性,而是将分布视为描述我们对参数的信念。因此,上面的钟形曲线表明我们非常确定参数的值非常接近于零,但我们认为真实值高于或低于该值的可能性相同,直到某个点。
碰巧的是,人类身高确实遵循正态曲线,所以假设我们相信人类平均身高的真实值遵循如下钟形曲线:
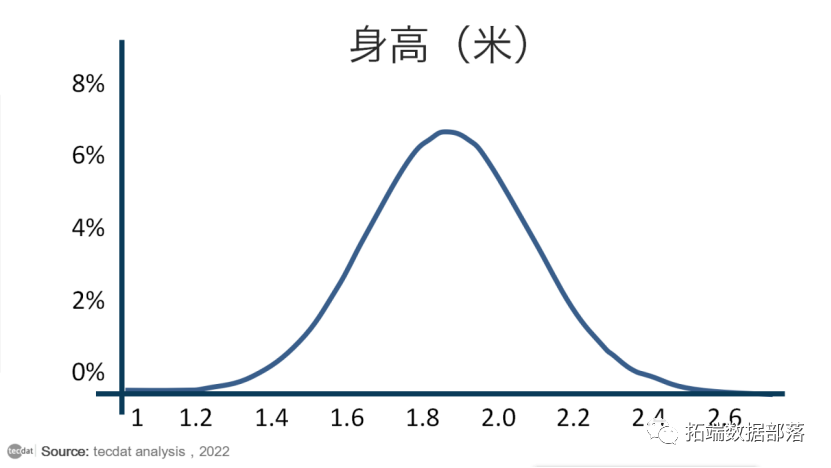
显然,这张图所代表的有信仰的人多年来一直生活在巨人中间,因为据他们所知,最有可能的成人平均身高是1米8(但他们并不是特别自信)。
让我们想象一下这个人去收集了一些数据,他们观察了1米6到 1米8之间的人群。我们可以在下面表示该数据,以及另一条显示人类平均身高值最能解释数据的正态曲线:
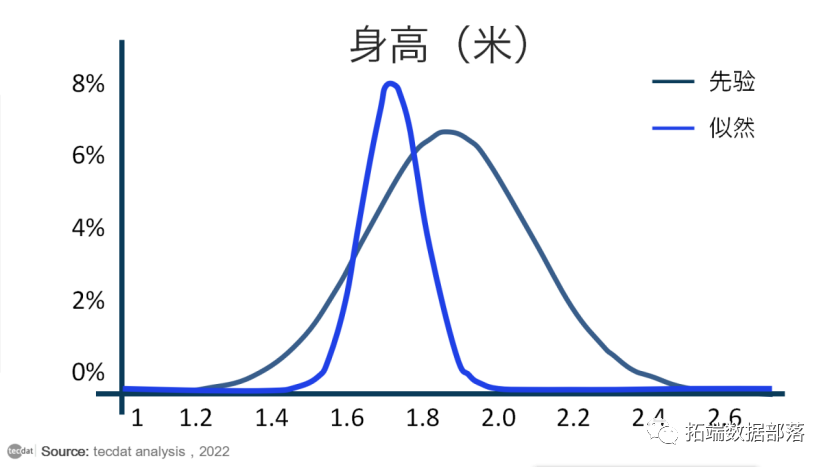
在贝叶斯统计中,代表我们对参数的信念的分布称为先验分布,因为它在看到任何数据之前捕获了我们的信念。似然分布通过表示一系列参数值以及每个参数解释我们正在观察的数据的可能性来总结观察到的数据告诉我们的内容。估计最大化似然分布的参数值只是回答了这个问题:什么参数值最有可能观察到我们观察到的数据?在没有先验信念的情况下,我们可能会止步于此。
然而,贝叶斯分析的关键是结合先验分布和似然分布来确定后验分布。这告诉我们,考虑到我们先前的信念,哪些参数值可以最大限度地提高观察我们所做的特定数据的机会。在我们的例子中,后验分布如下所示:
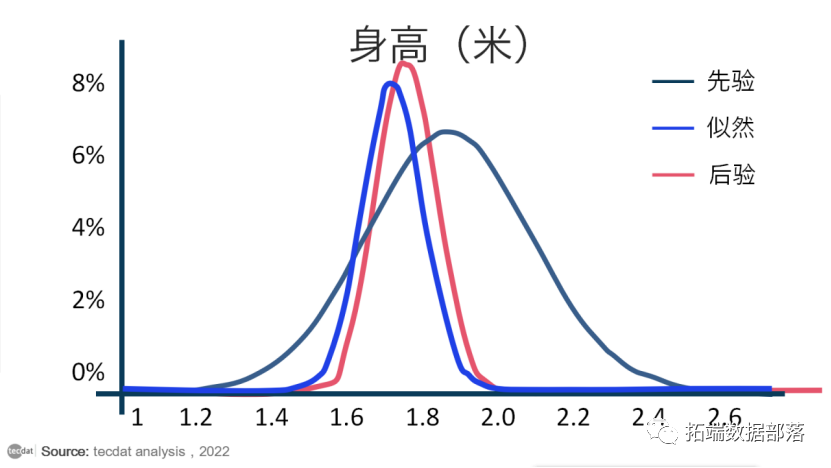
上图,红线代表后验分布。您可以将其视为先验分布和似然分布的一种平均值。由于先验分布更短且分布更广,因此它代表了一组对人类平均身高的真实值“不太确定”的信念。同时,似然总结了相对狭窄范围内的数据,因此它代表了对真实参数值的“更确定”的猜测。
当先验可能性结合起来时,数据(由可能性表示)支配了在巨人中长大的假设个人的弱先验信念。尽管那个人仍然认为人类的平均身高比数据告诉他的要高一些,但他基本上相信数据。
在两条钟形曲线的情况下,求解后验分布非常容易。有一个简单的公式可以将两者结合起来。但是,如果我们的先验分布和似然分布没有那么好怎么办?有时,使用没有方便形状的分布对我们的数据或我们的先验信念进行建模是最准确的。如果我们的概率最好由具有两个峰值的分布来表示,并且出于某种原因我们想要解释一些非常古怪的先验分布怎么办?我通过手绘一个丑陋的先验分布来可视化下面的场景:
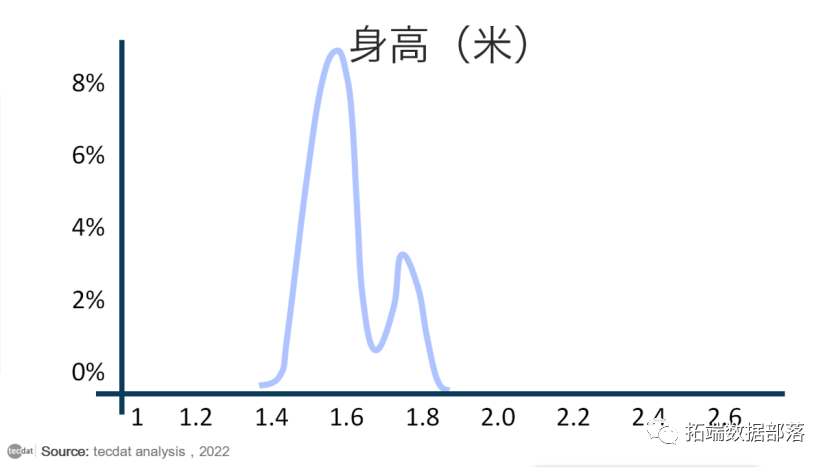
和以前一样,存在一些后验分布,它给出了每个参数值的可能性。但它有点难以看出它可能是什么样子,并且不可能通过分析来解决。
MCMC 方法
MCMC 方法允许我们估计后验分布的形状,以防我们无法直接计算它。回想一下,MCMC 代表马尔可夫链蒙特卡罗方法。为了理解它们是如何工作的,我将介绍蒙特卡罗模拟。
蒙特卡罗模拟只是一种通过重复生成随机数来估计固定参数的方法。通过获取生成的随机数并对它们进行一些计算,蒙特卡洛模拟提供了一个参数的近似值。

假设我们想估计圆的面积:
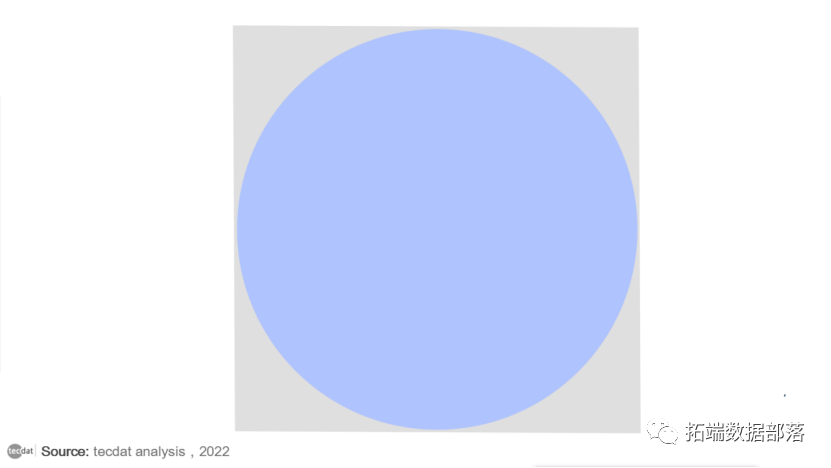
由于圆在边长为 1的正方形内,因此面积可以很容易地计算为 0.785 。但是,我们可以在正方形内随机放置 20 个点。然后我们计算落在圆圈内的点的比例,并将其乘以正方形的面积。这个数字是圆面积的一个很好的近似值。
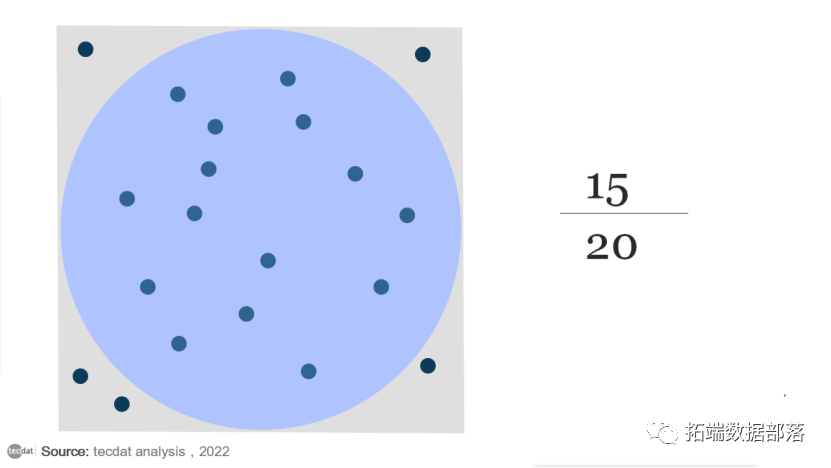
由于 20 个点中有 15 个位于圆内,因此该圆看起来约为 0.75 。对于只有 20 个随机点的蒙特卡洛模拟来说还不错。
蒙特卡罗模拟不仅用于估计困难形状的区域。通过生成大量随机数,它们可用于对非常复杂的过程进行建模。
有了蒙特卡罗模拟和马尔可夫链的一些知识,我希望对 MCMC 方法如何工作的无数学解释非常直观。
回想一下,我们正在尝试估计我们感兴趣的参数的后验分布,即人类平均身高:
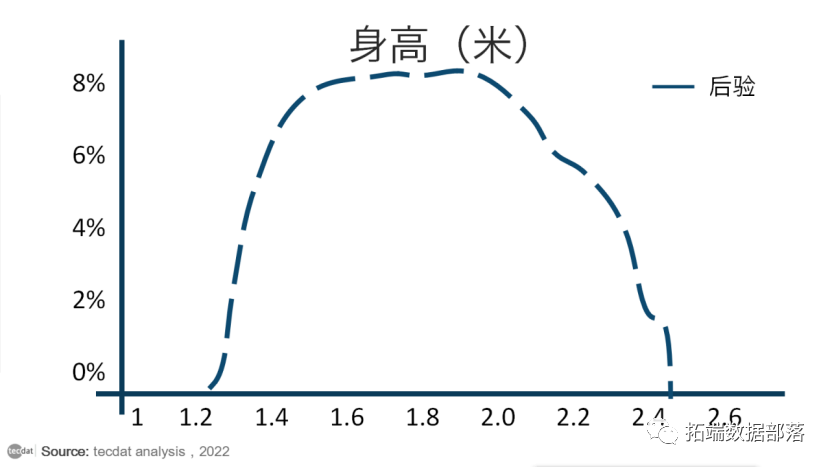
我不是可视化专家,显然我也不擅长将我的示例保持在常识范围内:我的后验分布示例严重高估了人类的平均身高。
我们知道后验分布在我们的先验分布和似然分布的范围内,但无论出于何种原因,我们都无法直接计算它。使用 MCMC 方法,我们将有效地从后验分布中抽取样本,然后计算统计数据,例如抽取样本的平均值。
首先,MCMC 方法选择一个随机参数值来考虑。模拟将继续生成随机值(这是蒙特卡洛部分),但要遵守一些规则来确定什么是好的参数值。诀窍是,对于一对参数值,可以通过计算每个值解释数据的可能性来计算哪个是更好的参数值,给定我们的先验信念。如果随机生成的参数值比上一个更好,则以一定的概率将其添加到参数值链中,该概率取决于它的好坏程度(这是马尔可夫链部分)。
为了直观地解释这一点,让我们回想一下某个值的分布高度代表观察该值的概率。因此,我们可以认为我们的参数值(x 轴)展示了高概率和低概率的区域,显示在 y 轴上。对于单个参数,MCMC 方法从沿 x 轴随机采样开始:
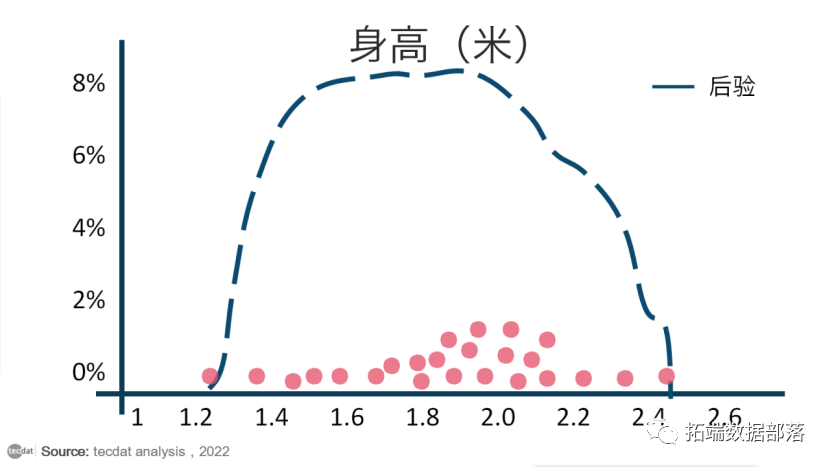
红点是随机参数样本
由于随机样本受固定概率的影响,它们往往会在一段时间后收敛于我们感兴趣的参数的最高概率区域:
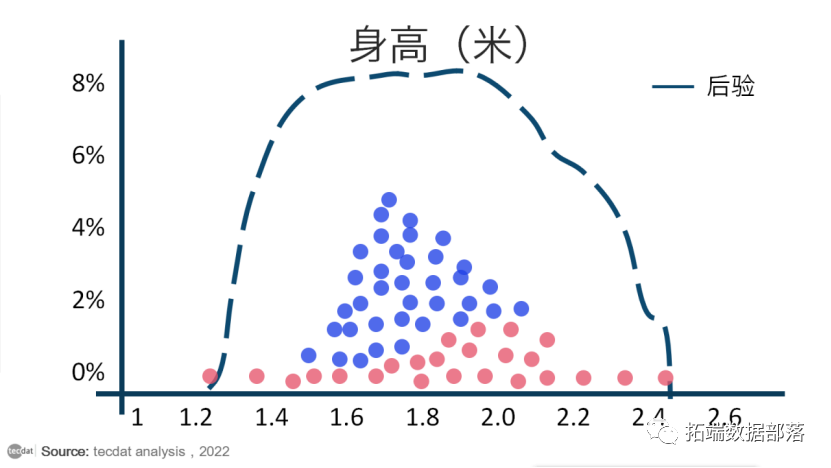
蓝点仅代表任意时间点之后的随机样本,此时预计会发生收敛。注意:垂直堆叠点纯粹是为了说明目的。
收敛后,MCMC 采样会产生一组点,这些点是来自后验分布的样本。围绕这些点绘制直方图,并计算您喜欢的任何统计数据:
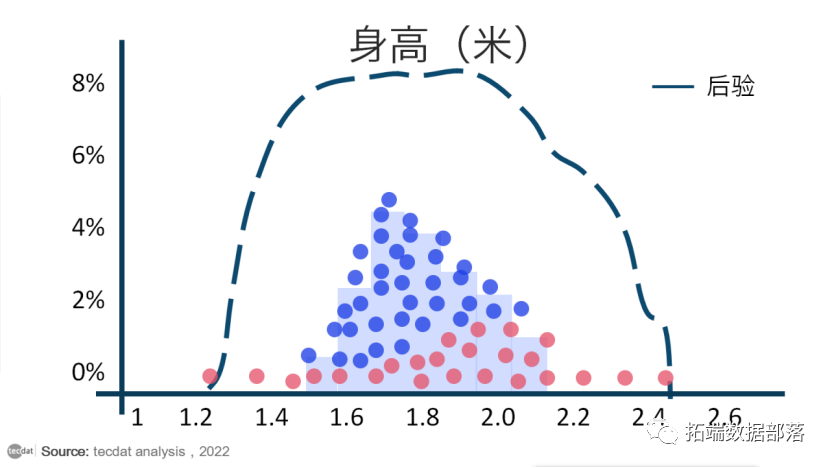
在 MCMC 模拟生成的样本集上计算的任何统计量都是我们对真实后验分布统计量的最佳猜测。
MCMC 方法也可用于估计多个参数(例如人的身高和体重)的后验分布。对于n 个参数,在 n 维空间中存在高概率区域,其中某些参数值集可以更好地解释观察到的数据。因此,我认为 MCMC 方法是在概率空间内随机抽样以近似后验分布。
点击标题查阅往期内容

R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样

左右滑动查看更多
01
02
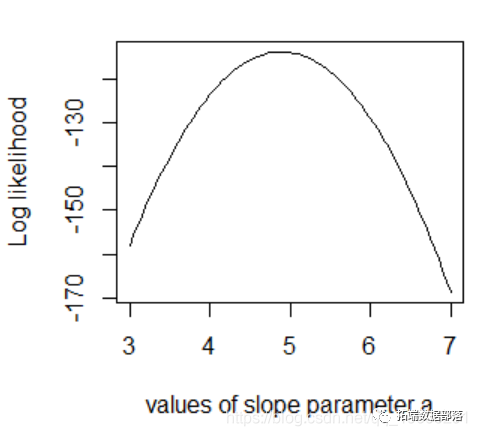
03
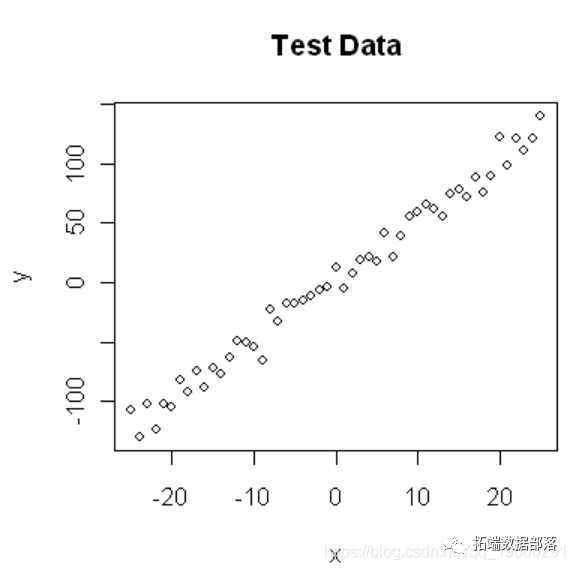
04

什么是MCMC,什么时候使用它?
MCMC只是一个从分布抽样的算法。
这只是众多算法之一。这个术语代表“马尔可夫链蒙特卡洛”,因为它是一种使用“马尔可夫链”(我们将在后面讨论)的“蒙特卡罗”(即随机)方法。MCMC只是蒙特卡洛方法的一种,尽管可以将许多其他常用方法看作是MCMC的简单特例。
我为什么要从分布中抽样?
从分布中抽取样本是解决一些问题的最简单的方法。
可能MCMC最常用的方法是从贝叶斯推理中的某个模型的后验概率分布中抽取样本。通过这些样本,你可以问一些问题:“参数的平均值和可信度是多少?”。
如果这些样本(查看文末了解数据获取方式)是来自分布的独立样本,则 估计均值将会收敛在真实均值上。
假设我们的目标分布是一个具有均值m和标准差的正态分布s。
作为一个例子,考虑用均值m和标准偏差s来估计正态分布的均值(在这里,我将使用对应于标准正态分布的参数):
我们可以很容易地使用这个rnorm 函数从这个分布中抽样
seasamples<-rn 000,m,s)样本的平均值非常接近真实平均值(零):
- mean(sa es)
-
-
-
- ## \[1\] -0. 537
事实上,在这种情况下,$ n $样本估计的预期方差是$ 1 / n $,所以我们预计大部分值在$ \ pm 2 \,/ \ sqrt {n} = 0.02 。
- summary(re 0,mean(rnorm(10000,m,s))))
-
-
-
- ## Min. 1st Qu. Median Mean 3rd Qu. Max.
-
- ## -0.03250 -0.00580 0.00046 0.00042 0.00673 0.03550
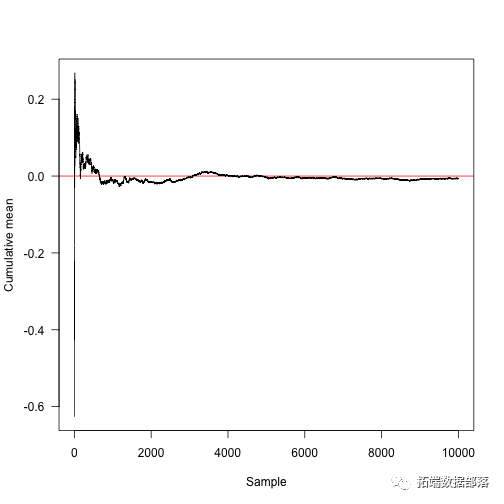
这个函数计算累积平均值之和。
- cummean<-fun msum(x)/seq_along(x)
-
-
-
- plot(cummaaSample",ylab="Cumulative mean",panel.aabline(h=0,col="red"),las=1)
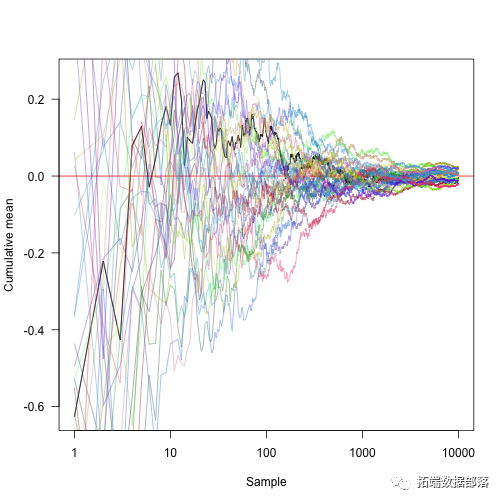
将x轴转换为对数坐标并显示另外30个随机方法:
可以从您的一系列采样点中抽取样本分位数。
这是分析计算的点,其概率密度的2.5%低于:
p<-0.025a.true<-qnorm(p,m,s)a.true1## \[1\] -1.96我们可以通过在这种情况下的直接整合来估计这个
- aion(x)dnorm(x,m,s)
-
- g<-function(a)integrate(f,-Inf,a)$valuea.int<-uniroot(function(x)g(a10,0))$roota.int1## \[1\] -1.96
并用Monte Carlo积分估计点:
a.mc<-unnasamples,p))a.mc## \[1\] -2.023a.true-a.mc## \[1\] 0.06329但是,在样本量趋于无穷大的极限内,这将会收敛。此外,有可能就错误的性质作出陈述; 如果我们重复采样过程100次,那么我们得到一系列与均值附近的误差相同幅度的误差的估计:
- a.mc<-replicate(anorm(10000,m,s),p))
-
- summary(a.true-a.mc)
-
- ## Min. 1st Qu. Median Mean 3rd Qu. Max. ## -0.05840 -0.01640 -0.00572 -0.00024 0.01400 0.07880
这种事情真的很常见。在大多数贝叶斯推理中,后验分布是一些(可能很大的)参数向量的函数,您想对这些参数的子集进行推理。
在一个等级模型中,你可能会有大量的随机效应项被拟合,但是你最想对一个参数做出推论。在
贝叶斯框架中,您可以计算您感兴趣的参数在所有其他参数上的边际分布(这是我们上面要做的)。
为什么“传统统计”不使用蒙特卡洛方法?
对于传统教学统计中的许多问题,不是从分布中抽样,可以使函数最大化或最大化。所以我们需要一些函数来描述可能性并使其最大化(最大似然推理),或者一些计算平方和并使其最小化的函数。
然而,蒙特卡罗方法在贝叶斯统计中的作用与频率统计中的优化程序相同,这只是执行推理的算法。所以,一旦你基本知道MCMC正在做什么,你可以像大多数人把他们的优化程序当作黑匣子一样对待它,像一个黑匣子。
马尔可夫链蒙特卡罗
假设我们想要抽取一些目标分布,但是我们不能像从前那样抽取独立样本。有一个使用马尔科夫链蒙特卡洛(MCMC)来做这个的解决方案。首先,我们必须定义一些事情,以便下一句话是有道理的:我们要做的是试图构造一个马尔科夫链,它抽样的目标分布作为它的平稳分布。
定义
假设我们有一个三态马尔科夫过程。让我们P为链中的转移概率矩阵:
- P<-rbind(a(.2,.1,.7),c(.25,.25,.5))P ## \[,1\] \[,2\] \[,3\]## \[1,\] 0.50 0.25 0.25## \[2,\] 0.20 0.10 0.70## \[3,\] 0.25 0.25 0.50 rowSums(P)
-
-
-
- ## \[1\] 1 1 1
P[i,j]给出了从状态i到状态的概率j。
请注意,与行不同,列不一定总和为1:
- colSums(P)
-
-
-
- ## \[1\] 0.95 0.60 1.45
这个函数采用一个状态向量x(其中x[i]是处于状态的概率i),并通过将其与转移矩阵相乘来迭代它P,使系统前进到n步骤。
- iterate.P<-function(x,P,n){
-
- res<-matrix(NA,n+1,len
-
- a<-xfor(iinseq_len(n))
-
- res\[i+1,\]<-x<-x%*%P
-
- res}
从处于状态1的系统开始(x向量 [1,0,0] 也是如此,表示处于状态1的概率为100%,不处于任何其他状态)
同样,对于另外两种可能的起始状态:
y2<-iterate.P(c(0,1,0),P,n)y3<-iterate.P(c(0,0,1),P,n)这表明了平稳分布的收敛性。
ma=1,xlab="Step",ylab="y",las=1)matlines(0:n,y2,lty=2)matlines(0:n,y3,lty=3)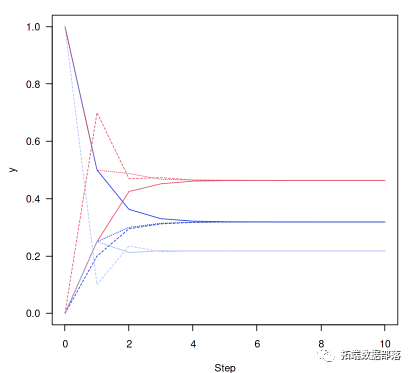
我们可以使用R的eigen函数来提取系统的主要特征向量(t()这里转置矩阵以便得到左特征向量)。
- v<-eigen(t(P)
-
- ars\[,1\]
-
- v<-v/sum(v)# 归一化特征向量
然后在之前的数字上加上点,表明我们有多接近收敛:
matplot(0:n,y1a3,lty=3)points(rep(10,3),v,col=1:3)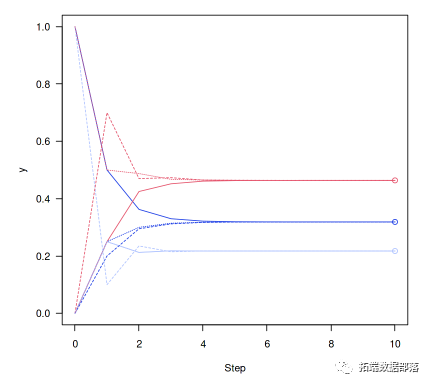
上面的过程迭代了不同状态的总体概率; 而不是通过系统的实际转换。所以,让我们迭代系统,而不是概率向量。
- run<-function(i,P,n){
-
- res<-integer(n)for(a(n))
-
- res\[\[t\]\]<-i<-sample(nrow(P),1,pr=P\[i,\])
-
- res}
这链条运行了100个步骤:
samples<-run(1,P,100)ploaes,type="s",xlab="Step",ylab="State",las=1)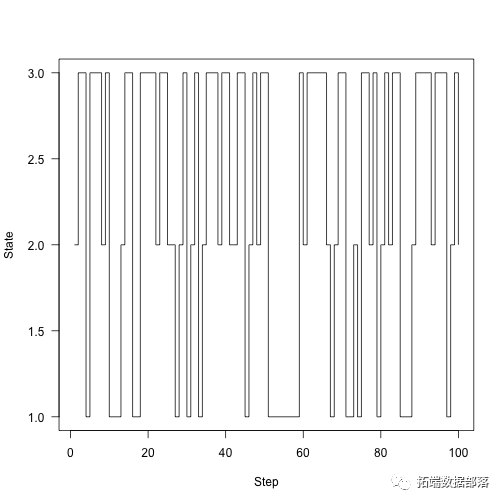
绘制我们在每个状态随时间变化的时间分数,而不是绘制状态:
plot(cummean(samplesa2)lines(cummean(samples==3),col=3)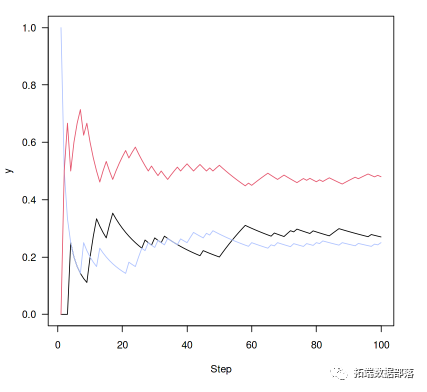
再运行一下(5000步)
- n<-5000set.seed(1)
-
- samples<-run(1,P,n)plot(cummeanasamples==2),col=2)lines(cummean(samples==3),col=3)abline(h=v,lty=2,col=1:3)
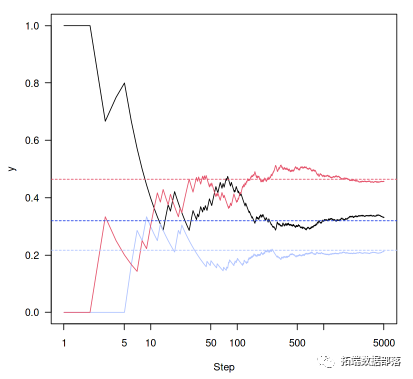
所以这里的关键是:马尔可夫链有一些不错的属性。马尔可夫链有固定的分布,如果我们运行它们足够长的时间,我们可以看看链条在哪里花费时间,并对该平稳分布进行合理的估计。
Metropolis算法
这是最简单的MCMC算法。
MCMC采样1d(单参数)问题
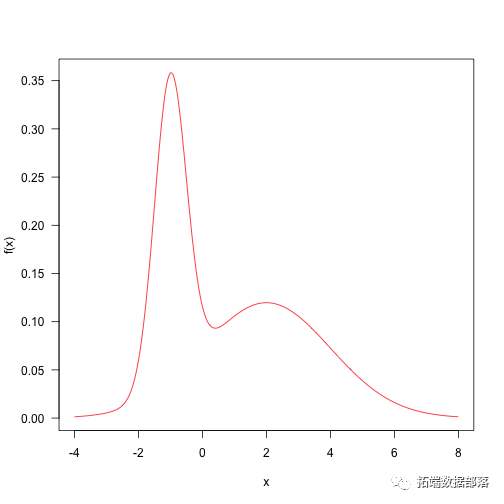
这是两个正态分布的加权和。这种分布相当简单,可以从MCMC中抽取样本。
这里是一些参数和目标密度的定义。
p<-0.4ma1,2)sd<-c(.5,2)f<-function(x)p\*dnora\],sd\[1\])+(1-p)\*dnorm(x,mu\[2\],sd\[2\])概率密度绘制
我们来定义一个非常简单的算法,该算法从以当前点为中心的标准偏差为4的正态分布中抽样
而这只需要运行MCMC的几个步骤。它将从点x返回一个矩阵,其nsteps行数和列数与x元素的列数相同。如果在标量上运行, x它将返回一个向量。
- run<-funagth(x))for(iinseq_len(nsteps))
-
- res\[i,\]<-x<-step(x,f,q)drop(res)}
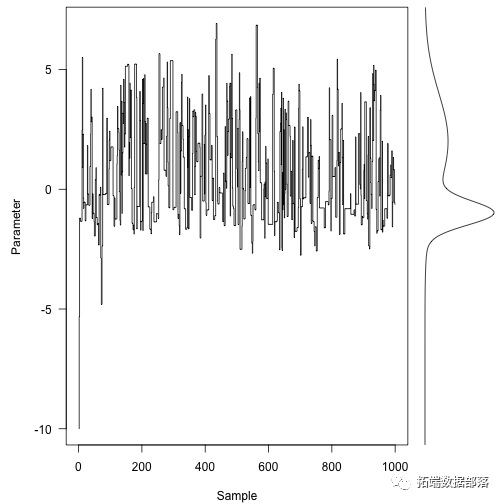
这里是马尔可夫链的前1000步,目标密度在右边:
- layout(matrix(ca,type="s",xpd=NA,ylab="Parameter",xlab="Sample",las=1)
-
- usr<-par("usr")
-
- xx<-seq(usr\[a4\],length=301)plot(f(xx),xx,type="l",yaxs="i",axes=FALSE,xlab="")
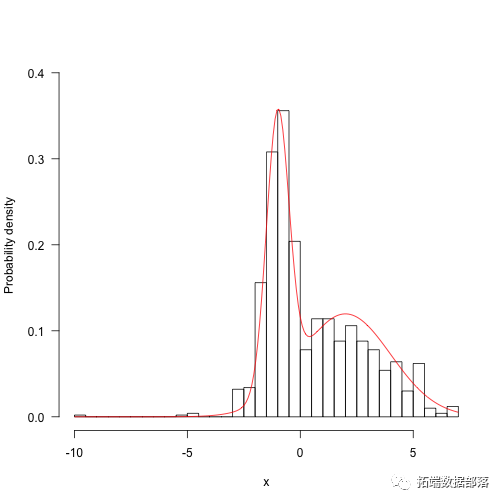
- hist(res,5aALSE,main="",ylim=c(0,.4),las=1,xlab="x",ylab="Probability density")
-
- z<-integrate(f,-Inf,Inf)$valuecurve(f(x)/z,add=TRUE,col="red",n=200)
运行更长时间,结果开始看起来更好:
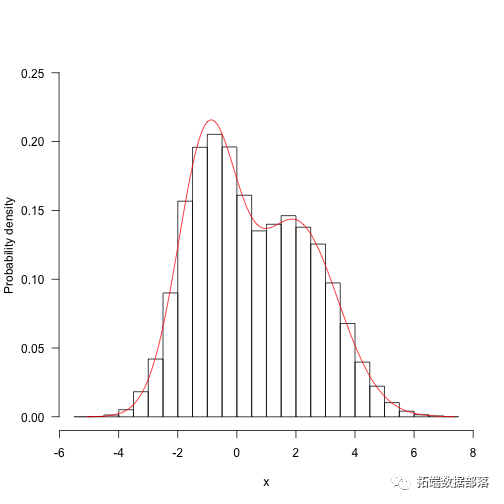
res.long<-run(-10,f,q,50000)hist(res.long,100,freq=FALSE,main="",ylim=c(0,.4),las=1,xlab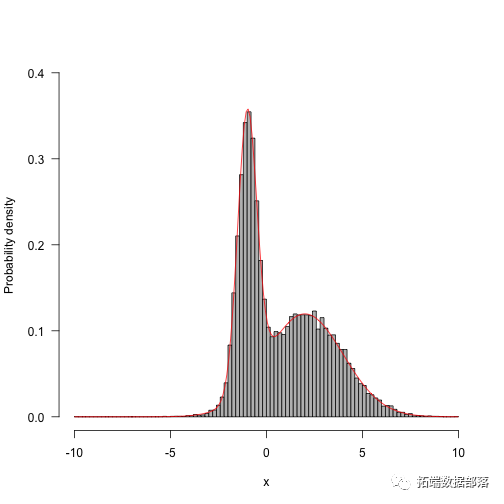
现在,运行不同的方案 - 一个标准差很大(33),另一个标准差很小(3)。
res.fast<-run(-10action(x)rnorm(1,x,33),1000)res.slow<-run(-10,f,functanorm(1,x,.3),1000)注意三条轨迹正在移动的不同方式。
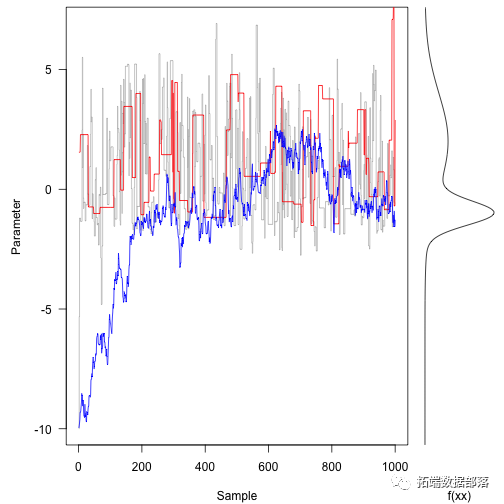
相反,红色的痕迹拒绝其中的大部分空间。
蓝色的踪迹提出了倾向于被接受的小动作,但是它随着大部分的轨迹随机行走。它需要数百次迭代才能达到概率密度的大部分。
您可以在随后的参数中看到不同方案步骤在自相关中的效果 - 这些图显示了不同滞后步骤之间自相关系数的衰减,蓝线表示统计独立性。
par(mfrow=c(1,3ain="Intermediate")acf(res.fast,las=1,m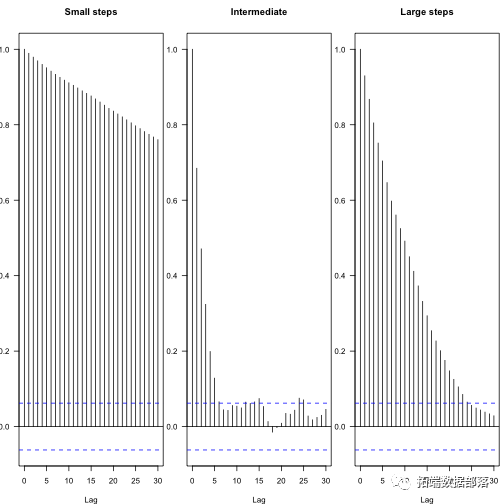
由此可以计算独立样本的有效数量:
1coda::effectiveSize(res)1 2## var1 ## 1871coda::effectiveSize(res.fast)1 2## var1 ## 33.191coda::effectiveSize(res.slow)1 2## var1 ## 5.378这更清楚地显示了链条运行时间更长的情况:
- naun(-10,f,q,n))
-
- xlim<-range(sapply(saa100)
-
- hh<-lapply(samples,function(x)hist(x,br,plot=FALSE))
-
- ylim<-c(0,max(f(xx)))
显示100,1,000,10,000和100,000步:
for(hinhh){plot(h,main="",freq=a=300)}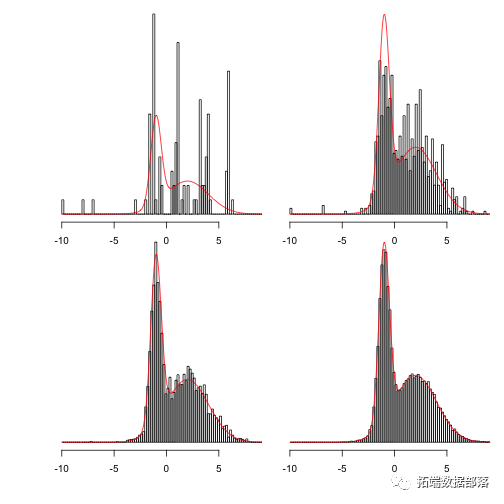
MCMC在两个维度
给出了一个多元正态密度,给定一个均值向量(分布的中心)和方差 - 协方差矩阵。
- make.mvn<-function(mean,vcv){
-
- logdet<-as.numeric(detea+logdet
-
- vcv.i<-solve(vcv)function(x){
-
- dx<-x-meanexp(-(tmp+rowSums((dx%*%vcv.i)*dx))/2)}}
如上所述,将目标密度定义为两个mvns的总和(这次未加权):
mu1<-c(-1,1)mu2<-c(2,-2)vcv1<-ma5,.25,1.5),2,2)vcv2<-matrix(c(2,-.5,-.5,2aunctioax)+f2(x)x<-seq(-5,6,length=71)y<-seq(-7,6,lena-expand.grid(x=x,y=y)z<-matrix(aaTRUE)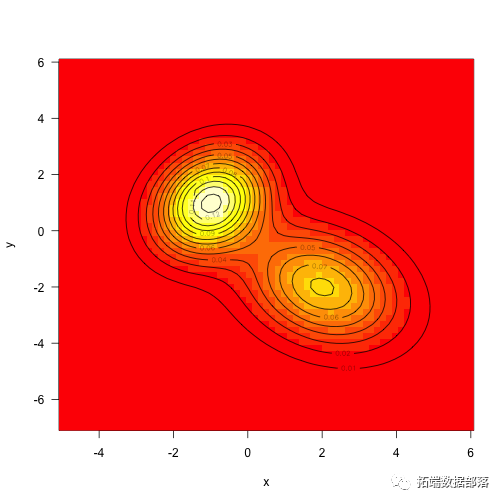
从多元正态分布取样也相当简单,但我们将使用MCMC从中抽取样本。
这里有一些不同的策略 - 我们可以同时在两个维度上提出动作,或者我们可以独立地沿着每个轴进行采样。这两种策略都能奏效,虽然它们的混合速度会有所不同。
假设我们实际上并不知道如何从mvn中抽样 ,让我们提出一个在两个维度上一致的提案分布,从每边的宽度为“d”的正方形取样。
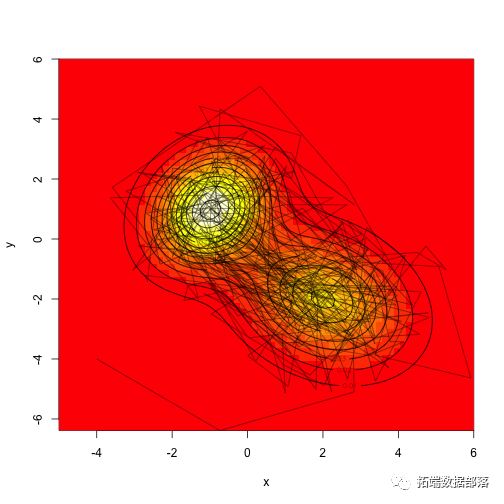
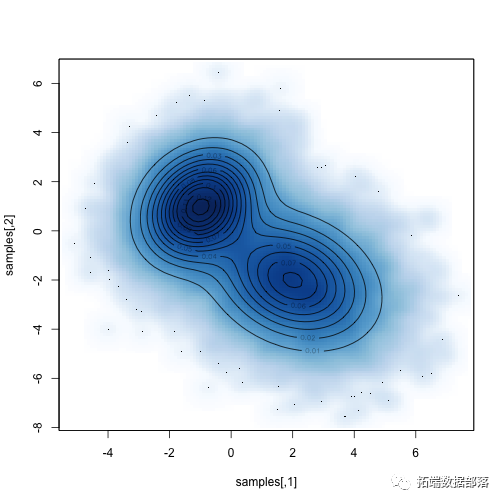
比较抽样分布与已知分布:
例如,参数1 的边际分布是多少?
hisales\[,1\],freq=FALSa",xlab="x",ylab="Probability density")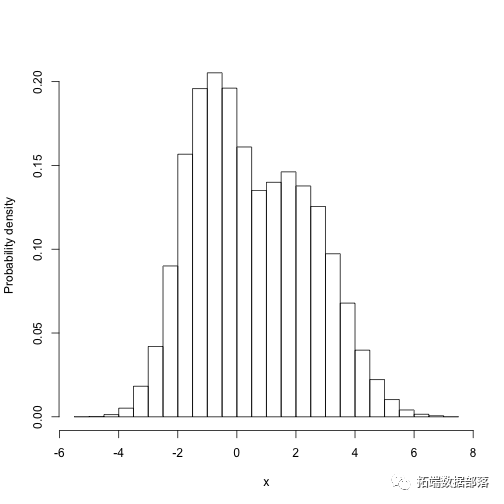
我们需要整合第一个参数的第二个参数的所有可能值。那么,因为目标函数本身并不是标准化的,所以我们必须将其分解为一维积分值 。
- m<-function(x1){
-
- g<-Vectorize(function(x2)f(c(x1,ae(g,-Inf,Inf)$value}
-
- xx<-seq(mina\]),max(sales\[,1\]),length=201)
-
- yy<-s
-
- uehist(samples\[,1\],freq=FALSE,ma,0.25))lines(xx,yy/z,col="red")
数据获取
在下面公众号后台回复“MCMC数据”,可获取完整数据。

点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言中实现马尔可夫链蒙特卡罗MCMC模型》。
点击标题查阅往期内容
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯METROPOLIS-HASTINGS GIBBS 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间
R语言马尔可夫MCMC中的METROPOLIS HASTINGS,MH算法抽样(采样)法可视化实例
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Matlab用BUGS马尔可夫区制转换Markov switching随机波动率模型、序列蒙特卡罗SMC、M H采样分析时间序列
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言BUGS序列蒙特卡罗SMC、马尔可夫转换随机波动率SV模型、粒子滤波、Metropolis Hasting采样时间序列分析
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计

![]()


