
- 1大地测量观测数据可视化MATLAB工具箱:(1)时间序列、统计数据可视化_visbundle
- 2ubuntu如何限制系统日志大小?
- 3UINO优锘科技助力银行业开启智慧运维,踏入智慧金融时代_优锘 故障运营
- 4SpringBoot启动流程源码分析二、SpringApplication准备阶段_设定managementfactory.getruntimemxbean().name 配置
- 5JAVA同城服务台球助教台球教练系统源码的实现流程
- 6文本生成图像新SOTA!RealCompo:逼真和构图的动态平衡(清北最新)_realcompo: dynamic equilibrium between realism and
- 7深入理解Spring Boot Controller层的作用与搭建过程_spring boot controller 处理流程
- 8PyTorch指标计算库TorchMetrics详解_pytorchlighning torchmetrics f1
- 9基础课5——垂直领域对话系统架构_垂直领域问答对话实现方法
- 10NLP-文本蕴含(文本匹配):概述【单塔模型、双塔模型】_文本蕴含任务
面试必问Redis缓存一致性问题和缓存击穿、雪崩、穿透、大Key/HotKey、倾斜_rdb.c.2888 duplicate key redis
赞
踩
1.一致性问题
所谓一致性问题,指的是缓存和数据库对同一份变量如何保持一致。
1.1 强一致性、最终一致性
一致性问题根据对缓存不一致的容忍程度可以划分为强一致和最终一致。强一致性保证只能通过一致性协议、分布式锁来进行控制。最终一致性可以通过MQ、最大努力通知等手段来实现。
1.2 先更新缓存,后更新DB
这个方案是最不可取的,因为如果一旦更新缓存成功,但是数据库写入失败就会发生脏数据问题。
1.3 先更新DB,后更新缓存
有可能发生数据库成功更新但是缓存更新失败,那么缓存中值永远都是旧的值。
1.4 先删缓存,后更新DB
这个设计存在2个问题:
1.如果先把缓存删掉,那么将会有大量读请求直接落地到DB层,造成DB压力。
2.如果A线程删了缓存,还没来得及更新DB,B线程过来发现缓存没有就去DB读取老数据,此时A线程更新完毕回写缓存,B线程最后回写缓存,此时缓存中仍然是旧的值。
1.5 先更新DB,后删缓存
和先删缓存后更细DB类似,同样存在两个问题。缓存可能仍然存的旧值。
1.6 优化方案
1.6.1 结合业务场景给缓存设置过期时间
1.6.2 异步延时双删
采用先删缓存,后更新DB,更新DB完成后再通过异步任务删除缓存。这样尽可能保证缓存中的数据和数据库是一致的。但是这样存在双删期间的脏数据问题。
1.6.3 canal组件结合MQ实现最终一致性
1.6.4 强一致性保障,锁/分布式读写锁
2.穿透、击穿、雪崩
2.1 缓存穿透
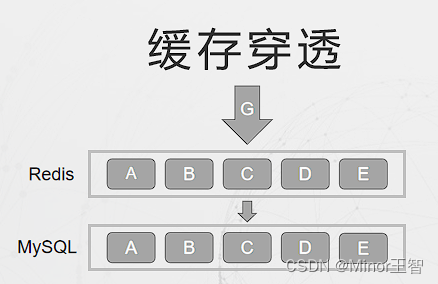
缓存穿透:是指查询一个根本不存在的数据,缓存层和存储层都不会命中,缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。 缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
方案一:业务领域结合自身场景根据Key的特点做参数校验。
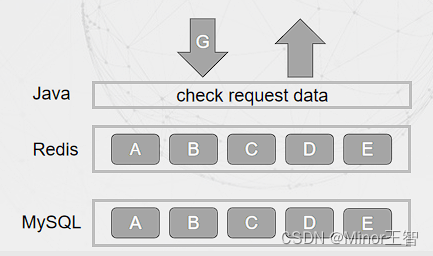
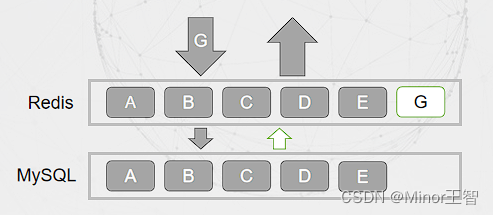
方案二:缓存空对象:当缓存和数据库都未命中,缓存该Key为空对象缓存。为了避免恶意请求造成 大量无用的Key,可以将空对象的Key设置很短的过期时间。
方案三:布隆过滤器:在访问缓存层之前,将存在的Key用布隆过滤器提前保存起来,当请求过来时,检查Key是否在过滤器中存在。

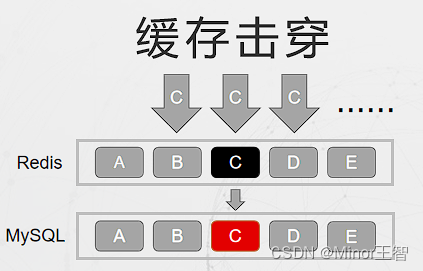
2.2 缓存击穿
缓存击穿:是指一个设置了过期时间的热点Key,大并发集中对这一个点进行访问,当这个 Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,个时候大并发的请求可能会瞬间把后端DB压垮。
方案一:使用互斥锁形式,当获取缓存层的值为空的时候并不是立马去数据库读取,而是立马 对某一资源进行互斥锁定,比如setNX命令。当设置成功后,再进行数据库的读取,然后设置缓存。
方案二:1、Key永不过期。
2、Key对应的value添加过期时间字段,后台守护线程维护该类Key的失效问题。
2.3 缓存雪崩
缓存雪崩:在某段时间内,缓存大面积过期失效,此时正值流量洪峰,缓存层并未起到防御作用,大量并发和请求下沉到数据库层,导致数据库压力剧增;严情况下,导致数据库层级联宕机。
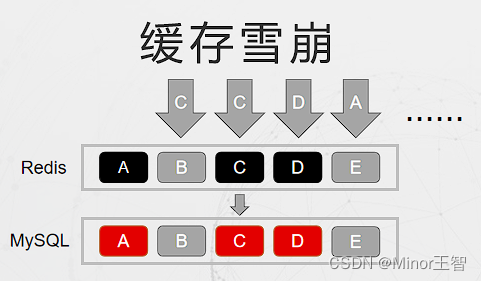
方案一: 服务的高可用保障。
方案二: 熔断/限流降级。
方案三: 相关业务领域的缓存将失效时间分散。
3.Hot Key和Big Key问题
3.1 热Key问题
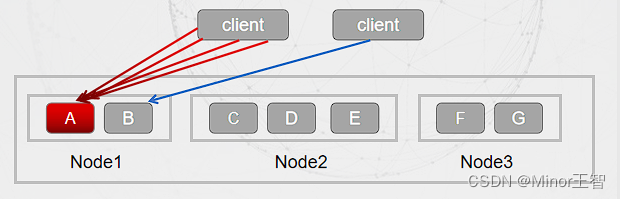
热Key: 在Redis中,访问频率高的Key称之为热Key。产生热Key的问题大致分有: 1、业务规划不合理,消费的数据量远超预期,比如促销、秒杀。 2、突发事件的不可预测,比如明星八卦、主播促销、热点新闻。 3、请求分片过于集中,超过单节点的请求预期。
热Key的危害:
1、流量巨大,容易导致物理网卡流量上限,影响全线业务。
2、如果发生缓存击穿,必将导致持久层雪崩。
3、若缓存集群的分片不合理,导致个别节点负载达到上限,大范围影响业务。
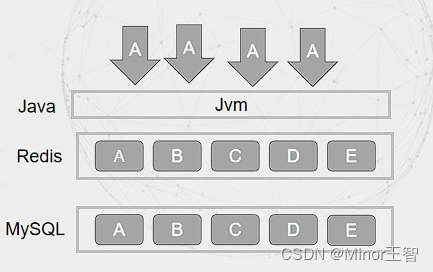
方案一:二级缓存策略,客户端发起缓存层的请求之前,先在自身容器的JVM获取二级缓冲, 如果本地JVM内存中存在缓存,则快速返回,极大降低Redis压力。但是也会带来一致性问题和内存开销问题。
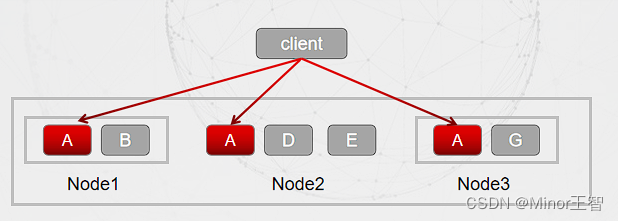
方案二:Key分散,利用合理的分片算法,对Key进行分散缓存。将热点 key 分散为多个子 key,然后存储到缓存集群的不同机器上,这些子 key 对应的 value都和热点 key 是一样的。当通过热点 key 去查询数据时,通过 某种 hash算法随机选择一个子key,然后再去访问缓存机器,将热点分散到了多个子key 上。
方案三:同方案二类似,采用读写分离机制,从节点可横向扩招减轻压力。
3.2 大Key问题
BigKey: 是指key对应的value所占的内存空间比较大。
BigKey带来的问题:
1、集群模式下,内存空间不均匀。
2、网络阻塞,导致先关业务无法正常提供服务。
3、低版本存在删除困难、迁移困难问题
如何优化: 1、结合业务场景,对BigKey进行拆分存储。
2、过期数据定期清理。
3、时刻监控Redis使用率和内存水位。
4、二级缓存。
4.数据倾斜问题
数据倾斜和热key的处理手段类似。
5.脑裂问题
脑裂问题无法100%避免,在哨兵模式下可以配置min-replicas-to-write n 来配置要求至少n个slave同步到了数据才算数据的写入成功。在发生了脑裂后,老master会拒绝新的写请求。

