
- 1训练样本集的制作_样本集制作
- 2存储器容量计算及相关概念_储存计算
- 3CentOS7.6安装docker_centos 7.6.1810安装docker
- 4如何对业务场景做数据分析?_人货场帆软
- 5【GitHub项目推荐--21个最佳开源网络爬虫库,适合Python、Java、Go、JavaScript开发语言】【转载】_gtihub开源库
- 6NLP常见任务的分类指标_机器翻译任务指标
- 7中国人工智能学会通讯——面向知识图谱的自然语言问答系统 2 语义解析式的知识库问答...
- 8开源在线客服系统源码(PHP开发的网页在线客服聊天系统源码)_前端开源客服聊天系统
- 9基于Python实现的仓库库存管理系统|进销存储系统_pyqt 仓库管理
- 10RabbitMQ集群搭建详细介绍以及解决搭建过程中的各种问题 + 配置镜像队列——实操型
低光照图像增强《Deep Retinex Decomposition for Low-Light Enhancement》论文笔记
赞
踩
1 原理
经典Retinex将图像分解为反射率
R
R
R和照明度
I
I
I。
S
S
S表示源图像,则表示为:
S
=
R
∘
I
(1)
S=R\circ I\tag{1}
S=R∘I(1)
- R R R 代表反射率,描述了捕获物体的内在属性,它被认为在任何光照( I I I)条件下都是一致的
- I I I 代表照明度(亮度),代表各种物体上的亮度,在低光照图像上,它通常会受到黑暗和不平衡的照明分布影响
- ∘ \circ ∘ 代表元素间的叠加
本文所提照度、照明、照明度、照度图、照明图可理解为一个意思,即 I I I,都反映物体上的亮度
2 步骤

2.1 分解(Decomposition)
Retinex-Net通过Decom-Net将输入图像 S n o r m a l S_{normal} Snormal和 S l o w S_{low} Slow分别分解为R和I。在训练阶段输入 S n o r m a l S_{normal} Snormal和 S l o w S_{low} Slow, 而在测试阶段只输入 S l o w S_{low} Slow。在低照明度/正常照明度图像具有相同的反射率和照明平滑度的限制下,Decom-Net以一种数据驱动的方式学习到图像在不同照明度下具有一致性的R。
2.2 调整(Adjustment)
Enhance-Net被用来提高 I l o w I_{low} Ilow的照明度,基于编解码框架。一个多尺度的串联被用来保持大区域内照明度与上下文信息的全局一致性,同时集中注意力调整局部分布。此外,在低照明条件下经常产生的放大的噪声将从反射率 R l o w R_{low} Rlow中去除。
2.3 重建(Reconstruction)
在重建阶段将调整后的照明度 I ^ l o w \hat{I}_{low} I^low和反射率 R ^ l o w \hat{R}_{low} R^low按元素相乘法结合起来。
3 步骤详解
3.1 数据驱动的图像分解
在训练阶段,Decom-Net每次接收成对的低照明度/正常照明度图像。在低照明度和正常照明度图像具有相同反射率的指导下,学习低照明度和正常照明度的图像分解。训练时不需要提供真实的反射率和照明度。只需要知道反射率一致性和照明平滑度作为损失函数嵌入网络。因此,网络分解是自动从成对的低照明度/正常照明度图像中学习的,并且在本质上描述适合不同光照条件下的照明变化。
这个问题只是在形式上找到一个良好的代表来进行光线调整,不需要准确的获得实际的内在图像。因此,我们让网络学习在低照明度图像和其相应的增强结果之间找到一致的成分。
Decom-Net首先设置一个3×3的卷积层从输入图像 S l o w S_{low} Slow和 S n o r m a l S_{normal} Snormal中提取特征。然后,使用几个3×3的配有ReLU激活函数的卷积层,将RGB图像映射为反射率 R R R和照明度 I I I。最后,一个3×3的卷积层从特征空间映射出 R R R和 I I I,并用sigmoid激活函数将 R R R和 I I I约束在 [0,1] 内。
损失
L
L
L由重建损失
L
r
e
c
o
n
L_{recon}
Lrecon、不变反射率损失
L
i
r
L_{ir}
Lir和照明平滑度损失
L
i
s
L_{is}
Lis组成:
L
=
L
r
e
c
o
n
+
λ
i
r
L
i
r
+
λ
i
s
L
i
s
(2)
L=L_{recon}+\lambda_{ir}L_{ir}+\lambda_{is}L_{is}\tag{2}
L=Lrecon+λirLir+λisLis(2)
其中
λ
i
r
\lambda_{ir}
λir和
λ
i
s
\lambda_{is}
λis表示平衡反射率一致性的照明平滑度的系数。
基于
R
l
o
w
R_{low}
Rlow和
R
n
o
r
m
a
l
R_{normal}
Rnormal都能用相应的照明图
I
l
o
w
I_{low}
Ilow和
I
n
o
r
m
a
l
I_{normal}
Inormal重建图像的假设,重建损失
L
r
e
c
o
n
L_{recon}
Lrecon表示为:
L
r
e
c
o
n
=
∑
i
=
l
o
w
,
n
o
r
m
a
l
∑
j
=
l
o
w
,
n
o
r
m
a
l
λ
i
j
∥
R
i
∘
I
j
−
S
j
∥
1
(3)
L_{recon}=\sum_{i=low,normal}\sum_{j=low,normal}\lambda_{ij}\left\|R_{i}\circ I_{j}-S_{j}\right\|_{1}\tag{3}
Lrecon=i=low,normal∑j=low,normal∑λij∥Ri∘Ij−Sj∥1(3)
L1范数: ∥ x ∥ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + ∣ x 3 ∣ + . . . + ∣ x n ∣ \left\|x\right\|_1=|x_1|+|x_2|+|x_3|+...+|x_n| ∥x∥1=∣x1∣+∣x2∣+∣x3∣+...+∣xn∣
引入不变反射率损失
L
i
r
L_{ir}
Lir来约束反射率的一致性:
L
i
r
=
∥
R
l
o
w
−
R
n
o
r
m
a
l
∥
1
(4)
L_{ir}=\left\|R_{low}-R_{normal}\right\|_{1}\tag{4}
Lir=∥Rlow−Rnormal∥1(4)
照明平滑度损失
L
i
s
L_{is}
Lis在下一节详细描述。
3.2 结构感知的平滑度损失
照度图一个基本假设是局部一致性和结构感知性。一个好的照度图应该在纹理细节上表现得平滑,同时可以保持整体结构的边界。
全变化最小化(TV),使整个图像的梯度最小化,通常作为各种图像恢复任务的平滑先验。然而,直接使用 TV 在图像具有强结构或亮度急剧变化的区域作为损失函数会失效。这是由于照度图梯度的均匀减小,无论区域是纹理细节还是强边界。换句话说,TV 的损失是无视结构的。

上图显示了反射率梯度加权 TV 损失对照明平滑度的有效性。第一行显示加权 TV 损失的输入图像(a)、反射率(b)和照明(c)。第二行显示一个放大区域,其中(d)是输入图像,(e)和(f)表示加权 TV 损失的
R
R
R和
I
I
I,(g)和(h)是原始 TV 损失的
R
R
R和
I
I
I。可以看出原始 TV 损失得到的照明模糊,并且在反射率上留下强黑色边缘。
为了使损失函数可以感知图像结构,用反射率图的梯度对原始 TV 函数进行加权,最终
L
i
s
L_{is}
Lis为:
L
i
s
=
∑
i
=
l
o
w
,
n
o
r
m
a
l
∥
∇
I
i
∘
exp
(
−
λ
g
∇
R
i
)
∥
(5)
L_{is}=\sum_{i=low,normal}\left\|\nabla I_i\circ\exp(-\lambda_g\nabla R_i)\right\|\tag{5}
Lis=i=low,normal∑∥∇Ii∘exp(−λg∇Ri)∥(5)
无下标的范数指L2范数,即 ∥ x ⃗ ∥ = ∥ x ⃗ ∥ 2 = x ⃗ \left\|\vec{x}\right\|=\left\|\vec{x}\right\|_2=\vec{x} ∥x ∥=∥x ∥2=x 的模长
其中, ∇ \nabla ∇是梯度,包括 ∇ h \nabla_h ∇h(水平)和 ∇ v \nabla_v ∇v(垂直), λ g \lambda_g λg是平衡结构感知强度的系数。在权重 exp ( − λ g ∇ R i ) \exp(-\lambda_g\nabla R_i) exp(−λg∇Ri)的作用下, L i s L_{is} Lis在反射率梯度陡的地方(即图像结构定位的位置和照明度不连续的位置)放宽了平滑度的约束。
虽然LIME也考虑了在加权 TV 约束下保持照明图中的图像结构,但本文认为这两种方法是不同的。对于LIME,全变化约束由一个初始照明图进行加权,这是R、G和B通道中每个像素的最大强度。本文的结构感知平滑度损失是由反射率加权的。在LIME中使用的静态初始估计可能不能像反射率那样描述图像的结构,因为反射率被假定为图像的物理特性。由于Decom-Net是用大规模的数据离线训练的,所以照明和权重(反射率)可以在训练阶段同时更新。
3.3 多尺度的照明调整
照明增强网络采用了一个编解码架构的整体框架。为了分层去调整照明,引入了一个多尺度连接结构。
编解码架构在大区域内获取上下文信息。输入图像依次下采样到一个小尺度,这样网络可以看到大尺度的照明分布。这就给网络带来了自适应调整的能力。利用大尺度的照明信息,上采样块可以重建局部照明分布。通过元素级求加,从一个下采样块引入到其相应的镜像上采样块实现跳连,从而强制网络学习残差。
为了对照明进行分层调整,即在保持全局照明一致性的同时调整不同的局部照明分布,引入了多尺度连接方法。如果有M个逐步向上采样的块,每个块提取一个 C C C 通道特征图,通过最邻近插值调整不同尺度的这些特征,并将它们连接到一个 C × M C×M C×M 通道特征图上。然后,通过1×1的卷积层,将连接的特征简化为C通道。采用3×3卷积层重建照明图 I ^ \hat{I} I^。
一个下采样块由一个步幅为2的卷积层和一个ReLU组成。在上采样块中,使用了一个可调整大小的卷积层。可调整大小的卷积层由一个最邻近插值操作、一个步幅为1的卷积层和一个ReLU组成。
3.4 反射率的去噪
在分解步骤中,对网络施加了几个约束,其中之一是照度图 I l o w I_{low} Ilow的结构感知平滑度,当估计的照度图 I l o w I_{low} Ilow是平滑的,反射率R上的细节被保留下来,包括提升的噪声。鉴于黑暗区域的噪声在分解过程中根据亮度强度被放大,因此需要与照明度相关的去噪方法。具体细节在 第5.4节 体现。
4 数据集
该实验所使用的数据集分为两类:真实摄影对(LOL数据集)和来自原始图像的合成对。第一类抓住了真实案例中的退化特征和属性,第二类在数据增强中起作用,使场景和物体多样化。
4.1 真实场景捕获的数据集
LOw-Light paired dataset:包含500个低光/正常光图像对,大多数低光图像通过改变曝光时间和ISO收集而来。图像包含房屋、校园、俱乐部、街道等。
 上图为LOL数据集中的低/正光图像对的几个例子。在这个数据集中捕获的对象和场景是多种多样的。
上图为LOL数据集中的低/正光图像对的几个例子。在这个数据集中捕获的对象和场景是多种多样的。
4.2 从原始图像中合成图像对
收集了270张来自MEF、NPE、LIME、DICM、VV和Fusion数据集的低光图像,将图像转换为YCbCr通道并计算Y通道的直方图。从RAISE收集了1000张原始图像作为正常光图形并计算Y通道的直方图。
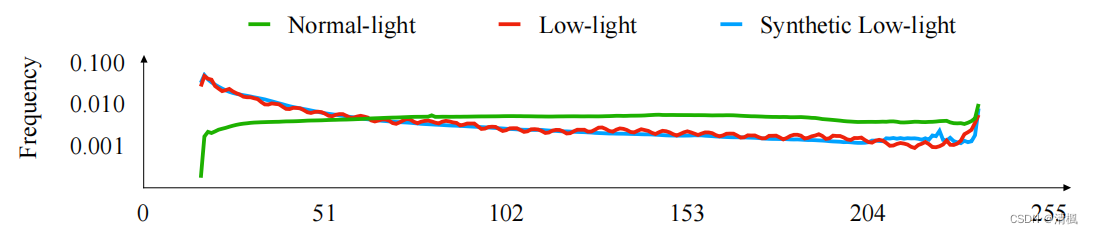
上图为基于YCbCr中Y通道直方图的拟合结果。为清晰起见,以曲线图和纵轴的形式表示的直方图按对数域进行缩放。横轴表示像素值,注意Y通道的范围为16到240。
通过尝试不同参数,使RAISE的1000张原始图像的Y通道直方图符合低光图像,合成图像的照明度分布与低光照图像的照明度分布一致。
5 实验
5.1 实验细节
在第4节提到的LOL数据集,其中485对用于训练,剩余15对用于评估。因此,网络是在485对真实案例和1000对合成图像上训练的。
Decom-Net包括5个带有ReLU的卷积层(位于两个不包含激活函数的卷积层之间),最后通过sigmoid将结果约束在 [0,1] 内。
Enhance-Net由3个下采样块和3个上采样块构成。
首先训练Decom-Net和Enhance-Net,然后使用随机梯度下降法(SGD)对网络进行带反向传播的端到端微调。
batch-size设置为16,patch-size设置为96×96。 λ i r \lambda_{ir} λir、 λ i s \lambda_{is} λis、 λ g \lambda_{g} λg分别设置为0.001、0.1和10。当 i ≠ j i≠j i=j时, λ i j \lambda_{ij} λij设置为0.001,否则设置为1。
5.2 分解结果

上图为在LOL数据集中使用Decom-Net和LIME的分解结果。结果表明,Decom-Net可以从纹理区域和平滑区域的一对图像中提取潜在的一致性反射率
R
R
R。低光图像的反射率与正常光图像的反射率相似,除了在真实场景中出现的黑暗区域的放大噪声。另一方面,照度图描绘了图像上的亮度和阴影。与Decom-Net的结果相比,LIME在反射率
R
R
R上留下了很多照明度信息。
5.3 评价

上图显示了在三幅自然图像上的视觉比较。
如红框所示,Retinex-Net在不过度曝光的情况下照亮暗淡的物体,这得益于基于学习的图像分解方法和多尺度定制照度图。
与LIME相比,Retinex-Net的结果并没有部分过度暴露(见静物中的叶子和房间中的外部叶子)。
与DeHz相比,Retinex-Net的结果中物体没有黑色的边缘,这得益于加权TV损失项(见街道上房屋的边缘)。
5.4 联合低光增强和去噪
考虑到综合性能,采用BM3D作为Retinex-Net的去噪操作。由于噪声在反射率
R
R
R上被不均匀地放大,故使用了一种照明相对策略。我们比较了我们的联合去噪Retinex-Net与两种方法,一种是去噪后处理的LIME,另一种是JED,一种最近的联合弱光增强和去噪方法。

如上图所示,Retinex-Net更好地保留了细节,而LIME和JED则模糊了边缘。
6 总结
本文提出了一种深度Retinex分解方法,该方法可以将数据驱动的观测图像分解为反射率和照明度,而不需要分解的反射率和照明度的真实数据。随后介绍了光照增强和对反射率的去噪操作。对分解网络和低光增强网络进行端到端训练。实验结果表明,该方法具有视觉上良好的增强效果,并很好地表示了图像分解。
7 代码复现
代码Github链接
由于实验代码使用的是TensorFlow1.x版本,而我本机安装的tensorflow2.x版本,故要进行版本替换。下载实验代码并保存于本地(我的保存在C:\Users\74269\PyProject)。 打开Anaconda Prompt,进入实验虚拟环境(我的环境名称为TF2,提前安装好tensorflow和相关库,cpu或gpu版本都可以。没有虚拟环境的可以直接在base环境安装,或者自己查一下conda虚拟环境的设置。后者要把虚拟环境加载到jupyter中,教程很多,这里不再赘述)。
打开Anaconda Prompt,进入实验虚拟环境(我的环境名称为TF2,提前安装好tensorflow和相关库,cpu或gpu版本都可以。没有虚拟环境的可以直接在base环境安装,或者自己查一下conda虚拟环境的设置。后者要把虚拟环境加载到jupyter中,教程很多,这里不再赘述)。
(base) C:\Users\74269>activate TF2
(TF2) C:\Users\74269>
- 1
- 2
进入项目根目录。
(TF2) C:\Users\74269>cd ./PyProject/RetinexNet-master
(TF2) C:\Users\74269\PyProject\RetinexNet-master>
- 1
- 2
- 3
安装了tensorflow后,使用 tf_upgrade_v2 可以将tensorflow文件从版本1.x转换为版本2.x,将代码中的三个py文件全部转换,转换后会生成report.txt文件,用于记录所修改的内容。
(TF2) C:\Users\74269\PyProject\RetinexNet-master>tf_upgrade_v2 --infile main.py --outfile main_v2.py
(TF2) C:\Users\74269\PyProject\RetinexNet-master>tf_upgrade_v2 --infile model.py --outfile model_v2.py
(TF2) C:\Users\74269\PyProject\RetinexNet-master>tf_upgrade_v2 --infile utils.py --outfile utils_v2.py
- 1
- 2
- 3
将文件main.py,model.py,utils.py删除,并将main_v2.py,model_v2.py,utils_v2.py重命名为main.py,model.py,utils.py。
打开jupyter,新建一个notebook(选择安装tensorflow的虚拟环境。创建了虚拟环境,但是没有虚拟环境可选的,需要将虚拟环境加载到jupyter)。
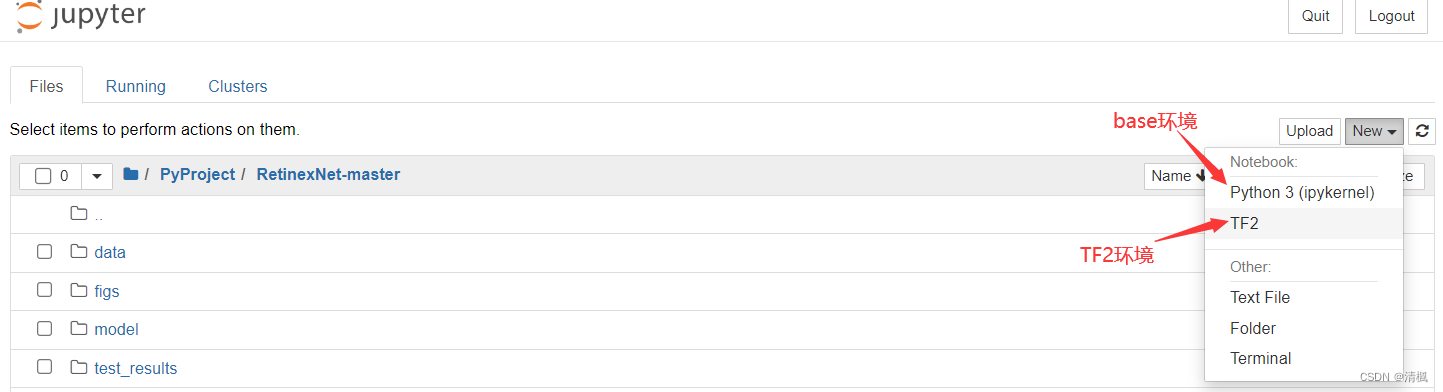
打开后,输入:%run main.py --phase=test,点击运行即可在test_results文件夹查看结果。

如果要测试自己的图片,可以在./data/test/low目录下添加自己的图片,注意尺寸不要过大,跟样例大小差不多即可,否则程序会崩溃,且每次运行代码都要重启核。


