
- 1CSS的属性【all:inherit】有什么奥秘?
- 2Git版本控制管理——分支_git show-branch
- 3php其他反序列化知识学习
- 4gitconfig 配置文件[credential]使用记录
- 5git clone 出现"error: RPC failed; curl 56 GnuTLS recv error (-9): A TLS packet with unexpected length ...
- 6java基于ssm奶茶店进销存系统_奶茶进销存
- 7【MySQL】数据的导入导出及.sql文件执行_导出数据库脚本的命令
- 8【字符集二】多字节字符vs宽字符
- 9[ project.config.json 文件内容错误] project.config.json: libVersion 字段需为
- 10IO多路复用之POLL【内附可运行代码注释完整】_c io复用 poll
阿里开源高性能搜索引擎 Havenask - Ha3_ha3开源
赞
踩
本文会重点介绍一下阿里系的搜索引擎中间件 Havenask(内部代号Ha3),在阿里内部支持了淘宝、天猫、菜鸟、优酷、高德、饿了么等在内的阿里搜索业务。
Ha3 支持千亿级别数据实时检索、百万qps查询,百万TPS高时效性写入保障,毫秒级查询延迟和数据更新。
开源地址:http://github.com/alibaba/havenask
1. 发展历程
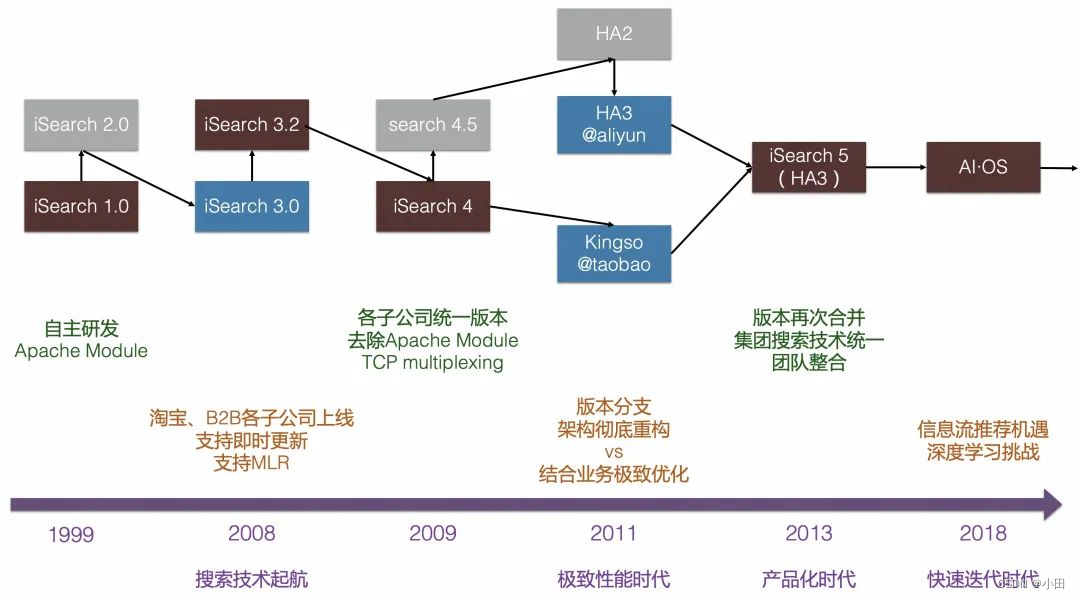
- 1999年~2008年起源于雅虎搜索技术(YST、Vespa)的单机版搜索引擎,支持淘宝、B2B等子公司搜索业务。
- 2009年~2011年完成自研搜索引擎HA3(Havenask)研发,开启自研大规模分布式高性能搜索引擎时代。
- 2013年Havenask支持阿里巴巴集团几乎所有搜索业务,统一代码分支,以产品化方式规模化支持集团大量搜索业务。
- 2018年深度学习技术广泛应用,Havenask继续演进,除了提供传统的倒排索引能力外,还提供KV、KKV、向量索引,支持深度模型和在线预测,提供插件定制、自研CAVA语言支持业务扩展等能力,成为阿里搜推广场景的核心AI智能引擎。
- 2022年阿里将搜索引擎 Havenask 开源,为更多用户提供更高性能、更低成本、更便捷易用的搜索服务。
关键节点
- 早期电商搜索是Apache http server module的形式实现,一个业务一个分支,与业务逻辑深度耦合
- 2009年,支持业务的同时组建一支小队伍,从零开始重写整个搜索系统
- 2011年,新系统完成研发,替代雅虎老的网页搜索并完成上线,开启了自研大规模分布式高性能搜索引擎时代。后来这个组织架构的调整成了今天的UC 神马搜索,2013年UC整合了“一搜”团队以及百度的一支技术团队,同时引入360 等公司专家,进一步加速了移动搜索业务的推进,同年推出移动搜索品牌“神马搜索”
- 2013年,问天引擎开始大规模支持几乎所有业务,统一代码分支、产品化方式支持大量搜索业务,技术团队整合到一起,以极致的性能优化、分布式、高可用、运维友好为目标不断打磨这个搜索产品。
- 2016年,深度学习技术的广泛应用,ha3 逐步集成了各种除传统倒排索引以外的能力,称为阿里搜推广场景的核心AI智能引擎。
2 架构
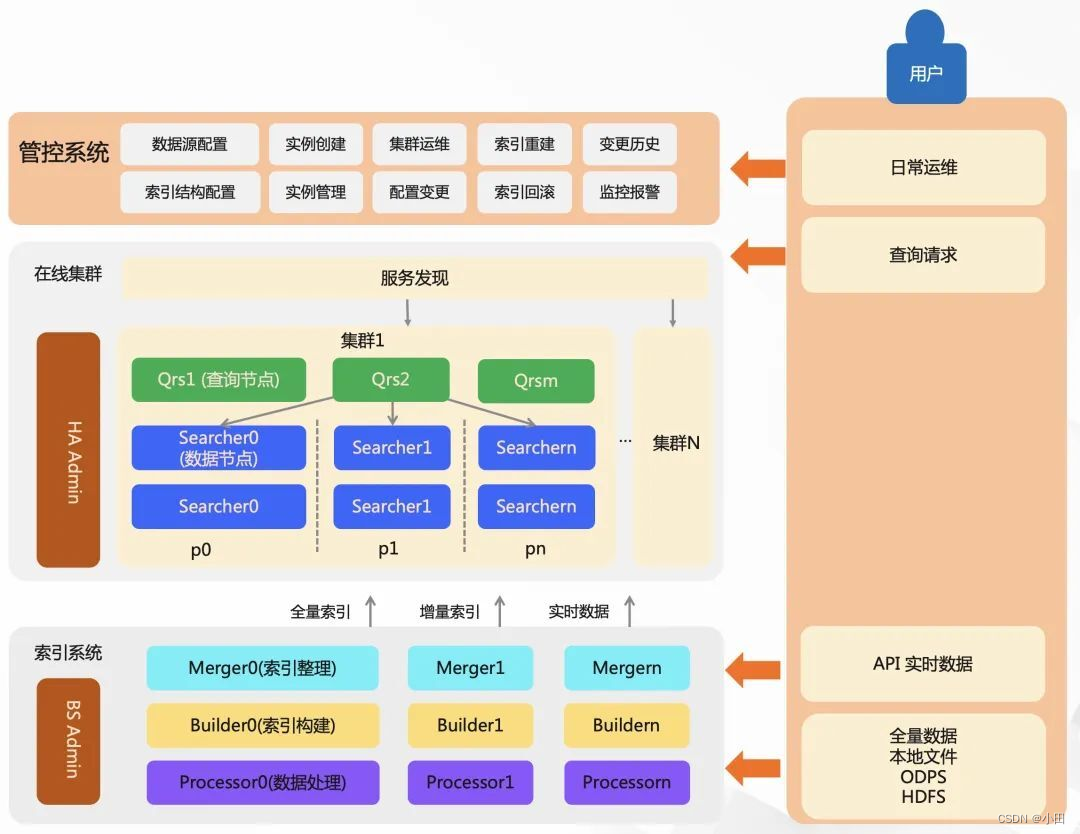
一个较为完整的搜索服务由:在线系统、索引系统、管控系统、扩展插件等部分构成,其中包括了查询流、数据流、控制流。
1)在线系统,包含了 QRS 和 Searcher。Qrs 负责接收用户查询、查询分发、收集整合结果。Searcher 是搜索查询的执行者,负责倒排索引召回、统计、条件过滤、文档打分、排序、摘要生成等。
2)索引系统,负责索引数据生成的过程,还包含有文档处理与索引构建服务 Build Service。索引构建分为三个步骤,对数据进行前置处理(例如分词、向量计算等)、产出索引、合并索引文件的处理。
3)管控系统,负责提供强大的运维能力。
4)扩展插件,提供插件机制,索引和在线流程各环节中,均可以通过开发插件,对原始文档(UDF)、查询 Query、召回、算分(粗排)、排序、摘要进行灵活修改。
2.1 ha3架构
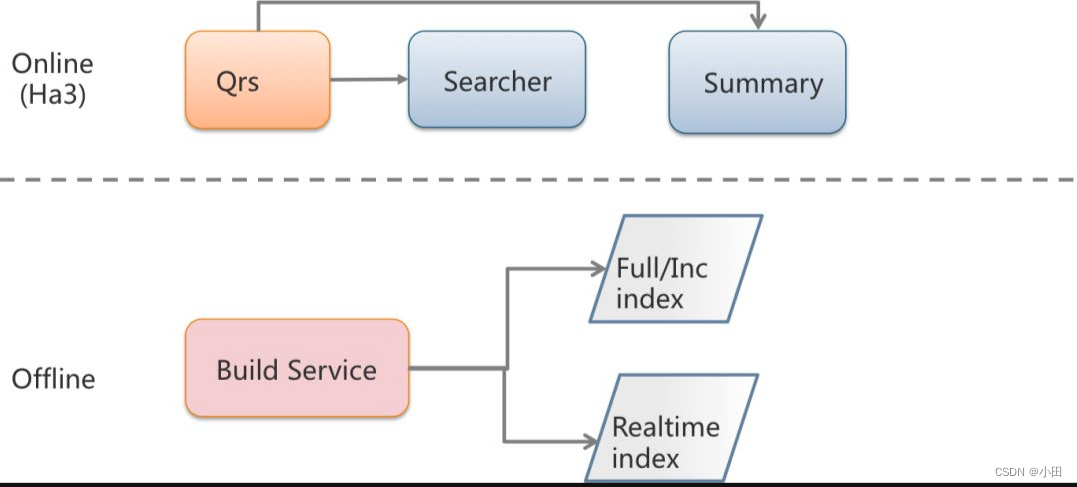
在线
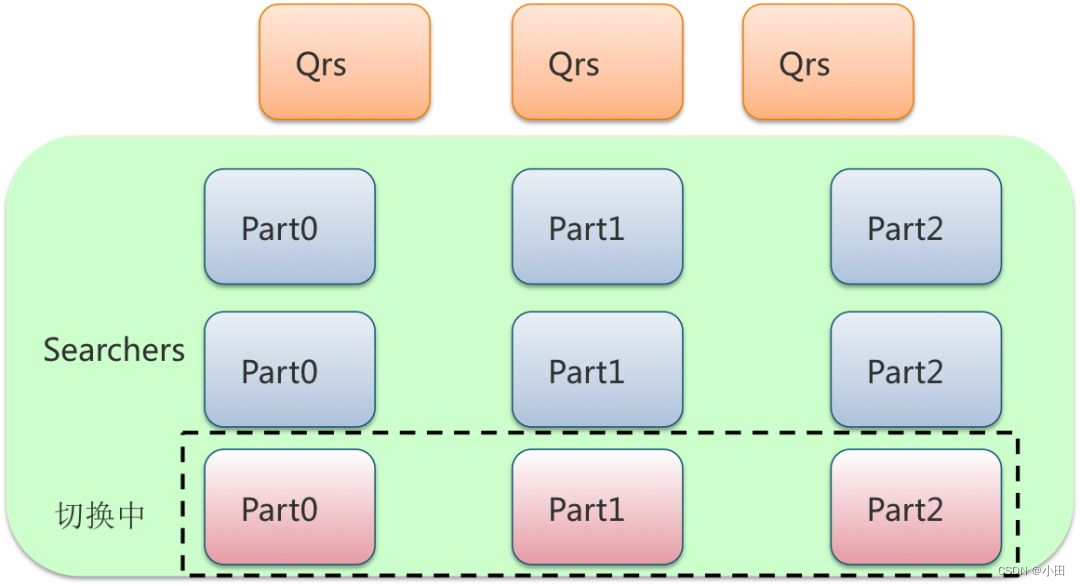
- 系统内部包含了QRS(query result searcher)和 Searcher 两种基本的角色。其中qrs用于接收用户查询,将用户查询分发给Searcher(也就是多个partition的场景),收集Searcher返回的结果作整合,最终返回给用户,这里用户指的是Ha3的调用方如 SP(搜索链路ha3上游服务) 和TPP(推荐链路ha3上游服务)。
- Searcher是搜索执行的执行者,倒排索引的召回、统计、条件过滤、文档打分以及排序及摘要生成的过程都在Searcher上完成。有时候根据业务需要也会把摘要(Summary)独立成一个单独的集群。
- 实际的部署一般采用多机房灾备部署,QRS与Searcher 多行部署,多行主要应对大流量请求和上线过程中的部分行重启(两行保证50%可用)。Searcher可以根据业务需要调整列数,解决单机内存或磁盘放不下数据的问题。
- QRS和Searcher 通过运维系统挂在到发现服务上,内部常用的发现服务通常是cm2 和vipserver。结合gig团队开发的RPC lib, 对QRS和Searcher的访问可以做到自动的流量均衡和坏节点自动检测。
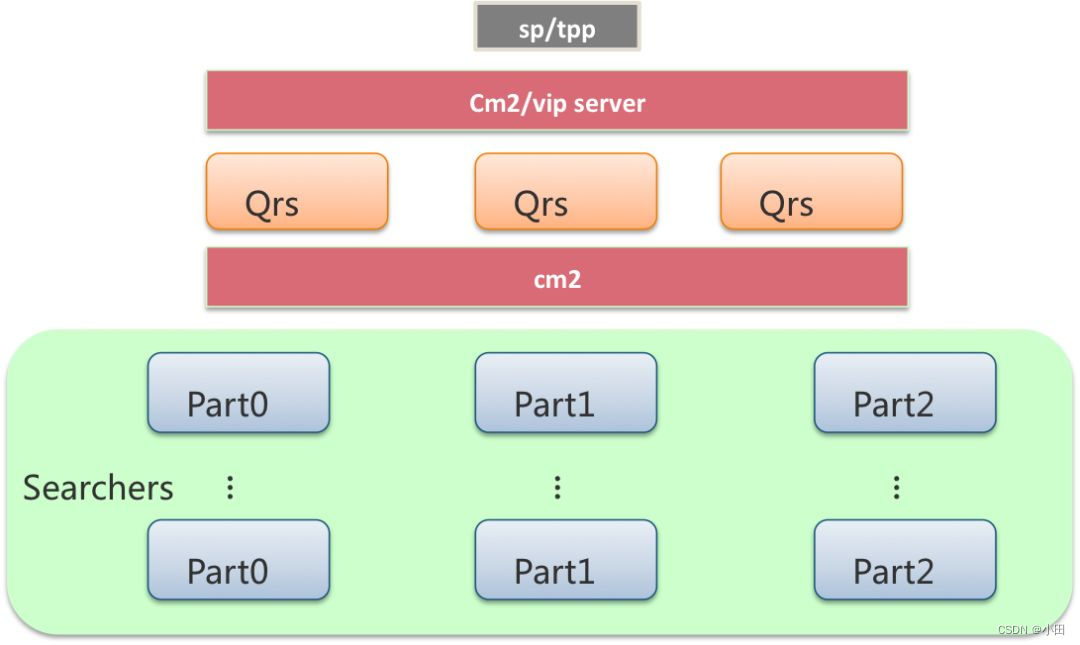
离线
- 所谓的离线是指索引数据的生成过程,一般包括了离线全量数据的生产和实时消息的生产,都是通过Build Service系统生成的。
- Build Service是一个独立的服务,通过运维系统监控数据源是否有新的数据产出,将产出的全量和增量数据放到HDFS或者pangu上,通过DP服务,分发给Ha3的Searcher。其中全量索引的产出周期通常是一天一次,增量索引的产出周期是15分钟(可以配置)。
- 在增量消息和全量消息之外还有实时消息,BS以lib的方式存在于Ha3中,用于处理实时消息,直接将产出实时索引放到Searcher的实时内存里(实时内存可配置)。这样Ha3的查询时效性就可以做到秒级,但是如果实时消息太多会把内存占满,解决办法就是 增量索引与全量索引合并的时候Ha3会清空实时内存与增量索引的交际,从而释放部分实时内存。
2.2 ha3业务分层
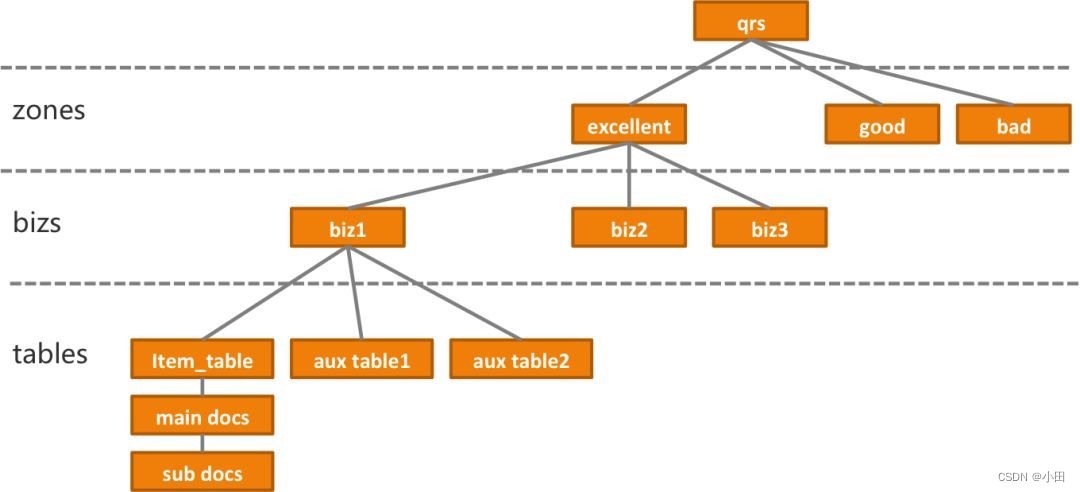
从业务角度出发,Ha3包括了zone、biz、table的概念
- table是数据表,Ha3中一个zone必须包括一个主表(item_table),有时候还会包括辅表,辅表在数量上没有限制。辅表数据是对主表的补充,在线查询的时候Searcher通过配置中指定的字段,将主表和辅表的结果join到一起返回给调用方。
- biz(业务配置) 描述了QRS和Searcher上的统计、算分、排序、摘要等多个环节。集群的多个biz,可以满足ABTest的需要。
- zone 是用于将多个biz与多个table 进行业务上划分存在的概念,与biz和table的关系是一对多。
用户构建查询串的时候,需要输入zone的名称和zone下biz的名称,来指定zone下的业务逻辑,zone是必须要指定的,biz是可以不指定的,这时候会使用默认的业务配置(default)
config=cluster:zone_name&&query=plain:你好&&attribute=id
3 ha3 运行细节
3.1 在线流程
在线流程中,用户访问Ha3的方式是向多行部署的其中一个Qrs发送请求,而Qrs的选择是通过发现服务配合流量均衡策略实现的。一个完整的请求会包含查询关键词,并且会包含描述了统计、过滤、排序的行为参数。Qrs会再次通过发现服务结合流量均衡策略,选择具体的一列或多列Searcher机器,将用户查询分发下去。Searcher上执行索引查找、过滤、统计,这些流程的具体行为与相关参数在查询和配置中均会有涉及。
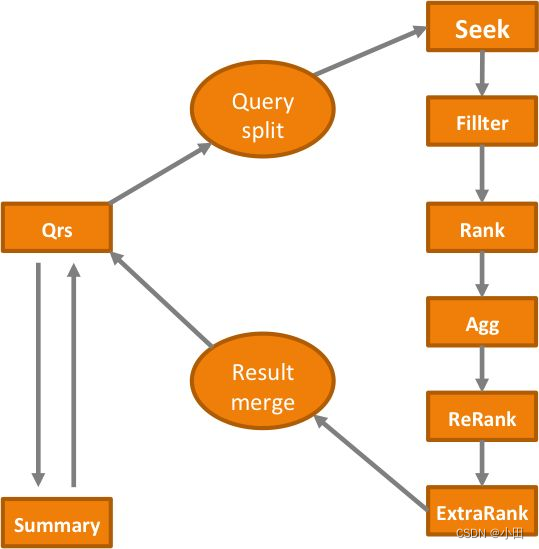
3.1.1 QRS
qrs上的查询逻辑主要分两个阶段 :第一个阶段向一个完整行的多列Searcher发送请求,从多列Searcher中拿到结果后合并排序。第二个阶段是将排序后前N个文档再次拼接查询串继续请求Searcher得到摘要查询结果,拿到摘要之后合并结果返回给用户。一般大多是时候摘要都是单独请求或者不请求。
3.1.2 Searcher
Searcher的在线查询流程较多,主要的步骤如下
- seek: 倒排索引的召回、合并与求交。这里默认是边打分边循环seek,默认128个doc为一组进行循环seek +filter
- filter: 剔除不满足条件的文档
- Rank:粗排算分,这里的算分过程耗时通常较少,但参与计算的文档量巨大,经过这一步后,得分靠前的文档会被保留,其余都会被删除,具体保留多少文档由用户的配置或查询条件决定,通常与参与Rank的文档有数量级上的差距
- Agg: 对结果进行统计,统计内容根据用户查询条件决定
- Rerank: 精排算分,参与算分的文档跟粗排有数量级的差距,计算逻辑较为复杂。
- ExtraRank: 返回给qrs前的最终排序
3.2 离线流程
离线流程的执行者Build Service, 负责将纯文本的商品数据构建成Ha3格式的索引文件。原始的商品数据有两类,一类是存放在HDFS上的全量商品数据,这是定期(一般周期为天)由业务方产出,另一类为实时增量数据,商品信息变更后,业务放即时通知给消息系统Swift。
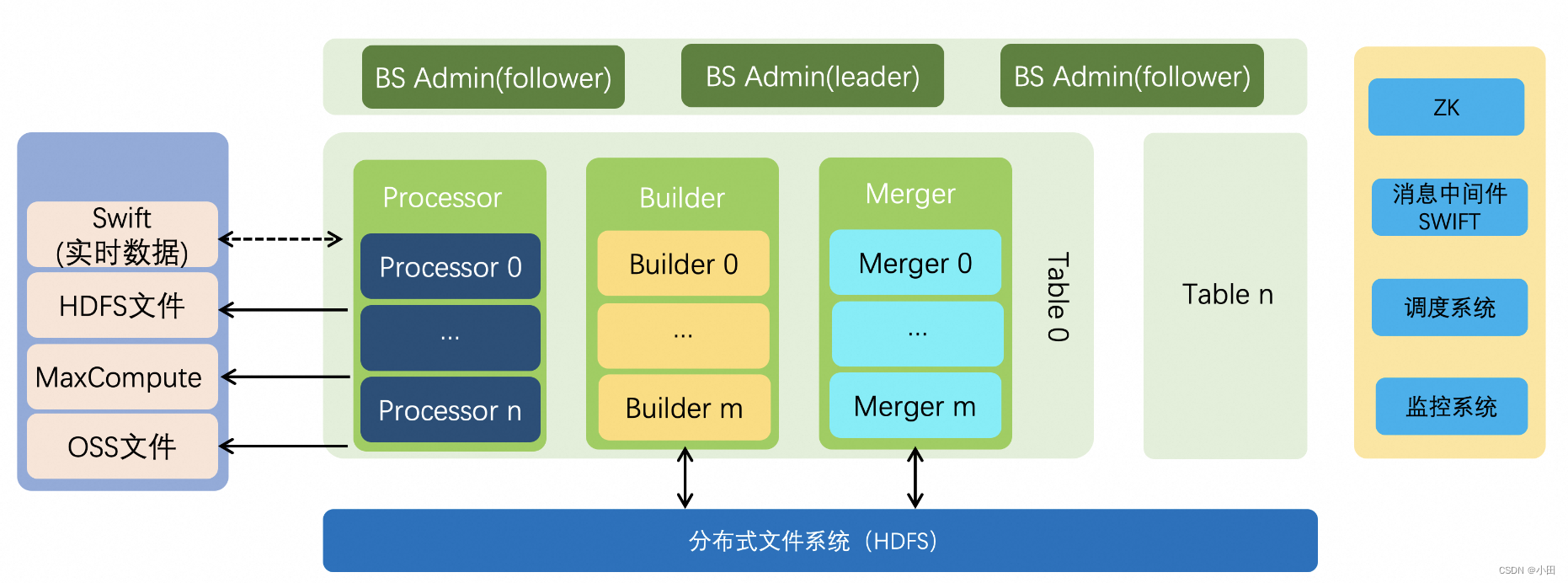
3.2.1 三个重要角色
- Processor: 从数据源拉取数据,支持多种数据源,比如HDFS、OSS等分布式文件系统,同时也支持对接Swift消息中间件处理实时数据。对原始数据做一些分词、数据格式转换等处理,开发者可以通过定制数据源reader插件和数据处理DocumentProcessor插件来扩展支持不同的数据源和数据处理逻辑。
- Builder:负责索引的构建,将经过processor处理的数据按照Schema的配置构建成倒排、正派、摘要索引。Build与Processor的数据交互是通过Swift消息中间件来实现的,即Processor将处理之后的数据写到Swift,Build从Swift中读取这些数据进行索引构建。
- Merger:Merger负责索引的定期整理,定期索引整理使索引文件更加紧凑,可以降低在线集群索引加载的内存开销,提升检索性能。索引整理时会清除已经标记删除的数据(实时这一块),小的索引文件合并成大的索引文件,也可以按照配置文件在整理时根据某个字段进行离线排序,这样可以进一步提升检索性能。
除了以上三种角色之外还有BS Admin,负责整个集群的任务调度和资源管理。提供丰富的接口进行索引的构建和构建任务的启停,资源的调整等,一般Admin会配合调度系统来调度任务的执行并维护任务的状态。
在一个Build Service服务中可以有一个或者多个Admin,通过Zookeeper进行leader选举,只有leader才会管理整个Build Service服务,其他Admin作为fllower。
对于Processor、Builer和Meger节点,它们只有分片(Shard)的概念,没有备份的概念。比如对于Processor,每个分片处理不同的数据,一个分片只会启动一个节点,如果某些原因启动了多个节点,多个节点之间通过ZK进行leader选举,只有leader节点才会存活并工作,非leader节点的进程会自动退出。Builder和Merger的情况与Processor类似,唯一不同的是分片数是在创建表时就确定的,它们只能基于分片数据调节并发度,因此Builder和Meger节点真实启动的个数是分片数乘以并发度。
4 ha3 运维
Ha3的日常运维包括二进制版本更新、配置更新、全量与增量索引更新、扩行扩列、机器调度分配等。这些都是通过简易的web操作(tisplus->suez ops),后端子模块相互配合完成的,避免了全手工操作的琐碎而又容易出错的细节。实现运维环节的子模块包含以下几个:
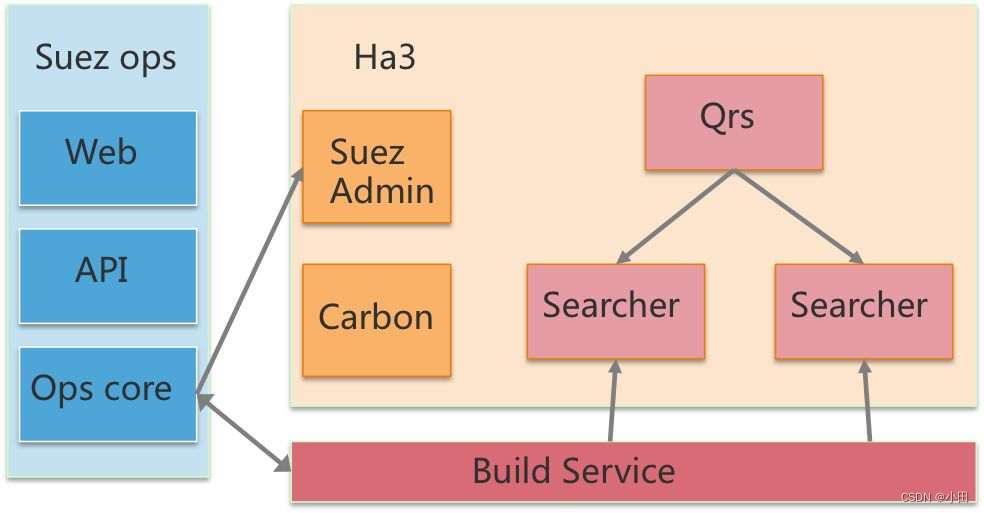
- suez_ops: 线上运维操作的入口,后台将build service、swift、ha3和离线产出做全流程的对接,配置的更新、回滚、扩列扩行、资源调整等均能在suez_ops的web界面上操作,对于在交互和web上有强定制需求的用户,suez_ops也提供了API,以供进一步开发。
- suez admin: 这是一个承上启下的角色。用户通过suez_ops提交自己的运维需求,ha3 admin拿到更新信息之后,将更新目标分解,发送给自己管理的qrs或者searcher,具体变更行为由qrs或者searcher进程自己完成。
- carbon: 是一个内嵌在suez admin中,以lib存在的调度框架,一方面收集下游worker(qrs/searcher)的状态,检测状态(是否挂掉)、是否完成目标状态,令一方面调度具体的worker来执行。
让用户无感知的在线服务更新,是通过灰度(rolling)的方式实现的。在多行部署的前提下,通过用户配置的最小服务比例(minHealthRation)参数,carbon选择合适的行数进行更新。如果当前机器不够,则会申请新的机器以凑够足够的行数,待该组机器都更新成功之后,再选择下一组进行继续升级。至于升级过程中是否停流量,可以在目标中设置是否由carbon停流量,不过在suez中,都是worker自己决定的。对于ha3,除了binary更新、内存不够情况下的forceLoad,都是不停流量升级的。
5 名词解释
- MLR模型 :(mixed logistic regression, 混合逻辑斯特回归) 阿里盖坤提出
- CTR预估:click-through-rate 点击率预估,互联网广告效果的一项重要指标
- Kingso : 一套开源的搜索架构
- KV:输入一个K 或者多个 K 返回一个V或者多个V
- KKV:输入一个pkey和skey 返回单个值,只输入pkey则返回值序列。
- 向量索引:非结构化数据检索,如图片、声音、视频等。开源框架包括Faiss 、milvus、Proxima等
- 深度模型:
- 卷积神经网络(Convolutional Neural Networks, CNN):主要用于图像和视频处理任务,能够提取图像和视频的局部特征和空间关系。
- 循环神经网络(Recurrent Neural Networks, RNN):主要用于处理序列数据,如文本、语音等。它可以学习序列中的上下文信息,能够自动捕捉输入数据中的长期依赖性。
- 长短期记忆网络(Long Short-Term Memory, LSTM):是一种特殊的RNN,能够更好地处理长期依赖性。在自然语言处理领域中应用广泛。
- 生成对抗网络(Generative Adversarial Networks, GAN):由生成器和判别器两部分组成,用于生成能够欺骗判别器的假样本,主要应用于图像、视频、音频等生成任务。
- 自编码器(Autoencoder, AE):一种无监督学习模型,用于数据压缩、去噪和特征提取等任务,能够学习输入数据的低维表示。
- 残差网络(Residual Neural Networks, ResNet):用于解决深度神经网络中的梯度消失问题,能够训练更深的神经网络。
- 注意力机制(Attention Mechanism):能够在输入序列中自动学习重要性权重,用于序列生成、机器翻译、图像描述等任务。
- 其他深度学习模型,如Transformer、BERT、GPT等,它们在自然语言处理领域中应用广泛。
- 在线预测:训练得到的模型根据在线输入给出输出
| 特点 | 机器学习 | 深度学习 |
|---|---|---|
| 模型复杂度 | 较为简单,采用线性模型、决策树、支持向量机 | 非常复杂,采用多层神经网络 |
| 特征工程 | 手工提取特征 | 自动特征提取 |
| 数据量 | 较小数据量 | 几百万 |
| 计算资源 | 较小 | 较强算力GPU/TPU |
| 应用场景 | 文本分类、推荐系统 | 计算机视觉、自然语言处理 |
6. 开源搜索引擎
- Apache Lucene :完全用JAVA编写的高性能、功能齐全的全文检索引擎架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎。推出的目的是为软件开发人员提供一个简单易用的工具包,以方便地在目标系统中实现全文检索的功能,或是在此基础简历起完整的全文检索引擎。
- Apache Solr : 基于Lucence 的全文搜索服务器,流行的企业级搜索引擎,主要功能包括全文检索、命中高亮、分面检索、动态聚类、数据库集成,以及对富文本(word、pdf)的处理。高度可扩展,提供分布式搜索和索引复制,Solr 4 还增加了NoSQL支持。
- Elasticsearch: 基于Lucence的搜索引擎,提供了分布式、多租户的全文搜索引擎平台,支持海量数据的实时检索、聚合分析和可视化展示。
- Sphinx Search C++开发的全文搜索引擎:从头开始设计时就考虑到了性能、相关性(又名搜索质量)和集成的简单性。它是用 C++ 编写的,适用于 Linux(RedHat、Ubuntu 等)、Windows、MacOS、Solaris、FreeBSD 和其他一些系统。Sphinx 让你可以快速轻松地批量索引和搜索存储在 SQL 数据库、NoSQL 存储或文件中的数据,或者即时索引和搜索数据,使用 Sphinx 就像使用数据库服务器一样。各种文本处理功能可以根据你的特定应用程序要求微调 Sphinx,并且许多相关功能确保你也可以调整搜索质量。
- Manticore Search:使用 C++ 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码并保持开源!这一切使 Manticore Search 成为一个现代,快速,轻量级和功能齐全的数据库,具有出色的全文搜索功能

