
- 1Python入门题031:excel表格筛选重复数据_python查找 excel重复字段
- 2element plus中tree组件选中、悬停背景颜色和字体颜色设置_element plus tree 修改鼠标移入颜色
- 3大语言模型(LLMs)综合调研_llms模型
- 4解决安卓:Execution failed for task ‘:processDebugResources‘. / Unknown chunk type ‘200‘. / AAPT2 aapt2-_unknown chunk type '200'.
- 5Python数据分析案例-中国电影网电影数据可视化分析_电影数据分析
- 6JVM调优常用的工具JPS、JMAP、JSTAT、JSTACK和JCMD的使用详解_jmap和jstack区别
- 7uniApp中使用小程序XR-Frame创建3D场景(2)加载模型_wxml中3d模型展示
- 8【map】【滑动窗口】【字典树】C++算法:2781最长合法子字符串的长度
- 92021-02-05_2021.2.5怎么变成2021.02.05
- 10Knn算法的实现_knn算法实现
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧_nl2sql问答页面
赞
踩
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]
NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]
NL2SQL进阶系列(4):ConvAI、DIN-SQL等16个业界开源应用实践详解[Text2SQL]
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
prompt的组成包四个元素:
- Instruction(指令,必须)
- Context(上下文信息,可选)
- Input Data(需要处理的数据,可选)
- Output Indicator(要输出的类型或格式,可选)
一个面向复杂任务的prompt的一般都包含Instruction,Context,Input Data,Output Indicator。
所以面向大语言模型的开发应用过程就是如下公式:
LMM(Instruction + Context + Input Data + Output Indicator) = Output
prompt engineering 就是写好这四块东西Instruction,Context,Input Data,Output Indicator,让模型的输出Output越准越好
1.text2sql prompt
> prompt = """
> 现在你是一个数据分析师,SQL大神,请根据用户提供的表的信息,以及用户的需求,写出效率最高的SQL,
> 表信息如下:
> 表名:students;
> 字段:id,name,age,location
> 用户需求:统计一下姓名年龄大于23,姓名包含andy且在beijing,的的学生个数。
> 并且要求输出的SQL以#开头,以#结尾,样例如下:
> #SELECT * FROM table#
> #SELECT COUNT(*) FROM table#
> 注意不需要分析过程,直接给出SQL语句
> """
> inputttext ="""<human>:
> {}
> <aibot>:
> """.format(prompt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出结果: #SELECT COUNT(*) FROM students WHERE age > 23 AND name LIKE ‘%andy%’ AND location = ‘beijing’#

2.大模型text2sql 微调教程
LLM大模型:https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
训练数据:https://huggingface.co/datasets/Clinton/Text-to-sql-v1
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
- 更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
- 同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
- 更高效的推理:为了支持更广大用户的使用,本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
- 开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
数据格式如下:
"""Below are sql tables schemas paired with instruction that describes a task. Using valid SQLite, write a response that appropriately completes the request for the provided tables. ### Instruction: provide the number of patients whose diagnoses icd9 code is 60000? ### Input: CREATE TABLE procedures (\n subject_id text,\n hadm_id text,\n icd9_code text,\n short_title text,\n long_title text\n)\n\nCREATE TABLE prescriptions (\n subject_id text,\n hadm_id text,\n icustay_id text,\n drug_type text,\n drug text,\n formulary_drug_cd text,\n route text,\n drug_dose text\n)\n\nCREATE TABLE demographic (\n subject_id text,\n hadm_id text,\n name text,\n marital_status text,\n age text,\n dob text,\n gender text,\n language text,\n religion text,\n admission_type text,\n days_stay text,\n insurance text,\n ethnicity text,\n expire_flag text,\n admission_location text,\n discharge_location text,\n diagnosis text,\n dod text,\n dob_year text,\n dod_year text,\n admittime text,\n dischtime text,\n admityear text\n)\n\nCREATE TABLE lab (\n subject_id text,\n hadm_id text,\n itemid text,\n charttime text,\n flag text,\n value_unit text,\n label text,\n fluid text\n)\n\nCREATE TABLE diagnoses (\n subject_id text,\n hadm_id text,\n icd9_code text,\n short_title text,\n long_title text\n) ### Response:SELECT COUNT(DISTINCT demographic.subject_id) FROM demographic INNER JOIN diagnoses ON demographic.hadm_id = diagnoses.hadm_id WHERE diagnoses.icd9_code = "60000" """
- 1
- 2
训练代码:text2sqlBaichuan13B.py
2.1 姜子牙系列模型

- Ziya-LLaMA-13B-v1.1
- Ziya-LLaMA-13B-v1
- Ziya-LLaMA-7B-Reward
- Ziya-LLaMA-13B-Pretrain-v1
姜子牙通用大模型V1是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。目前姜子牙通用大模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。
https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
https://github.com/IDEA-CCNL/Ziya-Coding
https://www.modelscope.cn/models/Fengshenbang/Ziya-LLaMA-13B-v1/summary
继续预训练 Continual pretraining
原始数据包含英文和中文,其中英文数据来自openwebtext、Books、Wikipedia和Code,中文数据来自清洗后的悟道数据集、自建的中文数据集。在对原始数据进行去重、模型打分、数据分桶、规则过滤、敏感主题过滤和数据评估后,最终得到125B tokens的有效数据。
为了解决LLaMA原生分词对中文编解码效率低下的问题,在LLaMA词表的基础上增加了7k+个常见中文字,通过和LLaMA原生的词表去重,最终得到一个39410大小的词表,并通过复用Transformers里LlamaTokenizer来实现了这一效果。
在增量训练过程中,使用了160张40GB的A100,采用2.6M tokens的训练集样本数量和FP 16的混合精度,吞吐量达到118 TFLOP per GPU per second。因此能够在8天的时间里在原生的LLaMA-13B模型基础上,增量训练110B tokens的数据。
- 多任务有监督微调 Supervised finetuning
在多任务有监督微调阶段,采用了课程学习(curiculum learning)和增量训练(continual learning)的策略,用大模型辅助划分已有的数据难度,然后通过“Easy To Hard”的方式,分多个阶段进行SFT训练。SFT训练数据包含多个高质量的数据集,均经过人工筛选和校验:
- Self-Instruct构造的数据(约2M):BELLE、Alpaca、Alpaca-GPT4等多个数据集
- 内部收集Code数据(300K):包含leetcode、多种Code任务形式
- 内部收集推理/逻辑相关数据(500K):推理、申论、数学应用题、数值计算等
- 中英平行语料(2M):中英互译语料、COT类型翻译语料、古文翻译语料等
- 多轮对话语料(500K):Self-Instruct生成、任务型多轮对话、Role-Playing型多轮对话等
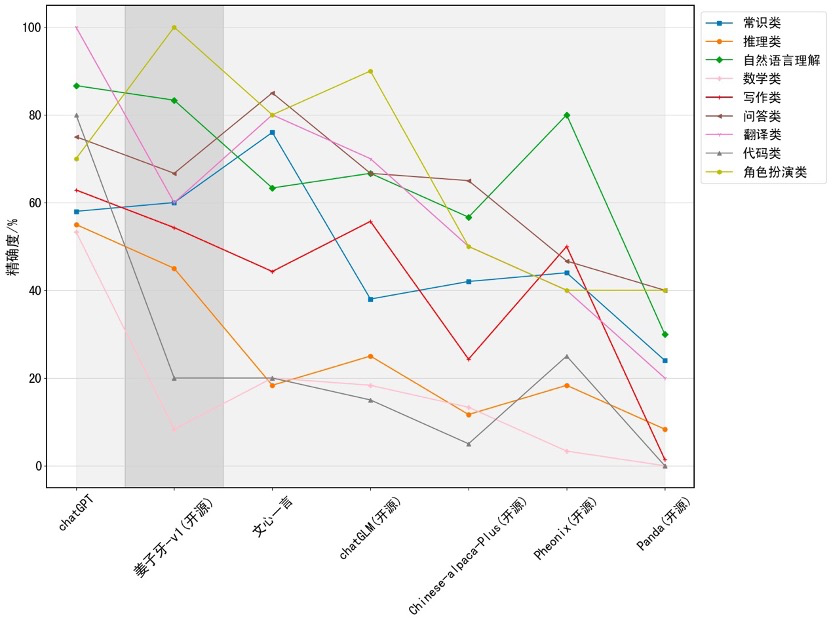
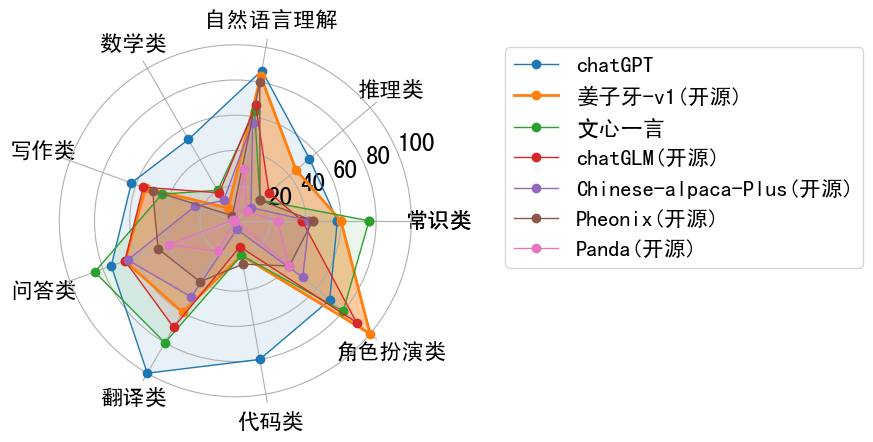
Ziya2-13B-Chat采用"<human>:"和"<bot>:"作为用户和模型的角色识别Prompt,使用"\n"分隔不同角色对话内容。 在推理时,需要将"<human>:"和"<bot>:"作为前缀分别拼接至用户问题和模型回复的前面,并使用"\n"串连各对话内容。
Ziya2-13B-Chat adopts "<human>:" and "<bot>:" as the role recognition prompts for users and models, and uses "\n" to separate the contents of different roles. When doing inference, "<human>:" and "<bot>:" need to be concatenated as prefixes in front of the user's question and the model's reply respectively, and "\n" is used to join the contents of each role.
- 1
- 2
- 3
以下为具体使用方法:
Following are the details of how to use it:
from modelscope import AutoTokenizer, AutoModelForCausalLM, snapshot_download import torch device = torch.device("cuda") messages = [{"role": "user", "content": "手机如果贴膜贴了一张防指纹的钢化膜,那屏幕指纹解锁还有效吗?"}] user_prefix = "<human>:" assistant_prefix = "<bot>:" separator = "\n" prompt = [] for item in messages: prefix = user_prefix if item["role"] == "user" else assistant_prefix prompt.append(f"{prefix}{item['content']}") prompt.append(assistant_prefix) prompt = separator.join(prompt) model_dir = snapshot_download('Fengshenbang/Ziya2-13B-Chat', revision='master') model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype=torch.bfloat16).to(device) tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=False) input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device) generate_ids = model.generate( input_ids, max_new_tokens=512, do_sample = True, top_p = 0.9, temperature = 0.85, repetition_penalty=1.05, eos_token_id=tokenizer.encode("</s>"), ) output = tokenizer.batch_decode(generate_ids)[0] print(output)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
模型部署
import gradio as gr import os import gc import torch from transformers import AutoTokenizer #指定环境的GPU,我的环境是2张A100(40GB)显卡,于是我设置了两张卡,也可以一张80GB的A100 os.environ['CUDA_VISIBLE_DEVICES'] = "0,1" #这个utils文件直接下载官方给的文件即可 from utils import SteamGenerationMixin class MindBot(object): def __init__(self): #这个model_path为你本地的模型路径 model_path = './ziya_v1.1' self.model = SteamGenerationMixin.from_pretrained(model_path, device_map='auto').half() self.model.eval() self.tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False) def build_prompt(self, instruction, history, human='<human>', bot='<bot>'): pmt = '' if len(history) > 0: for line in history: pmt += f'{human}: {line[0].strip()}\n{bot}: {line[1]}\n' pmt += f'{human}: {instruction.strip()}\n{bot}: \n' return pmt def interaction( self, instruction, history, max_new_tokens, temperature, top_p, max_memory=1024 ): prompt = self.build_prompt(instruction, history) input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids if input_ids.shape[1] > max_memory: input_ids = input_ids[:, -max_memory:] prompt_len = input_ids.shape[1] # stream generation method try: tmp = history.copy() output = '' with torch.no_grad(): for generation_output in self.model.stream_generate( input_ids.cuda(), max_new_tokens=max_new_tokens, do_sample=True, top_p=top_p, temperature=temperature, repetition_penalty=1., eos_token_id=2, bos_token_id=1, pad_token_id=0 ): s = generation_output[0][prompt_len:] output = self.tokenizer.decode(s, skip_special_tokens=True) # output = output.replace('\n', '<br>') output = output.replace('\n', '\n\n') tmp.append((instruction, output)) yield '', tmp tmp.pop() # gc.collect() # torch.cuda.empty_cache() history.append((instruction, output)) print('input -----> \n', prompt) print('output -------> \n', output) print('history: ======> \n', history) except torch.cuda.OutOfMemoryError: gc.collect() torch.cuda.empty_cache() self.model.empty_cache() history.append((instruction, "【显存不足,请清理历史信息后再重试】")) return "", history def chat(self): with gr.Blocks(title='IDEA MindBot', css=".bgcolor {color: white !important; background: #FFA500 !important;}") as demo: with gr.Row(): gr.Column(scale=0.25) with gr.Column(scale=0.5): gr.Markdown("<center><h1>IDEA Ziya</h1></center>") gr.Markdown("<center>姜子牙通用大模型V1.1是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。目前姜子牙通用大模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。</center>") gr.Column(scale=0.25) with gr.Row(): gr.Column(scale=0.25) with gr.Column(scale=0.5): chatbot = gr.Chatbot(label='Ziya').style(height=500) msg = gr.Textbox(label="Input") # gr.Column(scale=0.25) with gr.Column(scale=0.25): max_new_tokens = gr.Slider(0, 2048, value=1024, step=1.0, label="Max_new_tokens", interactive=True) top_p = gr.Slider(0, 1, value=0.85, step=0.01, label="Top P", interactive=True) temperature = gr.Slider(0, 1, value=0.8, step=0.01, label="Temperature", interactive=True) with gr.Row(): gr.Column(scale=0.25) with gr.Column(scale=0.25): clear = gr.Button("Clear") with gr.Column(scale=0.25): submit = gr.Button("Submit") gr.Column(scale=0.25) msg.submit(self.interaction, [msg, chatbot,max_new_tokens,top_p,temperature], [msg, chatbot]) clear.click(lambda: None, None, chatbot, queue=False) submit.click(self.interaction, [msg, chatbot,max_new_tokens,top_p,temperature], [msg, chatbot]) return demo.queue(concurrency_count=10).launch(share=False,server_name="127.0.0.1", server_port=7886) if __name__ == '__main__': mind_bot = MindBot() mind_bot.chat()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
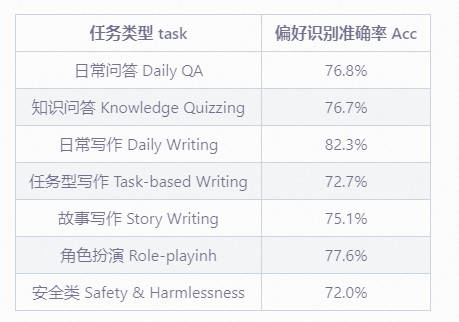
- 人类反馈学习 Reinforcement learning from Human Feedback
基于SFT阶段的模型,Ziya2-13B-Chat针对多种问答、写作以及模型安全性的任务上进行了人类偏好的对齐。自行采集了数万条高质量人类偏好数据,使用Ziya2-13B-Base训练了人类偏好反馈模型,在各任务的偏好数据上达到了72%以上的准确率。
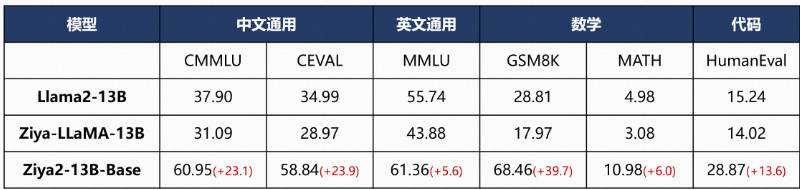
- 效果评估 Performance
Ziya2-13B-Base在Llama2-13B的基础上进行了约650B自建高质量中英文数据集的继续训练,在中文、英文、数学、代码等下游理解任务上相对于Llama2-13B取得了明显的提升,相对Ziya-LLaMA-13B也有明显的提升。
3.Prompt升级
参考文章:https://zhuanlan.zhihu.com/p/635799364?utm_id=0
- 第一版
尽管模型的输出SQL语句本身都是正确的,却存在着一个明显的问题:它会产生多余的输出。具体来说,模型似乎过度地“幻想”了SQL查询的结果,将一些并不属于实际查询结果的数据也一并输出,这导致了信息冗余和不必要的复杂性。

- 第二版
经过版本升级后,引入了角色扮演的功能,告知模型它现在是一名数据分析师,且精通SQL。然而,尽管模型的输出SQL语句本身是正确的,但结果呈现的方式却不够结构化,这导致它并不适合后续的操作和分析。期望模型仅输出一段单独的、结构清晰的SQL语句,而不是包含多余或复杂化的输出。作为数据分析师,更注重结果的准确性和实用性,因此希望模型能够在这方面进行改进。

- 第三版
经过进一步的版本升级,增强了模型的输出引导功能,希望它输出的SQL语句能够以“#”开头,并以“#”结尾。然而,发现尽管模型的SQL语句本身是正确的,但其输出结果却存在错误:结尾部分缺少了一个“#”。这导致了输出格式的不一致和潜在的识别问题。期待模型在输出SQL时能够严格遵守规定的格式,确保每个SQL语句都以“#”完整包围,以满足后续处理和分析的需求。
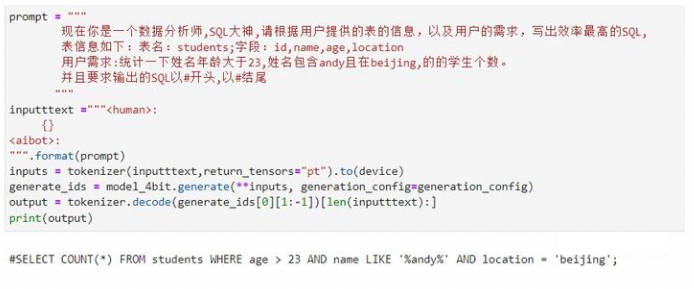
- 最终版
经过又一次的版本升级,不仅在输出引导方面进行了增强,还提供了具体的示例,以帮助模型更好地理解的期望。这次,欣喜地发现,模型的输出SQL语句完全符合的需求。通过明确的输出引导和示例,模型能够准确地生成结构清晰、格式规范的SQL语句,为后续的数据处理和分析提供了极大的便利。这一改进不仅提升了模型的性能,也进一步提高了的工作效率和准确性。

至此,已深入掌握面向大模型开发的核心技术,学会如何有效利用大模型的强大能力,以应对各类复杂任务。整个过程可细化为以下关键步骤:
-
首先,需精心构建高质量的prompt。其中,指令(Instruction)的设定至关重要,需精确、明确地传达的任务需求;上下文信息(Context)作为可选内容,有助于模型更全面地理解问题背景;输入数据(Input Data)是模型处理的具体对象,应根据任务特点灵活选择;输出指引(Output Indicator)则用于规定输出结果的类型、格式及精度,确保模型输出符合专业标准。
-
随后,需要不断迭代与优化prompt。这是一个精细的调试过程,通过对比分析模型的实际输出与预期结果,可以发现prompt中的不足之处,进而针对性地调整其表述和细节。通过多次迭代,可以逐步完善prompt,使模型输出更加精确、全面。
-
最后,验证prompt的稳定性和准确性是不可或缺的环节。通过大量的测试与验证,可以评估模型在不同情境下的表现,确保其输出的稳定性和可靠性。此外,还需要关注模型的泛化能力,确保其能够应对各种未知或复杂情况。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

