
- 1ollama+open-webui,本地部署自己的大模型
- 2BAT面试官告诉你如何回答你的职业规划_后台工程师职业规划 面试
- 3【计算机毕业设计】校园综合服务小程序_校园综合服务小程序毕设
- 4QT With OpenGL(Texture篇)
- 5微服务 Spring Cloud 6,用了这么多年Docker容器,殊不知你还有这么多弯弯绕_docker 微服务
- 6【FPGA】一、FPGA简介
- 7如何在ChatGPT的API中支持多轮对话_chatgpt api连续对话
- 8信息收集——DNS域名系统_dns记录 和whois信息
- 9Vue中使用图片编辑器 tui-image-editor 实现在线编辑保存
- 10大语言模型技术原理_大语言模型大数据检索技术
实验二 HDFS的Shell命令操作,和HDFS的API操作_本关任务:hdfs命令实战
赞
踩
文章目录
- 实验目的
- 一、 实验原理
- 二、实验准备
- 实验内容
- 步骤
- 项目1 HDFS常见命令练习
- 列出HDFS当前用户家目录下的文件及文件夹:
- 列出HDFS文件下名为directory的文件夹中的文件:
- 上传文件,将本地目录file1文件上传到HDFS上并重命名为file2:
- 下载文件,将HDFS中的file2文件复制到本地系统并命名为file1:
- 查看文件,查看HDFS下file1文件中的内容:
- 删除文档,删除HDFS下名为file1的文件:
- 在HDFS根路径下建立新目录,名为directory:
- 本地文件复制到HDFS(注意与put的区别):
- 本地文件移动到HDFS
- 文件或文件夹复制:
- 文件或文件夹的移动:
- copyToLocal 复制文件到本地:
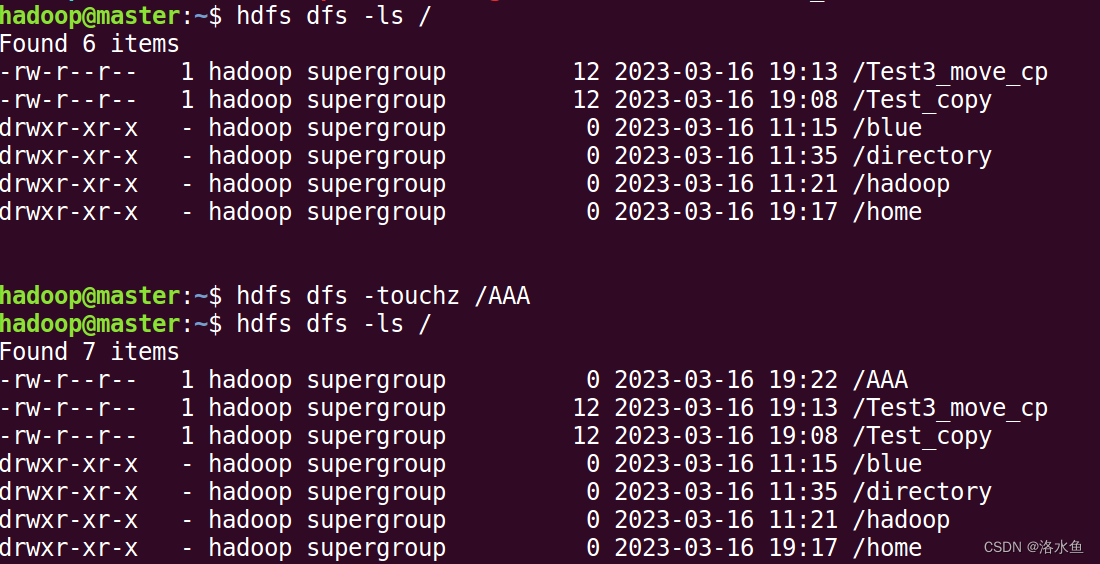
- touchz 创建一个空文件file:
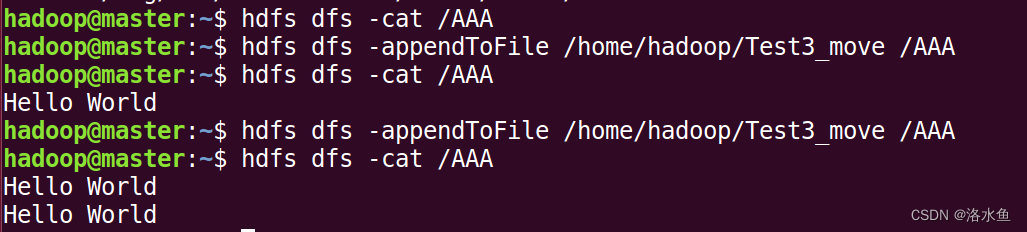
- 追加到文件末尾的指令:
- 项目2 HDFS命令的综合运用实践
- (1)创建一个文件file1,查看file1是否创建成功,往file1内写一些内容。
- (2)在HDFS上创建一个文件夹folder1,把file1上传到folder1中。
- (3)查看是否上传成功,成功后查看file1的内容。
- (4)把file1下载到本地,查看file1的内容。
- (5)把folder1删除,并查看是否删除成功。
- (6)最后把本地的file1删除
- 【拓展与思考】
- 思考题1(必做):对项目1、项目2命令行操作的结果,是否能在Web访问模式下看到?如果能请截图举例说明;如果不能,请查清原因并确认结果。
- 思考题2(必做):hdfs dfs -ls -R 某个HDFS上的目录 该命令中“R”参数的作用是什么?请截图并给出相应的说明。
- 思考题3(必做):如果已经上传了某个本地A文件到HDFS上,并在HDFS中命名为file1, 那再次上传A文件并在HDFS中命名为file1是否可行(路径一致)?如果换另一个本地文件B上传到HDFS中也命名为file1是否可行(路径一致)?
- 思考题4(必做):如果操作对象是文件夹,如何使用命令完成和文件类似的操作?
- 思考题5(选做,可加分保命): hdfs dfs -copyFromLocal 与 hdfs dfs -put 有什么区别?
- 思考题6(选做,可加分保命): linux中每一个命令其实都是对应程序的执行结果,那HDFS命令对应的程序具体在哪些文件中定义呢?
- 项目3 HDFS的API使用实践
- 项目4 HDFS的API单元测试程序和更多思考(选做)--还没写
来自博主卷毛迷你猪的授权,這是我的老師的博客多多關注
实验目的
掌握 Hadoop 中 HDFS 的 Shell 命令操作
掌握 Hadoop 中 HDFS 的API操作
项目1:HDFS常见命令练习
项目2:HDFS命令的综合运用实践
项目3:HDFS的API使用实践
项目4:HDFS的API单元测试程序和更多思考(选做)
一、 实验原理
HDFS是hadoop平台的核心组成之一。
HDFS的访问方式有多种,可通过web访问,也可通过shell方式或者API方式访问。
基本操作有:对文件的读、写、追加、删除;新建文件夹、删除文件夹等;还可显示文件及文件夹的属性。
二、实验准备
实验一中已经完成配置的伪分布式hadoop环境。
项目1、项目2,可以直接使用上述环境
项目3有可能需要配置自己的虚拟机网络连接模式
实验内容
【实验项目】项目1、项目2、项目3必做;项目4选做
项目1:HDFS常见命令练习
项目2:HDFS命令的综合运用实践
项目3:HDFS的API使用实践
项目4:HDFS的API单元测试程序和更多思考(选做)
步骤
项目1 HDFS常见命令练习
我们先熟悉一下HDFS的Shell命令,(以下实验使用hdfs dfs类命令,可以在终端输入hdfs dfs -help command查询命令用法),执行并查看结果。
列出HDFS当前用户家目录下的文件及文件夹:
(1)列出HDFS当前用户家目录下的文件及文件夹:(刚开始是没有文件夹的需要自己新建)
hdfs dfs -ls (hdfs dfs -ls [path])

列出HDFS文件下名为directory的文件夹中的文件:
(2)列出HDFS文件下名为directory的文件夹中的文件:
hdfs dfs -ls directory

上传文件,将本地目录file1文件上传到HDFS上并重命名为file2:
(3)上传文件,将本地目录file1文件上传到HDFS上并重命名为file2:
hdfs dfs -put file1 file2
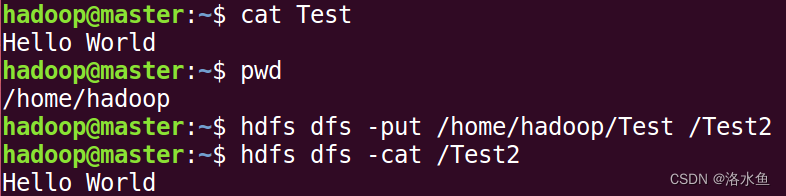
下载文件,将HDFS中的file2文件复制到本地系统并命名为file1:
(4)下载文件,将HDFS中的file2文件复制到本地系统并命名为file1:
hdfs dfs -get file2 file1

查看文件,查看HDFS下file1文件中的内容:
(5)查看文件,查看HDFS下file1文件中的内容:
hdfs dfs -cat file1

删除文档,删除HDFS下名为file1的文件:
(6)删除文档,删除HDFS下名为file1的文件:
hdfs dfs -rm file1
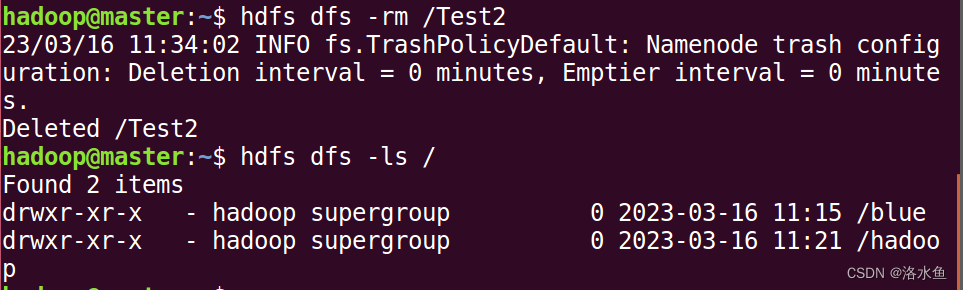
在HDFS根路径下建立新目录,名为directory:
(7)在HDFS根路径下建立新目录,名为directory:
hdfs dfs -mkdir /directory
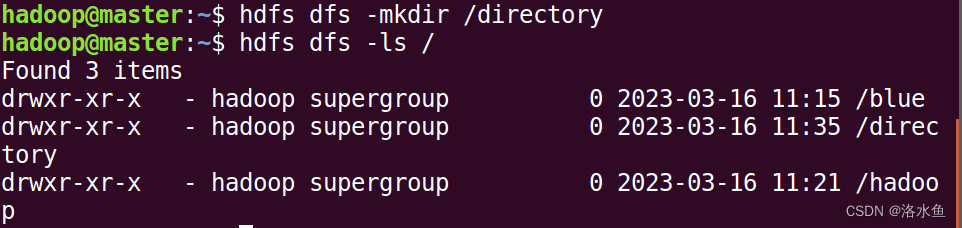
本地文件复制到HDFS(注意与put的区别):
(8)本地文件复制到HDFS(注意与put的区别):
hdfs dfs -copyFromLocal LocalPath ToPath
简单的说,-put更宽松,可以把本地或者HDFS上的文件拷贝到HDFS中;而-copyFromLocal则更严格限制只能拷贝本地文件到HDFS中。
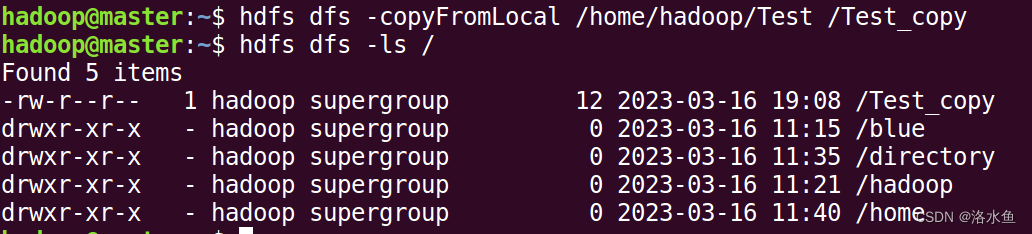
本地文件移动到HDFS
(9)本地文件移动到HDFS:
hdfs dfs -moveFromLocal LocalPath ToPath
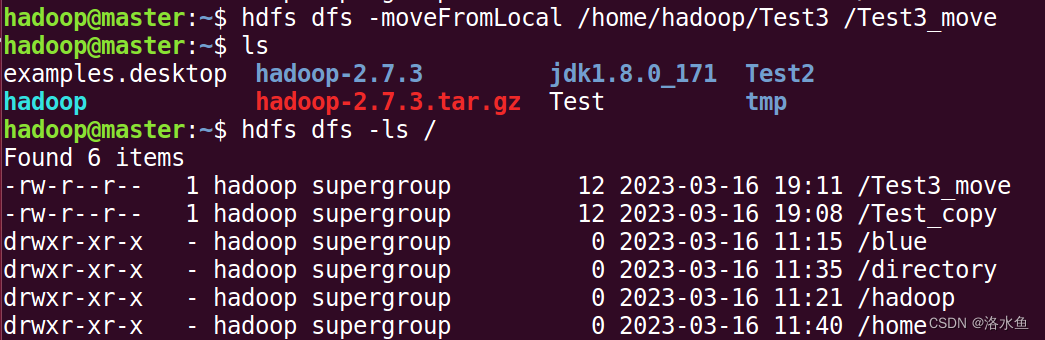
文件或文件夹复制:
(10)文件或文件夹复制:
hdfs dfs -cp src dsth
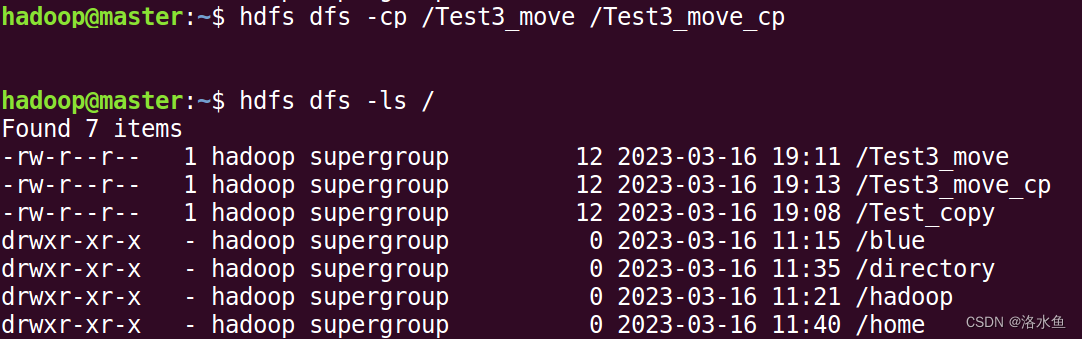
文件或文件夹的移动:
(11)文件或文件夹的移动:
hdfs dfs -mv src dst

copyToLocal 复制文件到本地:
(12)copyToLocal 复制文件到本地:
hdfs dfs -copyToLocal src dst

touchz 创建一个空文件file:
(13) touchz 创建一个空文件file:
hdfs dfs -touchz file
追加到文件末尾的指令:
14)追加到文件末尾的指令:
hdfs dfs -appendToFile local.txt text.txt
项目2 HDFS命令的综合运用实践
【注】文件名字可以自己取,重点是命令执行是否成功
(1)创建一个文件file1,查看file1是否创建成功,往file1内写一些内容。
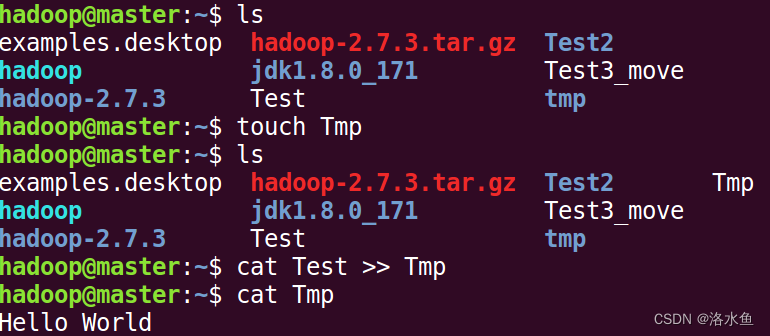
(2)在HDFS上创建一个文件夹folder1,把file1上传到folder1中。

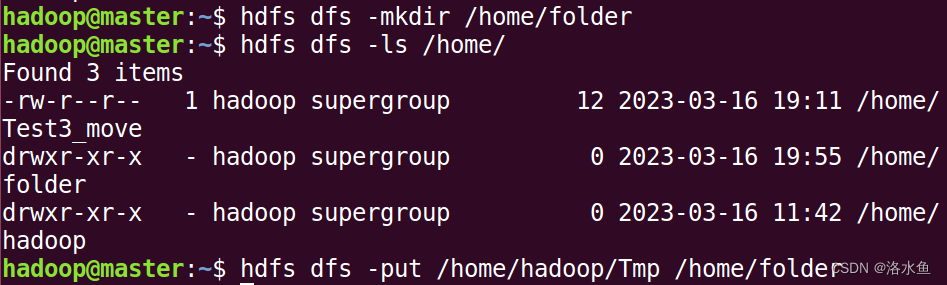
(3)查看是否上传成功,成功后查看file1的内容。
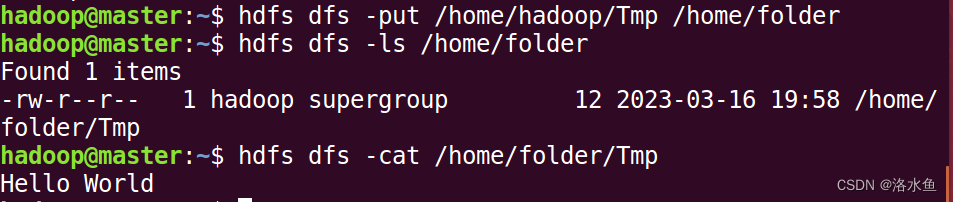
(4)把file1下载到本地,查看file1的内容。

(5)把folder1删除,并查看是否删除成功。


(6)最后把本地的file1删除
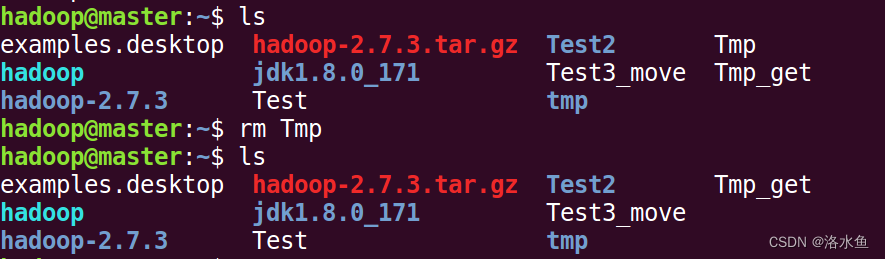
【拓展与思考】
【拓展与思考】思考题1、思考题2、思考题3必做,其余选做
思考题1(必做):对项目1、项目2命令行操作的结果,是否能在Web访问模式下看到?如果能请截图举例说明;如果不能,请查清原因并确认结果。
1.先进入50070,在Utilities下的Browse the file system下可以先看见我们之前创建的目录信息
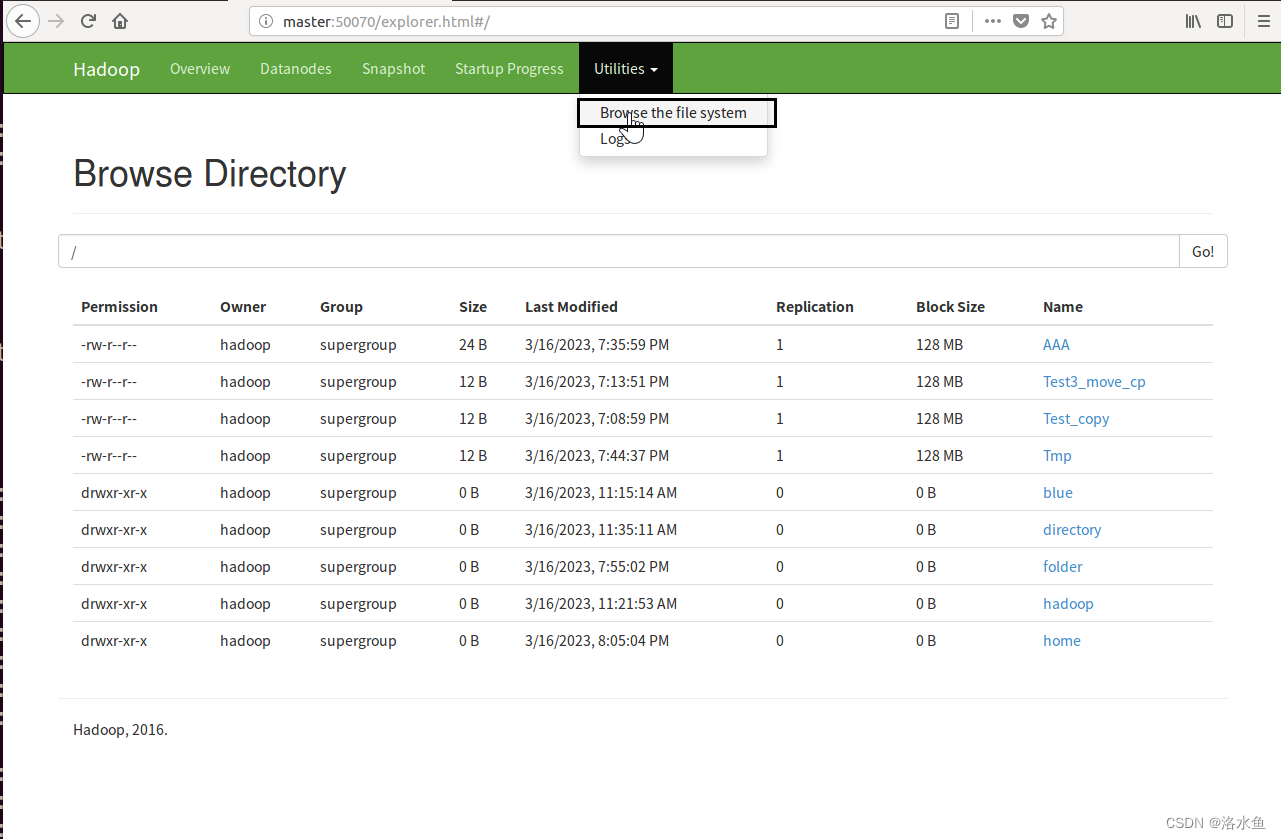
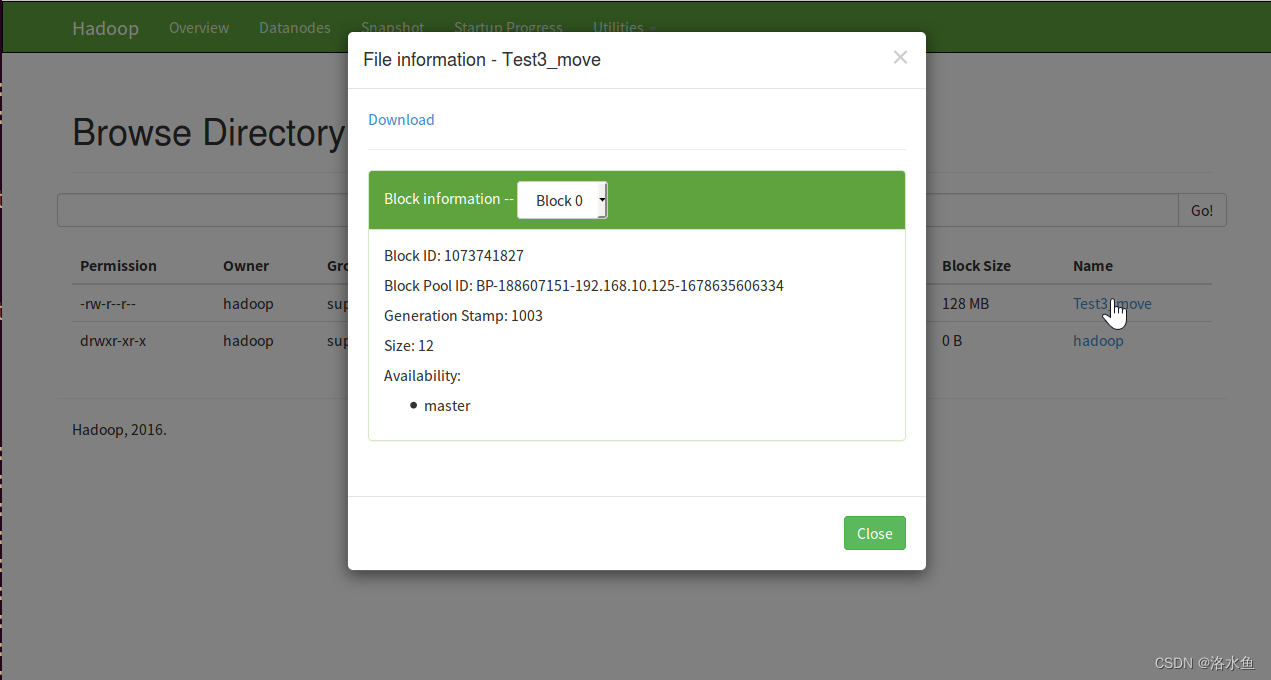
HDFS Web界面可以直接下载文件。单击文件列表中需要下载的文件名,超链接在弹出窗口中单击【Download】,即可将文件下载到本地。
思考题2(必做):hdfs dfs -ls -R 某个HDFS上的目录 该命令中“R”参数的作用是什么?请截图并给出相应的说明。
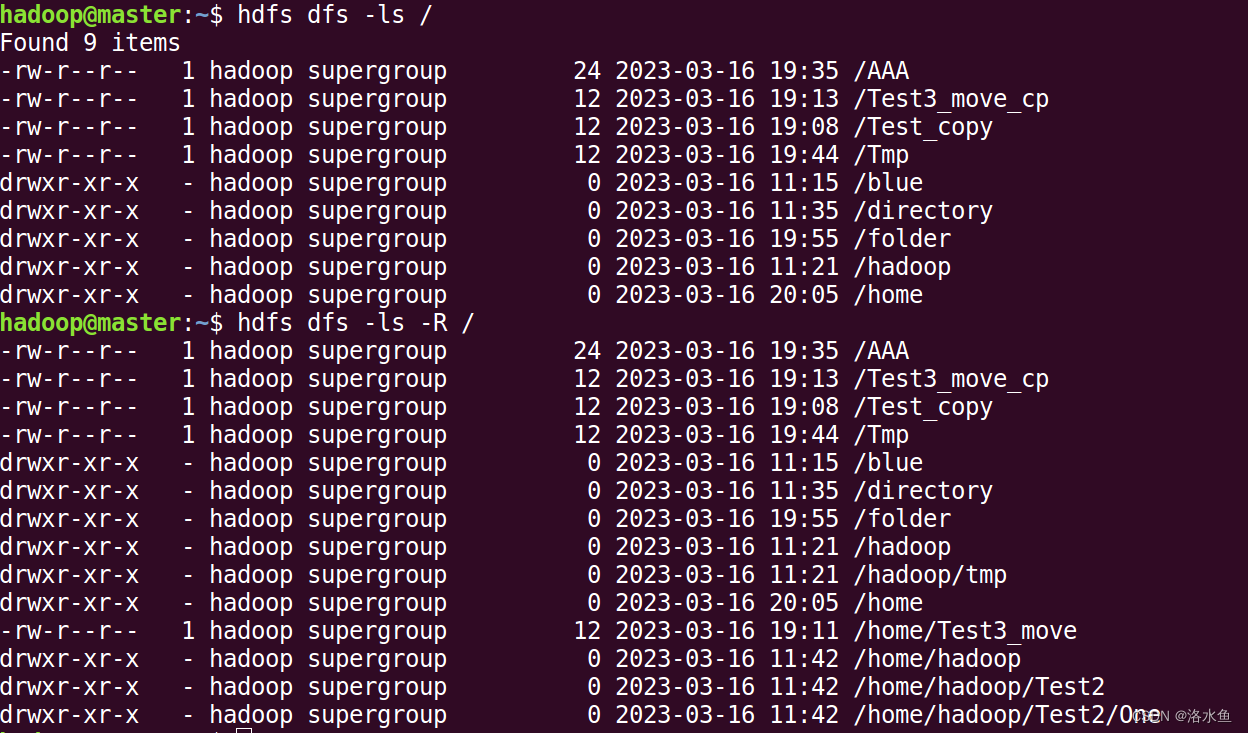
在hdfs dfs -ls命令中,-R参数表示递归地列出指定目录下的所有文件和子目录,包括子目录中的文件和子目录。如果不加-R参数,则只会列出指定目录下的文件和子目录,不会递归到子目录中去。
因此,使用hdfs dfs -ls -R <hdfs_directory>命令可以递归地列出指定HDFS目录下的所有文件和子目录的详细信息,包括文件名、权限、大小、修改时间等信息。这对于需要查看大量文件和子目录的情况非常有用,可以方便快捷地查看整个目录结构,并且不需要手动进入每个子目录进行查看。
- 1
- 2
- 3
思考题3(必做):如果已经上传了某个本地A文件到HDFS上,并在HDFS中命名为file1, 那再次上传A文件并在HDFS中命名为file1是否可行(路径一致)?如果换另一个本地文件B上传到HDFS中也命名为file1是否可行(路径一致)?
如果已经上传了本地文件A到HDFS上,并在HDFS中命名为file1,再次上传本地文件A并在HDFS中命名为file1是可行的,但实际上并不会改变原有的文件内容,只会在HDFS上创建一个新的副本。
如果上传另一个本地文件B,并在HDFS中命名为file1(路径一致),则会覆盖原来的file1文件,即用新的文件B替换原有的文件A。
- 1
- 2
- 3
思考题4(必做):如果操作对象是文件夹,如何使用命令完成和文件类似的操作?
如果需要操作的对象是文件夹,可以使用以下命令完成和文件类似的操作:
上传文件夹到HDFS:hdfs dfs -copyFromLocal <local_directory> <hdfs_directory> 或者 hdfs dfs -put <local_directory> <hdfs_directory>
下载HDFS文件夹到本地:hdfs dfs -copyToLocal <hdfs_directory> <local_directory> 或者 hdfs dfs -get <hdfs_directory> <local_directory>
在HDFS中创建文件夹:hdfs dfs -mkdir <hdfs_directory>
删除HDFS中的文件夹:hdfs dfs -rm -r <hdfs_directory> 或者 hdfs dfs -rmdir <hdfs_directory>
显示HDFS文件夹内容:hdfs dfs -ls <hdfs_directory>
将本地文件夹合并到HDFS文件夹:hdfs dfs -put <local_directory>/* <hdfs_directory> 或者 hdfs dfs -copyFromLocal <local_directory>/* <hdfs_directory>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
思考题5(选做,可加分保命): hdfs dfs -copyFromLocal 与 hdfs dfs -put 有什么区别?
hdfs dfs -copyFromLocal和hdfs dfs -put都是将本地文件上传到HDFS的命令,但它们有以下区别:
hdfs dfs -copyFromLocal命令只能将本地文件复制到HDFS,而hdfs dfs -put命令可以将本地文件复制到HDFS,也可以将HDFS文件复制到HDFS。
hdfs dfs -put命令可以指定文件的权限、用户和组,而hdfs dfs -copyFromLocal命令则不能指定这些参数。
hdfs dfs -put命令可以设置文件的块大小和副本数,而hdfs dfs -copyFromLocal命令则不能设置这些参数。
因此,如果只是将本地文件上传到HDFS,并且不需要指定文件的权限、用户和组以及文件块大小和副本数,则使用hdfs dfs -copyFromLocal命令更为简单方便。如果需要更多的控制和配置,则可以使用hdfs dfs -put命令。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
思考题6(选做,可加分保命): linux中每一个命令其实都是对应程序的执行结果,那HDFS命令对应的程序具体在哪些文件中定义呢?
在Linux系统中,可以通过which命令来查找HDFS命令对应的程序所在的位置
该命令会输出hdfs可执行程序所在的路径。
- 1
- 2

项目3 HDFS的API使用实践
大致步骤
- 3-1 改造虚拟机网络
- 3-2 改造Hadoop配置
- 3-3 编写代码 ==> 要完成文件的 创建/追加/修改
实验内容 项目3-1 改造虚拟机网络
【前置知识】VMware网络配置中的:桥接模式、NAT模式和仅主机模式
问题:如何让虚拟机里的Linux设备上网呢?
桥接模式(Bridged Mode):这种模式会将虚拟机连接到主机所在的网络中,让虚拟机可以像主机一样直接访问网络。
桥接模式下要让虚拟机里的Linux设备上网需要:
在VMware的网络设置中选择桥接模式,然后选择要桥接的物理网络适配器。
在Linux虚拟机中使用DHCP或手动配置IP地址和其他网络设置。
如果您使用的是DHCP,请确保虚拟机可以正确获取IP地址、默认网关和DNS服务器地址。
NAT模式(Network Address Translation Mode):这种模式会将虚拟机连接到主机所在的网络,但会使用主机的IP地址作为虚拟机的公共IP地址,因此虚拟机可以通过主机访问Internet。
NAT模式下要让虚拟机里的Linux设备上网,您需要:
在VMware的网络设置中选择NAT模式。
在Linux虚拟机中使用DHCP或手动配置IP地址和其他网络设置。
如果您使用的是DHCP,请确保虚拟机可以正确获取IP地址、默认网关和DNS服务器地址。
如果您手动配置了IP地址,请将默认网关设置为主机的IP地址。
仅主机模式(Host-Only Mode):这种模式只会将虚拟机连接到主机所在的网络中,虚拟机不能直接访问Internet。
要让虚拟机里的Linux设备上网,您需要:
在VMware的网络设置中选择仅主机模式。
在Linux虚拟机中使用DHCP或手动配置IP地址和其他网络设置。
如果您使用的是DHCP,请确保虚拟机可以正确获取IP地址、默认网关和DNS服务器地址。
如果您手动配置了IP地址,请将默认网关设置为主机的IP地址,并设置主机为虚拟机的DNS服务器。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
【前置知识】VMware网络配置中的:桥接模式、NAT模式和仅主机模式
需要设置虚拟网络
虚拟网络配置有三种模式:
• 仅主机(适配器VMnet1)
• NAT (适配器VMnet8)
• 桥接
此处的适配器可以简单理解为
人们常说的“网卡”。
查看下Windows下对应的网络设备和网络服务
查看下Windows下对应的网络设备和VM网络服务 ==> win+r 输入 services.msc 查看VM相关服务
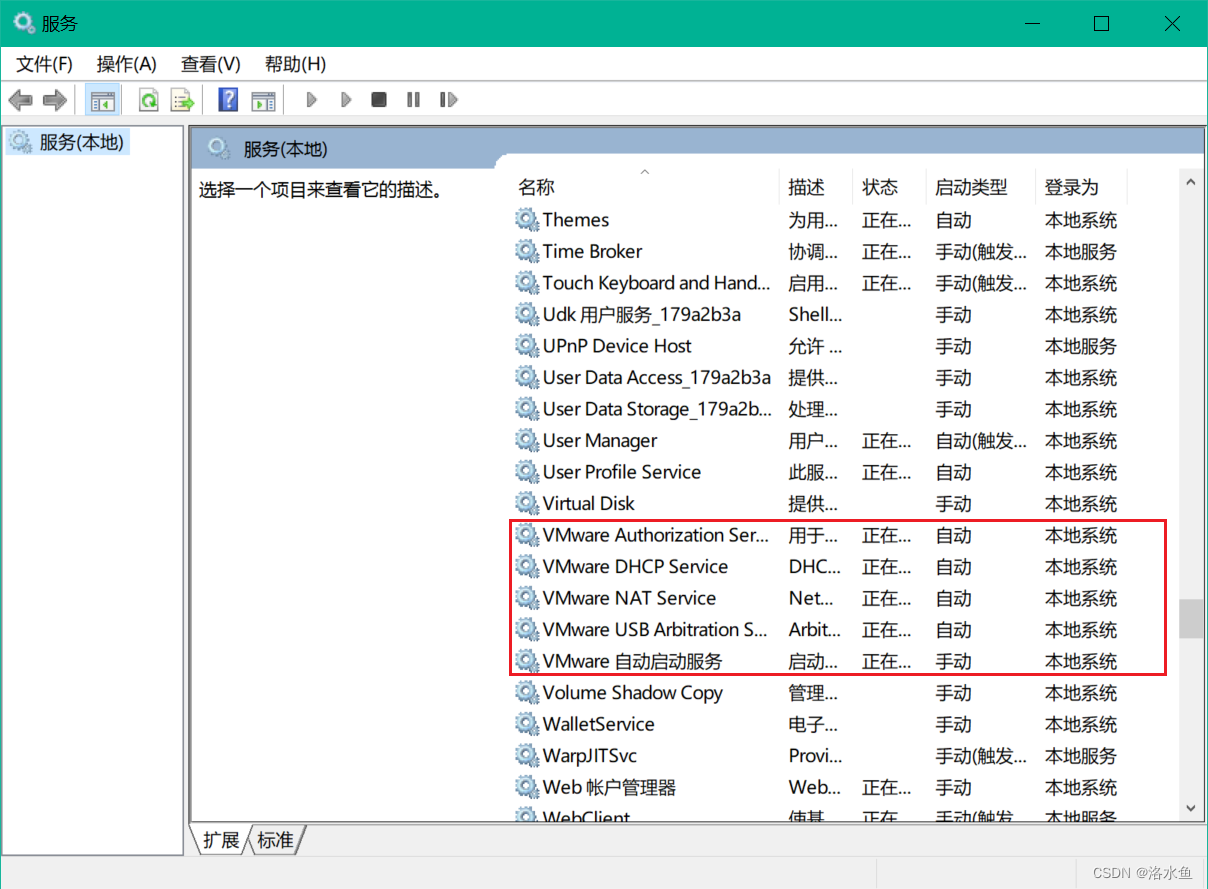
桥接模式:让物理机和虚拟机设置在同一个网段,前提是网段有多余的IP可用。
NAT模式:将物理机当做一个路由器去使用
仅主机模式:Host-Only模式将虚拟机与外网隔开,使得虚拟机成为一个独立的系统,只与主机相互通讯
显然:
NAT模式才是最好的解决方案
且我们应该放弃DHCP自动赋值地址信息,手动设置网络更加符合实际需要
更多网络知识细节,可以参考以下链接(附录中有完整网址):
• VMware虚拟机三种网络模式:桥接模式,NAT模式,仅主机模式
• vmware 虚拟机三种网络模式 桥接 NAT 仅主机区别 是什么意思
• 网络连接的三种模式:桥接模式,Net模式,仅主机模式
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_1-1 确认window上的虚拟网卡VMnet8开启(NAT用),手动设置配置
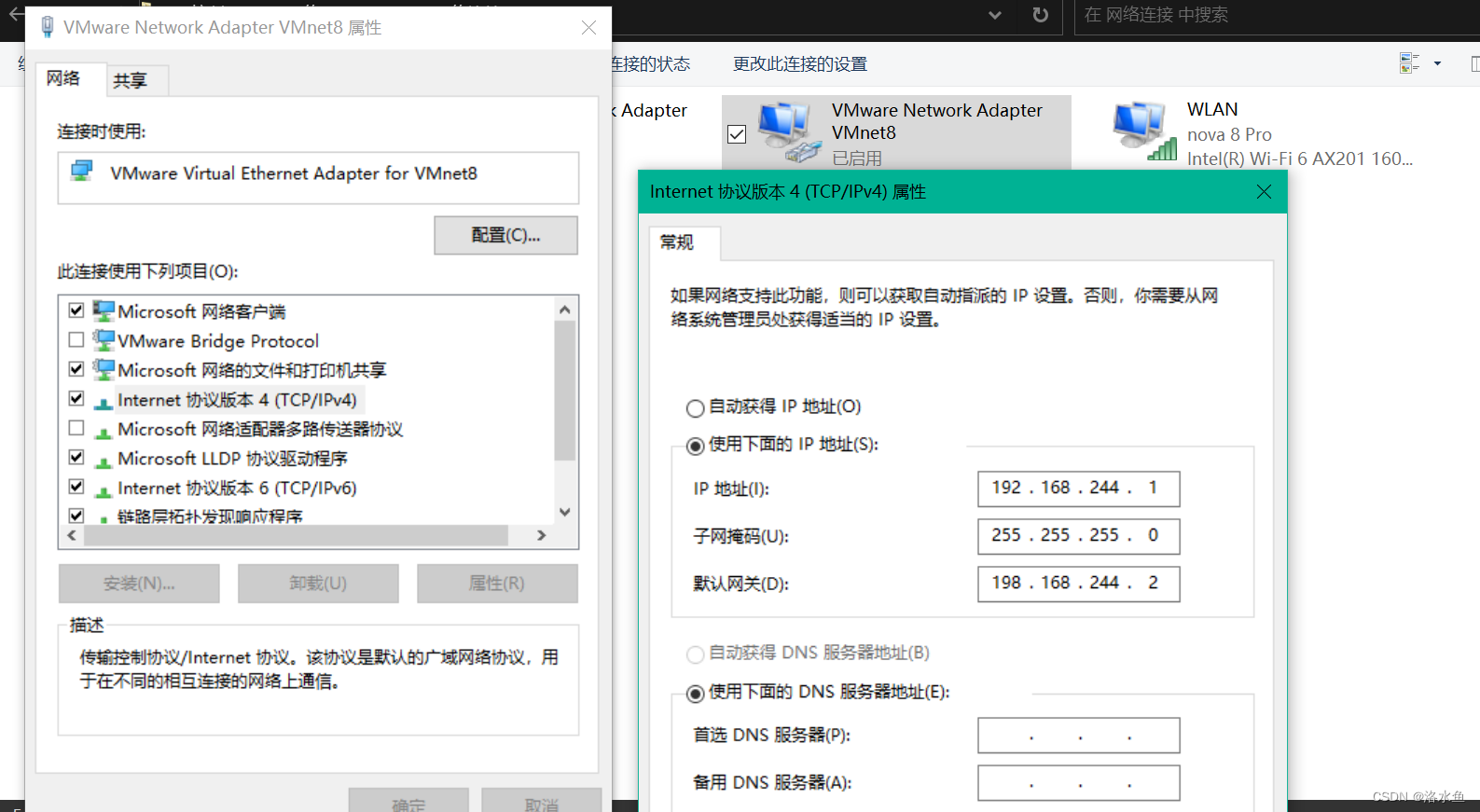
【实操】step_1-2 确认window上的虚拟网卡VMnet8开启(NAT用),手动设置配置
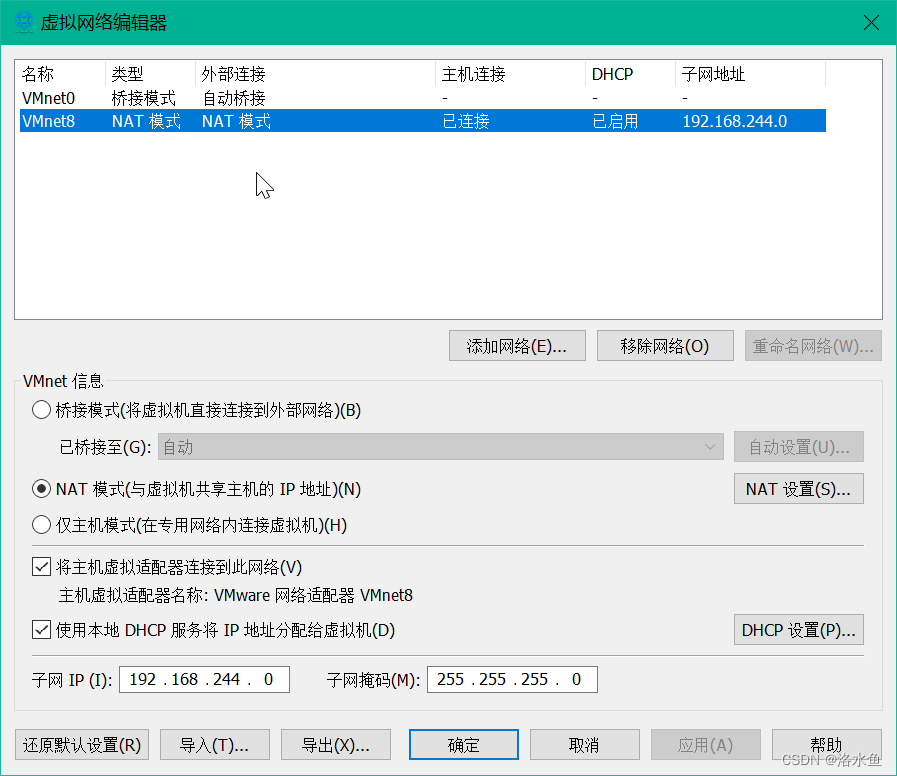
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_2-1 设置VM中网络,在“虚拟网络编辑器”中点击“更改设置”
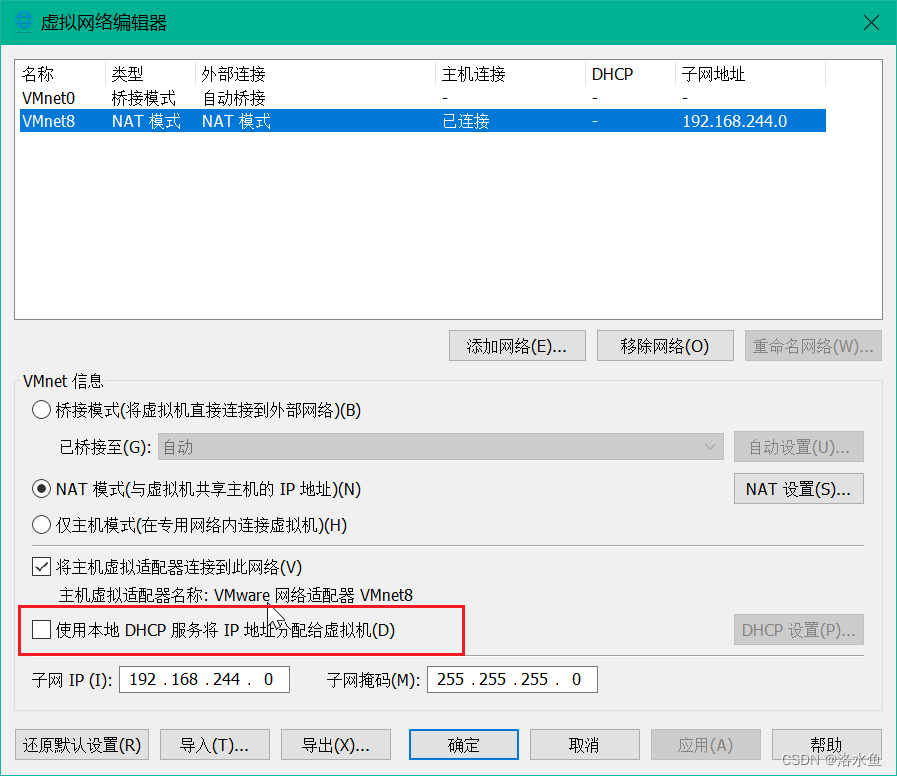
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_2-2 设置VM中网络,采用手动NAT
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_2-3 设置VM中网络,设置网关,点击“添加”绑定通信端口
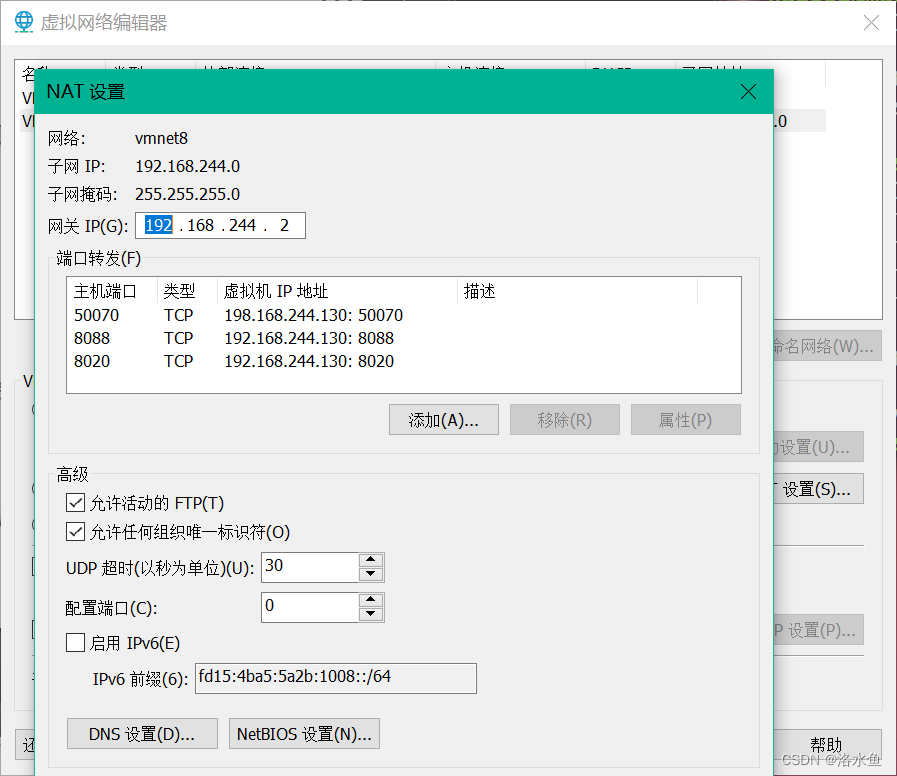
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_3-1 设置linux虚拟机网络,界面操作简单,也可以直接命令行
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_3-2 设置linux虚拟机网络,手动填写刚才在Window下拟定的配置
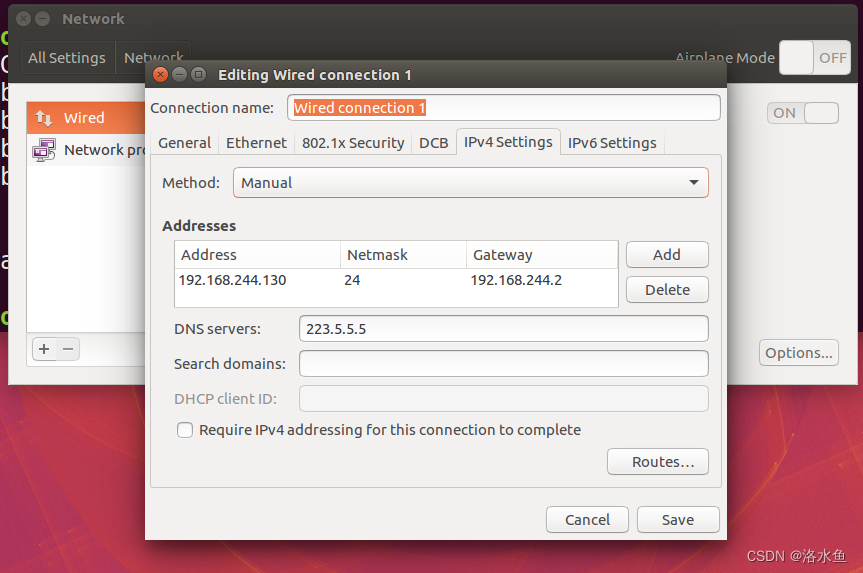
4.实验内容 项目3-1 改造虚拟机网络
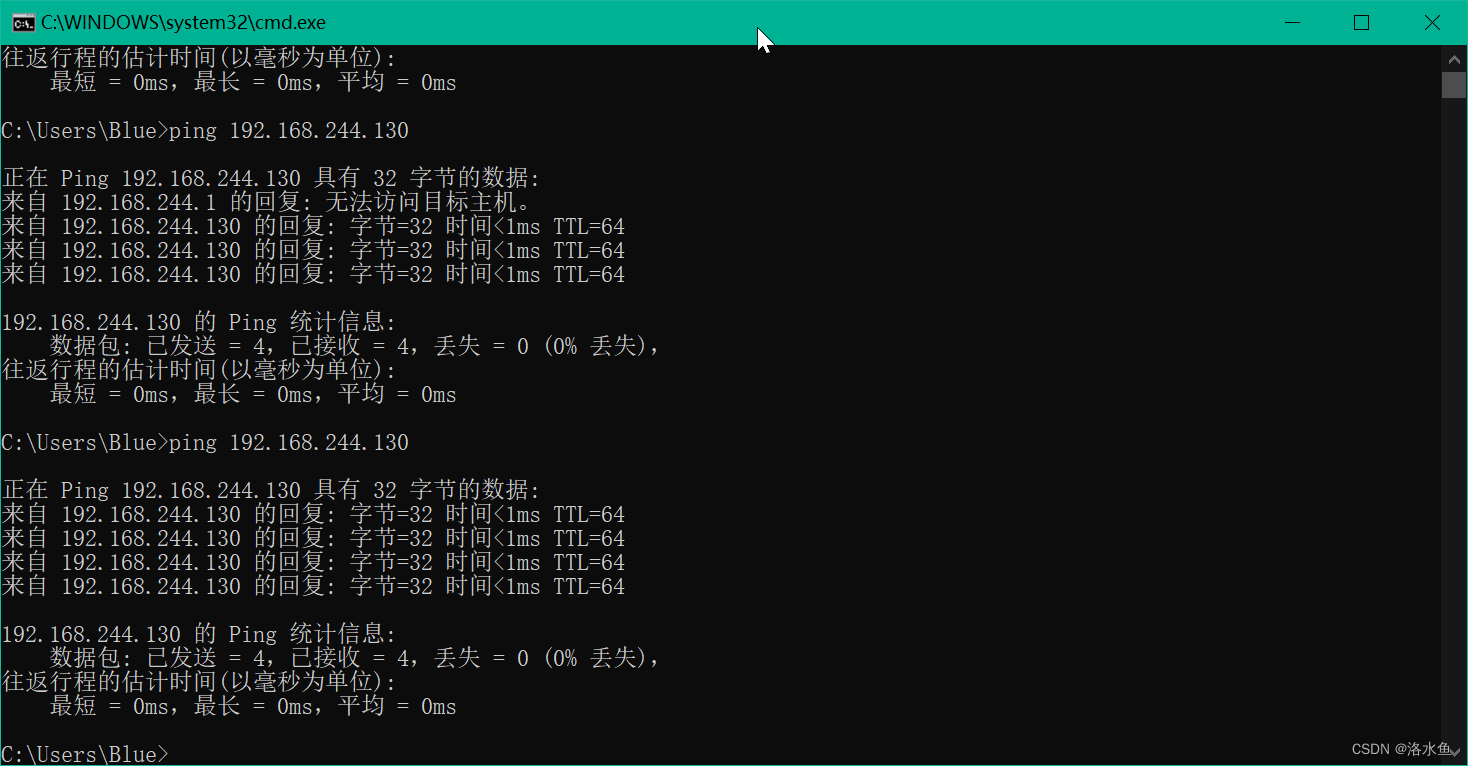
【实操】step_3-3 确认网络可以访问:试试ping百度、用浏览器上网(前提是物理机联网)
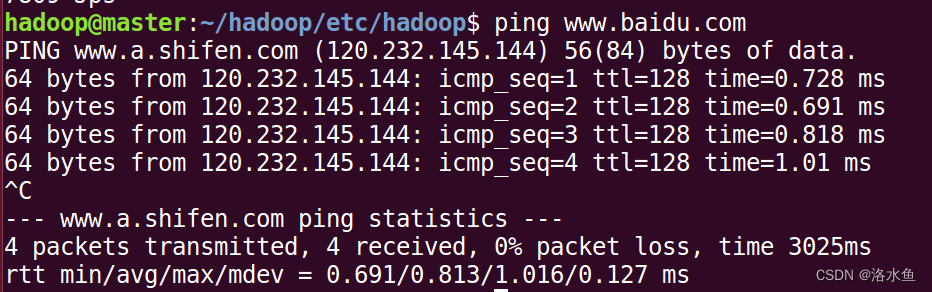
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_3-4 确认网络可以访问:试试ping百度、用浏览器上网(前提是物理机联网)

4.实验内容 项目3-1 改造虚拟机网络
【实操】step_3-5 在linux虚拟机中ping通windows物理机的VMnet8设定IP
第一次ping很长时间也没有数据(原因:没有关闭win的防火墙)

关闭后:
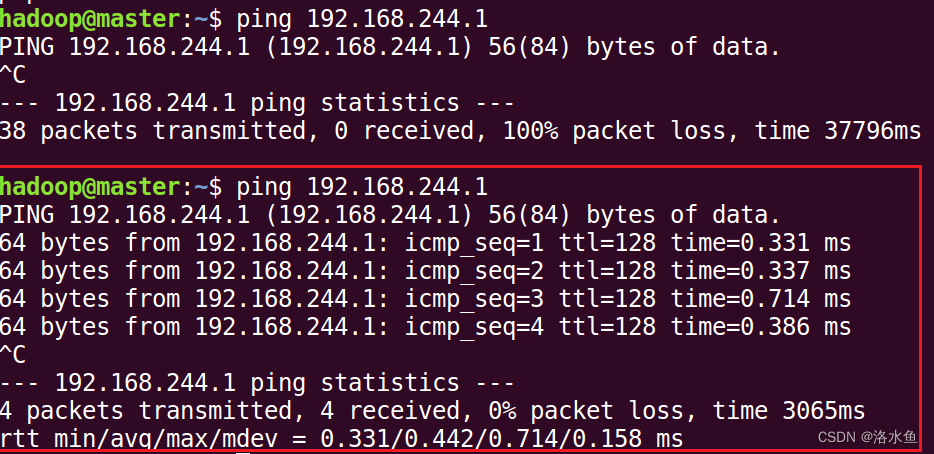
4.实验内容 项目3-1 改造虚拟机网络
【实操】step_3-6 在windows侧ping同linux虚拟机,确认两边网路通信OK(win+r cmd)
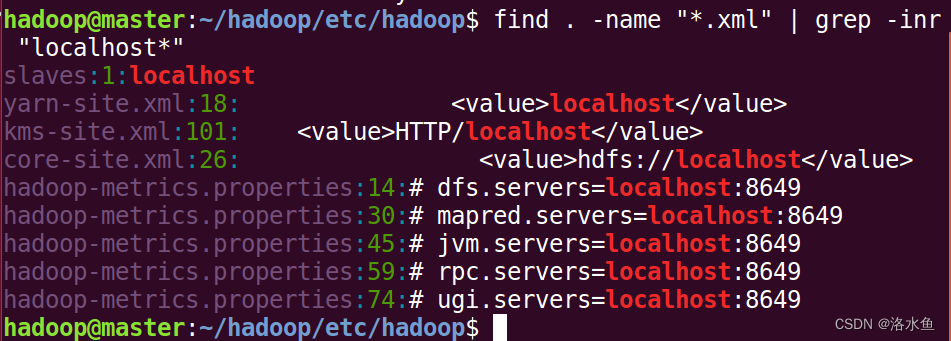
实验内容 项目3-2 改造Hadoop配置
【实操】将hadoop涉及到的5个进程的localhost都调整为新设定的IP,也可以使用/etc/hosts中设定一个名称,方便后续快速更改(这样做更加正规)
step_1 先查看有哪些文件使用了localhost
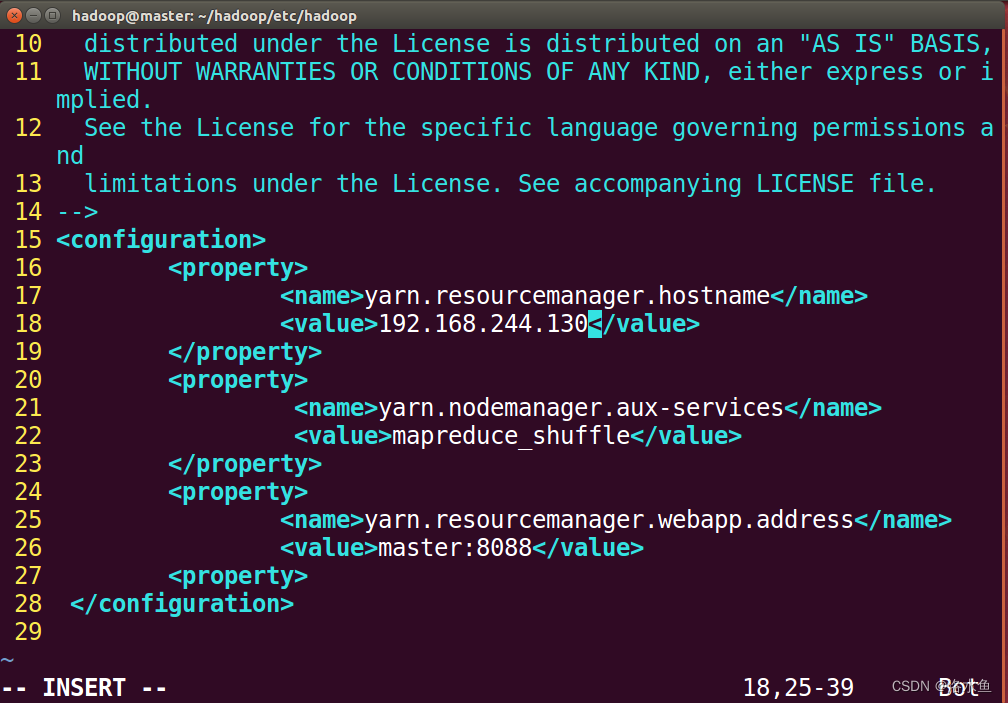
4.实验内容 项目3-2 改造Hadoop配置
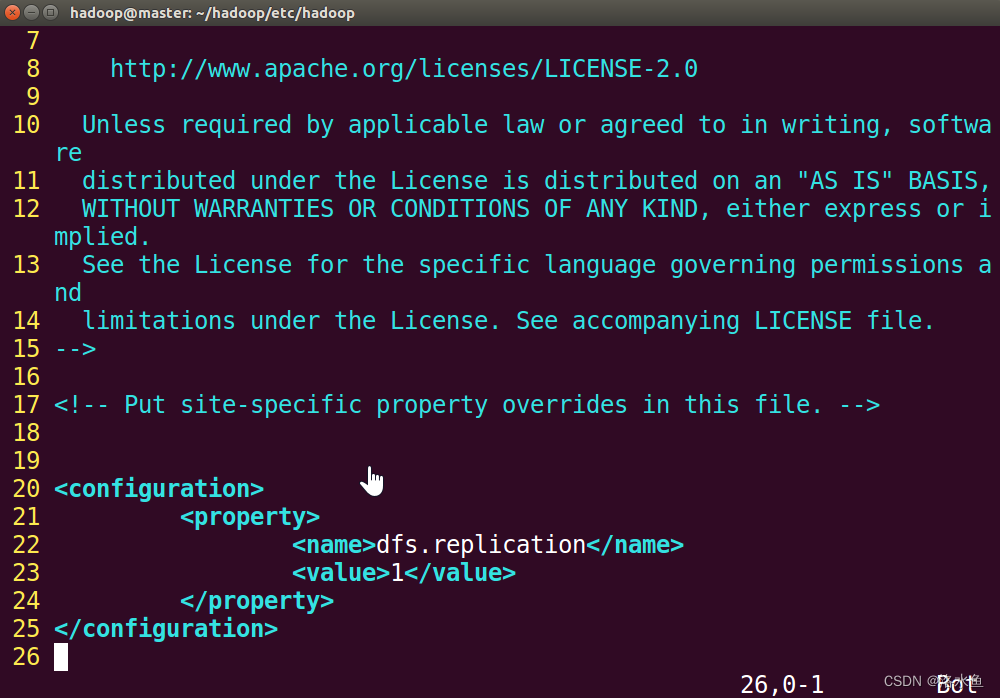
【实操】step_2-1 在关闭Hadoop所有服务的前提下修改相关配置文件(yarn-site.xml)master是我自己的主机名,请填自己的!!!
修改完后(第27行有语法错误下图还没有修改应为是前面截图正确的是</property>,后面会讲,看到就在这说了)
4.实验内容 项目3-2 改造Hadoop配置
【实操】step_2-2 在关闭Hadoop所有服务的前提下修改相关配置文件(hdfs-site.xml)
修改前:
修改后
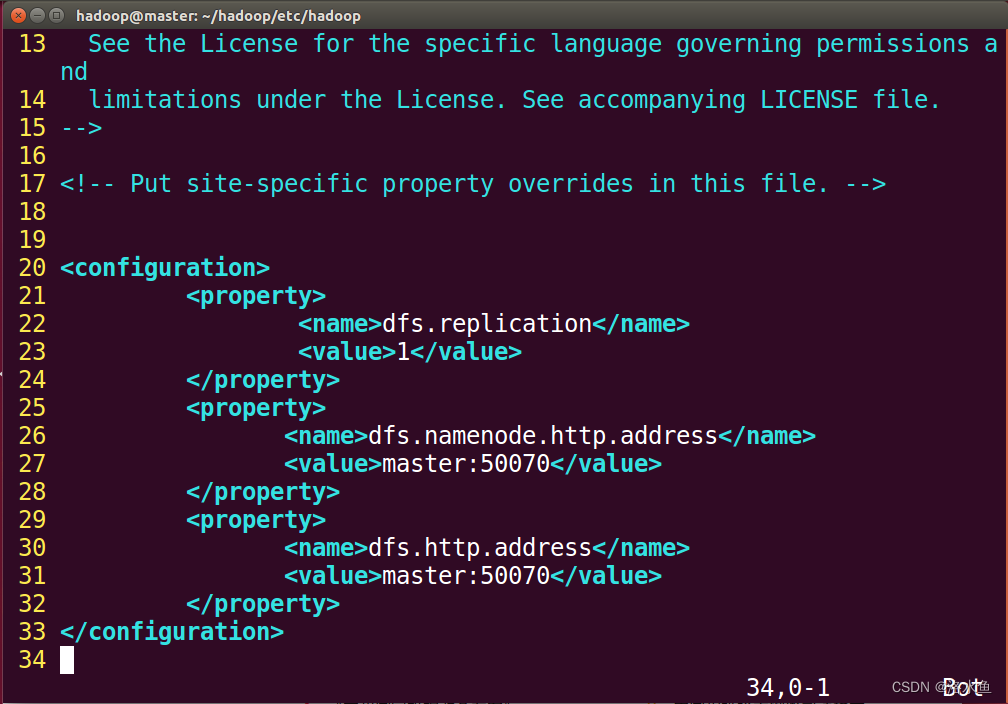
作用:
这些代码是 Hadoop 分布式文件系统的配置文件,其中包含以下三个属性:
dfs.replication:该属性设置了文件副本的数量。在这里,设置为1,表示文件只有一个副本存储在文件系统中。这意味着 Hadoop 不会创建文件的备份,这将节省磁盘空间,但也增加了数据丢失的风险。
dfs.namenode.http.address:这个属性指定了主 NameNode 的 HTTP 通信地址。在这里,设置为 master:50070,表示主 NameNode 在主机名为 master,端口号为 50070 的地址上运行。
dfs.http.address:该属性指定了所有 NameNode 和 DataNode 的 HTTP 通信地址。在这里,设置为 master:50070,表示所有节点都在主机名为 master,端口号为 50070 的地址上运行。
总的来说,这些代码的作用是设置 Hadoop 分布式文件系统的副本数量和各个节点的通信地址,以确保文件系统能够正确地工作。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.实验内容 项目3-2 改造Hadoop配置
【实操】step_2-3 在关闭Hadoop所有服务的前提下修改相关配置文件(core-site.xml)
就改了主机名为master
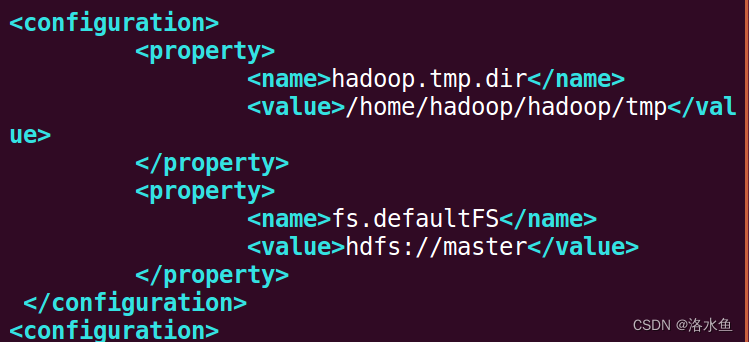
作用:
hadoop.tmp.dir:该属性指定了 Hadoop 的临时目录路径。在这里,设置为 /home/hadoop/hadoop/tmp,表示 Hadoop 将使用这个路径作为临时目录来存储各种临时文件和数据。
fs.defaultFS:该属性指定了 Hadoop 的默认文件系统。在这里,设置为 hdfs://master,表示 Hadoop 的默认文件系统是一个名为 master 的 NameNode 上运行的 HDFS 文件系统。
这些配置文件的作用是为 Hadoop 集群配置一些默认值,例如临时目录和默认文件系统。这些属性可以通过修改配置文件来改变,以适应特定的应用程序需求。
- 1
- 2
- 3
- 4
- 5
4.实验内容 项目3-2 改造Hadoop配置
【实操】step_2-4 最后在检查下是否还有遗漏
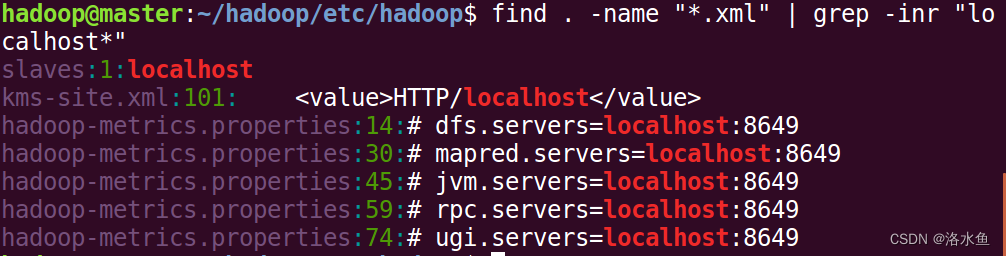
4.实验内容 项目3-2 改造Hadoop配置
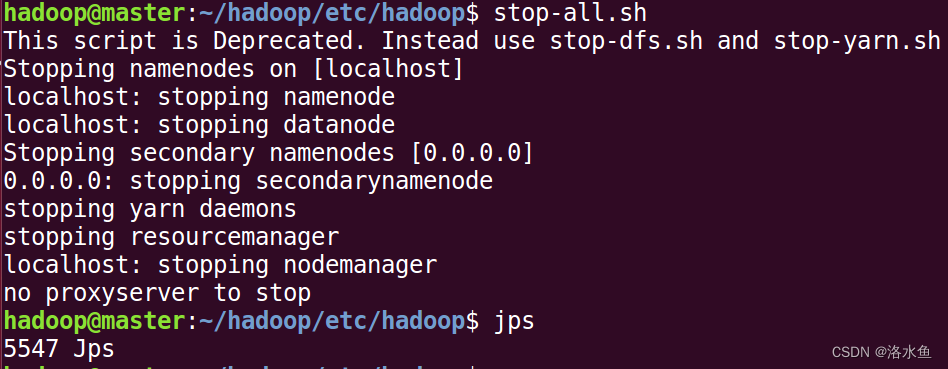
【实操】step_2-5 启动Hadoop,确认相关JVM进程正常工作
前面启动发现JVM(start-all.sh)报错yarn-site.xml,是前面的语法错误,可以回看我yarn-site.xml的截图
修复完后成功启动
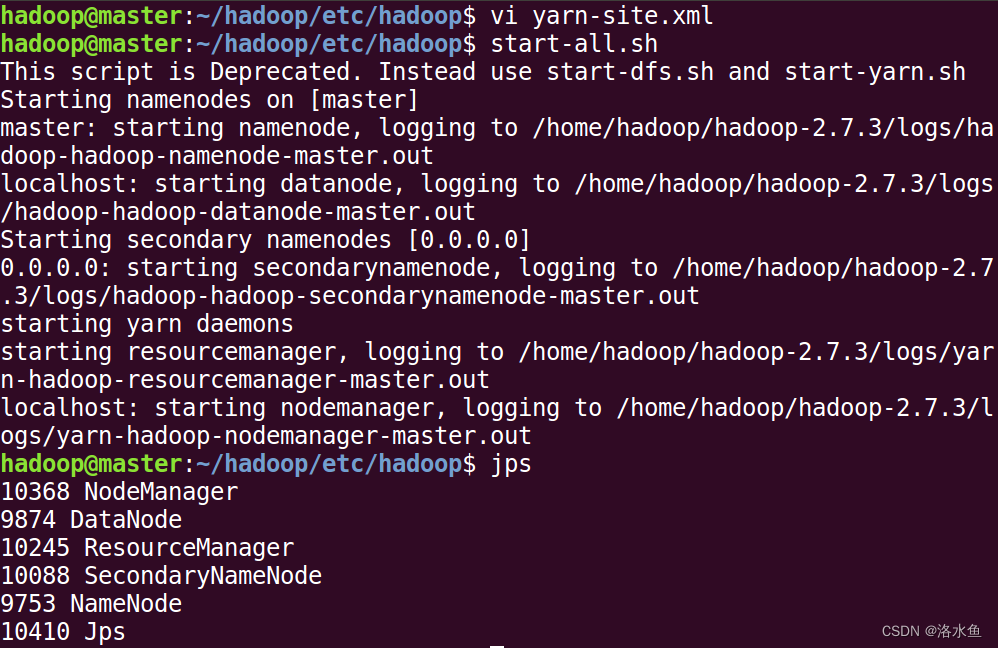
4.实验内容 项目3-2 改造Hadoop配置
【实操】step_2-6 简单测试功能是否可用
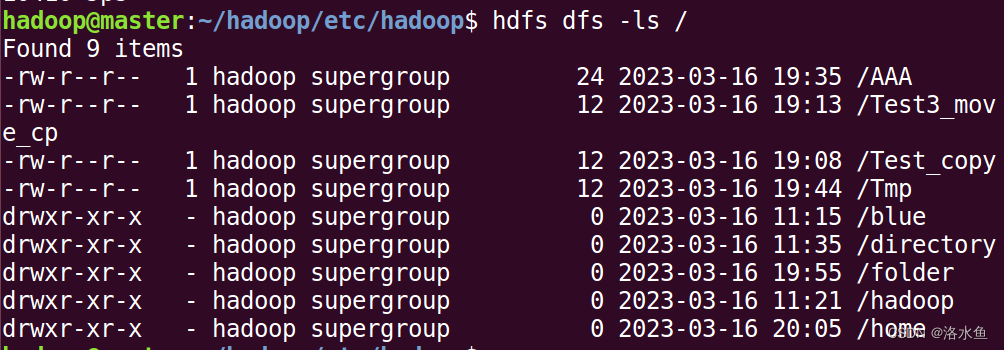
发现没有问题
实验内容 项目3-3 编写代码
【实操】此处用eclipse演示,具体细节请参考梁江怀老师博客
- 配置开发环境
(1)我们建议,可先采用非Maven的方式完成开发,因为这样可以规避许多的网络访问问题。
(2)如果非Maven方式完成后,再尝试去做Maven模式。 - 参考博客,编写代码
(1)非Maven工程API访问HDFS
https://blog.csdn.net/qq_42881421/article/details/83001401
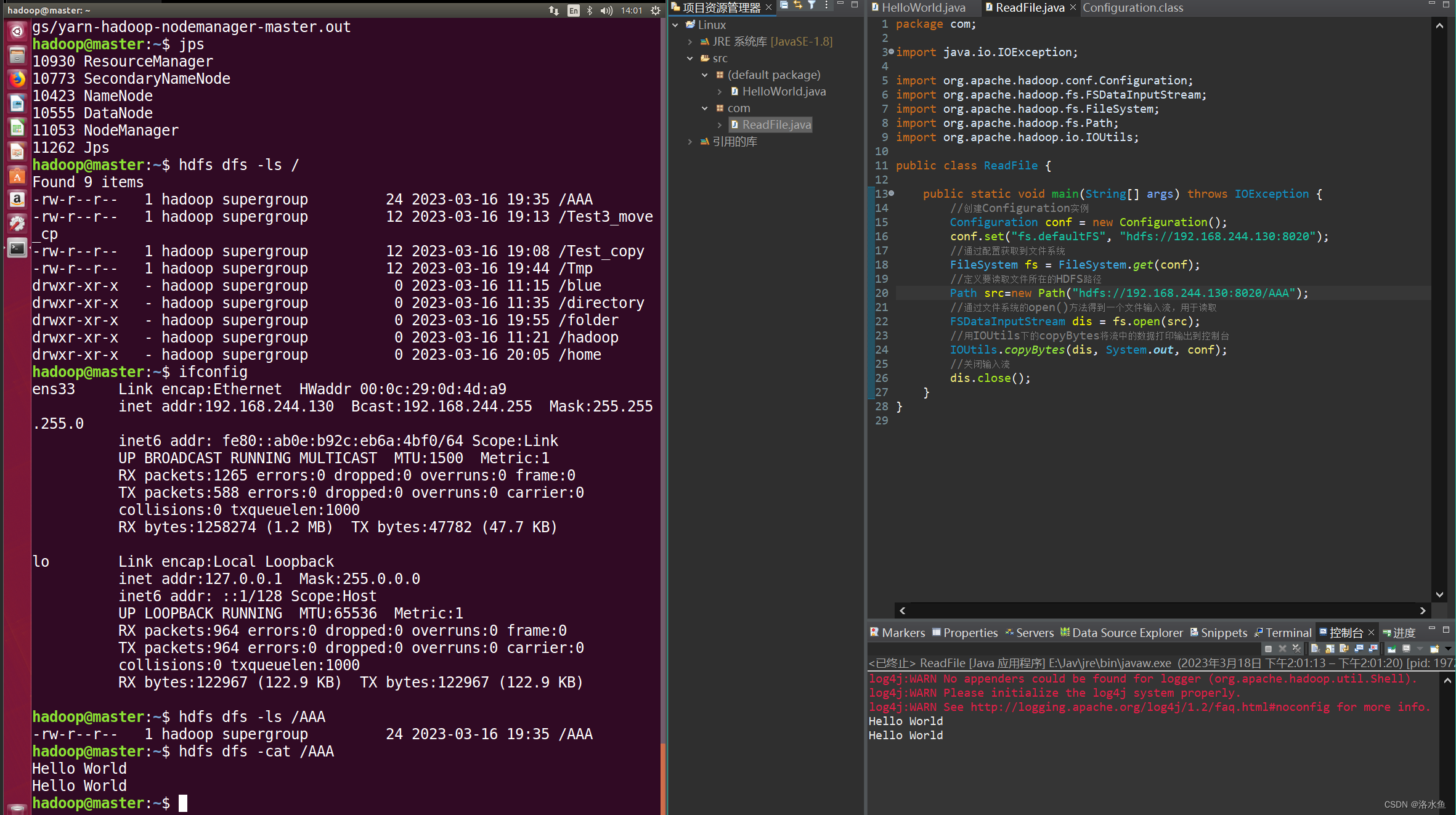
跟着弄成功运行!
(2)Maven工程API访问HDFS
https://blog.csdn.net/qq_42881421/article/details/100762022

【注】
• Maven的相关配置和下载请耐心完成
• 如果遇到海外网络不能访问的问题,请参考实验1介绍的配置国内镜像源的方法解决
• 其实为了方便,建议直接使用IDEA完成;后续课程《大数据内存计算》(spark)也要使用IDEA
根据教程同样完成:
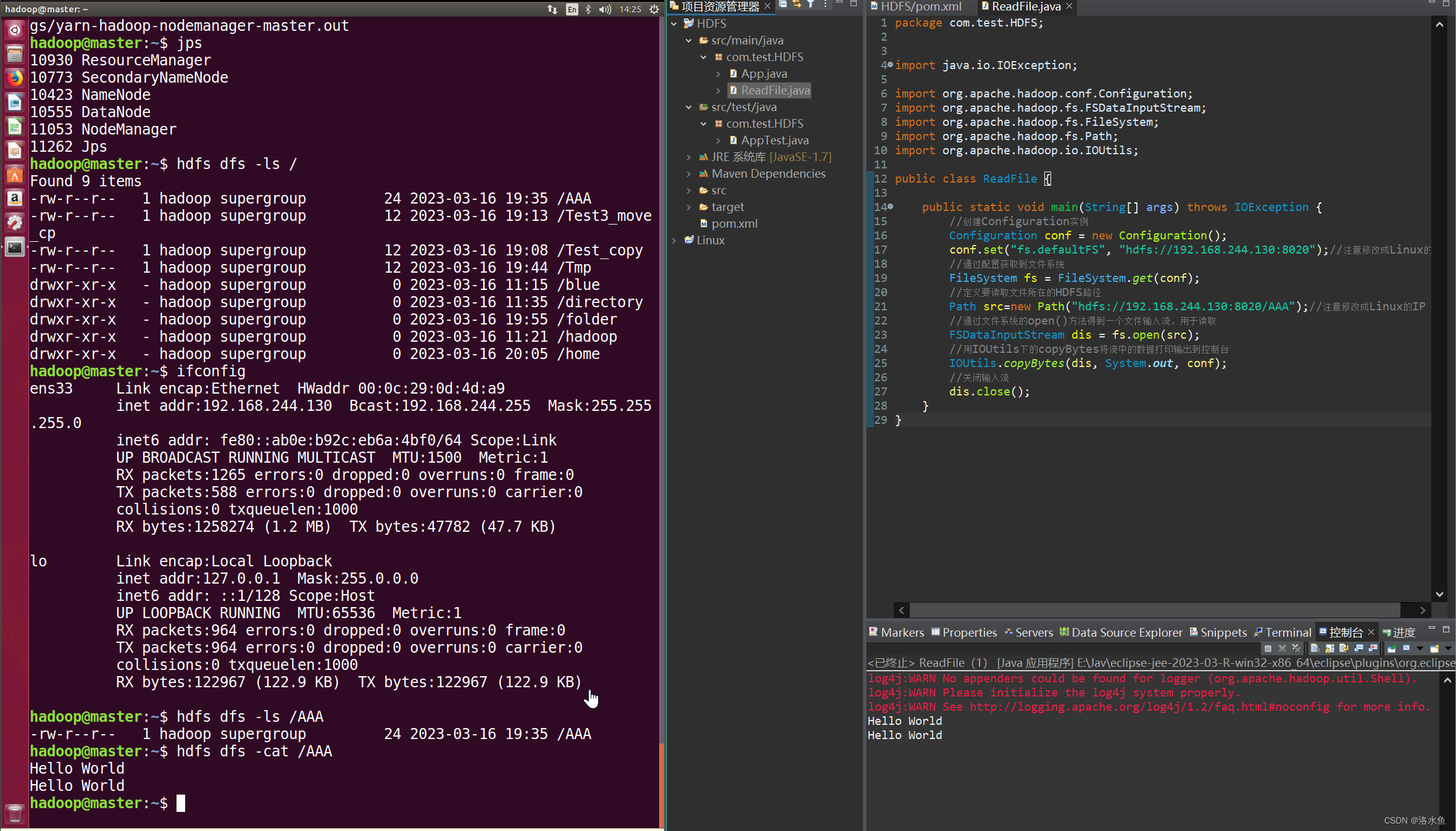
4.实验内容 项目3-3 编写代码
【实操】如果对环境配置不熟悉,可以先看:
(3)熟悉Eclipse + Maven的JAVA开发环境
https://blog.csdn.net/qq_42881421/article/details/82945454
(4)IDEA + Maven工程
https://blog.csdn.net/qq_42881421/article/details/100717502
(5)Maven的单篇安装教程
https://blog.csdn.net/qq_42881421/article/details/82900849
4.实验内容 项目3-3 编写代码
【实操】完成Maven工程配置后,编写如下代码(此处仅仅是文件内容读取,注意自己虚拟机的IP和端口)
package com.test.HDFS;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class ReadFile {
public static void main(String[] args) throws IOException {
//创建Configuration实例
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.244.130:8020");//注意修改成Linux的IP
//通过配置获取到文件系统
FileSystem fs = FileSystem.get(conf);
//定义要读取文件所在的HDFS路径
Path src=new Path("hdfs://192.168.244.130:8020/AAA");//注意修改成Linux的IP
//通过文件系统的open()方法得到一个文件输入流,用于读取
FSDataInputStream dis = fs.open(src);
//用IOUtils下的copyBytes将流中的数据打印输出到控制台
IOUtils.copyBytes(dis, System.out, conf);
//关闭输入流
dis.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4.实验内容 项目3-3 编写代码
【实操】注意,我们在虚拟网络IP的设备上编写了一个Client程序,用于读取HDFS上对应文件的内容:
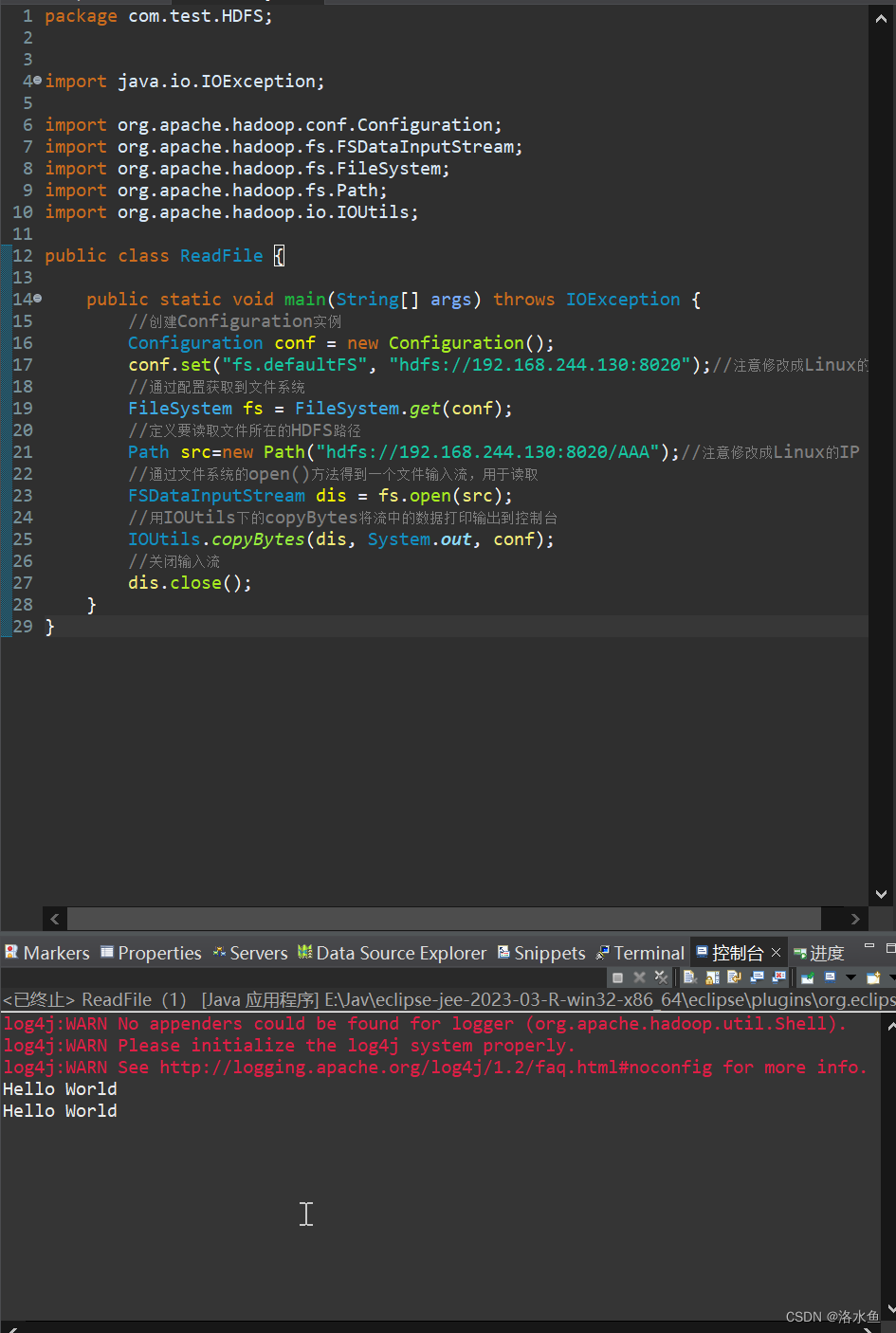
4.实验内容 项目3-3 编写代码
【实操】注意,通过编写HDFS API程序,我们一共要完成以下六个功能:
• 文件的创建
• 文件的删除
• 文件的上传
• 文件的下载
• 文件属性查看
• 文件内容查看
编写HDFS API程序可以使用Java编程语言,并使用Hadoop的Java API库进行开发。以下是六个基本功能的实现方法:
文件的创建
package com.test.HDFS;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import java.net.URI;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 创建Hadoop配置对象
URI uri = new URI("hdfs://192.168.244.130:8020"); // 定义HDFS连接参数
FileSystem fs = FileSystem.get(uri, conf, "hadoop"); // 获取HDFS文件系统对象
Path file = new Path("/Java_Create"); // 定义要创建的文件路径
FSDataOutputStream out = fs.create(file, true); // 创建文件输出流,第二个参数表示是否覆盖已有文件
out.writeBytes("Hello World\n"); // 写入文件内容(不支持中文)
out.writeUTF("你好世界\n"); // 再次写入文件内容(支持中文)
out.close(); // 关闭文件输出流
fs.close(); // 关闭HDFS文件系统对象
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

文件的删除
package com.test.HDFS;
import java.net.URI; // 引入Java标准库中的URI类,用于处理URI(统一资源标识符)。
import org.apache.hadoop.conf.Configuration; // 引入Apache Hadoop库中的Configuration类,用于读取Hadoop集群的配置信息。
import org.apache.hadoop.fs.FileSystem; // 引入Apache Hadoop库中的FileSystem类,用于访问Hadoop分布式文件系统(HDFS)。
import org.apache.hadoop.fs.Path; // 引入Apache Hadoop库中的Path类,用于表示HDFS上的路径。
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();// 引入Apache Hadoop库中的Path类,用于表示HDFS上的路径。
//注意修改为自己的IP
URI uri=new URI("hdfs://192.168.244.130:8020");// 创建一个URI对象,表示Hadoop集群的名称节点所在的地址和端口号。
FileSystem fs=FileSystem.get(uri,conf,"hadoop");//使用上述URI和Configuration对象,创建一个FileSystem对象,用于访问HDFS上的文件系统。
//HDFS file
Path path=new Path("/user/hadoop/1.txt");//创建一个Path对象,表示HDFS上的文件路径。
fs.delete(path,true);//使用FileSystem对象删除HDFS上指定的文件,第二个参数true表示递归删除,如果文件不存在也不会抛出异常。
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

文件的上传
第一次运行下面代码报错,后面发现原因是path的问题
package com.test.HDFS;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import java.net.URI;
public class UploadFile {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
//注意修改为自己的IP
URI uri=new URI("hdfs://192.168.244.130:8020");
FileSystem fs=FileSystem.get(uri,conf,"hadoop");
//local file
Path localPath=new Path("E:/Hello.txt");//这里写的是Windows系统下的文件路径,注意按实际修改。
//HDFS file
//上传到目的地路径,可以自定义, hdfs的/user/hadoop目录需要先用命令创建出来
Path dstPath=new Path("/hadoop/Hello.txt_Win");
fs.copyFromLocalFile(localPath,dstPath);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
把代码的Path改成下面这个,然后运行发现成功了
Path localPath = new Path(“file:///E:/Hello.txt”);


文件的下载
链接的教程这里有点小错误,跟我改就可以了
package com.test.HDFS;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import java.net.URI;
public class DownloadFile {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
URI uri=new URI("hdfs://192.168.244.130:8020");
FileSystem fs=FileSystem.get(uri,conf,"hadoop");
//HDFS文件:"/2.txt"为hdfs的文件,如果没有该文件请从Linux上传一个文件到HDFS.
Path dstPath=new Path("/hadoop/Hello.txt_Win");
//local文件位置:需要先在Windows D盘创建一个test文件夹存放下载的文件
Path localPath=new Path("file:///D:/Download_Linux");
//从HDFS下载文件到本地
fs.copyToLocalFile(false,dstPath,localPath,true);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

运行成功
文件属性查看
文件内容查看
package com.test.HDFS;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import java.net.URI;
import java.sql.Date;
import java.text.SimpleDateFormat;
public class FileAttr {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
URI uri=new URI("hdfs://192.168.244.130:8020");
FileSystem fs=FileSystem.get(uri,conf,"hadoop");
//locate file 文件位置
Path fpath=new Path("/hadoop/Hello.txt_Win");
FileStatus filestatus=fs.getFileLinkStatus(fpath);//指定要获取属性的文件路径。
//get block size 获取文件块大小
long blocksize=filestatus.getBlockSize();
System.out.println("blocksize:"+blocksize);
//get file size 获取文件大小
long filesize=filestatus.getLen();
System.out.println("filesize:"+filesize);
//get file owner 获取文件所属者
String fileowner=filestatus.getOwner();
System.out.println("fileowner:"+fileowner);
//get file access time 获取文件存取时间
SimpleDateFormat formatter=new SimpleDateFormat("yyyy-mm-dd hh:mm:ss");
long accessTime=filestatus.getAccessTime();
System.out.println("access time:"+formatter.format(new Date(accessTime)));
//get file modify time 获取文件修改时间
long modifyTime=filestatus.getModificationTime();
System.out.println("modify time:"+formatter.format(new Date(modifyTime)));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
运行成功
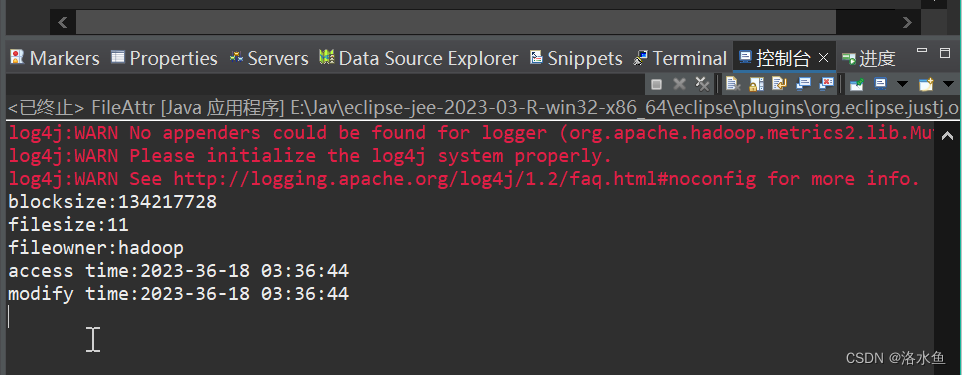
所有代码都可以参考 梁江怀 老师博客 or 科普白皮教材 or 《权威指南》
【拓展与思考】
思考题7(选做,可加分保命)实际上HDFS的命令除了 hdfs 也有 hadoop的,譬如hadoop fs -ls / 就等同于 hdfs dfs -ls /,请问这两种命令有和不同吗?
实际上,hadoop fs和hdfs dfs命令是相同的,只是在不同的Hadoop版本中使用不同的命令。
在早期版本中,hadoop fs是主要的文件系统命令,而在较新的版本中,hdfs dfs是主要的文件系统命令。
因此,两种命令的功能是相同的,都可以用于在HDFS中执行文件系统操作。
例如,hadoop fs -ls /和hdfs dfs -ls /命令都用于列出HDFS根目录中的文件和目录。
- 1
- 2
- 3
- 4
思考题8 (选做,可加分保命)hdfs dfs -ls的显示结果中,是否能够看到block副本数量,如果可以请指明,否则说明情况。
在hdfs dfs -ls命令的输出中,默认情况下是不会显示文件的block副本数量的。
但是,您可以使用hdfs dfs -ls -h命令来显示文件的人类可读形式的大小和block副本数量。
该命令的输出将包括文件大小、权限、所有者、组、修改时间、路径和block副本数量等信息。
- 1
- 2
- 3
思考题9(选做,可加分保命)之前学习Linux文件系统时,我们讨论过文件权限问题,请思考HDFS中的文件权限会有和不同之处?
虽然HDFS中的文件权限控制与Linux文件系统中的文件权限控制有些相似之处,但也存在一些重要的不同之处,
这些差异主要体现在权限控制的简单性和一些特殊性。
HDFS中的权限控制是由Hadoop的NameNode管理的,
而不是像Linux文件系统一样是由操作系统内核管理的。
HDFS中的文件权限比Linux文件系统中的文件权限更加简单,只包括读(read)、写(write)和执行(execute)三种权限。
HDFS中的文件权限控制比较粗粒度,只能控制整个文件或目录的读写执行权限,而不能对文件的特定部分进行访问控制。
- 1
- 2
- 3
- 4
- 5
- 6
思考题10(选做,可加分保命)HDFS中的distcp命令的作用是什么?它与hdfs dfs -cp 命令有何不同?
与hdfs dfs -cp命令相比,distcp命令的主要不同之处在于以下几点
并行复制:distcp命令可以在多个源和目标之间并行复制数据,以加快复制速度。例如,可以使用多个并发任务来复制不同的文件或子目录,每个任务都会复制一部分数据,以最大程度地利用集群的带宽和处理能力。
跨集群复制:distcp命令可以在不同的HDFS集群之间复制数据,而hdfs dfs -cp命令只能在同一集群内复制数据。这使得distcp命令非常适合在多个地理位置或不同的组织之间复制数据,例如,将数据从一个Hadoop集群复制到另一个Hadoop集群或将数据从Hadoop集群复制到云存储服务等。
自动故障恢复:distcp命令可以自动检测和恢复复制过程中的故障和错误。如果其中一个复制任务失败,distcp命令可以自动重新启动该任务,或者将失败的任务分成更小的子任务进行重试,以确保复制过程的连续性和正确性。
高级选项:distcp命令还提供了一些高级选项,例如设置带宽限制、跳过已经复制的文件、忽略某些文件或目录、在源和目标之间进行差异对比等。
- 1
- 2
- 3
- 4
- 5
项目4 HDFS的API单元测试程序和更多思考(选做)–还没写
【目的】目前实验课程也在不断进化和改革,其实思考题和选做部分的内容才能真正训练大家对课程知识体系的理解,也和培训班面向面试从业的理念更加贴近。
【思考】
Q1:每次为了尝试使用HDFS的API都要写一个类,然后编写main吗?
A1:这样做太业余了,明显应该用Java课程中学过的UT测试去编写测试代码啊。
Q2:一直强调文件分块是为了适应分布式计算,那么这点是如何体现的呢?
A2:参看“seek”和“文件属性”案例
Q3:HDFS是分布式的,那么如果我们文件中写入了数据,那么这些数据能够被立即读取到吗?
A3:参看《权威指南》P74,进一步理解I/O流,理解为何要出现工具类IOUtils
【注】还是那句话,多看经典书籍,多看项目作者写的资料、论文和书籍,辨(yuan)证(离开)垃圾教材和教程;培训班的课程要分辨着听;学习技术知识一定要有自己的总结。
实验内容 项目4-0 简单设置UT
前面没发现要导org.junit.Before,直接@Before报错
后面发现在如下界面导入
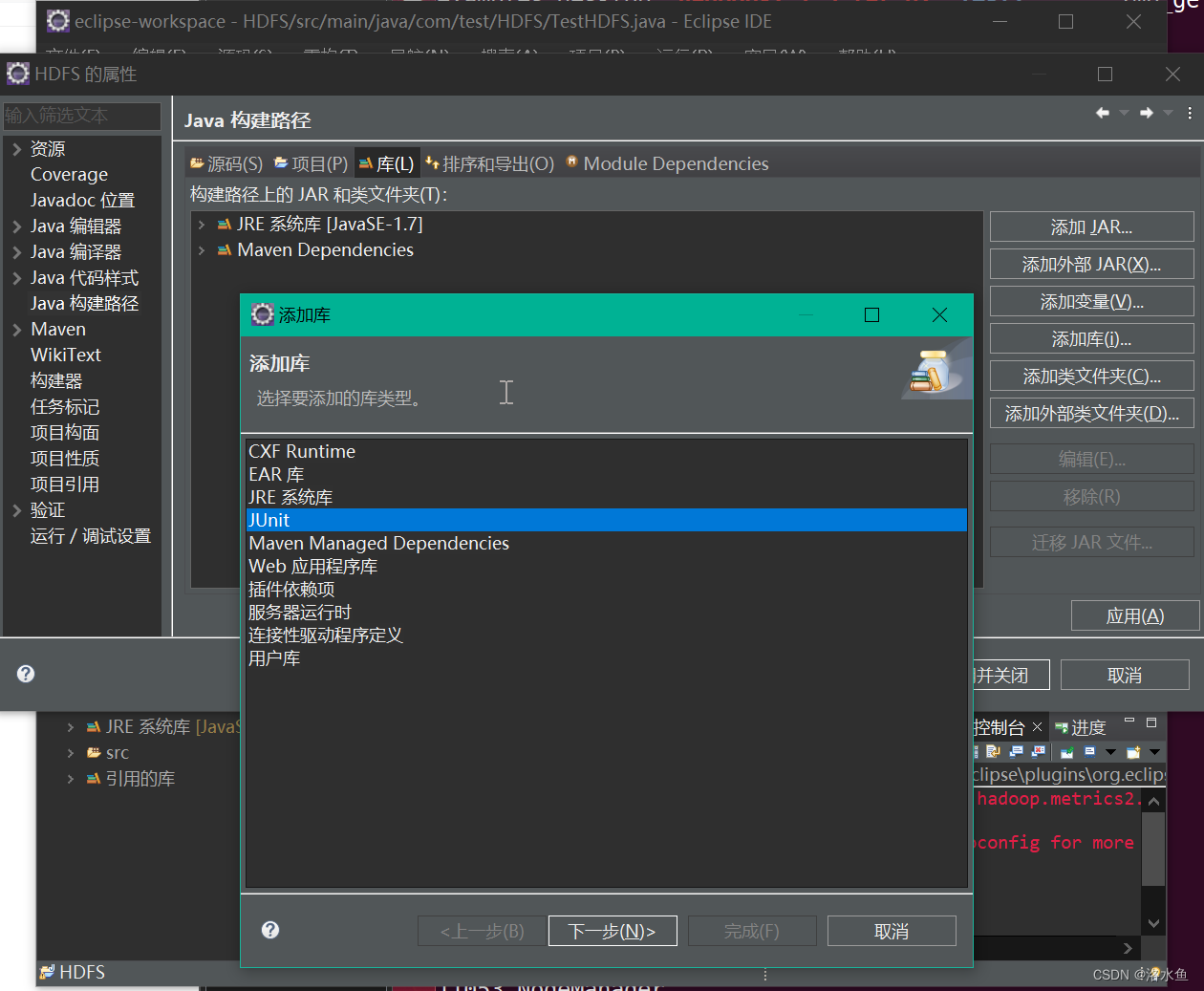
实验内容 项目4-1 单元测试mkdir
根据前面@Before的注释,先选择hd账号创建/lab2目录
4.实验内容 项目4-1 单元测试mkdir
【结果】
4.实验内容 项目4-1 单元测试mkdir
【结果】
4.实验内容 项目4-1 单元测试mkdir
根据前面@Before的注释,更改账号为ubuntu,执行命令报错
注意,打印语句在报错之前,所以信息仍然是:“目录已存在,将删除后重建”
错误调用栈信息比较多,在下一页展示,可以看到权限错误
4.实验内容 项目4-1 单元测试mkdir
4.实验内容 项目4-1 单元测试mkdir
4.实验内容 项目4-1 单元测试mkdir
实验内容 项目4-2 单元测试upload
4.实验内容 项目4-2 单元测试upload
实验内容 项目4-3 单元测试blocks
4.实验内容 项目4-3 单元测试blocks
4.实验内容 项目4-3 单元测试blocks
4.实验内容 项目4-3 单元测试blocks
4.实验内容 项目4-3 单元测试blocks
4.实验内容 项目4-3 单元测试blocks

