
- 1ABAP function module 的使用_abap module
- 2FPN(特征金字塔)-pytorch实践
- 3Hadoop 大数据生态框架--总述_数字生态系统的架构图
- 4element 项目全屏功能_elementplus全屏
- 5无线远距离WiFi模块图传技术,无人机智能安防预警应用_无线远距离图传
- 6SnailSVN Pro Mac:功能强大的SVN客户端,助您高效管理代码版本控制_mac svn客户端
- 7基于Matlab的无人船局部避碰算法仿真平台_无人船控制仿真程序
- 8论文笔记:Retrieval-Augmented Generation forAI-Generated Content: A Survey_retrieval-augmented generation for ai-generated co
- 9PO模式
- 10Dataphin核心功能(四):安全——基于数据权限分类分级和敏感数据保护,保障企业数据安全_开源数据安全管理
时间序列 工具库学习(1) tsfresh特征提取、特征选择
赞
踩
1. 更新清单:
2022.01.07:初次更新文章
2. 了解、安装tsfresh
tsfresh 可以自动计算大量的时间序列特性,包含许多特征提取方法和强大的特征选择算法。tsfresh 用于从时间序列和其他序列数据[1] 中进行系统特征工程。这些数据的共同点是它们按自变量排序。最常见的自变量是时间(时间序列)。
有一个名为hctsa的 matlab 包,可用于从时间序列中自动提取特征。也可以通过pyopy 包在 Python 中使用 hctsa 。其他可用的打包程序是featuretools、FATS和cesium。
pip install tsfresh
- 1
tsfresh官网: https://tsfresh.readthedocs.io/en/latest/index.html
tsfresh 用于从时间序列和其他序列数据[1] 中进行系统特征工程。这些数据的共同点是它们按自变量排序。最常见的自变量是时间(时间序列)。如果没有 tsfresh,将不得不手动计算所有这些特征;tsfresh 自动计算并自动返回所有这些特征。此外,tsfresh 与 Python 库pandas和兼容scikit-learn。
目前,tsfresh 不适合:
- 用于流式数据(流式数据是指通常用于在线操作的数据,而时间序列数据通常用于离线操作)
- 在提取的特征上训练模型(我们不想重新发明轮子,要训练机器学习模型,请查看 Python 包 scikit-learn)
- 用于高度不规则的时间序列;tsfresh 仅使用时间戳对观察结果进行排序,而许多特征与区间无关(例如,峰值的数量)并且可以为任何序列确定,其他一些特征(例如,线性趋势)假设时间间隔相等,当这个假设不成立时应谨慎使用。
3.快速使用案例【官网案例】
得到了一个包含[1] 中讨论的机器人故障的数据集。该数据集记录了 88 次机器人执行(每个机器人执行次数id在 1 到 88 之间是唯一的),它是机器人执行是否失败数据集的一个子集。为简单起见,我们仅区分成功执行和失败执行 ( y)。对于由不同 id 表示的每个样本,将分类机器人是否报告失败。从机器学习的角度来看,目标是对每组时间序列进行分类。
%matplotlib inline
import matplotlib.pylab as plt
from tsfresh import extract_features, extract_relevant_features, select_features
from tsfresh.utilities.dataframe_functions import impute
from tsfresh.feature_extraction import ComprehensiveFCParameters
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(1)加载数据集
对于每次执行,给出了 15 个力 (F) 和扭矩 (T) 样本,这些样本是在固定的时间间隔内针对空间维度 x、y 和 z 进行测量的。因此,数据帧的每一行都引用了一个特定的执行 ( id)、一个时间索引 ( index) 并记录了 6 个传感器的各自测量值 ( F_x、F_y、F_z、T_x、T_y、T_z)。(另外,可以看到y中id为1~5的报告是没有报告失败的【为True】)
from tsfresh.examples import robot_execution_failures
robot_execution_failures.download_robot_execution_failures()
df, y = robot_execution_failures.load_robot_execution_failures()
print(df)
print(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7


绘制一些示例 执行成功与 执行失败:
df[df.id == 3][['time', 'F_x', 'F_y', 'F_z', 'T_x', 'T_y', 'T_z']].plot(x='time', title='Success example (id 3)', figsize=(12, 6));
df[df.id == 20][['time', 'F_x', 'F_y', 'F_z', 'T_x', 'T_y', 'T_z']].plot(x='time', title='Failure example (id 20)', figsize=(12, 6));
- 1
- 2

已经可以通过肉眼看到一些差异 - 但是为了成功的机器学习,必须将这些差异转化为数字。为此, tsfresh 应运而生,它为每个机器人从这六个不同的时间序列中自动提取 多个特征。
最终得到的DataFrame extracted_features包含超过1200个不同的提取特征。现在,我们将首先删除所有的NaN值(这些值是由特征计算器创建的,不能用于给定的数据,例如,因为统计数据过低),然后只选择相关的特征。
(1)提取特征
① 函数调用方式:
from tsfresh import extract_features
extracted_features = extract_features(df, column_id="id", column_sort="time")
- 1
- 2
②使用:
extraction_settings = ComprehensiveFCParameters()
X = extract_features(df, column_id='id', column_sort='time',
default_fc_parameters=extraction_settings,
# impute就是自动移除所有NaN的特征
impute_function=impute)
X.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
X现在包含每个机器人执行(= id)的单行,所有特征tsfresh都是根据该id的测量时间序列值计算出来的。

查看特征提取之后原始特征变为了哪些特征:
print(X.columns)
len(X)
- 1
- 2

可见进行特征提取之后,数据量多了,因为原始和特征函数有不同的组装方式,使用数据量多了。
(2)选择特征
仅从这个大型数据集中选择相关特征。Tsfresh将对每一个特征进行假设检验,以检查它是否与给定的目标相关。
X_filtered = select_features(X, y)
X_filtered.head()
- 1
- 2

进行特征提取、特征选择之后,查看数据信息:
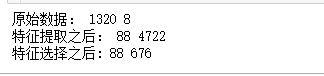
#第二个数值是有多少个特征(列),第一个数值是有多少行
print("原始数据:",len(df),len(df.columns))
print("特征提取之后:",len(X),len(X.columns))
print("特征选择之后:",len(X_filtered),len(X_filtered.columns))
- 1
- 2
- 3
- 4
(3)提取特征并选择特征
from tsfresh import select_features
from tsfresh.utilities.dataframe_functions import impute
extraction_settings = ComprehensiveFCParameters()
X = extract_features(df, column_id='id', column_sort='time',
default_fc_parameters=extraction_settings,
# we impute = remove all NaN features automatically
impute_function=impute)
impute(X)
features_filtered = select_features(X, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

只有大约600个特征被归类为足够相关。
(4)同时特征提取、选择、过滤
此外,甚至可以使用以下tsfresh.extract_relevant_features()功能同时执行提取、选择( imputing)和过滤 。
from tsfresh import extract_relevant_features
features_filtered_direct = extract_relevant_features(df, y,
column_id='id', column_sort='time')
- 1
- 2
- 3
- 4

具体案例:
X_filtered_2 = extract_relevant_features(df, y, column_id='id', column_sort='time',
default_fc_parameters=extraction_settings)
#下面返回True
(X_filtered.columns == X_filtered_2.columns).all()
- 1
- 2
- 3
- 4
(5)训练模型评估模型*
让我们在过滤后的以及提取的全部特征集上训练一个增强的决策树。
拆分数据集:
X_full_train, X_full_test, y_train, y_test = train_test_split(X, y, test_size=.4)
# 进行特征选择(也可以直接使用特征选择后的数据而不用到这里再选择)
X_filtered_train, X_filtered_test = X_full_train[X_filtered.columns],X_full_test[X_filtered.columns]
- 1
- 2
- 3
- 4
没进行选择特征之前 训练评估模型:
classifier_full = DecisionTreeClassifier()
classifier_full.fit(X_full_train, y_train)
print(classification_report(y_test, classifier_full.predict(X_full_test)))
- 1
- 2
- 3
打印查看输入的X和输入的Y:
X_full_train
- 1

y_train
- 1

进行选择特征之后 训练评估模型:
classifier_filtered = DecisionTreeClassifier()
classifier_filtered.fit(X_filtered_train, y_train)
print(classification_report(y_test, classifier_filtered.predict(X_filtered_test)))
- 1
- 2
- 3
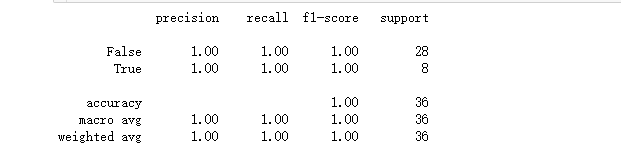
相比于使用所有特征(classifier_full),仅使用相关特征(classifier_filtered)实现以较少的数据获得更好的分类性能。
(6)注意!关于训练方式,不止一种。
①直接输入特征X和标签Y进行训练
这种方式就像上面(5)这种。
②输入索引映射和设置PPL的set_params进行训练
步骤描述:
- 加载数据
- 获取y的index为Dataframe。
- 拆分数据集
- 创建Pipeline
- 设置pipeline的时间序列容器为训练集
- 输入包含index 【训练集上】的空dataframe和y 进行 训练模型,评估训练集,并画出训练集拟合曲线
- 设置pipeline的时间序列容器为测试集,输入包含index【测试集上】 的空dataframe和y 进行 评估模型,评估测试集,并画出测试集的曲线
- 对于预测未来,每预测一次未来,将预测值加入训练集然后重复上面操作。【此外,预测未来的时候不应该有测试集,因为所有的数据都留给训练集的话有助于模型拟合,毕竟测试集的结果对于时间序列来说啥也不是】
案例:
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from tsfresh.examples import load_robot_execution_failures
from tsfresh.transformers import RelevantFeatureAugmenter
from tsfresh.utilities.dataframe_functions import impute
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures
download_robot_execution_failures()
df_ts, y = load_robot_execution_failures()
X = pd.DataFrame(index=y.index)
# Split data into train and test set
X_train, X_test, y_train, y_test = train_test_split(X, y)
#构建管道
ppl = Pipeline([
('augmenter', RelevantFeatureAugmenter(column_id='id', column_sort='time')),
('classifier', RandomForestClassifier())
])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
使用这种方式下,在面对训练集、测试集的时候也有两种方法:
第一种训练评估方法:一次性声明时间序列容器
#声明时间序列容器
ppl.set_params(augmenter__timeseries_container=df_ts);
ppl.fit(X_train, y_train)
# 测试集评估
y_pred = ppl.predict(X_test)
print(classification_report(y_test, y_pred))
- 1
- 2
- 3
- 4
- 5
- 6
第二种训练评估方法:分别声明训练集、测试集的 时间序列容器
#分别获取训练集、测试集的数据索引
df_ts_train = df_ts[df_ts["id"].isin(y_train.index)]
df_ts_test = df_ts[df_ts["id"].isin(y_test.index)]
# 设置 时间序列容器为训练集,并训练模型
ppl.set_params(augmenter__timeseries_container=df_ts_train);
#关键一步:输入训练集的数据索引作为X,输入y标签作为Y进行训练。期间索引会在管道里面找到df_ts_train的数据。
ppl.fit(X_train, y_train);
import pickle
with open("pipeline.pkl", "wb") as f:
pickle.dump(ppl, f)
# 设置 时间序列容器为测试集,并测试评估模型;【如无模型,先加载模型】
import pickle
with open("pipeline.pkl", "rb") as f:
ppk = pickle.load(f)
ppl.set_params(augmenter__timeseries_container=df_ts_test);
# 关键一步:输入测试集的数据索引作为X进行预测标签y
y_pred = ppl.predict(X_test)
print(classification_report(y_test, y_pred))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4. tsfresh的输入输出
Tsfresh提供了三种不同的选项来指定用于函数Tsfresh .extract_features()的时间序列数据格式。(当然,包括所有需要时间序列的实用函数,例如tsfresh.utilities.dataframe_functions.roll_time_series())
(1)输入输出简述
通常,输入格式选项是pandas的DataFrame对象,还有Dask DataFrame 和PySpark计算图,在这里讨论如何输入大的数据。
不管输入格式如何,tsfresh都将以下面描述的相同输出格式返回计算出的特征。
有四种重要的列类型(函数的参数)组成了这些数据帧。将用一个机器人故障数据集(参见这里)中的例子来描述每一个参数。
- column_id : 此列指示时间序列属于哪些实体。将为每个实体 (id) 单独提取特征。生成的特征矩阵将包含每个 id 的一行。每个机器人都是不同的实体,因此每个机器人都有不同的 id。
- column_sort: 此列包含允许对时间序列进行排序的值(例如时间戳)。通常,对于不同的 id 和/或种类,不需要具有等距的时间步长或相同的时间尺度。然而,某些功能可能只对等距时间戳有意义。如果省略此列,则假定 DataFrame 已按升序排序。每个机器人传感器测量值都有一个时间戳,用作column_sort。
- column_value: 此列包含时间序列的实际值。这对应于机器人上不同传感器的测量值。
- column_kind: 此列指示不同时间序列类型的名称(例如,工业应用中的不同传感器,如机器人数据集中)。对于每种时间序列,特征都是单独计算的。
重要提示:这些列都不允许包含NaN、Inf或-Inf值。
基于这些列构建的不同输入格式:
- 一个扁平的 DataFrame
- 堆叠的 DataFrame
- 平面数据帧字典
扁平DataFrame和堆叠DataFrame之间的区别是通过在tsfresh.extract_features()函数中指定(或不指定)参数column_value和column_kind来表示的。如果不确定选择哪一个,可以尝试扁平或堆叠的DataFrame。
(2)输入选项 1. Flat DataFrame 或 Wide DataFrame
如果column_value和column_kind都设置为None,则假定时间序列数据在一个平面DataFrame中。这意味着每个不同的时间序列必须保存为自己的列。
例如:假设为不同的对象A和B记录时间序列x和y的值,记录三个不同的时间t1、t2和t3。得到的DataFrame可能如下所示:

想用tsfresh计算一些特征,使用:
column_id="id", column_sort="time", column_kind=None, column_value=None
- 1
对于提取函数,对所有id分别提取特征,对x值和y值分别提取特征。也可以省略column_kind=None, column_value=None,因为这是默认值。
(3)输入选项 2. Stacked DataFrame 或 Long DataFrame
如果同时设置了column_value和column_kind,则假定时间序列数据是堆叠的 DataFrame。这意味着不同类型的时间序列没有不同的列。这种表示比平面数据帧有几个优点。例如,不同时间序列的时间戳不必对齐。
它不包含针对不同类型时间序列的不同列,而仅包含一个值列和一个种类列。按照我们之前的示例,数据框将如下所示:

该输入选项的方式是设置参数:
column_id="id", column_sort="time", column_kind="kind", column_value="value"
- 1
最终得到相同的特征。也可以省略value列,让tsfresh自动推断它。
(4)输入选项 3. 平面数据帧字典
不是传递一个DataFrame,它必须被tsfresh按其不同的类型分割,也可以给出一个字典映射,从一个字符串的种类到一个DataFrame只包含时间序列的那种类型的数据。所以本质上,对每一种时间序列都使用单一的DataFrame。
示例中的数据可以被拆分为两个DataFrames,结果产生以下字典:

可以将这个字典和以下参数一起传递给tsfresh:
column_id="id", column_sort="time", column_kind=None, column_value="value"
- 1
在本例中,我们不需要指定kind列,因为kind是各自的字典键。
(5)输出格式
所得到的特征矩阵(包含提取的特征)对于所有三个输入选项都是相同的。它将永远是一个pandas DataFrame的格式,如下:

其中x特征使用所有x值计算(分别用于A和B), y特征使用所有y值计算(分别用于A和B),以此类推。这个DataFrame也是tsfresh(例如tsfresh.select_features()函数)所使用的特征选择算法的预期输入格式。
5. tsfresh与 scikit-learn 兼容的转换器(Transformers)
tsfresh 包括三个与 scikit-learn 兼容的转换器,它们可以轻松地将时间序列的特征提取和特征选择合并到现有的机器学习管道中。
scikit-learn 管道允许组装几个将按顺序执行的预处理步骤,因此可以在设置不同参数的同时交叉验证(有关 scikit-learn 管道的更多详细信息,请查看官方文档[1])。tsfresh 转换器允许在这些预处理序列中提取和过滤时间序列特征。
tsfresh中的前两个估计器是 feature augmenter(提取特征) 和 FeatureSelector(执行特征选择算法) 。为了避免不必要的特征计算,最好将特征的提取和过滤结合在一步之内进行。因此,RelevantFeatureAugmenter将特征的提取和过滤结合在一个步骤中。
(1)快速使用
将 tsfresh RelevantFeatureAugmenter和 a 组合 RandomForestClassifier到单个管道中。然后,该管道可以在一个步骤中同时适合我们的转换器和分类器。
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from tsfresh.examples import load_robot_execution_failures
from tsfresh.transformers import RelevantFeatureAugmenter
import pandas as pd
# 下载数据集
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures
download_robot_execution_failures()
pipeline = Pipeline([
('augmenter', RelevantFeatureAugmenter(column_id='id', column_sort='time')),
('classifier', RandomForestClassifier()),
])
# df_ts是输入的x的dataframe,y是标签
df_ts, y = load_robot_execution_failures()
#这个X是记录了id
X = pd.DataFrame(index=y.index)
#设置参数
pipeline.set_params(augmenter__timeseries_container=df_ts)
pipeline.fit(X, y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
RelevantFeatureAugmenter的参数对应于顶级便利函数extract_relevant_features()的参数。 在上面的例子中,我们只设置了两个列的名称column_id=‘id’, column_sort=‘time’(有关这些参数的详细信息,请参阅数据格式)。
因为在对sklearn.pipeline.Pipeline 调用fit或transform时,不能将时间序列容器直接作为参数传递给增广步骤。必须通过调用pipeline.set_params(augmenter__timeseries_container=df_ts) 手动设置它。
通常,可以通过调用管道的set_params()方法或transformer的set_timeseries_container()方法来更改提取特征的时间序列容器。
(2)完整案例
导库:
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from tsfresh.examples import load_robot_execution_failures
from tsfresh.transformers import RelevantFeatureAugmenter
from tsfresh.utilities.dataframe_functions import impute
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
加载数据拆分数据集:
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures
download_robot_execution_failures()
df_ts, y = load_robot_execution_failures()
- 1
- 2
- 3
想使用提取的特征来预测每个机器人执行是否失败。因此,我们的基本“实体”是由不同的id.需要为管道准备一个以这些标识符作为索引的数据帧。
X = pd.DataFrame(index=y.index)
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
- 1
- 2
- 3
- 4
构建管道:
构建了一个sklearn管道,该管道由一个特征提取步骤(RelevantFeatureAugmenter)和一个后续的RandomForestClassifier组成。RelevantFeatureAugmenter接受与extract_features和select_features大致相同的参数。
在这种情况下,df_ts包含了训练集和测试集的时间序列,如果有不同的训练集和测试集的数据帧,必须调用set_params两次(见下文)
ppl = Pipeline([
('augmenter', RelevantFeatureAugmenter(column_id='id', column_sort='time')),
('classifier', RandomForestClassifier())
])
ppl.set_params(augmenter__timeseries_container=df_ts)
- 1
- 2
- 3
- 4
- 5
训练模型:
扩展器使用输入的时间序列数据提取X_train中每个标识符的时间序列特征,并使用传递的y_train作为目标,只选择相关的标识符。这些特性已经作为新列添加到X_train中。分类器现在可以在训练中使用这些特征。
ppl.fit(X_train, y_train)
- 1
评估预测:
在(干扰)拟合过程中,增强器只提取训练阶段发现的相关特征,分类器利用这些特征预测目标。
y_pred = ppl.predict(X_test)
print(classification_report(y_test, y_pred))
- 1
- 2
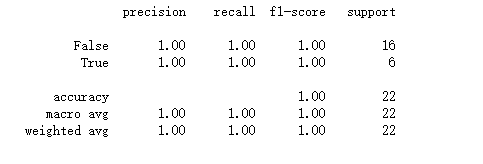
还可以找出,哪些列的扩展器已选择: ppl.named_steps["augmenter"].feature_selector.relevant_features
(3)评估预测测试集的时候需要调用两次ppl
在上面的示例中,我们将单个df_ts传入RelevantFeatureAugmenter用于训练和预测。在训练期间,仅提取带有id的数据,X_train而在预测期间则提取其余数据。
但是,调用set_params两次完全没有问题:一次在训练之前,一次在预测之前。例如,如果将经过训练的管道转储到磁盘并仅在稍后将其重新用于预测时,这会很方便。只需要确保id在训练/预测期间使用的实体的s 实际存在于传递的时间序列数据中。
df_ts_train = df_ts[df_ts["id"].isin(y_train.index)]
df_ts_test = df_ts[df_ts["id"].isin(y_test.index)]
df_ts_train,y_train.index
- 1
- 2
- 3
- 4

设置该时间容器存放的是训练集:
ppl.set_params(augmenter__timeseries_container=df_ts_train);
ppl.fit(X_train, y_train);
import pickle
with open("pipeline.pkl", "wb") as f:
pickle.dump(ppl, f)
- 1
- 2
- 3
- 4
- 5
- 6
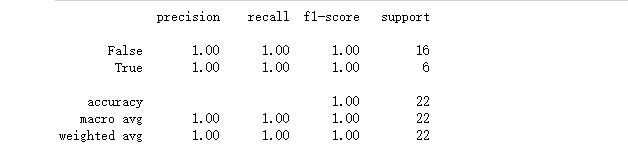
加载模型,设置该时间容器存放的是测试集:
import pickle
with open("pipeline.pkl", "rb") as f:
ppk = pickle.load(f)
ppl.set_params(augmenter__timeseries_container=df_ts_test);
y_pred = ppl.predict(X_test)
print(classification_report(y_test, y_pred))
- 1
- 2
- 3
- 4
- 5
- 6
6.tsfresh的特征提取方法汇总
tsfresh计算全面的特征数量。所有功能计算器都包含在子模块中:
tsfresh.feature_extraction.feature_calculators 该模块包含将时间序列作为输入并计算特征值的特征计算器。
https://tsfresh.readthedocs.io/en/latest/text/list_of_features.html

7.特征提取设置
当开始一个涉及时间序列的新数据科学项目时,可能希望从提取一组全面的特征开始。稍后可以确定哪些功能与手头的任务相关。在最后阶段,可能希望微调特征参数以微调模型。
(1)default_fc_parameters参数
计算哪些特征由tsfresh包含从特征计算器名称到其参数的映射的字典控制。这本词典叫做fc_parameters. 它将功能计算器名称(= 键)映射到参数(= 值)。字典中的每个键都将作为函数查找tsfresh.feature_extraction.feature_calculators并用于提取特征。
tsfresh附带一些预定义的fc_parameters字典集:
settings.ComprehensiveFCParameters, settings.EfficientFCParameters, settings.MinimalFCParameters
- 1
例如,仅计算极少的特征集:
每个键代表一个功能计算器。值是参数。如果特征计算器没有参数,None则用作值(并且这些特征计算器非常简单,它们都没有参数)
settings_minimal = settings.MinimalFCParameters()
settings_minimal
- 1
- 2
这个字典可以传递给 extract 方法,从而计算出一些基本的时间序列:
通过使用 settings_minimal 作为 default_fc_parameters 参数的值,这些设置可用于所有类型的时间序列。在这种情况下,settings_minimal字典用于“温度”和“压力”时间序列。
X_tsfresh = extract_features(df, column_id="id", default_fc_parameters=settings_minimal)
X_tsfresh.head()
- 1
- 2
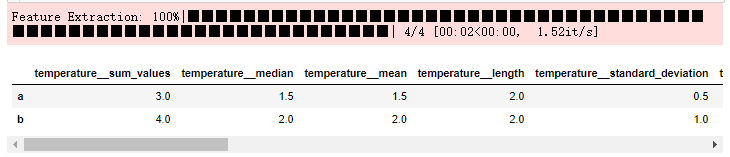
假设要删除长度特征并防止它被计算。只是需要从字典中删除它。
del settings_minimal["length"]
settings_minimal
#现在,如果为这个精简字典提取特征,将不会计算长度特征
X_tsfresh = extract_features(df, column_id="id", default_fc_parameters=settings_minimal)
X_tsfresh.head()
- 1
- 2
- 3
- 4
- 5
- 6
(2)kind_to_fc_parameters参数
现在,假设不想为两种类型的时间序列计算相同的特征。相反,每种类型都应该有不同的功能集。也可以单独控制要为不同种类的时间序列提取的特征。可以通过将另一个字典作为
kind_to_fc_parameters = {“种类”:fc_parameters}
- 1
范围。此 dict 必须是从种类名称(作为字符串)到fc_parameters对象的映射,通常会将其作为参数传递给default_fc_parameters参数。
为此,可以使用kind_to_fc_parameters参数,它可以让我们指定fc_parameters要用于哪种时间序列:
fc_parameters_pressure = {"length": None,
"sum_values": None}
fc_parameters_temperature = {"maximum": None,
"minimum": None}
kind_to_fc_parameters = {
"temperature": fc_parameters_temperature,
"pressure": fc_parameters_pressure
}
print(kind_to_fc_parameters)
X_tsfresh = extract_features(df, column_id="id", kind_to_fc_parameters=kind_to_fc_parameters)
X_tsfresh.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
因此,在这种情况下,对于传感器“pressure”,会计算“max”和“min”。对于“temperature”信号,取而代之的是 length 和 sum_values 特征。
提供的from_columns方法可用于从包含特征的数据框中推断设置字典。然后可以例如存储该字典并在下一次特征提取中使用该字典:
# Assuming `X_tsfresh` contains only our relevant features
relevant_settings = settings.from_columns(X_tsfresh)
relevant_settings
- 1
- 2
- 3
(3)计算所有特征
要计算一组全面的特征,请在tsfresh.extract_features()不传递default_fc_parameters或kind_to_fc_parameters对象的情况下调用该方法。这样,将使用默认选项,这将使用此包中的所有功能计算器,认为默认情况下可以返回。
(4)更复杂的字典
提供fc_parameters具有更大功能集的词典。该EfficientFCParameters包含应该比较快的计算功能和参数:
settings_efficient = settings.EfficientFCParameters()
settings_efficient
- 1
- 2
这ComprehensiveFCParameters是最大的一组功能。计算时间最长:
settings_comprehensive = settings.ComprehensiveFCParameters()
settings_comprehensive
- 1
- 2
①特征计算器的参数
更复杂的特征计算器具有可用于调整提取特征的参数。预定义设置(例如ComprehensiveFCParameters)已经包含这些功能的默认值。但是,对自己的项目,可能想要/需要调整它们。详细地说,fc_parameters字典中的值包含参数字典列表。计算特征时,参数列表中的每个条目将用于计算一个特征。
例如,看一下 feature large_standard_deviation,它取决于一个名为的参数r(它基本上定义了“大”的大小)。在ComprehensiveFCParameters包含了几个默认值r。它们中的每一个都将用于计算单个特征:
settings_comprehensive['large_standard_deviation']
- 1
如果在特征提取中使用这些设置,将触发20个不同的large_standard_deviation特征的计算,其中一个r=0.05到r=0.95。(如果现在想要更改特定功能计算器的参数,所需要做的就是更改字典值)
settings_tmp = {'large_standard_deviation': settings_comprehensive['large_standard_deviation']}
X_tsfresh = extract_features(df, column_id="id", default_fc_parameters=settings_tmp)
X_tsfresh.columns
- 1
- 2
- 3
- 4
(5)非手动创建字典
如果现在想要更改特定功能计算器的参数,所需要做的就是更改字典值。然后,提供了 从这个过滤后的特征矩阵的列名tsfresh.feature_extraction.settings.from_columns()构造kind_to_fc_parameters字典的方法,以确保只提取相关的特征。
这可以节省大量时间,因为可以避免计算不必要的特征。
# X_tsfresh contains the extracted tsfresh features
X_tsfresh = extract_features(...)
# which are now filtered to only contain relevant features
X_tsfresh_filtered = some_feature_selection(X_tsfresh, y, ....)
# we can easily construct the corresponding settings object
kind_to_fc_parameters = tsfresh.feature_extraction.settings.from_columns(X_tsfresh_filtered)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
8.滚动时间预测
使用tsfresh提取的特征可用于许多不同的任务,例如时间序列分类、压缩或预测。
假设有 100 个时间步长的某只股票(例如 Apple)的价格。现在,想要构建一个基于特征的模型来预测 Apple 股票的未来价格。可以删除(今天的)最后一个价格值,并从直到今天的时间序列中提取特征来预测今天的价格。但这只会给一个训练的例子。相反,可以重复此过程:对于股票价格时间序列中的每一天,删除当前值,提取该值之前的时间特征并训练以预测当天的值(已删除)。可以将其视为在已排序的时间序列数据上移动一个剪切窗口:在每个移位步骤中,提取通过剪切窗口看到的数据,以构建一个新的、较小的时间序列并仅在该时间序列上提取特征. 然后继续换档。在tsfresh,在数据上移动剪切窗口以创建更小的时间序列剪切的过程称为滚动。
滚动是一种将单个时间序列转换为多个时间序列的方法,每个时间序列的结束时间都比前一个时间步晚一个(或 n 个)。tsfresh 中实现的滚动实用程序可帮助在此过程中将数据重塑(和滚动)为可以应用常用tsfresh.extract_features()方法的格式。这意味着提取时间序列窗口和特征提取的步骤是分开的。

(1)滚动机制
dataframe:
以 4 或 2 个时间步长(1、2、3、4、8、9)测量了两个不同实体(id 1 和 2)的两个传感器 x 和 y 的值。
import pandas as pd
df = pd.DataFrame({
"id": [1, 1, 1, 1, 2, 2],
"time": [1, 2, 3, 4, 8, 9],
"x": [1, 2, 3, 4, 10, 11],
"y": [5, 6, 7, 8, 12, 13],
})
df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以使用tsfresh.utilities.dataframe_functions.roll_time_series()来获取连续的子时间序列。可以考虑在时间序列数据上滑动一个窗口,并提取可以通过该窗口看到的所有数据。窗口需要调整三个参数:
- max_timeshift:定义窗口最大的大小。提取的时间序列的最大长度为max_timeshift +
1。(它们也可以更小,因为开始时的时间戳具有较少的过去值)。 - min_timeshift:定义每个窗口的最小尺寸。较短的时间序列(通常在开头)将被省略。
- Advanced::rolling_direction:如果想在正(递增排序)或负(递减排序)方向滑动。几乎不需要负方向,因此可能不想更改默认值。此参数的绝对值决定了希望在每个剪切步骤中移动多少。
from tsfresh.utilities.dataframe_functions import roll_time_series
df_rolled = roll_time_series(df, column_id="id", column_sort="time")
- 1
- 2
新数据集仅包含来自旧数据集的值,但具有新的 ID。还time复制了排序列值(在这种情况下)。如果按 分组id,将得到以下部分(或窗口):

现在,可以对滚转的数据执行通常的特征提取过程:
例如 id 的特征(1,3)是使用id=1up to 和包括t=3(so t=1, t=2and t=3)的数据提取的。
from tsfresh import extract_features
df_features = extract_features(df_rolled, column_id="id", column_sort="time")
- 1
- 2

最终将为上面的每个部分生成特性,然后可以使用这些特性训练预测模型。【注意,这里会含有NaN值】
如果想训练一个模型进行预测,tsfresh还提供了函数tsfresh.utilities.dataframe_functions.make_forecasting_frame(),可以帮助你正确匹配目标向量。

9.多类[多分类、选择多个有效特征]选择案例
在多类分类示例中从时间序列中提取和选择有用的特征。该数据集由 7352 个加速度计读数的时间序列组成。每个读数代表一个加速度计读数,在 50hz 下持续 2.56 秒(每个读数总共 128 个样本)。此外,每次阅读都对应六种活动之一(步行、上楼、下楼、坐、站和躺)。
(1)数据处理
%matplotlib inline
import matplotlib.pylab as plt
from tsfresh import extract_features, extract_relevant_features, select_features
from tsfresh.utilities.dataframe_functions import impute
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载数据:
from tsfresh.examples.har_dataset import download_har_dataset, load_har_dataset, load_har_classes
# fetch dataset from uci
download_har_dataset()
df = load_har_dataset()
y = load_har_classes()
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
到目前为止,数据不是典型的时间序列格式:列是时间步长,而每一行是对不同人的度量。因此,我们将其转化为一种格式,在这种格式中,不同的人的时间序列由一个id标识,并按时间垂直顺序排列。
df["id"] = df.index
df = df.melt(id_vars="id", var_name="time").sort_values(["id", "time"]).reset_index(drop=True)
df.head()
- 1
- 2
- 3
- 4
可视化:
plt.title('accelerometer reading')
plt.plot(df[df["id"] == 0].set_index("time").value)
plt.show()
- 1
- 2
- 3
(2)特征抽取
只使用前700个id来操作,加快处理速度
# only use the first 700 ids to speed up the processing
X = extract_features(df[df["id"] < 700], column_id="id", column_sort="time", impute_function=impute)
X.head()
- 1
- 2
- 3
- 4

(3)训练和评估分类器
拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y[:700], test_size=.2)
- 1
classifier_full = DecisionTreeClassifier()
classifier_full.fit(X_train, y_train)
print(classification_report(y_test, classifier_full.predict(X_test)))
- 1
- 2
- 3

(4)多类特征选择
现在,将使用tsfresh select features方法选择相关特征的子集。然而,它只适用于二元分类或回归任务。
对于一个6个标签的多分类,因此将选择问题分割成6个二进制的一个-而不是所有的分类问题。对于它们中的每一个,可以做一个二元分类特征选择
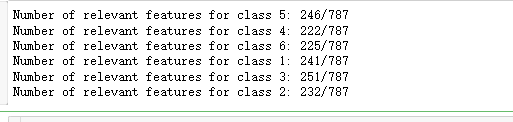
relevant_features = set()
for label in y.unique():
y_train_binary = y_train == label
X_train_filtered = select_features(X_train, y_train_binary)
print("Number of relevant features for class {}: {}/{}".format(label, X_train_filtered.shape[1], X_train.shape[1]))
relevant_features = relevant_features.union(set(X_train_filtered.columns))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对于训练集和测试集,只保留上面选择的那些特征,然后再次训练,通过去除不相关的特征来提高精度。
X_train_filtered = X_train[list(relevant_features)]
X_test_filtered = X_test[list(relevant_features)]
classifier_selected = DecisionTreeClassifier()
classifier_selected.fit(X_train_filtered, y_train)
print(classification_report(y_test, classifier_selected.predict(X_test_filtered)))
- 1
- 2
- 3
- 4
- 5
- 6

(5)改进的多类特征选择
为了通过筛选过程,可以指定一个特征应该作为相关预测器的类的数量。这与将multiclass参数设置为True和将n_significant设置为所需的类数量一样简单。将尝试与5类相关的要求。可以看到相关功能的数量比之前的实现要少。
X_train_filtered_multi = select_features(X_train, y_train, multiclass=True, n_significant=5)
print(X_train_filtered_multi.shape)
classifier_selected_multi = DecisionTreeClassifier()
classifier_selected_multi.fit(X_train_filtered_multi, y_train)
X_test_filtered_multi = X_test[X_train_filtered_multi.columns]
print(classification_report(y_test, classifier_selected_multi.predict(X_test_filtered_multi)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

10.时序预测案例1:一只股票的预测
将使用 Apple 的股票价格。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from tsfresh import extract_features, select_features
from tsfresh.utilities.dataframe_functions import roll_time_series, make_forecasting_frame
from tsfresh.utilities.dataframe_functions import impute
try:
import pandas_datareader.data as web
except ImportError:
print("You need to install the pandas_datareader. Run pip install pandas_datareader.")
from sklearn.linear_model import LinearRegression
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(1)获取数据
从“stooq”下载数据,只存储高值。请注意:此笔记本用于展示tsfresh特征提取 - 不是预测股市价格
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

