
- 1力扣-217. 存在重复元素
- 2Python Django Pycharm 创建并运行django项目_pycharm 运行django
- 32023华为OD面试手撕真题【最大子数组和】_华为 代码题
- 4《从零开始搭建游戏服务器》 java与C#的protobuf序列化不兼容_java 的 proto 文件 c# 能不能正常使用
- 5等保测评是什么
- 6红黑树(含图解和代码参考)_红黑树结构代码
- 7flutter开发中一直Running Gradle task ‘assembleDebug‘...的解决办法
- 8Golang-Gin Response 统一返回restful格式的数据
- 9Win32 API
- 10SD-LORA模型训练及SDXL-lora模型训练基础加进阶教程_lora基础及sdxl-lora进阶模型训练教程
Python数据挖掘-NLTK文本分析+jieba中文文本挖掘_python nltk jieba
赞
踩
一、NLTK介绍及安装
(注:更多资源及软件请W信关注“学娱汇聚门”)
1.1 NLTK安装
NLTK的全称是natural language toolkit,是一套基于python的自然语言处理工具集。
nltk的安装十分便捷,只需要pip就可以。相对Python2版本来说,NLTK更支持Python3版本。
pip install nltk在nltk中集成了语料与模型等的包管理器,通过在python解释器中执行
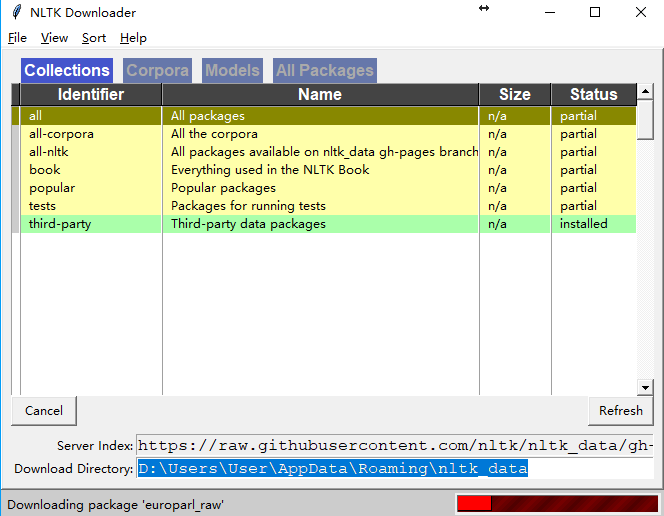
- >>> import nltk
- >>> nltk.download()
便会弹出下面的包管理界面,在管理器中可以下载语料,预训练的模型等。
1.2 NLTK功能介绍
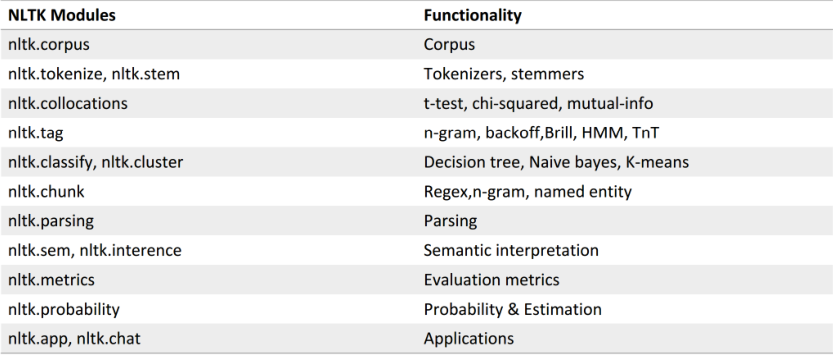
NLTK功能模块一览表:
NLTK⾃带语料库介绍:
- >>>from nltk.corpus import brown
- >>>brown.categories()
- ['adventure', 'belles_lettres', 'editorial',
- 'fiction', 'government', 'hobbies', 'humor',
- 'learned', 'lore', 'mystery', 'news', 'religion',
- 'reviews', 'romance', 'science_fiction']
- >>>len(brown.sents())
- 57340
- >>>len(brown.words())
- 1161192
Tokenize:把句子分一个个的小部件,如下例:
- >>> import nltk
- >>> sentence = “hello, world"
- >>> tokens = nltk.word_tokenize(sentence)
- >>> tokens
- ['hello', ‘,', 'world']
- from nltk.tokenize import word_tokenize
- tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm'
- print(word_tokenize(tweet))
- # ['RT', '@', 'angelababy', ':', 'love', 'you', 'baby', '!', ':',
- # ’D', 'http', ':', '//ah.love', '#', '168cm']
1.3 nltk.text类介绍:
nltk.text.Text()类用于对文本进行初级的统计与分析,它接受一个词的列表作为参数。Text类提供了下列方法。
| 方法 | 作用 |
|---|---|
| Text(words) | 对象构造 |
| concordance(word, width=79, lines=25) | 显示word出现的上下文 |
| common_contexts(words) | 显示words出现的相同模式 |
| similar(word) | 显示word的相似词 |
| collocations(num=20, window_size=2) | 显示最常见的二词搭配 |
| count(word) | word出现的词数 |
| dispersion_plot(words) | 绘制words中文档中出现的位置图 |
| vocab() | 返回文章去重的词典 |
nltk.text.TextCollection类是Text的集合,提供下列方法
| 方法 | 作用 |
|---|---|
| nltk.text.TextCollection([text1,text2,]) | 对象构造 |
| idf(term) | 计算词term在语料库中的逆文档频率,即log总文章数文中出现term的文章数 |
| tf(term,text) | 统计term在text中的词频 |
| tf_idf(term,text) | 计算term在句子中的tf_idf,即tf*idf |
二、中文分词简介
中文分词资料:
- 结巴分词的github主页
- https://github.com/fxsjy/jieba
- 基于python的中文分词的实现及应用
- http://www.cnblogs.com/appler/archive/2012/02/02/2335834.html
- 对Python中⽂分词模块结巴分词算法过程的理解和分析
- http://ddtcms.com/blog/archive/2013/2/4/69/jieba-fenci-suanfa-lijie/
- Penn Chinese Treebank Tag Set
- http://blog.csdn.net/neutblue/article/details/7375085
我们使用结巴分词(安装结巴库文件):pip install jieba
- import ntlk
- import jieba
- raw=open(u'../data/昆仑全本.txt',encoding='gb18030',errors='ignore').read()
- text=nltk.text.Text(jieba.lcut(raw))
- 以下为测试
- >>>print(text.concordance(u'阿雪')) #对于本小说,先看下女三主悲情姑娘阿雪出现的情况
-
- >>>print(text.vocab())
-
- >>>print(text.common_contexts([u'一起',u'一同'])) #下面看下文章常用的二词搭配
- output: 你_死
- >>>text.dispersion_plot([u'阿雪',u'柳莺莺',u'晓霜']) #查看三位女主出现的位置,发现第二位女主居然没有,很奇怪,可能她的名字被拆了吧。
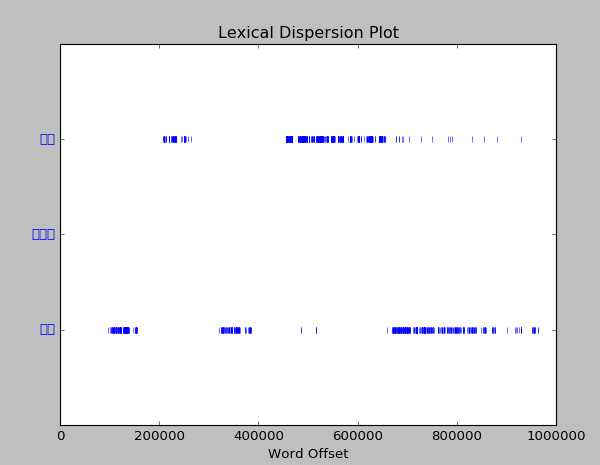
于是我们抽取全书排名前20的关键词,发现的确'柳莺莺'被切分成了'柳莺'这个词:
- import nltk
- import jieba.analyse
-
- raw=open(u'../data/昆仑全本.txt',encoding='utf-8',errors='ignore').read()
- a=jieba.analyse.extract_tags(raw, topK=20, withWeight=False, allowPOS=())
- print(a)
- ['梁萧', '柳莺', '云殊', '花晓霜', '文靖', '萧千绝', '阿雪', '二人', '一声', '忽地', '公羊', '武功',
- '众人', '陀罗', '心头', '晓霜', '秦伯符', '花生', '心中', '梁萧道']
3 Python结巴分词
3.1结巴分词介绍
“结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库。
- 备注:本部分取《昆仑》一书第一段第一句,即文件“昆仑全本.txt”只有:
-
- 大巴山脉,西接秦岭,东连巫峡,雄奇险峻,天下知名。山中道路又陡又狭,深沟巨壑,随处可见;其惊险之处,真个飞鸟难度,猿猱驻足,以李太白之旷达,
- 行经此地,也不禁长叹:“蜀道难,难于上青天。”
3.2 JIEBA分词
1、jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用
HMM 模型;
2、jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细;
3、待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8 ;
4、jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut 以及 jieba.lcut_for_search 直接返回 list ;
5、jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
- #coding=utf-8
- import jieba,math
- import jieba.analyse
-
- #jieba.cut主要有三种模式
- #随便对一个动物园的评论进行分析
- str_text=open(u'../data/昆仑全本.txt',encoding='utf-8',errors='ignore').read()
- #全模式cut_all=True
- str_quan1=jieba.cut(str_text,cut_all=True)
- print('全模式分词:{ %d}' % len(list(str_quan1)))
- str_quan2=jieba.cut(str_text,cut_all=True)
- print("$".join(str_quan2))
- # print(str(str_1)) #为一个generator 用for循环可以得到分词的结果
- # str_1_len=len(list(str_1)) #为什么?这里执行后后面.join 就不执行,求告知
-
- #精准模式cut_all=False,默认即是
- str_jing1=jieba.cut(str_text,cut_all=False)
- print('精准模式分词:{ %d}' % len(list(str_jing1)))
- str_jing2=jieba.cut(str_text,cut_all=False)
- print("$".join(str_jing2))
-
- #搜索引擎模式 cut_for_search
- str_soso1=jieba.cut_for_search(str_text)
- print('搜索引擎分词:{ %d}' % len(list(str_soso1)))
- str_soso2=jieba.cut_for_search(str_text)
- print("$".join(str_soso2))
-
- 运行结果:
- 全模式分词:{ 175}
- $$大巴$大巴山$巴山$山脉$$$西$接$秦岭$$$东$连$巫峡$$$雄奇$奇险$险峻$$$天下$知名$$$山中$中道$道路$又$陡$又$狭$$$深沟$巨$壑$$$随处$随处可见$可见$$$其$惊险$之处$$$真个$飞鸟$难度$$$猿$猱$驻足$$$以$李太白$太白$之$旷达$$$行经$此地$$$也$不禁$长叹$$$$蜀道$蜀道难$$$难于$难于上青天$上青$青天$$$$时$维$九月$$$正是$深秋$秋季$季节$$$满山$满山红$枫$似火$$$黄叶$如$蝶$$$一片$斑斓$景象$$$
- $崇山$崇山峻岭$峻岭$之中$$$但见$一条$鸟$道$$$上$依$绝壁$$$下$临$深谷$$$若有若无$若无$$$蜿蜒$向$南$$$一阵$山风$呼啸$呼啸而过$而过$$$掀起$崖$上$枯藤$$$露出$三个$班驳$的$暗红$大字$$$$神仙$度$$$
- 精准模式分词:{ 120}
- $大巴山$脉$,$西接$秦岭$,$东连$巫峡$,$雄奇$险峻$,$天下$知名$。$山中$道路$又$陡$又$狭$,$深沟$巨壑$,$随处可见$;$其$惊险$之$处$,$真个$飞鸟$难度$,$猿$猱$驻足$,$以$李太白$之$旷达$,$行经$此地$,$也$不禁$长叹$:$“$蜀道难$,$难于上青天$。$”$时维$九月$,$正是$深秋$季节$,$满山红$枫$似火$,$黄叶$如蝶$,$一片$斑斓$景象$。$ $
- $崇山峻岭$之中$,$但$见$一条$鸟道$,$上$依$绝壁$,$下临$深谷$,$若有若无$,$蜿蜒$向南$。$一阵$山风$呼啸而过$,$掀起$崖$上$枯藤$,$露出$三个$班驳$的$暗红$大字$:$“$神仙$度$”$.
- 搜索引擎分词:{ 135}
- $大巴$巴山$大巴山$脉$,$西接$秦岭$,$东连$巫峡$,$雄奇$险峻$,$天下$知名$。$山中$道路$又$陡$又$狭$,$深沟$巨壑$,$随处$可见$随处可见$;$其$惊险$之$处$,$真个$飞鸟$难度$,$猿$猱$驻足$,$以$太白$李太白$之$旷达$,$行经$此地$,$也$不禁$长叹$:$“$蜀道$蜀道难$,$难于$上青$青天$难于上青天$。$”$时维$九月$,$正是$深秋$季节$,$满山$满山红$枫$似火$,$黄叶$如蝶$,$一片$斑斓$景象$。$ $
- $崇山$峻岭$崇山峻岭$之中$,$但$见$一条$鸟道$,$上$依$绝壁$,$下临$深谷$,$若无$若有若无$,$蜿蜒$向南$。$一阵$山风$呼啸$而过$呼啸而过$,$掀起$崖$上$枯藤$,$露出$三个$班驳$的$暗红$大字$:$“$神仙$度$”$.

加自定义词库:
jieba.load_userdict(filename) filename为文件路径词典格式和dict.txt一样,一词一行,每行分三个部分(用空格隔开),词语 词频(可省) 词性(可省)顺序不可颠倒,若filename为路径或二进制方式打开,则需为UTF-8。
- 创建“自定义词库.txt”,其内容如下:
- 自定义词库
- 山脉
- 猿猱
- 又陡
- 又狭
运行代码如下:
3.3 JIEBA关键词抽取
3.3.1:基于TF-IDF算法的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- –sentence 为待提取的文本
- –topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- –withWeight 为是否一并返回关键词权重值,默认值为 False
- –allowPOS 仅包括指定词性的词,默认值为空,即不筛选,allowPOS可选地名、时间名、形容词等,词性列表详见:http://blog.csdn.net/u013421629/article/details/74097118
-
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径例题:见上一部分Top20关键词抽取。
3.3.2:基于TextRank算法的关键词提取
TextRank算法基于PageRank,用于为文本生成关键字和摘要.
参考文献:Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
- –基本思想:
- 1,将待抽取关键词的文本进行分词
- 2,以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 3,计算图中节点的PageRank,注意是无向带权图
- 注:各参数列表,见TF-IDF算法
- from jieba import analyse
- # 引入TextRank关键词抽取接口
- textrank = analyse.textrank
-
- # 原始文本
- text=open(u'../data/昆仑全本.txt',encoding='utf-8',errors='ignore').read()
-
- print("\nkeywords by textrank:")
- # 基于TextRank算法进行关键词抽取
- keywords = textrank(text)
- # 输出抽取出的关键词
- for keyword in keywords:
- print(keyword + "/")
-
- 结果:
- 长叹/
- 巫峡/
- 道路/
- 蜀道难/
- 东连/
- 知名/
3.4 JIEBA词频及停用词
3.4.1:词频统计、降序排序
- from jieba import analyse
- import jieba
- # 引入TextRank关键词抽取接口
- textrank = analyse.textrank
-
- # 原始文本
- article=open(u'../data/昆仑全本.txt',encoding='utf-8',errors='ignore').read()
- words = jieba.cut(article, cut_all = False)
- word_freq = {}
- for word in words:
- if word in word_freq:
- word_freq[word] += 1
- else:
- word_freq[word] = 1
- freq_word = []
- for word, freq in word_freq.items():
- freq_word.append((word, freq))
- freq_word.sort(key = lambda x: x[1], reverse = True) #反序排列,根据第二个参数
- max_number = int(input(u"需要前多少位高频词? "))
- for word, freq in freq_word[: max_number]:
- print(word, freq)
-
- 运行:
- 需要前多少位高频词? 6
- , 12 (发现高频词中占用较多的是逗号及句号)
- 又 2
- 。 2
- 之 2
- 道路 1
- 脉 1
3.4.2:自定义停用词集合
本部分文章来源于:http://blog.csdn.net/suibianshen2012/article/details/68927060 中的Part4.3
jieba分词中基于TF-IDF算法抽取关键词以及基于TextRank算法抽取关键词均需要利用停用词对候选词进行过滤。实现TF-IDF算法抽取关键词的类TFIDF和实现TextRank算法抽取关键词的类TextRank都是类KeywordExtractor的子类。而在类KeywordExtractor,实现了一个方法,可以根据用户指定的路径,加载用户提供的停用词集合。
类KeywordExtractor是在jieba/analyse/tfidf.py中实现。
类KeywordExtractor首先提供了一个默认的名为STOP_WORDS的停用词集合。
然后,类KeywordExtractor实现了一个方法set_stop_words,可以根据用户指定的路径,加载用户提供的停用词集合。
可以将extra_dict/stop_words.txt拷贝出来,并在文件末尾两行分别加入“一个”和
“每个”这两个词,作为用户提供的停用词文件,使用用户提供的停用词集合进行关键词抽取的实例代码如下,
- from jieba import analyse
- # 引入TF-IDF关键词抽取接口
- tfidf = analyse.extract_tags
- # 使用自定义停用词集合
- analyse.set_stop_words("stop_words.txt")
-
- # 原始文本
- text = "线程是程序执行时的最小单位,它是进程的一个执行流,\
- 是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,\
- 线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。\
- 线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。\
- 同样多线程也可以实现并发操作,每个请求分配一个线程来处理。"
-
- # 基于TF-IDF算法进行关键词抽取
- keywords = tfidf(text)
- print "keywords by tfidf:"
- # 输出抽取出的关键词
- for keyword in keywords:
- print keyword + "/",
关键词结果为,
- keywords by tfidf:
- 线程/ CPU/ 进程/ 调度/ 多线程/ 程序执行/ 执行/ 堆栈/ 局部变量/ 单位/ 并发/ 分派/ 共享/ 请求/ 最小/ 可以/ 允许/ 分配/ 多个/ 运行/
对比章节2.1中的关键词抽取结果,可以发现“一个”和“每个”这两个词没有抽取出来。
- keywords by tfidf:
- 线程/ CPU/ 进程/ 调度/ 多线程/ 程序执行/ 每个/ 执行/ 堆栈/ 局部变量/ 单位/ 并发/ 分派/ 一个/ 共享/ 请求/ 最小/ 可以/ 允许/ 分配/
实现原理 ,这里仍然以基于TF-IDF算法抽取关键词为例。
前面已经介绍了,jieba/analyse/__init__.py主要用于封装jieba分词的关键词抽取接口,在__init__.py首先将类TFIDF实例化为对象default_tfidf,而类TFIDF在初始化时会设置停用词表,我们知道类TFIDF是类KeywordExtractor的子类,而类KeywordExtractor中提供了一个名为STOP_WORDS的停用词集合,因此类TFIDF在初始化时先将类KeywordExtractor中的STOP_WORDS拷贝过来,作为自己的停用词集合stop_words。
- # 实例化TFIDF类
- default_tfidf = TFIDF()
- # 实例化TextRank类
- default_textrank = TextRank()
-
- extract_tags = tfidf = default_tfidf.extract_tags
- set_idf_path = default_tfidf.set_idf_path
- textrank = default_textrank.extract_tags
-
- # 用户设置停用词集合接口
- def set_stop_words(stop_words_path):
- # 更新对象default_tfidf中的停用词集合
- default_tfidf.set_stop_words(stop_words_path)
- # 更新对象default_textrank中的停用词集合
- default_textrank.set_stop_words(stop_words_path)
如果用户需要使用自己提供的停用词集合,则需要调用analyse.set_stop_words(stop_words_path)这个函数,set_stop_words函数是在类KeywordExtractor实现的。set_stop_words函数执行时,会更新对象default_tfidf中的停用词集合stop_words,当set_stop_words函数执行完毕时,stop_words也就是更新后的停用词集合。我们可以做个实验,验证在调用analyse.set_stop_words(stop_words_path)函数前后,停用词集合是否发生改变。
- from jieba import analyse
- import copy
-
- # 将STOP_WORDS集合深度拷贝出来
- stopwords0 = copy.deepcopy(analyse.default_tfidf.STOP_WORDS)
- # 设置用户自定停用词集合之前,将停用词集合深度拷贝出来
- stopwords1 = copy.deepcopy(analyse.default_tfidf.stop_words)
-
- print stopwords0 == stopwords1
- print stopwords1 - stopwords0
-
- # 设置用户自定停用词集合
- analyse.set_stop_words("stop_words.txt")
- # 设置用户自定停用词集合之后,将停用词集合深度拷贝出来
- stopwords2 = copy.deepcopy(analyse.default_tfidf.stop_words)
-
- print stopwords1 == stopwords2
- print stopwords2 - stopwords1
结果如下所示,
- True
- set([])
- False
- set([u'\u6bcf\u4e2a', u'\u8207', u'\u4e86', u'\u4e00\u500b', u'\u800c', u'\u4ed6\u5011', u'\u6216', u'\u7684', u'\u4e00\u4e2a', u'\u662f', u'\u5c31', u'\u4f60\u5011', u'\u5979\u5011', u'\u6c92\u6709', u'\u57fa\u672c', u'\u59b3\u5011', u'\u53ca', u'\u548c', u'\u8457', u'\u6211\u5011', u'\u662f\u5426', u'\u90fd'])
说明:
- 没有加载用户提供的停用词集合之前,停用词集合就是类KeywordExtractor中的STOP_WORDS拷贝过来的;
- 加载用户提供的停用词集合之后,停用词集合在原有的基础上进行了扩展;
证明了我们的想法。
3.5 JIEBA情感分析
未完待续。
参考:
1、python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库:[置顶] python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库http://blog.csdn.net/hhtnan/article/details/76586693
2、http://blog.csdn.net/suibianshen2012/article/details/68927060
3、http://blog.csdn.net/suibianshen2012/article/details/68927060

