
- 1词嵌入技术(Word Embeddings):算法原理,操作步骤,数学公式,代码实例,详细例子一步一步的说明等_为数据集设计词嵌入方法的步骤
- 2HTTP基本认证(Basic Authentication)的JAVA示例_java http basic authentication
- 3in use 大学英语4word_(完整word版)全新版大学英语第四册综合教程课后翻译答案及课文译文...
- 4Poe!集齐4大 AI 聊天工具的神器,再也不同担心用不上 ChatGPT 了~_poe注册
- 5pandas基础教程:(Dataframe操作/ Series操作/读取CSV文件/读取npy文件/pandas与numpy/数据科学)_dataframe 读取csv
- 622年我在CSDN做到了名利兼收_csdn博客 赚钱
- 7Verilog功能模块——读写位宽不同的同步FIFO_位宽不一样的fifo
- 8【git】从零实现git到github的连接和上传文件(最完整)
- 9secure boot 基本概念和框架
- 10CSDN可以修改发帖内容吗_csdn 发布文章后没办法修改嘛
数据结构——时间复杂度和算法复杂度_复杂度只考虑其导数,不考虑其实际值
赞
踩
目录
时间复杂度
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数(带未知数的函数表达式),时间复杂度不是执行时间(执行时间是有标准的,跟硬件设备有关系)它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
计算下列函数的时间复杂度
时间复杂度函数式:N*N+2*N+10
Func1 执行的基本操作次数 :
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010这里计算清楚该函数在那个量级就行,不必求具体值,上式中后俩项对F(N)的影响很小,
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法(估算个大概)。
这里时间复杂度:O(N^2)
F(N)=2*N+10,2和10对F(N)的影响不大,所以是O(N)
F(N)=M+N,
M远大于N,时间复杂度就是O(M)
N远大于M,时间复杂度就是O(N)
N和M差不多大,时间复杂度就是O(M)或O(N)
N=M,时间复杂度O(2M)或O(2N)


冒泡排序时间复杂度
N个元素, 冒泡排序第一轮比较N-1次
第二轮N-2次
.
.
.
最后一轮1次
1+2+3……+N-1=N*(N-1)/2=F(N)
对F(N)影响最大的一项是N^2/2,所以时间复杂度:O(N^2)
大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法(量级的估算):
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项(对结果产生决定性影响)。
3、如果最高阶项系数存在且不是1,则去除与这个项目相乘的常数(参考上面的冒泡排序和M+N那道题)。得到的结果就是大O阶。
如这道题,用常数1取代运行时间中的所有加法常数,这道题算法复杂度为O(1),O(1)不代表一次,代表常数次
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
strchar函数遍历一个字符串,找某一个字符
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)这道题最好情况:O(1)
平均情况:O(N/2)
最坏情况:O(N)
对于冒泡排序
时间复杂度最坏:O(N^2),
时间复杂度最好:O(N) 这种情况是数组排好序了,遍历了N个元素
时间复杂度不能去数循环,而是要对程序进行分析
这是希尔排序,有三层循环,不能把这个时间复杂度认为是O(N^3),这个排序要比冒泡排序快,这个排序平均下来O(N^1.3),因此我们不能通过循环去确定时间复杂度,要看算法的逻辑进行时间复杂度计算
计算二分查找的时间复杂度,二分查找数组必须是有序的
最好的情况是O(1)
最坏的情况,当找完所有的数后没有找到某元素
二分查找每次会缩放一半的区间,若区间大小为N,第一次在N/2个元素查找,第二次N/2/2,第三次N/2/2/2……=1,以此类推
每查找一次,查找区间的个数减少一班,最后就剩一个值了
假设查找了X次,N=2^X,X=log 2 N(以二为底,N的对数)
X就是时间复杂度O(log 2 N)
时间复杂度为:O(N)
Fac(N)>Fac(N-1)>Fac(N-2)……F(0)
这里总共要调用N次,这里递归了N次,每次是O(1)
对上题做修改后,时间复杂度变为O(N^2)
N+N-1+N-2+N-3......+1
2^0+2^1+2^2+2^3.... +2^(n-1)=2^N-1
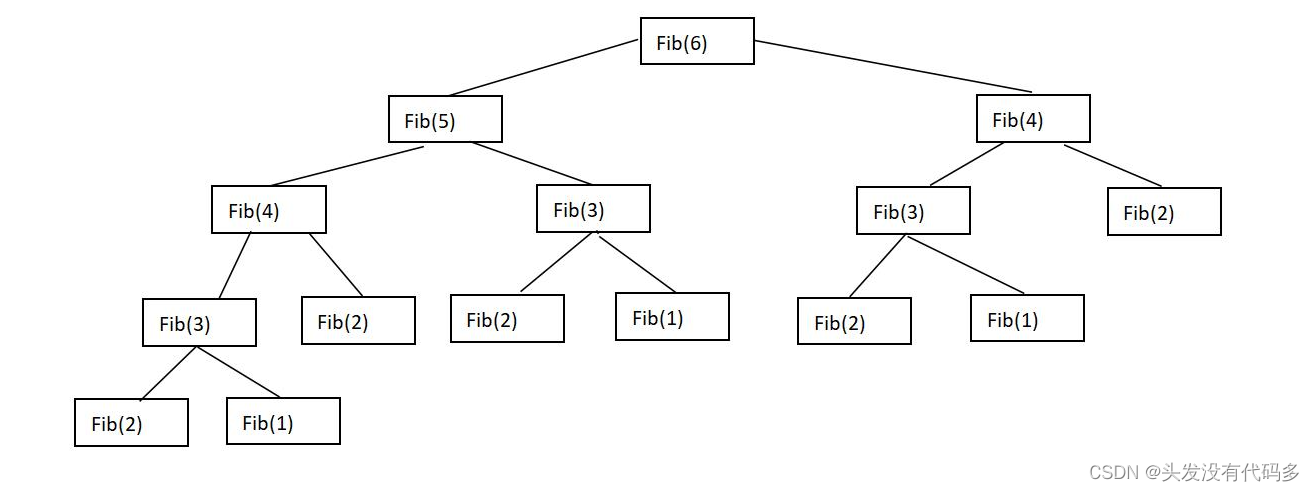
时间复杂度:O(2^N)
我们可以看到左边缺了一块,说明少了一些调用次数,但是少的这些调用次数和2^N相比可以忽略不计 。
优化斐波那契数列(把递归改循环)



旋转数组
给你一个数组,将数组中的元素向右轮转
k个位置,其中k是非负数。输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右轮转 1 步: [7,1,2,3,4,5,6]
向右轮转 2 步: [6,7,1,2,3,4,5]
向右轮转 3 步: [5,6,7,1,2,3,4]方法1:
方法二:
以空间换时间
新开辟一块空间把后K个拷贝到数组前面,前N-K个拷贝到数组后面 ,之后将TMP数组拷贝回原数组,然后释放tmp数组
方法二:





空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因 此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
冒泡循环空间复杂度:O(1),这里数组是创建好的不是临时占用的,这里只有三个变量end i 和exchang,每次循环当中end i exchang都各自占用一个空间,循环了N次,end只占了一个空间,i和exchange也一样,所以空间复杂度是O(1),
旋转数组
这个空间复杂度是O(N),因为中间有创建一个临时数组来接收旋转的结果
时间可以累计,空间可以重复利用
如果是结构体,还是O(1),不用考虑里面的成员个数,把结构体当成一个整体
空间复杂度为O(N),因为函数调用会涉及到栈帧的创建与销毁,每次在调用完一个函数之后,会把这块空间还给操作系统,这里对一个函数进行了调用,无论调用了多少次,函数所占的空间都一样,只不过是每次调用完之后会还给操作系统,每次调用的时候空间复杂度为O(1),调用N次就是O(N)
不管调用多少次,函数仍然占据




