
- 1秋招总结|五非选手转Java 0 offer 结束秋招之旅_满帮java 面经
- 2ROS 无人机仿真系统4 —— 通过键盘控制飞行器飞行_couldn't open joystick
- 3虚拟机IP地址消失以及静态IP地址转换_虚拟机没有ip地址怎么办
- 4Rust Web(一)—— 自建TCP Server_rust tcp server
- 5rpm与yum扩展、命令
- 6《看聊天记录都学不会C语言?太菜了吧》(1)我在大佬群里问基础问题没人理?_群里问了问题没人理
- 7vscode kite插件_Visual Studio Code(vscode)使用介绍
- 8Github 之 Pull Request_github 给pull request添加注释信息
- 9MySQL表的增删改查(进阶)
- 10判断字符串是否按首字母排序和长度排序_怎么判断一个字符串是否有序
Reids 基础 -- Redis数据库通用命令(SELECT、KEYS、SCAN、RANDOMKEY、SORT、EXISTS、DBSIZE、TYPE、RENAME、MOVE、DEL...)_redis select
赞
踩
文章目录
- 1. 导言
- 1. SELECT:切换至指定的数据库
- 2. KEYS:获取所有与给定匹配符相匹配的键
- 3. SCAN:以渐进方式迭代数据库中的键
- 4. RANDOMKEY:随机返回一个键
- 5. SORT:对键的值进行排序
- 6. EXISTS:检查给定键是否存在
- 7. DBSIZE:获取数据库包含的键值对数量
- 8. TYPE:查看键的类型
- 9. RENAME、RENAMENX:修改键名
- 10. MOVE:将给定的键移动到另一个数据库
- 11. DEL:移除指定的键
- 12. UNLINK:以异步方式移除指定的键
- 13. FLUSHDB:清空当前数据库
- 14. FLUSHALL:清空所有数据库
- 15. SWAPDB:互换数据库
- 16. 小结
1. 导言
无论是字符串键、散列键还是列表键,都会被存储到一个名为数据库的容器中。因为Redis是一个键值对数据库服务器,可以根据键的名字对数据库中的键值对进行索引。比如,通过使用Redis提供的命令,我们可以从数据库中移除指定的键,或者将指定的键从一个数据库移动到另一个数据库,诸如此类。
1. SELECT:切换至指定的数据库
一个Redis服务器可以包含多个数据库。在默认情况下,Redis服务器在启动时将会创建16个数据库:这些数据库都使用号码进行标识,其中第一个数据库为0号数据库,第二个数据库为1号数据库,而第三个数据库则为2号数据库,以此类推。
Redis虽然不允许在同一个数据库中使用两个同名的键,但是由于不同数据库拥有不同的命名空间,因此在不同数据库中使用同名的键是完全没有问题的,而用户也可以通过使用不同数据库来存储不同的数据,以此来达到重用键名并且减少键冲突的目的。
当用户使用客户端与Redis服务器进行连接时,客户端一般默认都会使用0号数据库,但是通过使用SELECT命令,用户可以从当前正在使用的数据库切换到自己想要使用的数据库:
语法:
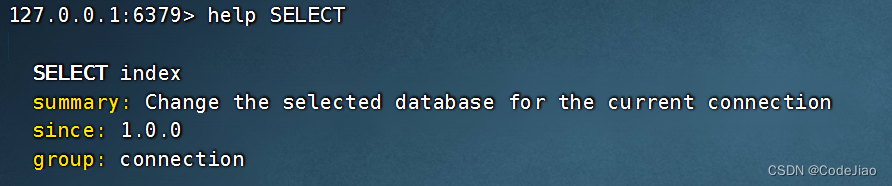
SELECT命令在切换成功之后将返回OK。
示例:
现在我的数据库里面没任何数据
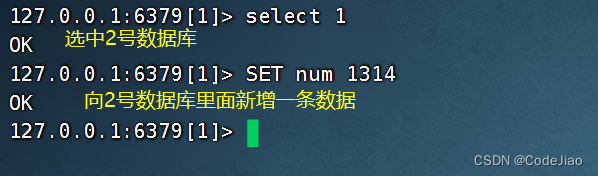
现在就可以在2号数据库里面看见新增的数据了

说明:
复杂度:O(1)。
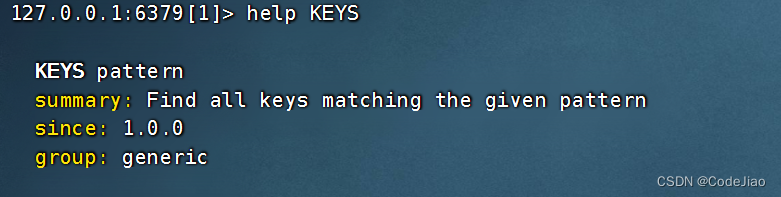
2. KEYS:获取所有与给定匹配符相匹配的键
KEYS命令接受一个全局匹配符作为参数,然后返回数据库中所有与这个匹配符相匹配的键作为结果:
语法:
示例:
如果我们想要获取数据库包含的所有键,那么可以执行以下命令:

如果我们想要获取所有以user为前缀的键,那么可以执行以下命令:

如果数据库中没有任何键与给定的匹配符相匹配,那么KEYS命令将返回一个空值:

说明:
复杂度:O(N),其中N为数据库包含的键数量。
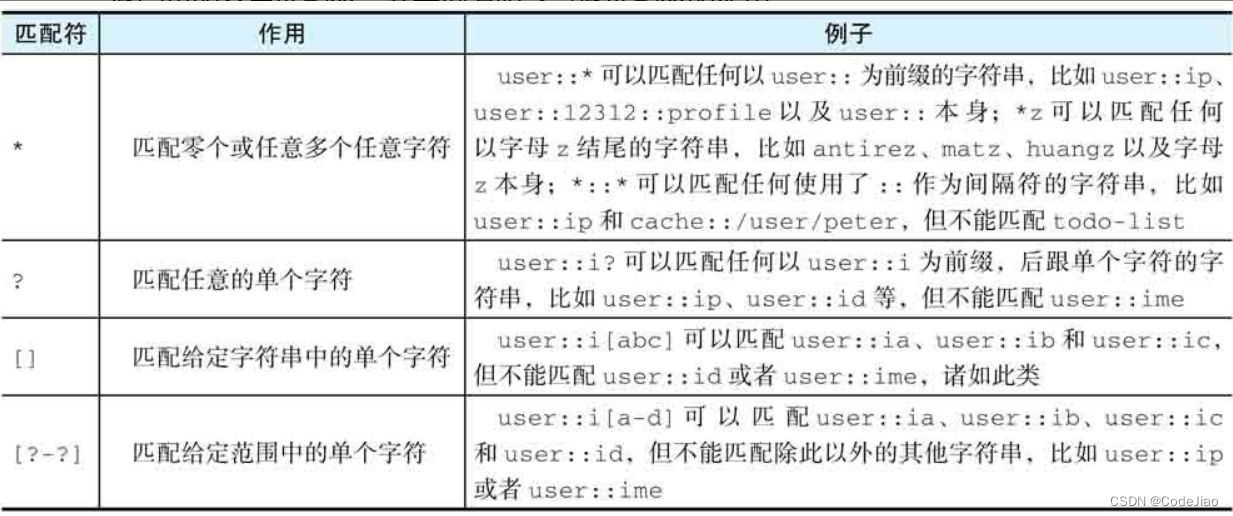
2.1 全局匹配符
KEYS命令允许使用多种不同的全局匹配符作为pattern参数的值,下表展示了一些常见的全局匹配符。
3. SCAN:以渐进方式迭代数据库中的键
因为KEYS命令需要检查数据库包含的所有键,并一次性将符合条件的所有键全部返回给客户端,所以当数据库包含的键数量比较大时,使用KEYS命令可能会导致服务器被阻塞。
为了解决这个问题,Redis从2.8.0版本开始提供SCAN命令,该命令是一个迭代器,它每次被调用的时候都会从数据库中获取一部分键,用户可以通过重复调用SCAN命令来迭代数据库包含的所有键。
语法:
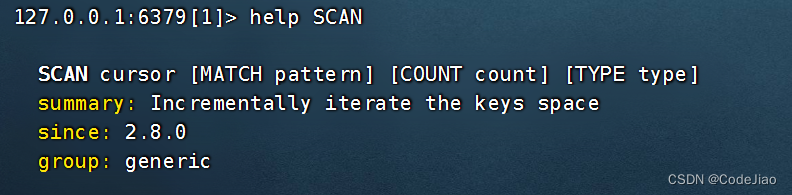 cursor参数用于指定迭代时使用的游标,游标记录了迭代的轨迹和进度。在开始一次新的迭代时,用户需要将游标设置为0。
cursor参数用于指定迭代时使用的游标,游标记录了迭代的轨迹和进度。在开始一次新的迭代时,用户需要将游标设置为0。
SCAN命令的执行结果由两个元素组成:
- 第一个元素是进行下一次迭代所需的游标,如果这个游标为0,那么说明客户端已经对数据库完成了一次完整的迭代。
- 第二个元素是一个列表,这个列表包含了本次迭代取得的数据库键;如果SCAN命令在某次迭代中没有获取到任何键,那么这个元素将是一个空列表。
关于SCAN命令返回的键列表,有两点需要注意:
- SCAN命令可能会返回重复的键,用户如果不想在结果中包含重复的键,那么就需要自己在客户端中进行检测和过滤。
- SCAN命令返回的键数量是不确定的,有时甚至会不返回任何键,但只要命令返回的游标不为0,迭代就没有结束。
示例:
在对SCAN命令有了基本的了解之后,让我们来试试使用SCAN命令去完整地迭代一个数据库。
我们先往数据库添加足够数量的数据:
为了开始一次新的迭代,我们将以0作为游标,调用SCAN命令:
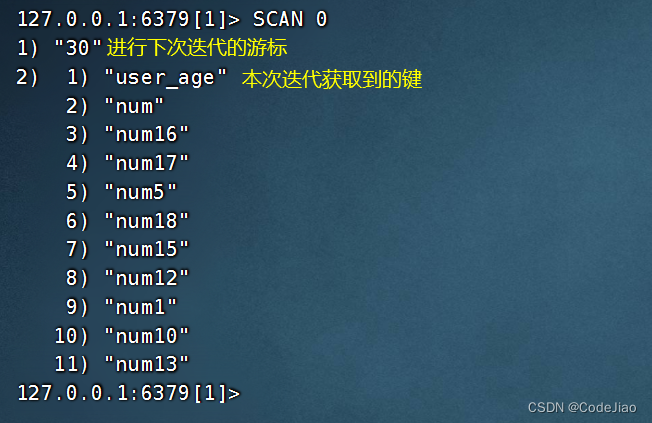
这个SCAN调用告知我们下次迭代应该使用30作为游标,并返回了11个键的键名。
为了继续对数据库进行迭代,我们使用30作为游标,再次调用SCAN命令:
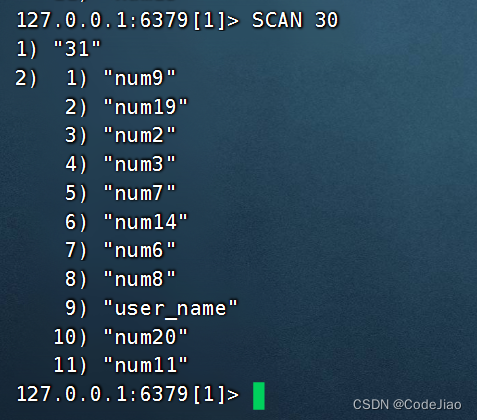 这次的SCAN调用返回了11个键,并告知我们下次迭代应该使用31作为游标。与之前的情况类似,这次我们使用31作为游标,再次调用SCAN命令:
这次的SCAN调用返回了11个键,并告知我们下次迭代应该使用31作为游标。与之前的情况类似,这次我们使用31作为游标,再次调用SCAN命令:
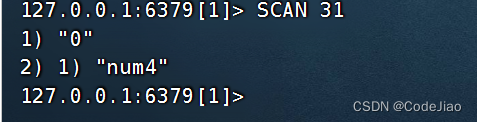
这次的SCAN调用只返回了1个键,并且它返回的下次迭代游标为0,这说明本次迭代已经结束,整个数据库已经被迭代完毕。
3.1 SCAN命令的迭代保证
针对数据库的一次完整迭代(full iteration)以用户给定游标0调用SCAN命令开始,直到SCAN命令返回游标0结束。SCAN命令为完整迭代提供以下保证:
- 从迭代开始到迭代结束的整个过程中,一直存在于数据库中的键总会被返回。
- 如果一个键在迭代的过程中被添加到数据库中,那么这个键是否会被返回是不确定的。
- 如果一个键在迭代的过程中被移除了,那么SCAN命令在它被移除之后将不再返回这个键,但是这个键在被移除之前仍然有可能被SCAN命令返回。
- 无论数据库如何变化,迭代总是有始有终的,不会出现循环迭代或者其他无法终止迭代的情况。
3.2 游标的使用
SCAN命令的游标不需要申请,也不需要释放,它们不占用任何资源,每个客户端都可以使用自己的游标独立地对数据库进行迭代。
此外,用户可以随时在迭代的过程中停止迭代,或者随时开始一次新的迭代,这不会浪费任何资源,也不会引发任何问题。
3.3 迭代与给定匹配符相匹配的键
在默认情况下,SCAN命令会向客户端返回数据库包含的所有键,它就像KEYS*命令调用的一个迭代版本。但是通过使用可选的MATCH选项,我们同样可以让SCAN命令只返回与给定全局匹配符相匹配的键。
语法:
示例:
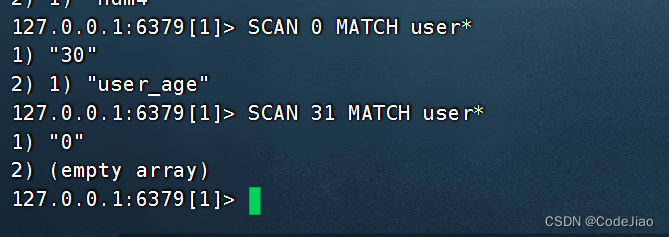
假设我们想要获取数据库中所有以user开头的键,但是因为这些键的数量比较多,直接使用KEYS user*有可能会造成服务器阻塞,所以我们可以使用SCAN命令来代替KEYS命令,对符合user*匹配符的键进行迭代。
3.4 指定返回键的期望数量
一般情况下,SCAN命令返回的键数量是不确定的,但是我们可以通过使用可选的COUNT选项,向SCAN命令提供一个期望值,以此来说明我们希望得到多少个键。
语法:
 这里需要特别注意的是,COUNT选项向命令提供的只是期望的键数量,但并不是精确的键数量。比如,执行SCAN cursor COUNT 10并不意味着SCAN命令最多只能返回10个键,或者一定要返回10个键。
这里需要特别注意的是,COUNT选项向命令提供的只是期望的键数量,但并不是精确的键数量。比如,执行SCAN cursor COUNT 10并不意味着SCAN命令最多只能返回10个键,或者一定要返回10个键。
- COUNT选项只是提供了一个期望值,告诉SCAN命令我们希望返回多少个键,但每次迭代返回的键数量仍然是不确定的。
- 不过在通常情况下,设置一个较大的COUNT值将有助于获得更多键,这一点是可以肯定的。
示例:
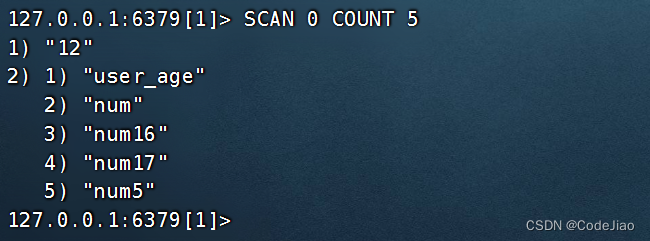
3.5 数据结构迭代命令(散列 HSCAN、集合 SSCAN、有序集合 ZSCAN)
Redis为散列、集合和有序集合也提供了与SCAN命令类似的游标迭代命令,分别是HSCAN命令、SSCAN命令和ZSCAN命令。
除了需要指定被迭代的散列之外,HSCAN命令的其他参数与SCAN命令的参数保持一致,并且作用也一样。
3.5.1 散列迭代命令
语法:
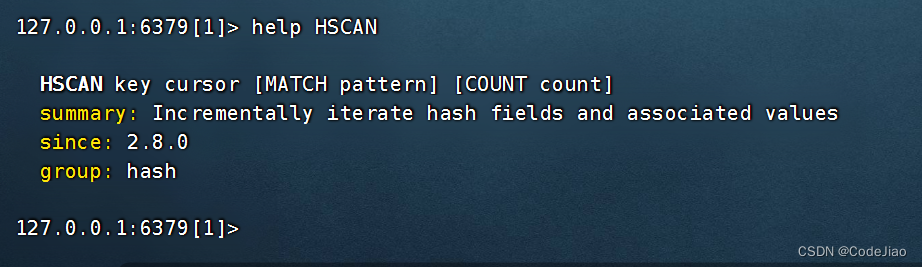
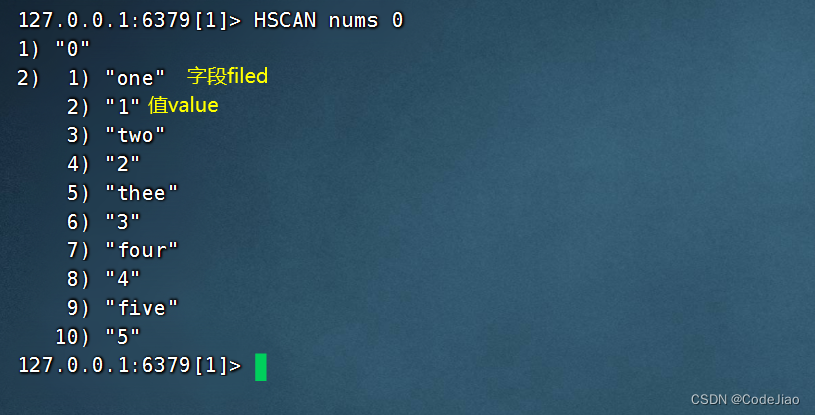
以下代码展示了如何使用HSCAN命令去迭代nums散列:
3.5.2 渐进式集合迭代命令:
SSCAN命令可以以渐进的方式迭代给定集合包含的元素。
语法:
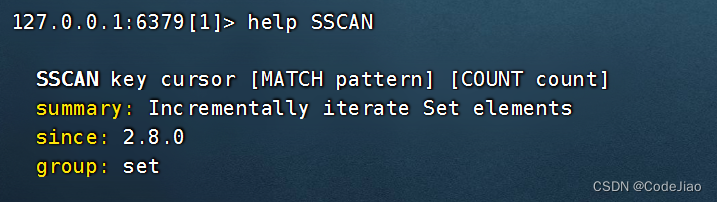
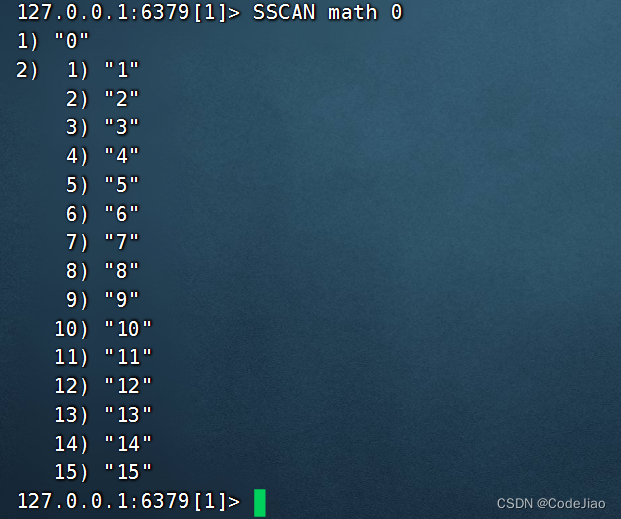
举个例子,假设我们想要对math集合进行迭代,那么可以执行以下命令:
3.5.3 渐进式有序集合迭代命令
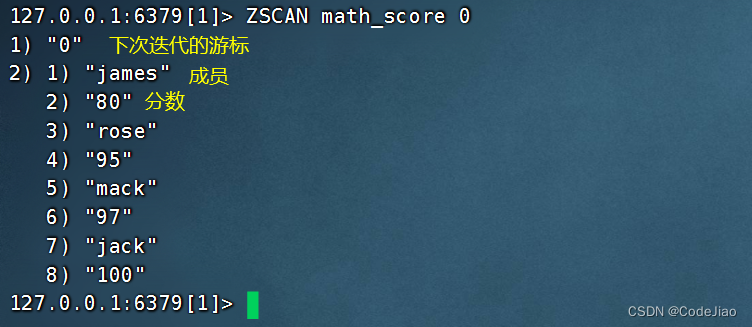
ZSCAN命令可以以渐进的方式迭代给定有序集合包含的成员和分值。
语法:
示例:
3.6 迭代命令的共通性质
HSCAN、SSCAN、ZSCAN这3个命令除了与SCAN命令拥有相同的游标参数以及可选项之外,还与SCAN命令拥有相同的迭代性质:
- SCAN命令对于完整迭代所做的保证,其他3个迭代命令也能够提供。比如,使用HSCAN命令对散列进行一次完整迭代,在迭代过程中一直存在的键值对总会被返回,诸如此类。
- 与SCAN命令一样,其他3个迭代命令的游标也不耗费任何资源。用户可以在这3个命令中随意地使用游标,比如随时开始一次新的迭代,又或者随时放弃正在进行的迭代,这不会浪费任何资源,也不会引发任何问题。
- 与SCAN命令一样,其他3个迭代命令虽然也可以使用COUNT选项设置返回元素数量的期望值,但命令具体返回的元素数量仍然是不确定的。
3.7 时间复杂度说明
复杂度:SCAN命令、HSCAN命令、SSCAN命令和ZSCAN命令单次执行的复杂度为O(1),而使用这些命令进行一次完整迭代的复杂度则为O(N),其中N为被迭代的元素数量。
4. RANDOMKEY:随机返回一个键
RANDOMKEY命令可以从数据库中随机地返回一个键。RANDOMKEY命令不会移除被返回的键,它们会继续留在数据库中。
语法:
示例:
以下代码展示了如何通过RANDOMKEY命令,从数据库中随机地返回一些键。
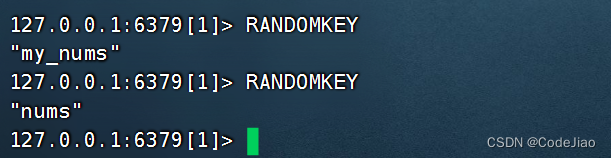
当数据库为空时,RANDOMKEY命令将返回一个空值(nil)
说明:
复杂度:O(1)。
5. SORT:对键的值进行排序
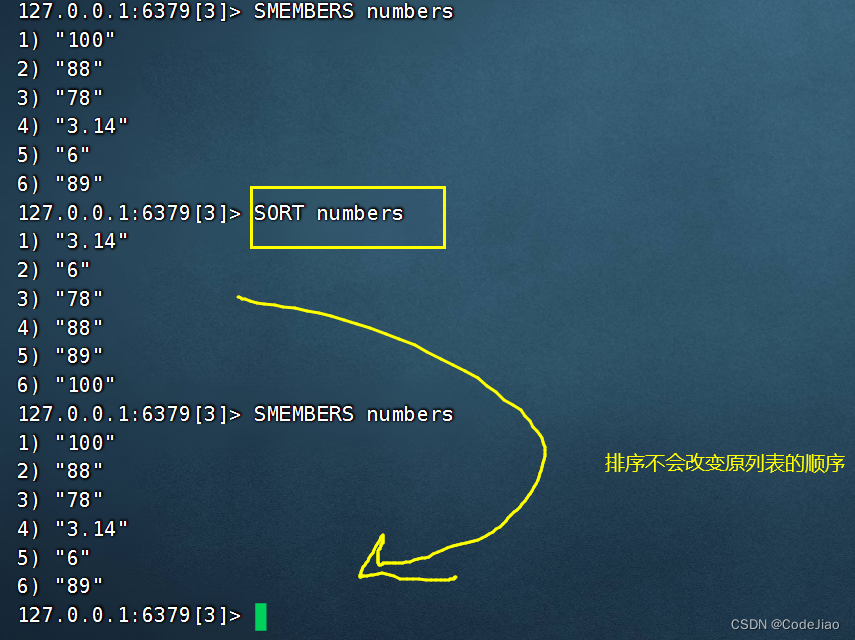
用户可以通过执行SORT命令对列表元素、集合元素或者有序集合成员进行排序。为了让用户能够以不同的方式进行排序,Redis为SORT命令提供了非常多的可选项,如果我们以不给定任何可选项的方式直接调用SORT命令,那么命令将对指定键存储的元素执行数字值排序。
排序后不会改变原列表的排列顺序。
语法:

在默认情况下,SORT命令将按照从小到大的顺序依次返回排序后的各个值。
示例:
5.1 指定排序方式
在默认情况下,SORT命令执行的是升序排序操作:较小的值将被放到结果的较前位置,而较大的值则会被放到结果的较后位置。
通过使用可选的ASC选项或者DESC选项,用户可以指定SORT命令的排序方式,其中ASC表示执行升序排序操作(默认升序),而DESC则表示执行降序排序操作。
示例:

5.2 对字符串值进行排序
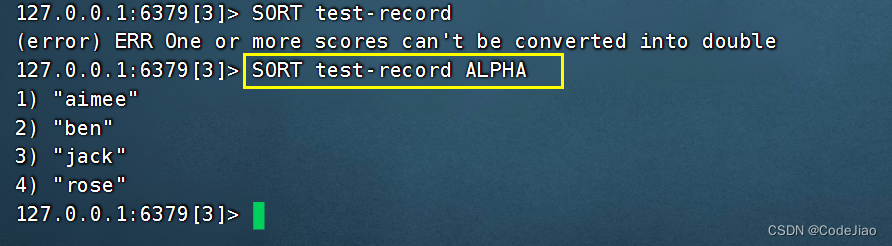
SORT命令在默认情况下进行的是数字值排序,如果我们尝试直接使用SORT命令去对字符串元素进行排序,那么命令将产生一个错误。
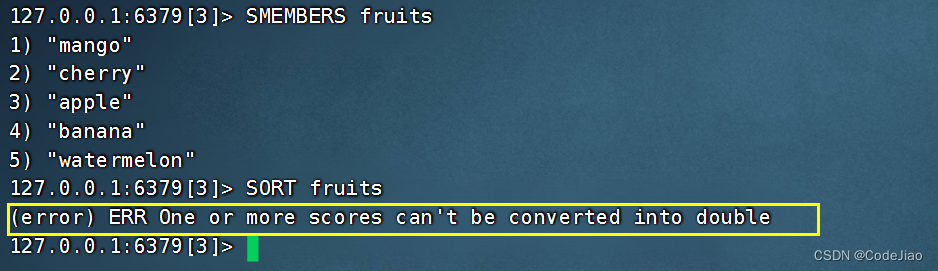
为了让SORT命令能够对字符串值进行排序,我们必须让SORT命令执行字符串排序操作而不是数字值排序操作,这一点可以通过使用ALPHA选项来实现。
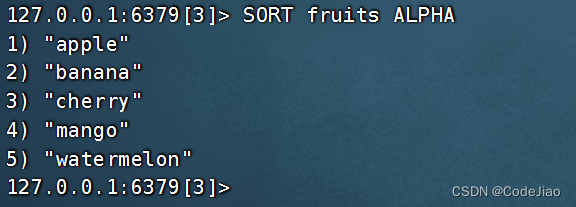
示例:
我们可以使用带ALPHA选项的SORT命令对fruits集合进行排序:
 或者使用以下命令,对test-record有序集合的成员进行排序:
或者使用以下命令,对test-record有序集合的成员进行排序:
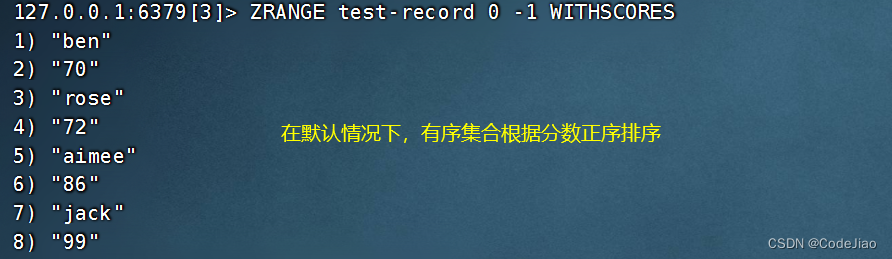
5.3 只获取部分排序结果
在默认情况下,SORT命令将返回所有被排序的元素,但如果我们只需要其中一部分排序结果,那么可以使用可选的LIMIT选项。
语法:

其中offset参数用于指定返回结果之前需要跳过的元素数量,而count参数则用于指定需要获取的元素数量。
示例:
获取fruits集合在排序之后的第3个元素:

注意,因为offset参数的值是从0开始计算的,所以这个命令在获取第3个被排序元素时使用了2而不是3来作为偏移量。
5.4 获取外部键的值作为结果
在默认情况下,SORT命令将返回被排序的元素作为结果,但如果用户有需要,也可以使用GET选项去获取其他值作为排序结果。
语法:

一个SORT命令可以使用任意多个GET pattern选项,其中pattern参数的值可以是:
- 包含*符号的字符串。
- 包含*符号和->符号的字符串。
- 一个单独的#符号。
5.4.1 获取字符串键的值
当pattern参数的值是一个包含*符号的字符串时,SORT命令将把被排序的元素与*符号进行替换,构建出一个键名,然后使用GET命令去获取该键的值。
示例:
假设数据库中存储着下表所示的一些字符串键,那么我们可以通过执行以下命令对fruits集合的各个元素进行排序,然后根据排序后的元素获取各种水果的价格:
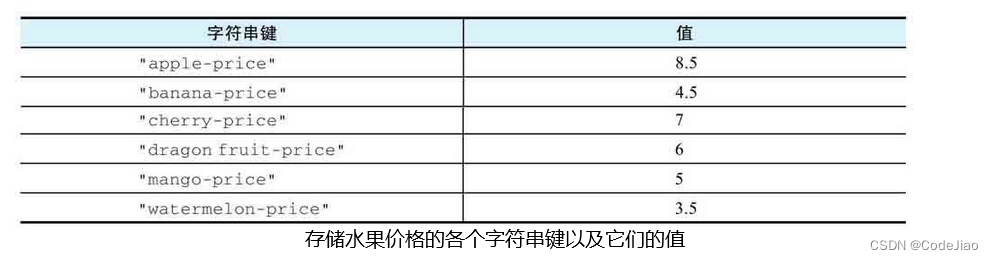
furits集合:
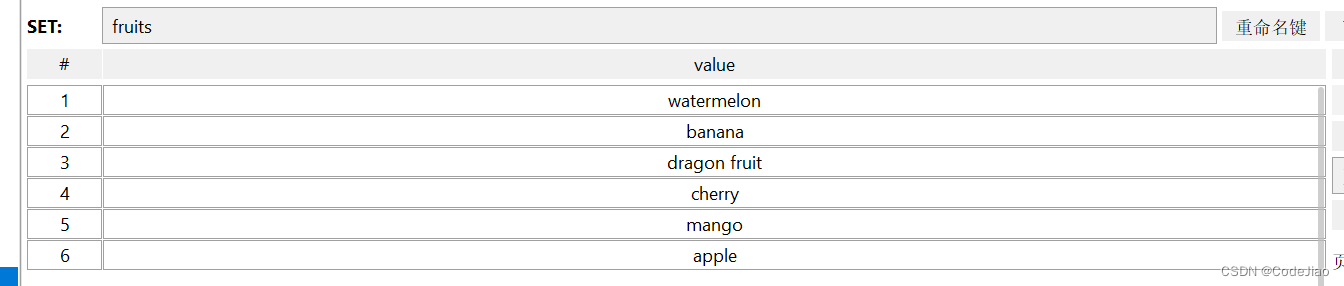
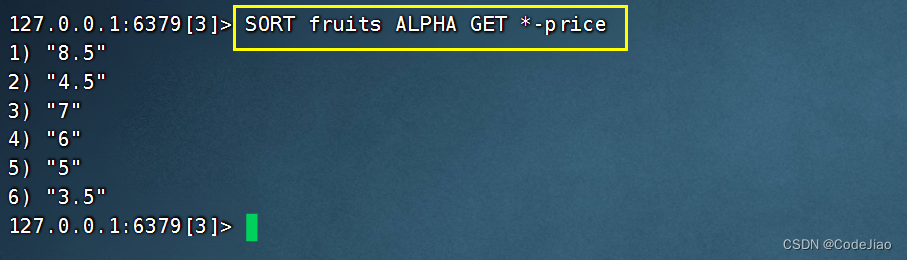
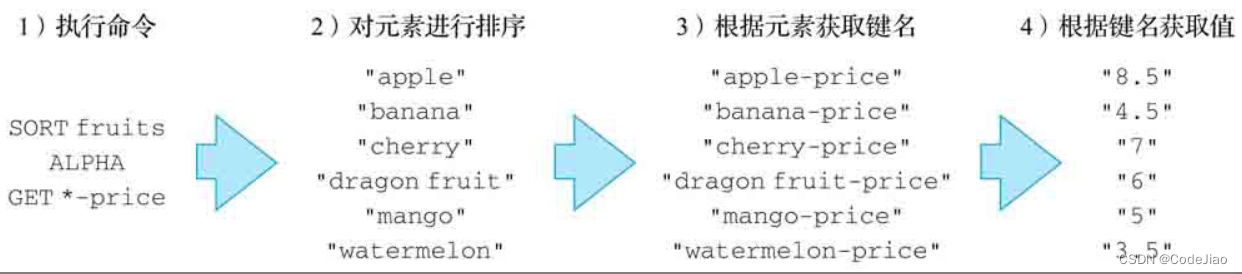
这个SORT命令的执行过程可以分为以下3个步骤:
- 对fruits集合的各个元素进行排序,得出一个由"apple"、“banana”、“cherry”、“dragon fruit”、“mango”、"watermelon"组成的有序元素排列。
- 将排序后的各个元素与*-price模式进行匹配和替换,得出键名"apple-price"、“banana-price”、“cherry-price”、“dragon fruit-price”、“mango-price"和"watermelon-price”。
- 使用GET命令获取以上各个键的值,并将这些值依次放入结果列表中,最后把结果列表返回给客户端。
5.4.2 获取散列中的键值
当pattern参数的值是一个包含*符号和->符号的字符串时,SORT命令将使用->左边的字符串为散列名,->右边的字符串为字段名,调用HGET命令,从散列中获取指定字段的值。此外,用户传入的散列名还需要包含*符号,这个*符号将被替换成被排序的元素。
示例:
假设数据库中存储着下表所示的apple-info、banana-info等散列,而这些散列的inventory键则存储着相应水果的存货量,那么我们可以通过执行以下命令,对fruits集合的各个元素进行排序,然后根据排序后的元素获取各种水果的存货量:
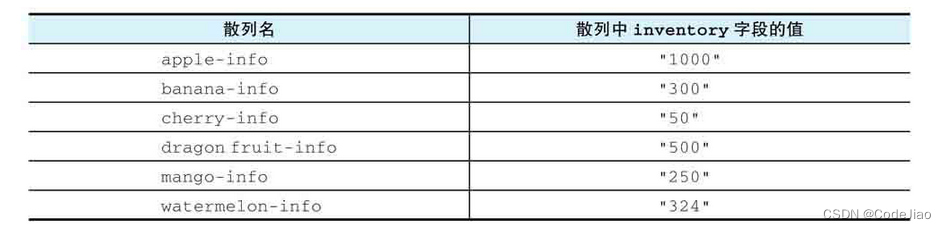
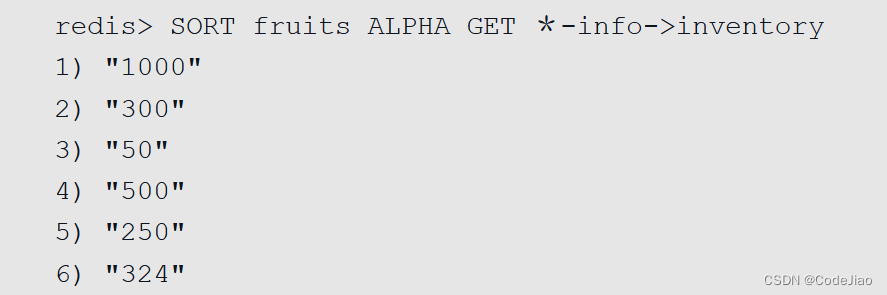
这个SORT命令的执行过程可以分为以下3个步骤:
- 对fruits集合的各个元素进行排序,得出一个由"apple"、“banana”、“cherry”、“dragon fruit”、“mango”、"watermelon"组成的有序元素排列。
- 将排序后的各个元素与*-info模式进行匹配和替换,得出散列名"apple-info"、“banana-info”、“cherry-info”、“dragon fruit-info”、“mango-info"和"watermelon-info”。
- 使用HGET命令,从以上各个散列中取出inventory字段的值,并将这些值依次放入结果列表中,最后把结果列表返回给客户端。
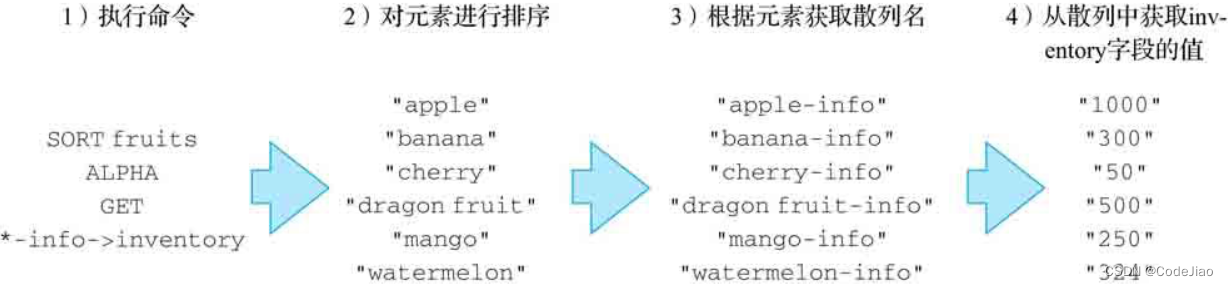
5.4.3 获取被排序元素本身
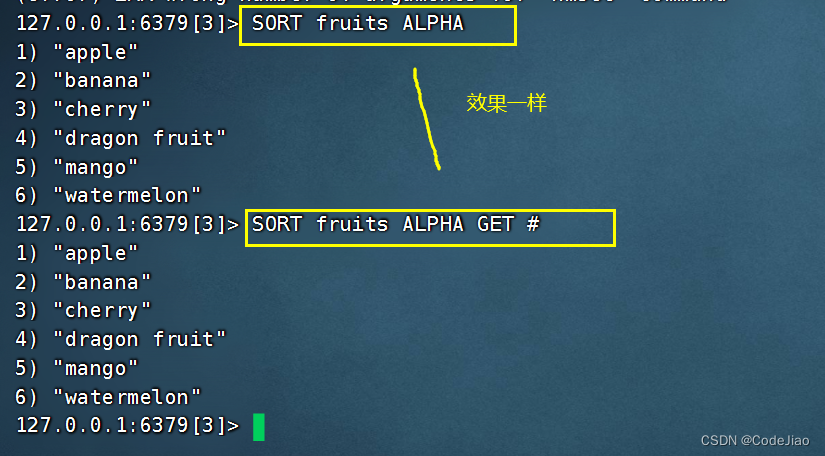
当pattern参数的值是一个#符号时,SORT命令将返回被排序的元素本身。
因为SORT key命令和SORT key GET #命令返回的是完全相同的结果,所以单独使用GET #并没有任何实际作用。
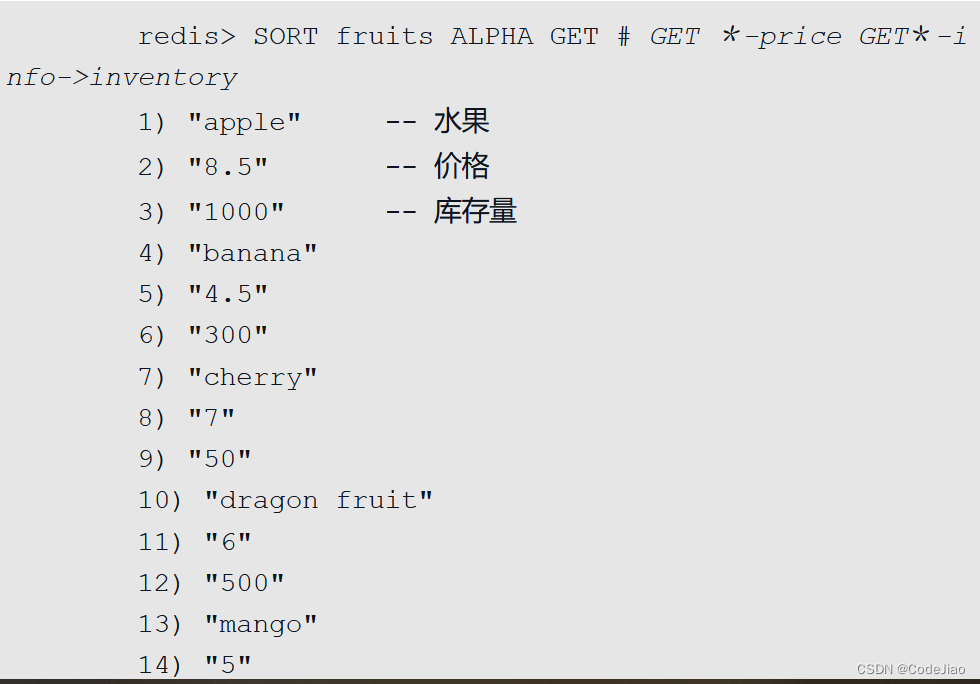
因此,我们一般只会在同时使用多个GET选项时,才使用GET #获取被排序的元素。比如,以下代码就展示了如何在对水果进行排序的同时,获取水果的价格和库存量:
5.5 使用外部键的值作为排序权重
在默认情况下,SORT命令将使用被排序元素本身作为排序权重,但在有需要时,用户可以通过可选的BY选项指定其他键的值作为排序的权重。
语法:

pattern参数的值既可以是包含*符号的字符串,也可以是包含*符号和->符号的字符串,这两种值的作用和效果与使用GET选项的作用和效果一样:前者用于获取字符串键的值,而后者则用于从散列中获取指定字段的值。
示例:
通过执行以下命令,我们可以使用存储在字符串键中的水果价格作为权重,对水果进行排序。

因为上面这个排序结果只展示了水果的名字,却没有展示水果的价格,所以这个排序结果并没有清楚地展示水果的名字和价格之间的关系。相反,如果我们在使用BY选项的同时,使用两个GET选项去获取水果的名字以及价格,那么就能够直观地看出水果是按照价格进行排序的了。
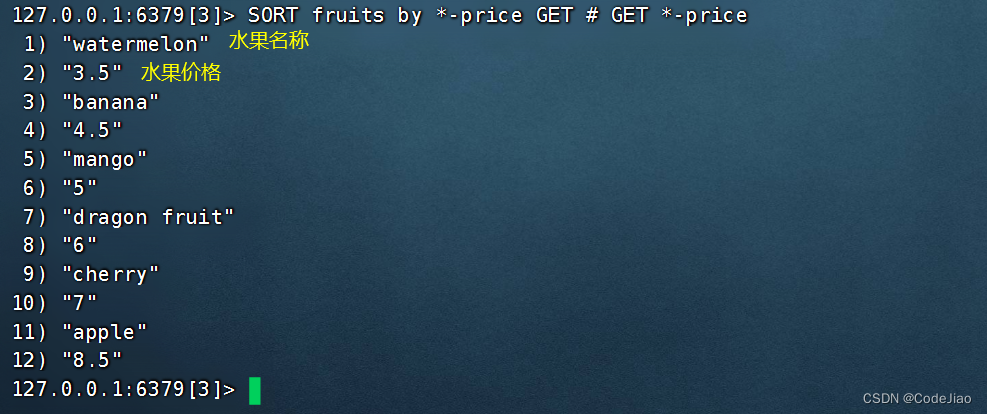 我们还可以通过执行以下命令,使用散列中记录的库存量作为权重,对水果进行排序并获取它们的库存量。
我们还可以通过执行以下命令,使用散列中记录的库存量作为权重,对水果进行排序并获取它们的库存量。

5.6 保存排序结果
在默认情况下,SORT命令会直接将排序结果返回给客户端,但如果用户有需要,也可以通过可选的STORE选项,以列表形式将排序结果存储到指定的键中。
语法:

如果用户给定的destination键已经存在,那么SORT命令会先移除该键,然后再存储排序结果。带有STORE选项的SORT命令在成功执行之后将返回被存储的元素数量作为结果。
示例:
以下代码展示了如何将排序fruits集合所得的结果存储到sorted-fruits列表中:
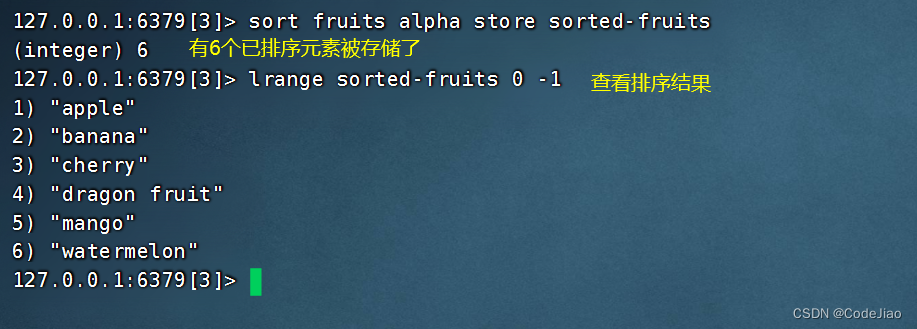
5.7 时间复杂度说明
复杂度:O(N*log(N)+M),其中N为被排序元素的数量,而M则为命令返回的元素数量。
6. EXISTS:检查给定键是否存在
用户可以通过使用EXISTS命令,检查给定的一个或多个键是否存在于当前正在使用的数据库中。
语法:
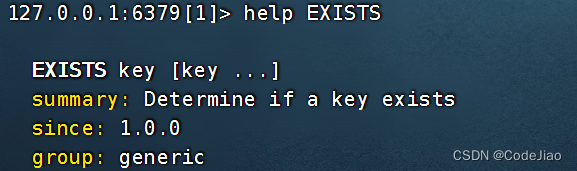
EXISTS命令将返回存在的给定键数量作为返回值。
示例:
通过将多个键传递给EXISTS命令,可以判断出在给定的键中,有多少个键是实际存在的。举个例子,通过执行以下命令,我们可以知道s1、s2和s3这3个给定键当中,只有2个键是存在的:

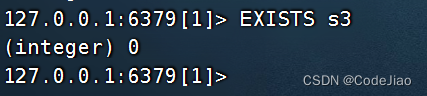
如果我们只想确认某个键是否存在,那么只需要将那个键传递给EXISTS命令即可:命令返回0表示该键不存在,返回1则表示该键存在。
比如,通过执行以下命令,我们可以知道键s3并不存在于数据库中:
说明:
复杂度:O(N),其中N为用户给定的键数量。
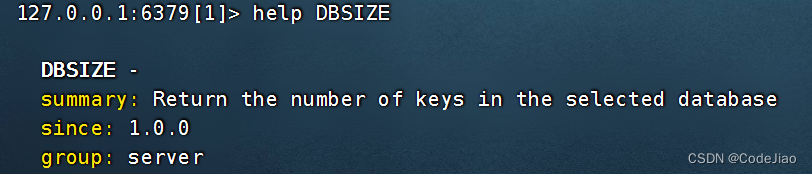
7. DBSIZE:获取数据库包含的键值对数量
用户可以通过执行DBSIZE命令来获知当前使用的数据库包含了多少个键值对(Redis里面所有数据都是键值对的形式)。
语法:
示例:
比如在以下这个例子中,我们就通过执行DBSIZE获知数据库目前包含了3个键值对:
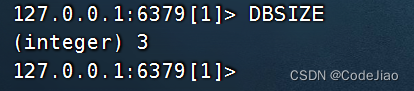
说明:
复杂度:O(1)。
8. TYPE:查看键的类型
TYPE命令允许我们查看给定键的类型。
语法:
下表列出了TYPE命令在面对不同类型的键时返回的各项结果。
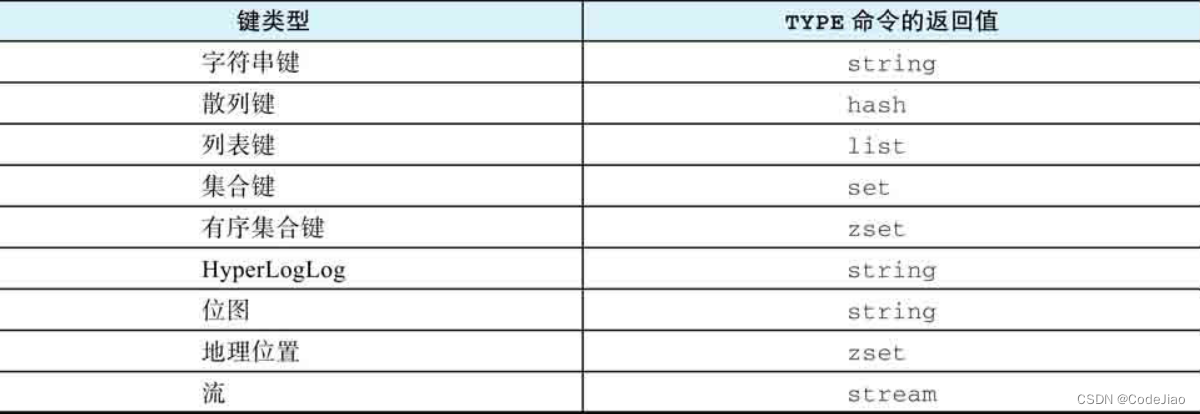
TYPE命令对于字符串键、散列键、列表键、集合键和流键的返回结果都非常直观,不过它对于之后几种类型的键的返回结果则需要做进一步解释:
- 因为所有有序集合命令,比如ZADD、ZREM、ZSCORE等,都是以z为前缀命名的,所以有序集合也被称为zset。因此TYPE命令在接收到有序集合键作为输入时,将返回zset作为结果。
- 因为HyperLogLog和位图这两种键在底层都是通过字符串键来实现的,所以TYPE命令对于这两种键将返回string作为结果。
- 与HyperLogLog和位图的情况类似,因为地理位置键使用了有序集合键作为底层实现,所以TYPE命令对于地理位置键将返回zset作为结果。
示例:
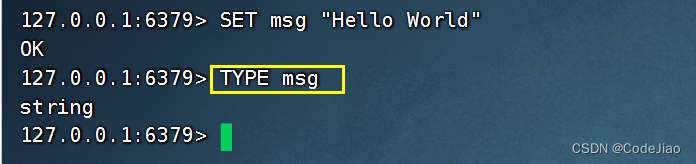
说明:
复杂度:O(1)。
9. RENAME、RENAMENX:修改键名
Redis提供了RENAME命令,用户可以使用这个命令修改键的名称。
语法:
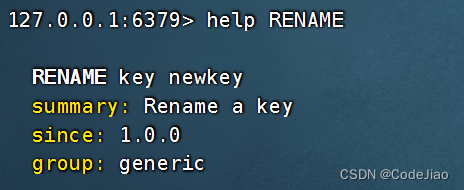
RENAME命令在执行成功时将返回OK作为结果。
示例:
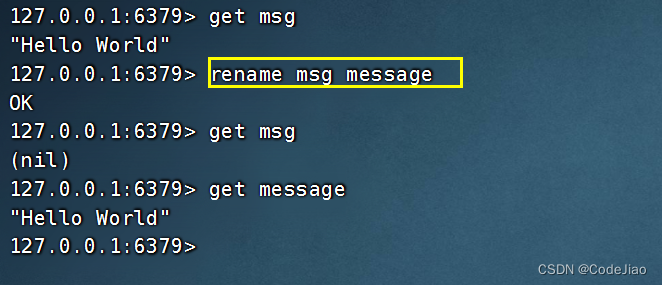
以下代码展示了如何将键msg改名为键message:
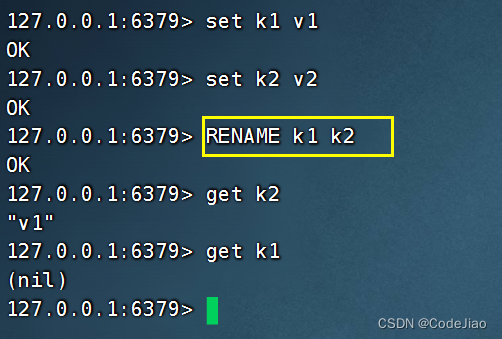
9.1 覆盖已存在的键
如果用户指定的新键名已经被占用,那么RENAME命令会先移除占用了新键名的那个键,然后再执行改名操作。
示例:
在以下例子中,键k1和键k2都存在,如果我们使用RENAME命令将键k1改名为键k2,那么原来的键k2将被移除:
9.2 只在新键名尚未被占用的情况下进行改名
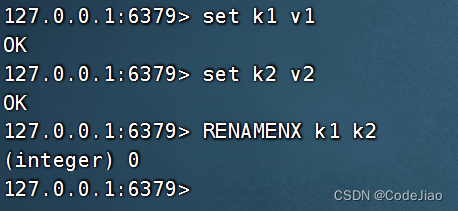
RENAMENX命令和RENAME命令一样,都可以对键进行改名,但RENAMENX命令只会在新键名尚未被占用的情况下进行改名,如果用户指定的新键名已经被占用,那么RENAMENX将放弃执行改名操作。
语法:
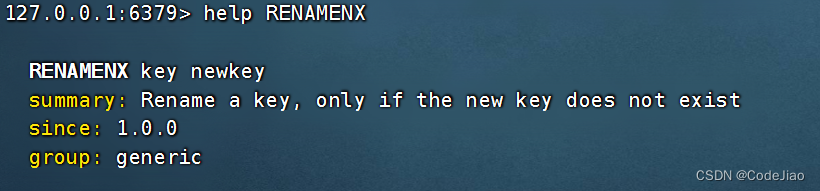
RENAMENX命令在改名成功时返回1,失败时返回0。
示例:
比如在以下例子中,因为键k2已经存在,所以尝试将键k1改名为k2将以失败告终:
9.3 时间复杂度说明
复杂度:O(1)。
10. MOVE:将给定的键移动到另一个数据库
用户可以使用MOVE命令,将一个键从当前数据库移动至目标数据库。
语法:
当MOVE命令成功将给定键从当前数据库移动至目标数据库时,命令返回1;如果给定键并不存在于当前数据库,或者目标数据库中存在与给定键同名的键,那么MOVE命令将不做动作,只返回0表示移动失败。
示例:
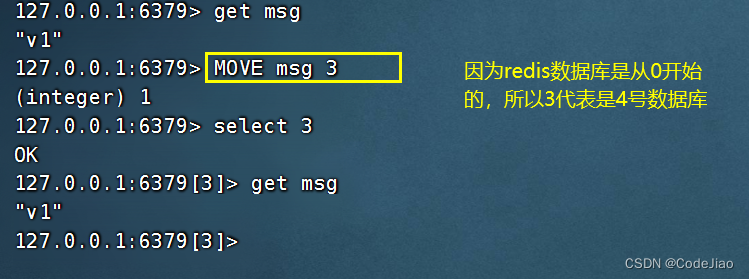
以下代码展示了如何将0号数据库中的msg键移动到4号数据库:
10.1 不覆盖同名键
当目标数据库存在与给定键同名的键时,MOVE命令将放弃执行移动操作(返回0)。
10.2 时间复杂度说明
复杂度:O(1)。
11. DEL:移除指定的键
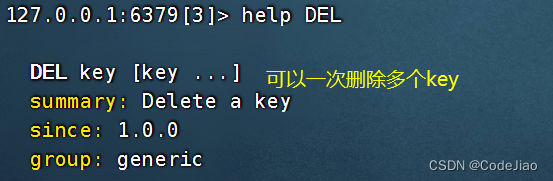
DEL命令允许用户从当前正在使用的数据库中移除指定的一个或多个键,以及与这些键相关联的值。
语法:
DEL命令将返回成功移除的键数量作为返回值。
示例:
 如果用户给定的键并不存在则返回0。
如果用户给定的键并不存在则返回0。
说明:
复杂度:O(N),其中N为被移除键的数量。
12. UNLINK:以异步方式移除指定的键
因为DEL命令会以同步方式执行移除操作,所以如果待移除的键非常庞大或者数量众多,那么服务器在执行移除操作的过程中就有可能被阻塞。比如,移除一个包含上百万个元素的集合,移除一个包含数十万个键值对的散列,或者一次移除成千上万个键,都有可能引起服务器阻塞。
为了解决这个问题,Redis从4.0版本开始新添加了一个UNLINK命令。
UNLINK命令与DEL命令一样,都可以用于移除指定的键,但它与DEL命令的区别在于,当用户调用UNLINK命令去移除一个数据库键时,UNLINK只会在数据库中移除对该键的引用(reference),而对键的实际移除操作则会交给后台线程执行,因此UNLINK命令将不会造成服务器阻塞。
与DEL命令一样,UNLINK命令也会返回被移除键的数量作为结果。此外,基于兼容方面的原因,Redis将在提供异步移除操作UNLINK命令的同时,继续提供同步移除操作DEL命令。
语法:

示例:
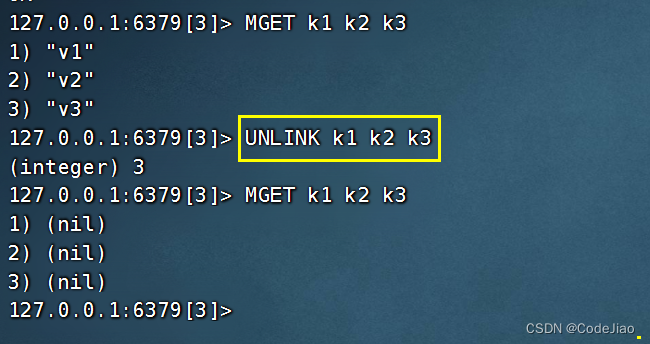
说明:
复杂度:O(N),其中N为被移除键的数量。
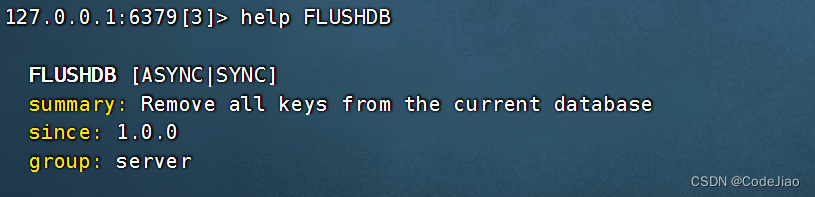
13. FLUSHDB:清空当前数据库
通过使用FLUSHDB命令,用户可以清空当前正在使用的数据库。
语法:
示例:
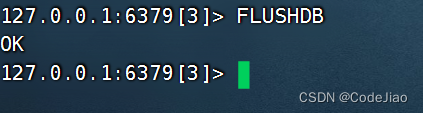
FLUSHDB命令会遍历用户正在使用的数据库,移除其中包含的所有键值对,然后返回OK表示数据库已被清空。
13.1 async选项
FLUSHDB命令是一个同步移除命令,并且因为FLUSHDB移除的是整个数据库而不是单个键,所以它常常会引发比DEL命令更为严重的服务器阻塞现象。
为了解决这个问题,Redis 4.0给FLUSHDB命令新添加了一个async选项:
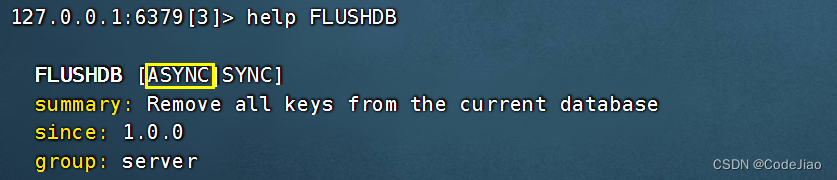
如果用户在调用FLUSHDB命令时使用了async选项,那么实际的数据库清空操作将放在后台线程中以异步方式进行,这样FLUSHDB命令就不会再阻塞服务器了。
示例:

13.2 时间复杂度说明
复杂度:O(N),其中N为被清空数据库包含的键值对数量。
14. FLUSHALL:清空所有数据库
过使用FLUSHALL命令,用户可以清空Redis服务器包含的所有数据库。
语法:
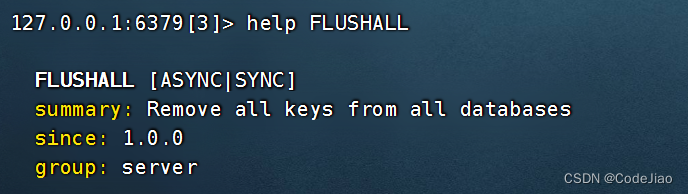
FLUSHALL命令会遍历服务器包含的所有数据库,并移除其中包含的所有键值对,然后返回OK表示所有数据库均已被清空。
与FLUSHDB命令一样,以同步方式执行的FLUSHALL命令也可能会导致服务器阻塞,因此Redis 4.0也给FLUSHALL命令添加了同样的async选项。
示例:

说明:
复杂度:O(N),其中N为被清空的所有数据库包含的键值对总数量。
15. SWAPDB:互换数据库
SWAPDB命令接受两个数据库号码作为输入,然后对指定的两个数据库进行互换,最后返回OK作为结果。
语法:
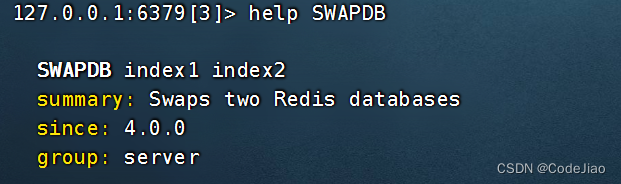
在SWAPDB命令执行完毕之后,原本存储在数据库index1中的键值对将出现在数据库index2中,而原本存储在数据库index2中的键值对将出现在数据库index1中。
说明:
因为互换数据库这一操作可以通过调整指向数据库的指针来实现,这个过程不需要移动数据库中的任何键值对,所以SWAPDB命令的复杂度是O(1)而不是O(N),并且执行这个命令也不会导致服务器阻塞。
16. 小结
- 所有Redis键,无论它们是什么类型,都会被存储到数据库中。
- 一个Redis服务器可以同时拥有多个数据库,每个数据库都拥有一个独立的命名空间。也就是说,同名的键可以出现在不同数据库中。
- 在默认情况下,Redis服务器在启动时将创建16个数据库,并使用数字0~15对其进行标识。
- 因为KEYS命令在数据库包含大量键的时候可能会阻塞服务器,所以我们应该使用SCAN命令来代替KEYS命令。
- 通过使用SORT命令,我们可以以多种不同的方式,对存储在列表、集合以及有序集合中的元素进行排序。
- 因为DEL命令在移除体积较大或者数量众多的键时可能会导致服务器阻塞,所以我们应该使用异步移除命令UNLINK来代替DEL命令。
- 用户在执行FLUSHDB命令和FLUSHALL命令时可以带上async选项,让这两个命令以异步方式执行,从而避免服务器阻塞。
- SWAPDB命令可以在完全不阻塞服务器的情况下,对两个给定的数据库进行互换,因此这个命令可以用于实现在线的数据库替换操作。

