
- 11. ATF(ARM Trusted firmware)完成启动流程_atf 安全启动流程
- 2Flink之详解InnerJoin、leftJoin以及窗口延迟时间的问题_flink left join
- 3rh2288v3服务器硬盘故障,RH2288H V3服务器出现0x02000007告警
- 4使用SuperTextMesh 针对项目的几个修改记录
- 5Android Studio实现内容丰富的安卓校园超市_android studio 超市系统
- 6springBoot redis -- spring-boot-starter-data-redis与spring-boot-starter-redis两个包的区别_spring-boot-starter-redis 和 spring-boot-starter-da
- 7【基于R语言群体遗传学】-1-哈代温伯格基因型比例
- 8大模型推理两种实现方式的区别:model.generate()和model()
- 9程序员出差是去干什么_程序员到底能不能去外包公司?
- 10Python时间模块之calendar模块_python calendar模块
Milvus 到底有多少种玩法?这份攻略合集请收好!_基于milvus的bert语义查重
赞
踩
Milvus 是一款开源的向量相似度搜索引擎,支持使用多种 AI 模型将非结构化数据向量化,并为向量数据提供搜索服务。Milvus 集成了 Faiss、Annoy 等广泛应用的向量索引库,开发者可以针对不同场景选择不同的索引类型。使用 Milvus 就可以以相当低的成本研发出最简可行产品。
在 Milvus 社区中最常遇到的问题之一便是:
“我想搭建一个 xx 系统,Milvus 可以实现吗?有没有供参考的项目呢?”

其实,项目组已经将许多使用 Milvus 加速 AI 应用的项目在 zilliz-bootcamp 上开放源码。而为了方便大家更加直接和简单地体验 Milvus,我们目前已经在官网上线了涉及 CV、NLP 和计算机听觉等多种领域的 4 个在线应用场景:https://zilliz.com/solutions
-
智能问答系统
-
以图搜图系统
-
音频检索系统
-
视频物体检测系统
本文将介绍上述应用场景的基本原理和使用方法,接下来就让我们开始吧!
应用场景介绍
智能问答
问答系统是自然语言处理领域中的经典应用场景,可用于回答人们以自然语言形式提出的问题。智能问答系统的经典应用场景包括:智能语音交互、在线客服、知识获取、情感类聊天等。在本应用场景中,我们将 Google 的开源模型 Bert 与向量相似性搜索引擎 Milvus 相结合,快速搭建了一个基于语义理解的智能问答机器人。
项目源码:https://github.com/zilliz-bootcamp/intelligent_question_answering_v2

使用方法
-
上传问答数据集,文件格式为 csv,其中包含 question 和 answer 两列。
-
搜索目标问题,召回相似的标准问题。
-
点击最相似的问题,得到问题答案。
使用教程:
Milvus 在线问答机器人服务 v2.0
实现原理
数据导入:
-
使用 Bert 模型将上传数据集中的标准问题转化为 768 维特征向量存储在 Milvus 中,Milvus 会返回对应 ID。
-
将这些问题的 ID 和其对应的答案存储在 PostgreSQL 中。
进行问题搜索时:
-
使用 Bert 模型将用户问题转化为特征向量。
-
在 Milvus 中对特征向量进行相似度检索,获得与用户问题最相似的标准问题的 ID。
-
在 PostgreSQL 得出对应答案。
以图搜图
想必大家都对“以图搜图”并不陌生,因为这是各类搜索引擎和购物平台中必不可少的功能。事实上,我们可以自己搭建一个以图搜图系统——建立图片库并自己选择一张图片到库中进行搜索,最终得到与其相似的若干图片。在本应用场景中,Milvus 作为一款针对海量特征向量的相似性检索引擎,可以通过结合图片特征提取模型 VGG 轻松实现以图搜图功能功能。
项目源码:https://github.com/zilliz-bootcamp/image_search
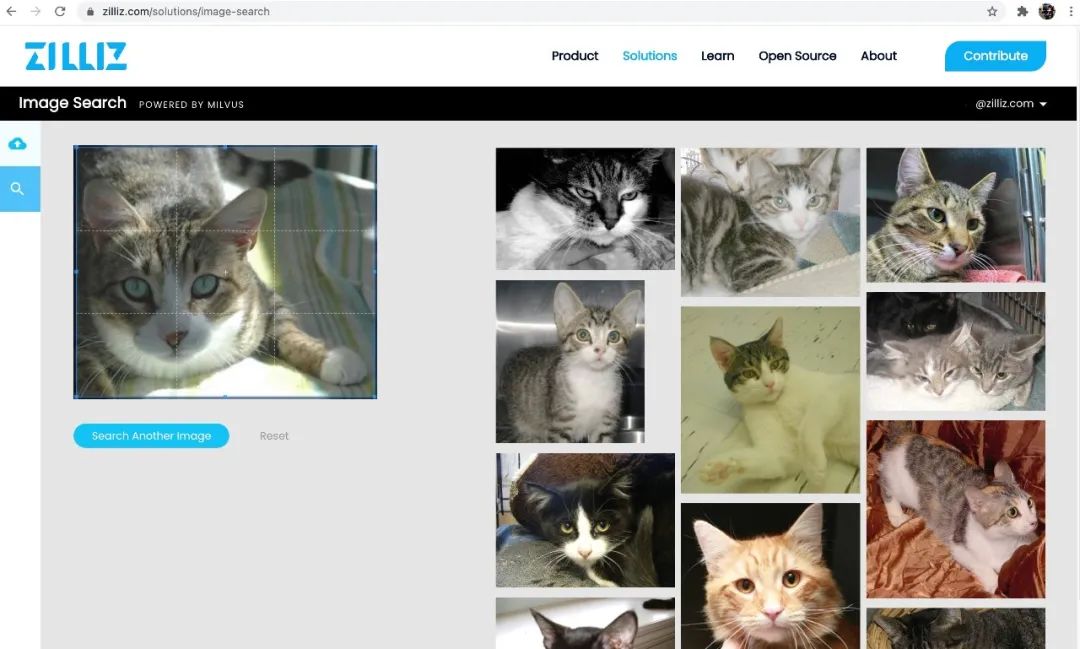
使用方法
-
上传图片数据集,文件格式为压缩包,其中只可以包含 jpg 图片。
-
上传想要搜索的图片,得到近似图片。
使用教程:
基于Milvus的以图搜图系统
实现原理
数据导入:
-
使用 VGG 模型将图片转化为 512 维特征向量存储在 Milvus 中,Milvus 会返回对应 ID。
-
将这些特征向量的 ID 和对应的图片路径存储在 CacheDB 中。
进行图片搜索时:
-
通过 VGG 模型将待搜索图片转化为特征向量。
-
在 Milvus 中对待搜索图片的特征向量进行相似度检索,得到 Milvus 库中最相似特征向量对应的 ID。
-
在 CacheDB 获得对应的图片。
音频检索
日常生活中,音频是一种重要的多媒体数据,我们会收听电台节目、欣赏在线音乐等。音频检索技术是智能语音系统的核心,具有十分广泛的应用场景。音频检索技术可以对网络媒体进行实时检索、审查和监控,从而达到保护版权的目的。音频检索技术在音频数据分类与统计中发挥着重要作用。本应用场景利用基于深度学习网络的 PANNs (Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition) 模型提取声音的特征向量,并结合 Milvus 从而提升相似音频的检索效率。
项目源码:https://github.com/zilliz-bootcamp/audio_search
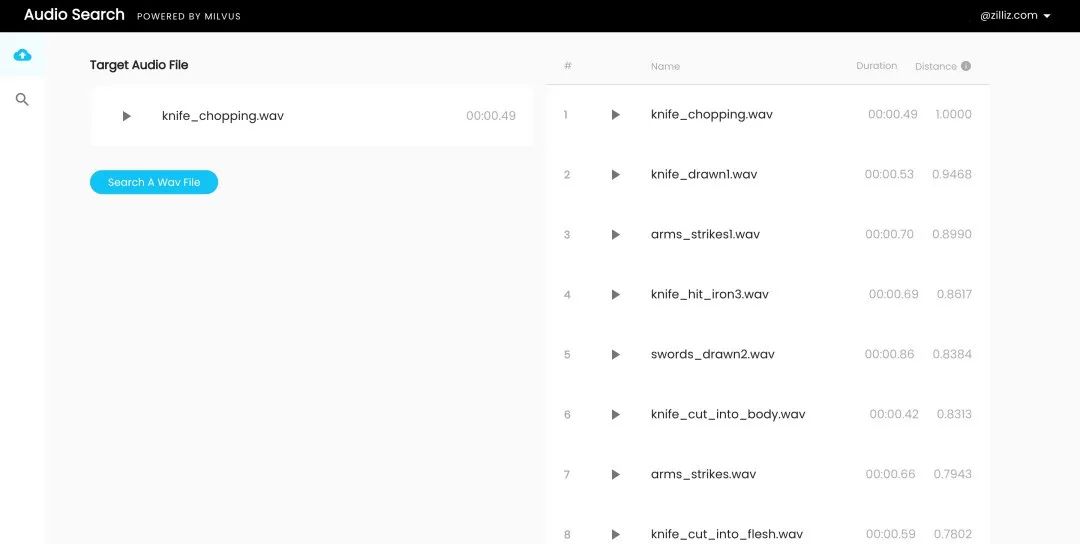
使用方法
-
上传音频数据集,其为只含有有 wav 的压缩文件。
-
上传想要搜索的音频,返回相似的音频。
使用教程:
基于Milvus的音频检索系统
实现原理
数据导入:
-
利用 panns-inference 预训练模型将音频数据转换为特征向量并导入到 Milvus 中,Milvus 将返回向量对应的 ID。
-
将返回的 ID 与音频数据的相关信息(如 wav_name)存储到 MySQL 数据库中。
进行音频检索时:
-
利用 panns-inference 预训练模型提取待检索音频数据的特征向量。
-
在 Milvus 中计算待检索音频数据特征向量与此前导入 Milvus 库中音频数据特征向量的内积距离。
-
根据检索返回结果的 ID 在 MySQL 中获取相似音频数据的信息。
视频物体检测
随着 AI 技术的飞速发展,目标检测和图像处理等技术都在学术界和工业界取得了重大突破。越来越多的 AI 平台都通过集成这些技术,并搭建了许多可以实际应用的系统。本应用场景基于 Milvus 结合了 OpenCV、YOLOv3 和 ResNet50 等技术,从而完成检测视频中物体的任务。
项目源码:https://github.com/zilliz-bootcamp/video_analysis
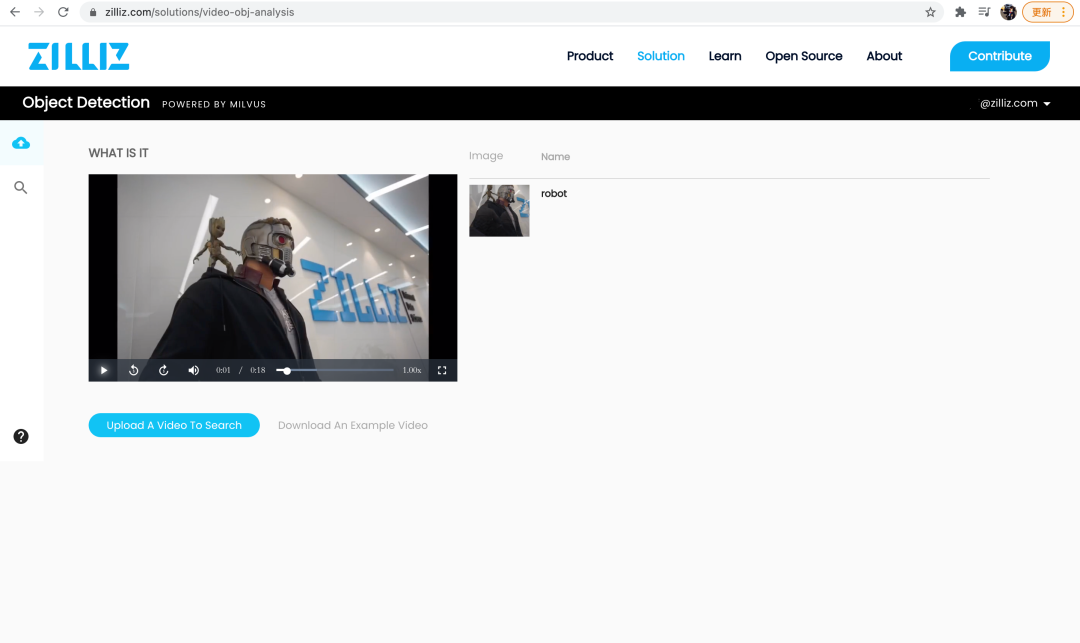
使用方法
-
上传物品数据集,其文件格式为图片压缩包,图片命名为物体名称。
-
数据导入后上传视频,系统对视频进行分析。点击播放视频即可得到每一时刻的物品检测结果。
使用教程:
基于Milvus的视频目标检测系统
实现原理
数据导入:
-
利用 ResNet50 模型提取数据集中物体特征并转化为 2048 维的向量并存储在 Milvus 中,Milvus 会返回对应 ID。
-
将 ID 与对应的名称、物体图片路径存储到 MySQL 数据库中。
进行物体检测时:
-
使用 OpenCV 对视频进行截帧处理。
-
使用 YOLOv3 网络进行目标检测。
-
使用 ResNet50 模型对视频帧中检测到的目标物体图片进行特征提取并转化为向量。
-
在 Milvus 中检索物体图像的特征向量,在 MySQL 中得到其对应名称和图片。
看了这么多 Milvus 的应用场景,有没有很心动呢?不如马上行动,来体验一下吧!如果你想与我们分享其它有趣的 Milvus 应用场景,欢迎扫码加入 Milvus 技术交流群~

欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码
milvus.io | 官网
space.bilibili.com/478166626 | Bilibili


