
深度学习-NLP-自动摘要、图像描述_图像描述 深度学习
赞
踩
自动摘要:自动将文本转换生成简短摘要的信息压缩技术
要求:足够的信息量、较低的冗余度、较高的可读性
抽取式摘要:从原文中取句子,高分句子,去掉冗余。效果一般。
Text rank 步骤:
1.去除原文的一些停用词,度量每个句子的相似度,计算得分,迭代传播,直至误差小于某一个范围。
2.对关键句子进行排序,根据摘要的长度选择一定数量的句子组成摘要。
生成式摘要
根据输入的文本获得对原文本的语义理解,逐渐成为主流。
优点是对原文有更全面的把握,更符合摘要的本质
缺点:句子的可读性、流畅度不如抽取式的。
基本框架:seq2seq,编解码结构,都是使用RNN构成,使用双向RNN构成编码器,使用单向RNN构成解码器。
关键技术:注意力机制、指针机制、
注意力机制:引入:由于长距离依赖问题,RNN到后面输入单词已经丢失了相当一部分信息;编码生成的语义向量同样丢失了大量信息,与机器翻译相同,在摘要生成的任务中同样使用了注意力机制。

指针机制 pointer mechanism
seq2seq存在的问题是:
难以准确复述原文的事实细节、无法处理原文中的未登录词、生成的摘要中存在重复的片段
一方面通过seq2seq模型保持抽象生成的能力;另一方面通过指针机制直接从原文中取词,提高摘要的准确度和缓解OOV问题
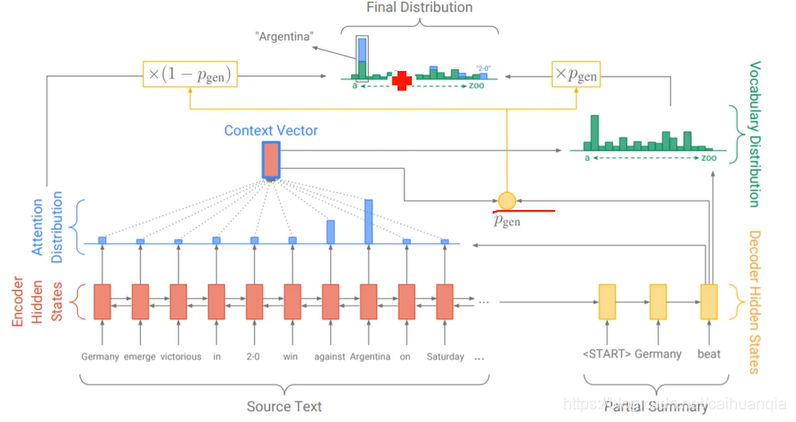
覆盖机制
文本生成存在重复的问题,解决就是coverage机制。在预测的过程中维护一个coverage向量。
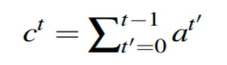
coverage向量表示过去每一笔预测中的分布的累计和,记录着模型已经关注过原文的那些词并且让这个向量影响当前步的attention计算。通过这样来避免持续关注到某些特定的词上面。
评价
自动评价指标ROUGE
ROYGE-n连续的n个词的质量
数据集:CNN/DailyMail
图像描述
生成对图像内容的自然语言的描述。
传统方法是通过人工设计的特征提取算子来提取图像的底层视觉特征,如几何、纹理、颜色等等。
问题:语义鸿沟的存在,底层的视觉特征无法对高维的语义特征进行有效的准确表达。
基于检索的方法依赖于文本描述库的大小,生成的描述不能正确适应各种场景。
基于模板的方法:将检索到的信息(可以通过检测器)组合或者将检索到的相关信息填入到预定义的语句模板的空白中。
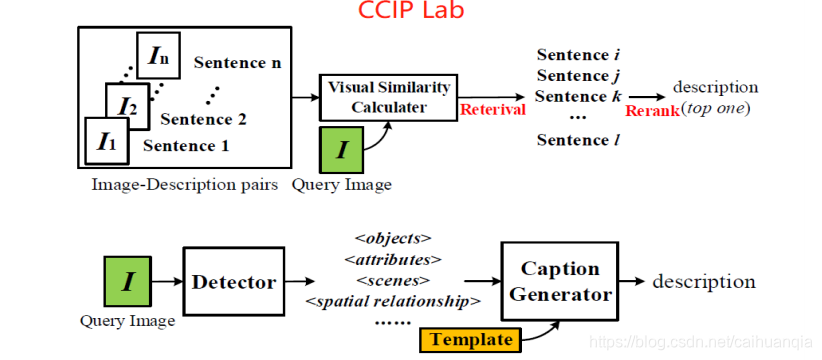
缺陷:无法生成可变长度的图像描述,限制了不同图像描述之间的多样性,描述显得呆板不自然。
深度学习:LSTM/GRU
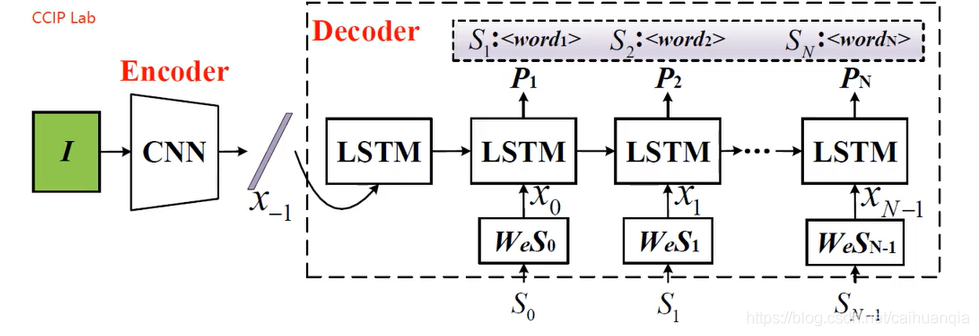
使用CNN作为encoder,使用LSTM作为decoder
开山文献:
• [Vinyals et al., 2015] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator. In CVPR, pages 3156–3164, 2015.
• [Xu et al., 2015] K. Xu, J. Ba, R. Kiros, K. Cho, A. C. Courville, R.
Salakhutdinov, R. S. Zemel, and Y. Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, pages 2048–2057,2015.
show and tell:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

