
- 1redis使用(3):哨兵、集群、_redis集群和哨兵的使用策略
- 2嵌入式系统那些事—脚本语言tcl_tcl脚本语言
- 3Java ClassNotFoundException异常解决指南
- 4机器学习(一):理解机器学习相关概念_csdn 机器学习
- 5计算机毕业设计springboot叫号系统fj6t49【附源码+数据库+部署+LW】_排队叫号业务流程spring
- 6Ubuntu22部署MySQL5.7详细教程
- 7python 三维图片 任意切片_Python3之切片及内置切片函数slice
- 8java常用设计模式 ----单例模式(简单易懂)_利用单例模式,管理文件中读取的数据,模拟程序的缓存设置。利用`get`方法获取其数
- 9Android 加入启动页_android 启动页
- 10Java Spring Session:(一)Spring Session 简介
人工智能学习与实训笔记(七):神经网络之模型压缩与知识蒸馏
赞
踩
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
七、模型压缩与知识蒸馏
出于对响应速度,存储大小和能耗的考虑,往往需要对大模型进行压缩。
7.1 模型压缩
模型压缩方法主要可以分为以下四类:
- 参数修剪和量化(Parameter pruning and quantization):用于消除对模型表现影响不大的冗余参数。早期工作表明,网络修剪和量化在降低网络复杂性和解决过拟合问题上是有效的。它可以为神经网络带来正则化效果从而提高泛化能力。参数修剪和量化可以进一步分为三类:量化和二值化,网络剪枝和结构化矩阵。量化可以看作是“量子级别的减肥”,神经网络模型的参数一般都用float32的数据表示,但如果我们将float32的数据计算精度变成int8的计算精度,则可以牺牲一点模型精度来换取更快的计算速度。而剪枝则类似“化学结构式的减肥”,将模型结构中对预测结果不重要的网络结构剪裁掉,使网络结构变得更加 ”瘦身“。比如,在每层网络,有些神经元节点的权重非常小,对模型加载信息的影响微乎其微。如果将这些权重较小的神经元删除,则既能保证模型精度不受大影响,又能减小模型大小。结构化矩阵则是用少于 m×n 个参数来描述一个 m×n 阶矩阵,以此来减少内存消耗。
- 低秩分解(Low-rank factorization):卷积神经网络中的主要计算量在于卷积计算,而卷积计算本质上是矩阵分析问题,因此可以通过对多维矩阵进行分解的方式,用多个低秩矩阵来逼近该矩阵,比如将一个3D卷积转换为3个1D卷积,从而降低参数复杂度和运算复杂度。
- 迁移/压缩卷积滤波器(Transferred/compact convolutional filters):通过构造特殊结构的卷积滤波器来降低存储空间、减小计算复杂度。
- 知识蒸馏(Knowledge distillation):类似“老师教学生”,使用一个效果好的大模型指导一个小模型训练,因为大模型可以提供更多的软分类信息量,所以会训练出一个效果接近大模型的小模型。
7.2 知识蒸馏
知识蒸馏(knowledge distillation)是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。最早是由 Hinton 在 2015 年首次提出并应用在分类任务上面,这个大模型我们称之为 teacher(教师模型),小模型我们称之为 Student(学生模型)。来自 Teacher 模型输出的监督信息称之为 knowledge(知识),而 student 学习迁移来自 teacher 的监督信息的过程称之为 Distillation(蒸馏)。
7.2.1 知识蒸馏的原理
一般使用蒸馏的时候,往往会找一个参数量更小的 student 网络,那么相比于 teacher 来说,这个轻量级的网络不能很好的学习到数据集之前隐藏的潜在关系,如上图所示,相比于 one hot 的输出,teacher 网络是将输出的 logits 进行了 softmax,更加平滑的处理了标签,即将数字 1 输出成了 0.6(对 1 的预测)和 0.4(对 0 的预测)然后输入到 student 网络中,相比于 1 来说,这种 softmax 含有更多的信息。好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让 student 学习到 teacher 的泛化能力,理论上得到的结果会比单纯拟合训练数据的 student 要好。另外,对于分类任务,如果 soft targets 的熵比 hard targets 高,那显然 student 会学习到更多的信息。最终 student 模型学习的是 teacher 模型的泛化能力,而不是“过拟合训练数据”
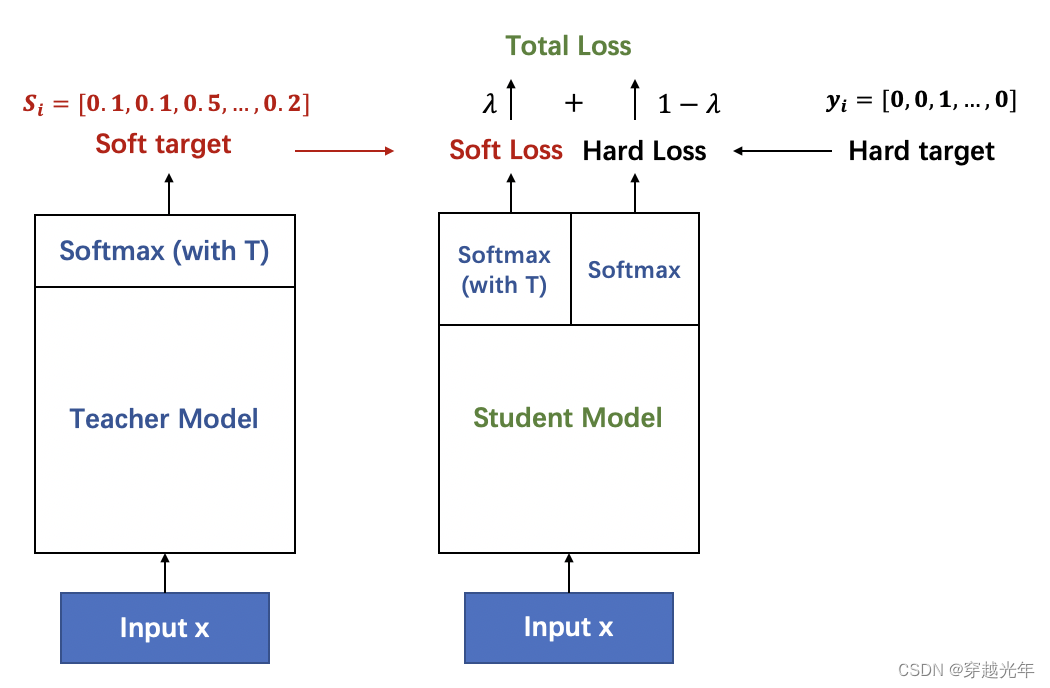
- 1. 如上图所示,左边的教师网络是一个复杂的大模型,以它带有温度参数T的softmax输出作为软目标作为学生网络学习的软目标。
- 2. 学生网络在学习时,也通过带有温度参数T的softmax进行概率分布预测,与软目标计算soft loss。
- 3. 同时,也通过正常的训练流程获得预测的样本类别与真实的样本类别计算hard loss。
- 4 最终根据 γ∗softloss+(1−γ)∗hardloss作为损失函数来训练学生网络。
这个公式就是知识蒸馏的核心理论。其实就是要让学生模型学习到老师模型的泛化能力。
7.2.2 知识蒸馏的种类
1、 离线蒸馏
离线蒸馏方式即为传统的知识蒸馏,如上图(a)。用户需要在已知数据集上面提前训练好一个 teacher 模型,然后在对 student 模型进行训练的时候,利用所获取的 teacher 模型进行监督训练来达到蒸馏的目的,而且这个 teacher 的训练精度要比 student 模型精度要高,差值越大,蒸馏效果也就越明显。一般来讲,teacher 的模型参数在蒸馏训练的过程中保持不变,达到训练 student 模型的目的。蒸馏的损失函数 distillation loss 计算 teacher 和 student 之前输出预测值的差别,和 student 的 loss 加在一起作为整个训练 loss,来进行梯度更新,最终得到一个更高性能和精度的 student 模型。
2、 半监督蒸馏
半监督方式的蒸馏利用了 teacher 模型的预测信息作为标签,来对 student 网络进行监督学习,如上图(b)。那么不同于传统离线蒸馏的方式,在对 student 模型训练之前,先输入部分的未标记的数据,利用 teacher 网络输出标签作为监督信息再输入到 student 网络中,来完成蒸馏过程,这样就可以使用更少标注量的数据集,达到提升模型精度的目的。
3、 自监督蒸馏
自监督蒸馏相比于传统的离线蒸馏的方式是不需要提前训练一个 teacher 网络模型,而是 student 网络本身的训练完成一个蒸馏过程,如上图(c)。具体实现方式 有多种,例如先开始训练 student 模型,在整个训练过程的最后几个 epoch 的时候,利用前面训练的 student 作为监督模型,在剩下的 epoch 中,对模型进行蒸馏。这样做的好处是不需要提前训练好 teacher 模型,就可以变训练边蒸馏,节省整个蒸馏过程的训练时间。
7.2.3 知识蒸馏的作用
1、提升模型精度
用户如果对目前的网络模型 A 的精度不是很满意,那么可以先训练一个更高精度的 teacher 模型 B(通常参数量更多,时延更大),然后用这个训练好的 teacher 模型 B 对 student 模型 A 进行知识蒸馏,得到一个更高精度的模型。
2、降低模型时延,压缩网络参数
用户如果对目前的网络模型 A 的时延不满意,可以先找到一个时延更低,参数量更小的模型 B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的 teacher 模型 C 来对这个参数量小的模型 B 进行知识蒸馏,使得该模型 B 的精度接近最原始的模型 A,从而达到降低时延的目的。
3、图片标签之间的域迁移
用户使用狗和猫的数据集训练了一个 teacher 模型 A,使用香蕉和苹果训练了一个 teacher 模型 B,那么就可以用这两个模型同时蒸馏出一个可以识别狗,猫,香蕉以及苹果的模型,将两个不同与的数据集进行集成和迁移。
4、降低标注量
该功能可以通过半监督的蒸馏方式来实现,用户利用训练好的 teacher 网络模型来对未标注的数据集进行蒸馏,达到降低标注量的

