
- 1ubuntu22.04安装Ros2(每步都有图)(20221124)
- 2用kithara驱动控制IS620N伺服电机简单实例_kithara不支持千兆网卡
- 3机器学习各大模型原理的深度剖析!进来学习!!_机器学习模型
- 4ESLint 的一些理解_eslint explicit
- 5ThreadPoolExecutor和ThreadPoolTaskExecutor区别_executorthreadpool 和 executorthreadtaskpool
- 6腾讯云函数 python_腾讯云函数SCF使用心得
- 7linux mysql8离线升级_mysql 8.0升级8.4
- 8人工智能 | 通俗讲解AI基础概念_人工智能 通俗讲义
- 9计算机常用英语词汇_s expected. if you encounter any issues, please re
- 10Django | 从中间件的角度来认识Django发送邮件功能
利用亚马逊云科技构建安全的端到端生成式 AI 应用程序
赞
踩
关键字: [reInforce, Langchain, Secure Generative Ai, Private Link Connectivity, Retrieval Augmented Generation, Data Ingestion Workflow, Text Generation Workflow]
本文字数: 1300, 阅读完需: 6 分钟
导读
在一场亚马逊云科技活动上,演讲者阐释了如何利用亚马逊云科技服务构建安全的端到端生成式人工智能应用程序。演讲者探讨了借助Amazon Bedrock、Private Link和检索增强生成(RAG)等服务来构建此类应用程序的方法。具体而言,演讲者指出,像Amazon Bedrock提供的基础模型可能会面临模型幻觉、缺乏领域知识以及隐私/安全隐患等挑战。该演讲重点介绍了所提出的解决方案如何通过Private Link实现数据隐私和安全性,确保符合监管合规性,并通过使用RAG从外部数据源获取上下文信息,从而释放大型语言模型(LLMs)的全部潜力。
演讲精华
以下是小编为您整理的本次演讲的精华,共1000字,阅读时间大约是5分钟。
在不断发展的尖端技术领域中,生成式人工智能(Generative AI)的出现引起了各行业组织的浓厚兴趣。然而,这一革命性领域所带来的兴奋情绪也被一些必须解决的挑战所缓和,以充分发挥其潜力。模型幻觞(Model hallucination)是一个重大障碍,即当面对超出其知识领域的查询时,AI会生成不准确的信息。此外,缺乏特定领域知识、时间意识以及隐私和安全问题进一步增加了复杂性。
在这些挑战中,该公司与一位同事在Lightfoot着手开发一个安全的端到端生成式AI云应用程序。最初被构想为针对独立软件供应商(ISVs)的解决方案,该公司的努力已经发展到为更广泛的受众服务,包括那些希望利用生成式AI同时确保数据隐私和安全的组织。可以想象一个金融机构渴望为其大型语言模型(LLMs)提供上下文客户数据,同时保持严格的安全协议。或者是一个帮助台,希望通过从网络和云基础设施中获取上下文见解来赋予其操作员更高的效率,从而更好地解决问题。这只是该应用程序可以解决的无数用例中的几个例子。
为了驾驭这个错综复杂的领域,该公司制定了一个全面的方法。首先,建立对生成式AI及其带来的挑战的基线理解。然后,深入探讨亚马逊云科技 Private Link在确保安全连接方面的关键作用。之后,探讨了Retrieval Augmented Generation(RAG)的概念,这是一种通过从外部知识库提供相关上下文信息来增强LLMs准确性和效率的技术。
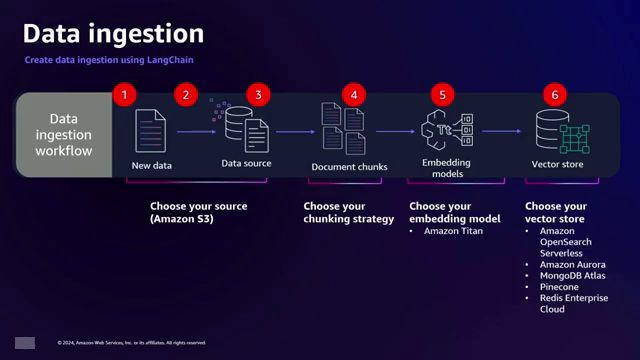
对于那些不熟悉RAG的人,让我们来解释一下。该过程主要包括两个工作流程:数据摄取和文本生成。在数据摄取阶段,相关数据源(如PDF文件)会被预处理、分块为较小的段落,并使用Amazon Titan转换为称为嵌入(embeddings)的数值表示。这些嵌入随后存储在矢量存储(如Amazon OpenSearch Serverless)中,以实现高效检索。
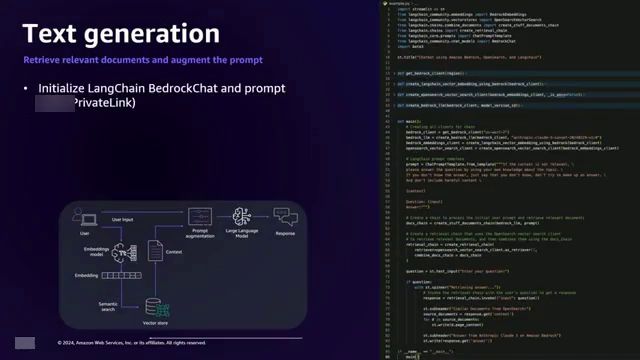
文本生成工作流程始于用户向大型语言模型(LLM)提出查询。该提示被转换为嵌入向量,然后用于在向量存储中搜索相似的嵌入向量,这些嵌入向量代表相关的上下文信息。检索到的富含上下文的数据随后与原始提示相结合,并呈现给LLM,使其能够生成更准确和更有见地的响应。
为了说明RAG(Retrieval Augmented Generation,检索增强生成)的强大功能,可以考虑一个场景,用户询问一个专有概念”Infomind”,而基础模型对此概念没有任何先验知识。如果没有RAG,LLM将坦率地承认缺乏相关信息。然而,借助RAG,LLM可以利用从向量存储中检索到的上下文数据,提供更有意义和准确的响应。
确保数据隐私和安全性是努力的重中之重。亚马逊云科技 Private Link成为一个关键组件,实现了亚马逊云科技服务与虚拟私有云(VPC)内资源之间的私有连接。通过在客户的VPC和亚马逊云科技 Bedrock服务之间建立私有链路连接,后者提供对各种基础模型(如Titan、Jurassic 2和CLOD Stable Diffusion)的访问,应用程序的流量将保持在亚马逊的私有网络内,避免暴露在公共互联网上。
安全生成式AI应用程序的实现涉及亚马逊云科技服务和Langchain Python库的协同工作。在数据摄取工作流程中,S3存储桶作为文档的来源,通过网关端点访问。事件触发器启动Lambda函数,将文档加载到S3存储桶中。Langchain随后将文档分割成块,亚马逊 Titan通过私有链路创建这些块的嵌入向量。最后,这些嵌入向量被索引到亚马逊 OpenSearch Serverless中,后者也通过私有链路访问,完成了向量存储。
在文本生成工作流程中,Langchain Bedrock Chat和Langchain Retrieval Chain通过私有链路初始化。用户的查询提示触发一个函数,该函数通过语义搜索从OpenSearch中检索相似的文档。检索到的富含上下文的数据增强了初始提示,然后通过私有链路发送到亚马逊云科技 Bedrock服务,生成一个具有上下文意识和准确性的响应。
该解决方案的底层架构体现了其稳健性和可扩展性。在单个客户账户中,应用程序负载均衡器(ALB)前置一个运行Streamlit Web应用程序的EC2实例。私有子网中托管了一个Lambda函数,该函数通过私有链路与OpenSearch建立连接,实现数据的ingestion和检索。另一个Lambda函数通过私有链路与亚马逊云科技Bedrock服务进行通信,以实现文本生成。
对于寻求将此解决方案作为服务提供的独立软件供应商(ISV)而言,架构可扩展以容纳多个客户账户。每个客户的VPC均托管Web应用程序,可通过TLS连接访问,并通过诸如Amazon Cognito之类的服务进行身份验证。网络负载均衡器(NLB)将流量路由到ALB和Web应用程序,而其余组件则与单账户架构相似,包括用于OpenSearch查询和通过私有链路进行Bedrock查询的Lambda。该架构使ISV能够将安全的生成式AI应用程序作为服务提供给客户,使他们能够利用生成式AI的强大功能,同时保持数据隐私和安全性。
该解决方案的关键优势是多方面的。首先也是最重要的,它通过明智地使用私有链路来维护数据隐私和安全性,确保跨行业的合规性。此外,通过利用RAG,它释放了LLM的全部潜力,通过整合来自外部知识库的上下文信息,提高了其准确性和效率。
总之,这款在云中的安全端到端生成式AI应用程序代表了一项开创性的努力,旨在利用生成式AI的强大功能,同时解决隐私、安全和准确性等固有挑战。通过无缝集成亚马逊云科技服务(如私有链路、Bedrock、Titan和OpenSearch Serverless)、Langchain库和RAG技术,该解决方案使组织能够自信地利用生成式AI,开启创新和效率的新领域。
下面是一些演讲现场的精彩瞬间:
基础模型是通过在某个时点利用大量非结构化数据进行预训练而获得,因此可应用于诸多用例,并且经过定制化训练,能够产生更加有意义的输出。

通过预处理和分块大型PDF文件,将相关数据存储于S3中,并借助Amazon Titan创建嵌入式向量,为语言模型提供上下文信息。
通过语义搜索从向量存储中检索相关上下文数据,并将其与原始提示相结合,从而使大型语言模型能够生成更加有意义的响应。
借助Langchain Bedrock Chat、Langchain Retrieval Chain和OpenSearch进行语义搜索,我们能够在私有链路上生成上下文相关且更加准确的聊天机器人响应。
总结
解锁基于安全云架构的生成式人工智能(Generative AI)的力量
在当今数字化时代,组织越来越多地探索利用生成式人工智能来增强其运营和服务的潜力。然而,确保数据隐私、安全性和合规性仍然是一个关键挑战。本次演讲深入探讨了一种解决方案,利用云端的安全端到端架构,发挥生成式人工智能的强大功能。
该解决方案利用Amazon Bedrock作为各种基础模型的网关,并结合检索增强生成(RAG)来克服模型虚构、缺乏领域知识和时间意识不足等挑战。通过在组织的虚拟私有云(VPC)和Bedrock服务之间建立私有链路连接,数据流量将保持在Amazon的私有网络内,从而降低了暴露在公共互联网的风险。
该解决方案包括两个关键工作流程:数据摄取和文本生成。在数据摄取阶段,相关文档经过预处理、分块,并使用Amazon Titan创建其嵌入向量。然后,这些嵌入向量通过私有链路连接被索引到向量存储中,如Amazon OpenSearch Serverless。在文本生成工作流程中,用户提示被转换为嵌入向量,用于在向量存储中搜索相关上下文。这种富含上下文的数据增强了初始提示,使基础模型能够生成更准确和更有意义的响应。
通过结合私有链路连接、RAG和安全架构,组织可以释放生成式人工智能的全部潜力,同时保持数据隐私、确保合规性,并提高准确性和效率。演讲最后提供了资源,包括使用Bedrock和RAG的研讨会,并邀请与会者进一步合作和分享代码样本。

