
- 1网络爬虫之网页数据解析(JSON与JsonPATH)_u8c22
- 2ant design Form 组件总结 结合Modal 自定义Modal的实现 (Upload Input Select DatePicker Cascader)_modalform 退出,渲染oncancel
- 3HarmonyOS学习路之方舟开发框架—学习ArkTS语言(基本语法 四)_arkts开发语言
- 4vue百度地图通过地址名称来获取该地址的经纬度gps_vue 百度地图 标注 获取 经纬度
- 5Unity Koreographer 之 音乐制作插件介绍学习,一般使用步骤介绍(包括:一般音乐游戏制作流程简绍) 一
- 6微信小程序底部实现自定义动态Tabbar_微信下程序中动态使用tabbar
- 7解决使用element-plus时使用el-select-v2组件时,选中后无法移除focus的状态的方法。_element ui el-select-v2
- 8地图常见操作总结_settrafficoff
- 9C# 浮点类型,长度,范围,精度,定义和赋值_c#float中浮点类型
- 10前端炫酷登录页,拿来就能用_好看的前端登陆页面
书生·浦语大模型实战营学习笔记(一)
赞
踩
教程链接:GitHub - InternLM/tutorial
视频链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
书生·浦语大模型全链路开源体系
从模型到应用:


数据
2TB数据 覆盖多种模态和任务
开源多模态语料库书生万卷1.0,包括文本数据、图像文本数据、视频数据,覆盖科技、文学、媒体、教育多个领域


预训练工具

微调
大语言模型的下游应用中,增量续训和有监督微调是经常会用到两种方式。
增量续训:使用场景:让基座模型学习到一些新知识,如某个垂类领域知识。训练数据:文章、书籍、代码等。训练数据的形式和格式与预训练一致。
有监督微调:使用场景:让模型学会理解和遵循各种指令,或者注入少量领域知识。训练数据:高质量的对话、问答数据。有监督微调通常采用全量参数微调和部分参数微调。以lora为例,将预训练权重固定,引入小的训练参数,减少训练代价。
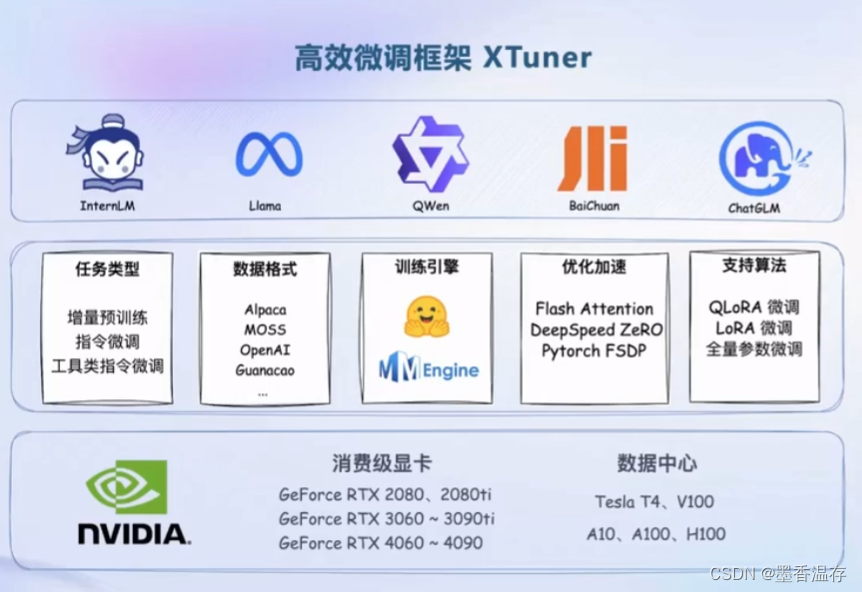
高效的微调框架XTuner:能够适配多种生态,包括多种微调策略与算法,覆盖各类 SFT 场景;适配多种开源生态支持加载 HuggingFace、ModelScope 模型或数据集;自动优化加速开发者无需关注复杂的显存优化与计算加速细节。适配多种硬件:训练方案覆盖 NVIDIA 20 系以上所有显卡,最低只需 8GB 显存即可微调 7B 模型。
 评测
评测
 目前国内外的评测体系有些为客观评测,有些是主观评测,也有部分主管和客观都支持。但从全面性来讲不能满足大模型的发展。
目前国内外的评测体系有些为客观评测,有些是主观评测,也有部分主管和客观都支持。但从全面性来讲不能满足大模型的发展。
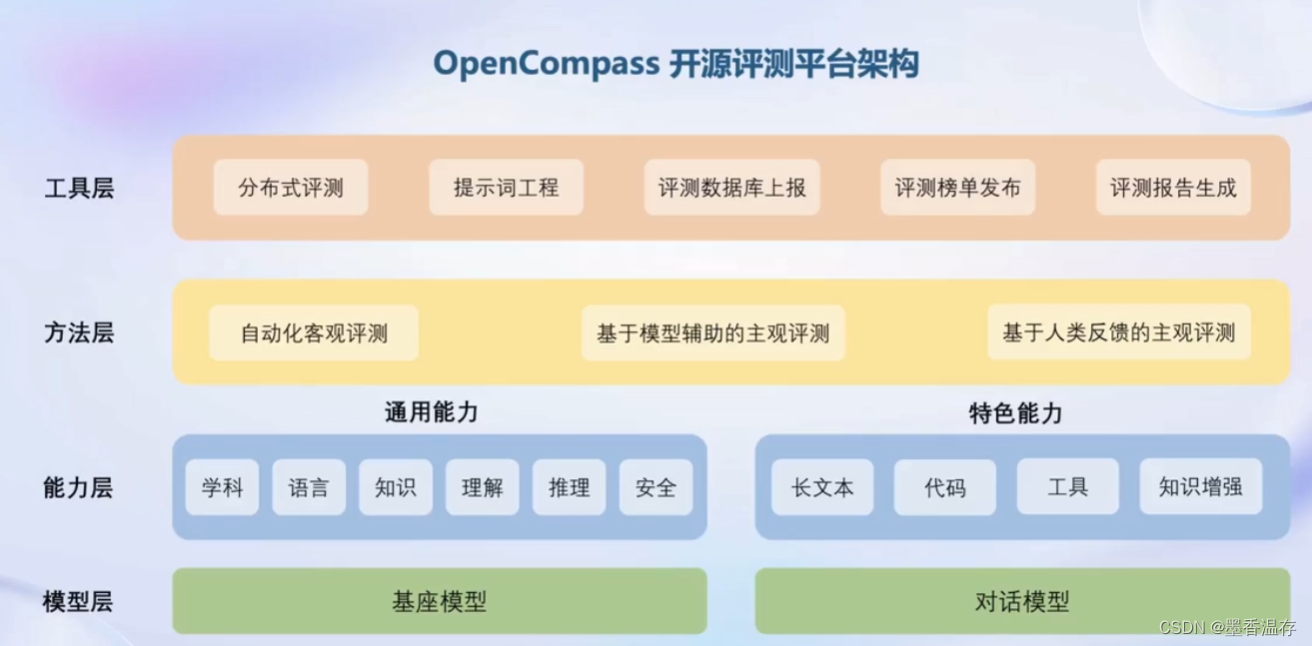
提出了OpenCompass评测体系,提供了六大维度,支持80+评测集,40万+评测题目。将大模型能力分为学科、语言、知识、理解、推理、安全六大维度。再在每个大维度中间细分,避免只关注某一个能力维度。
OpenCompass不仅提供了评测体系,也提供了多层可使用的工具。
 部署
部署
大语言模型特点:
- 内存开销巨:庞大的参数量,采用自回归生成token,需要缓存k/v
- 动态Shape:请求数不固定,token逐个生成,且数量不定
- 模型结构相对简单:transformer结构,大部分是decoder-only
技术挑战:
- 设备:低存储设备(消费级显卡、移动.端等) 如何部署?
- 推理:如何加速 token 的生成速度;如何解决动态shape,让推理可以不间断;如何有效管理和利用内存
- 服务:提升系统整体吞吐量;降低请求的平均响应时间
部署方案
技术点
- 模型并行
- 低比特量化
- Attention优化
- 计算和访存优化
- Continuous Batching
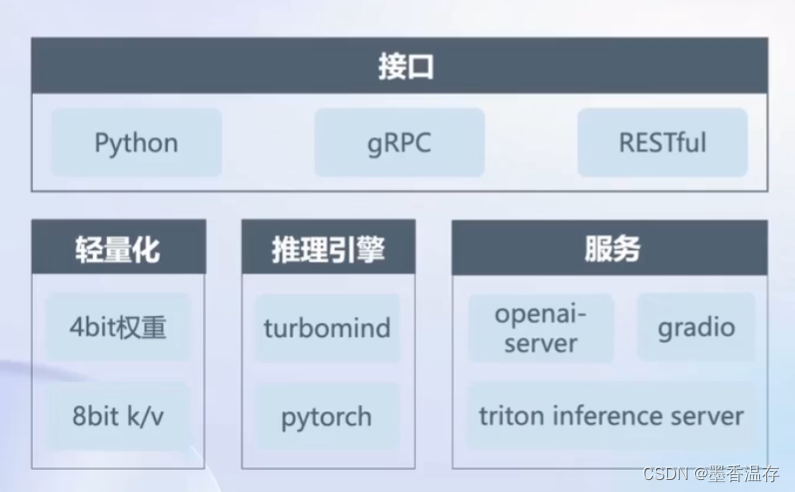
为解决大语言模型部署所遇到的挑战开发了LMDeploy推理框架。模型轻量化、推理、服务都能解决。对外提供python接口,gRPC接口,RESTful接口。
智能体应用
大语言模型的局限性:
- 最新信息和知识的获取
- 回复的可靠性
- 数学计算
- 工具使用和交互
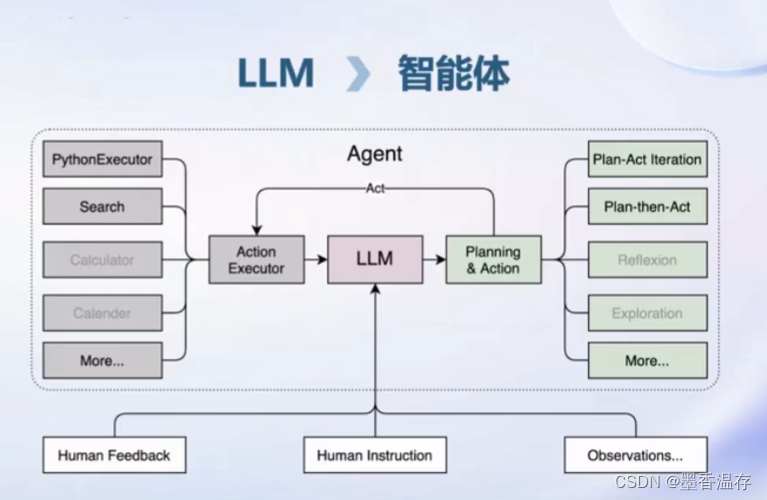
开源了一个轻量级智能体框架Lagent
 针对智能体打造了多模态智能体工具箱 AgentLego
针对智能体打造了多模态智能体工具箱 AgentLego
- 丰富的工具集合,尤其是提供了大量视觉、多模态相关领域的前沿算法功能
- 支持多个主流智能体系统,如 LangChain,Transformers Agent,Lagent 等
- 灵活的多模态工具调用接口,可以轻松支持各类输入输出格式的工具函数
- 一键式远程工具部署,轻松使用和调试大模型智能体


