
- 12022年5月、11月网络工程师真题详解_快速获得lun在某时刻完整数据拷贝
- 2java markdown协作_课外资源 - 基于Java实现的多用户同步MarkDown编辑器
- 3网络安全人才缺口巨大,现在网安工程师能挣多少钱?_网络安全工程师挣钱吗
- 4Android AIDL 实现两个APP之间的跨进程通信实例_android 两个app类调用
- 5python大一基础题_Python 基础练习题
- 6java计算机毕业设计基于安卓Android/微信小程序的在线装修预定系统APP_基于安卓的家装erp系统设计
- 7使用GitHub API 查询开源项目信息
- 8Mac 系统安装maven_mac 安装 maven
- 9【强化学习】PPO算法求解倒立摆问题 + Pytorch代码实战_ppo算法代码
- 10Element-UI:el-table样式修改_el-table 样式修改
RAD-NeRF模型训练教程
赞
踩
仓库:wwaityousea/xuniren (github.com)
数字人解决方案——基于真人视频的三维重建数字人源码与训练方法
article/2023/6/29 3:30:50
前言
1.真人视频三维重建数字人源码是基于NeRF改进的RAD-NeRF,NeRF(Neural Radiance Fields)是最早在2020年ECCV会议上的Best Paper,其将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景。
NeRF其输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片。也可以简要概括为用一个MLP神经网络去隐式地学习一个三维场景。
NeRF最先是应用在新视点合成方向,由于其超强的隐式表达三维信息的能力后续在三维重建方向迅速发展起来。
2.NeRF使用的场景有几个主流应用方向:
新视点合成:

物体精细重建:

城市重建:

人体重建:

3.真人视频合成
通过音频空间分解的实时神经辐射谈话肖像合成

一、训练环境
1.系统要求
我是在win下训练,训练的环境为win 10,GPU RTX 3080 12G,CUDA 11.7,cudnn 8.5,Anaconda 3,Vs2019。
2.环境依赖
使用conda环境进行安装,python 3.10
- #下载源码
- git clone https://github.com/ashawkey/RAD-NeRF.git
- cd RAD-NeRF
- #创建虚拟环境
- conda create --name vrh python=3.10
- #pytorch 要单独对应cuda进行安装,要不然训练时使用不了GPU
- conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
- conda install -c fvcore -c iopath -c conda-forge fvcore iopath
- #安装所需要的依赖
- pip install -r requirements.txt
3.windows下安装pytorch3d,这个依赖还是要在刚刚创建的conda环境里面进行安装。
- git clone https://github.com/facebookresearch/pytorch3d.git
- cd pytorch3d
- python setup.py install
安装pytorch3d很慢,也有可能中间报错退出,这里建议安装vs 生成工具。Microsoft C++ 生成工具 - Visual Studio https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
二、数据准备
1.从网上上下载或者自己拍摄一段不大于5分钟的视频,视频人像单一,面对镜头,背景尽量简单,这是方便等下进行抠人像与分割人脸用的。我这里从网上下载了一段5分钟左右的视频,然后视频编辑软件,只切取一部分上半身和头部的画面。按1比1切取。这里的剪切尺寸不做要求,只是1比1就可以了。
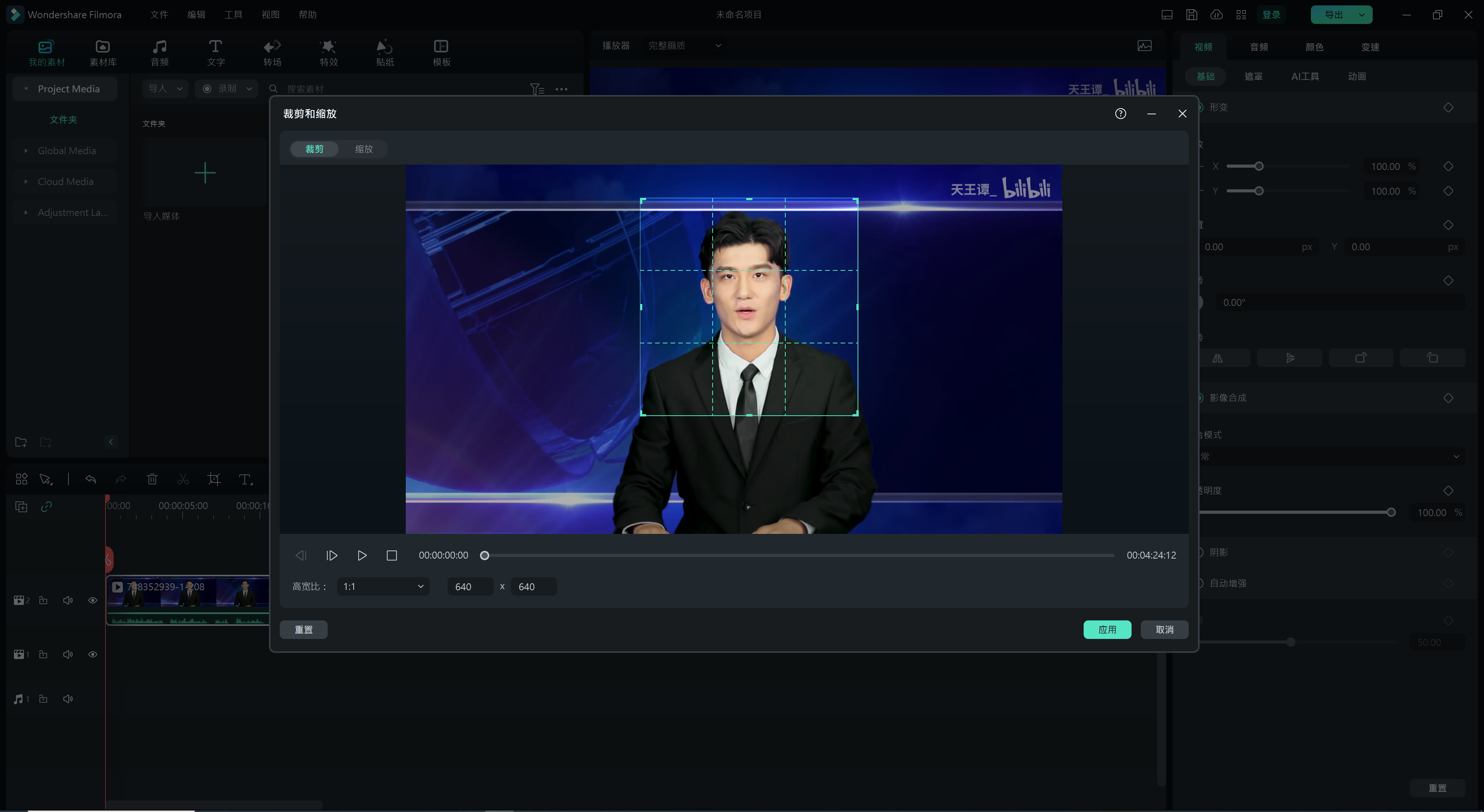
2.把视频剪切项目参数设置成1比1,分辨率设成512*512。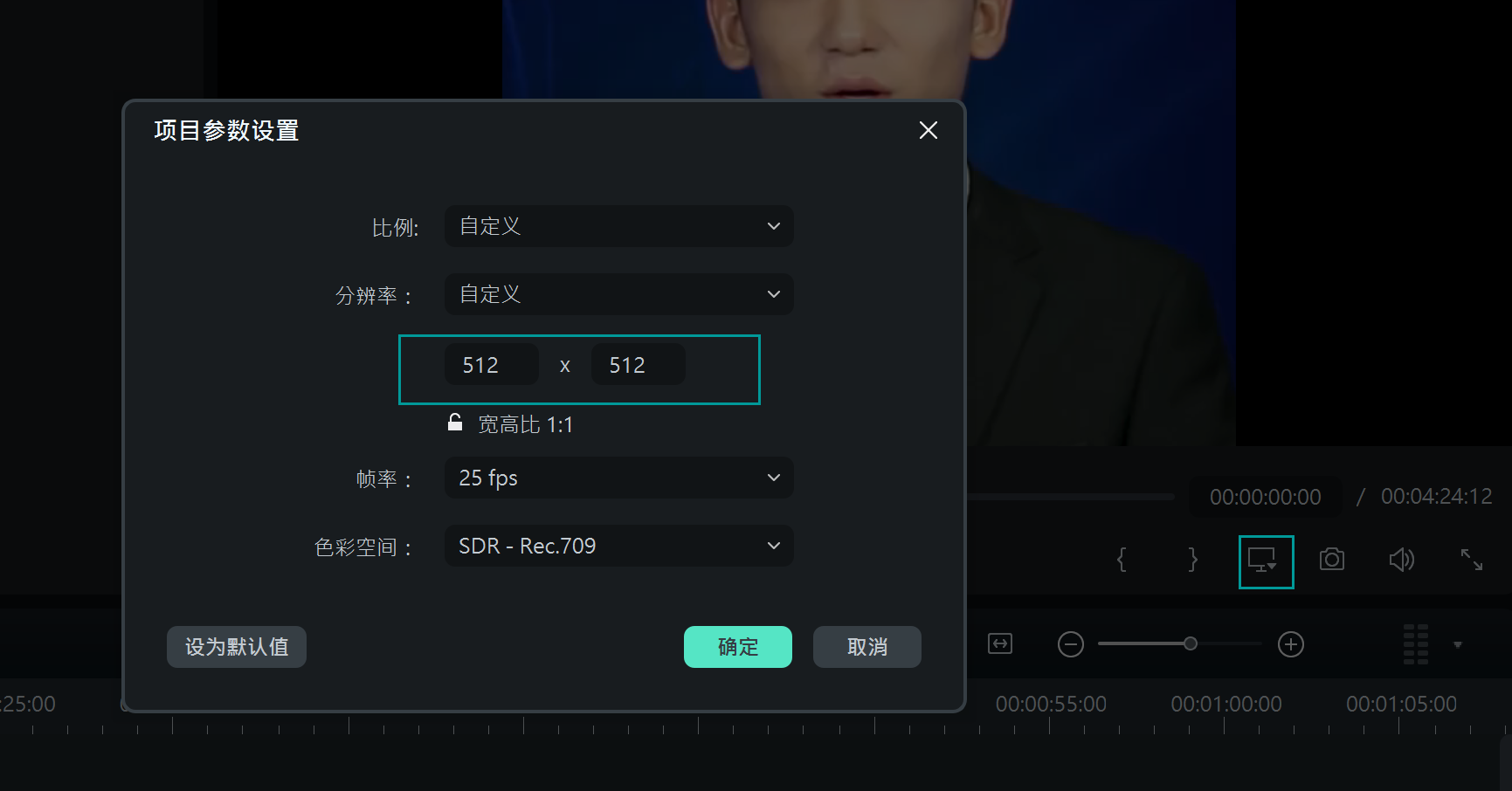
3.数据长宽按512*512,25fps,mp4格式导出视频。
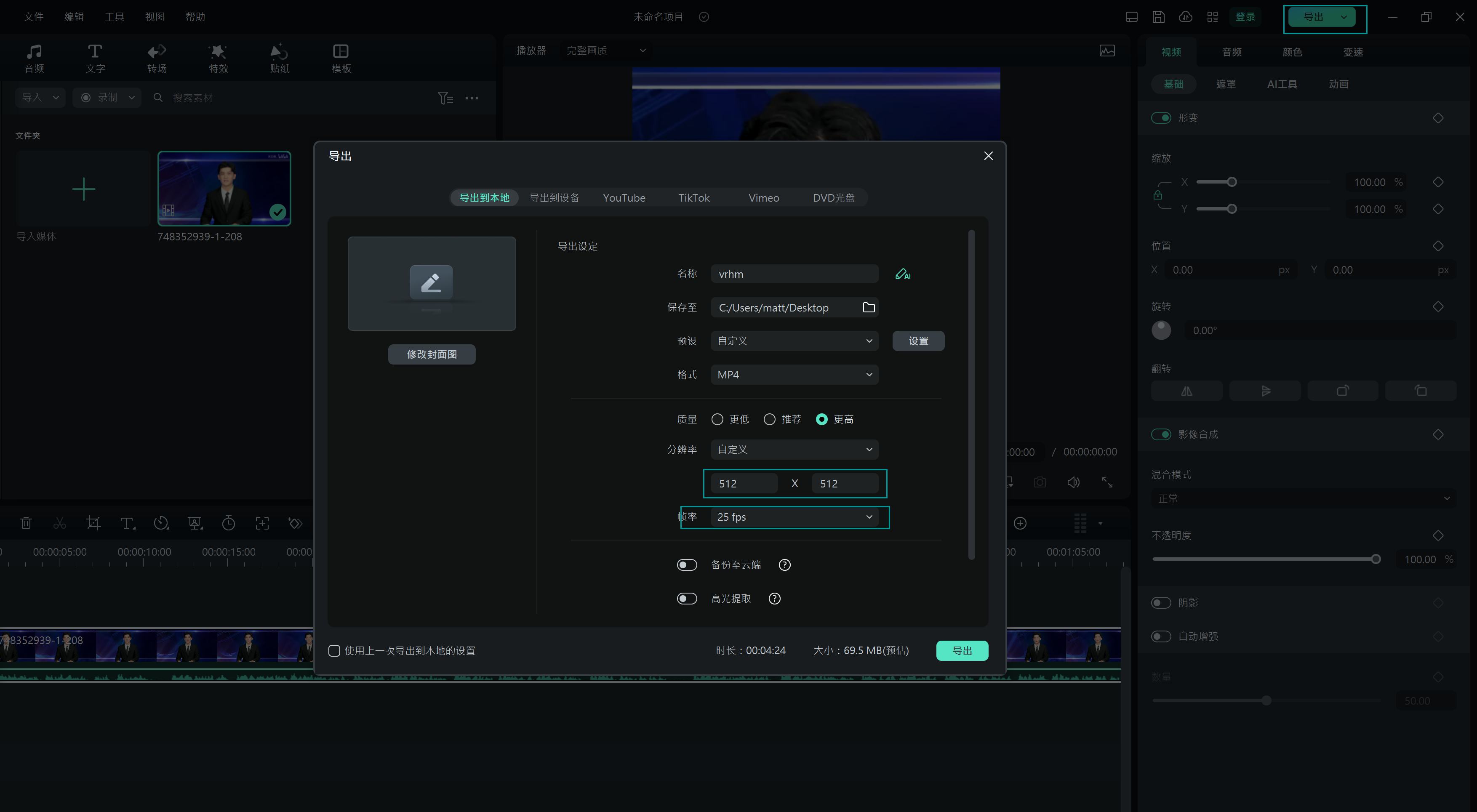
4.把导出的数据放到项目目录下,如下图所示, 我这里面在data下载创建了一个与文件名一样的目录,然后把刚刚剪切的视频放进目录里面。

视频数据如下:

三、人脸模型准备
1.人脸解析模型
模型是从AD-NeRF这个项目获取。下载AD-NeRF这个项目。
git clone https://github.com/YudongGuo/AD-NeRF.git把AD-NeRF项目下的data_utils/face_parsing/79999_iter.pth复制到RAD-NeRF/data_utils/face_parsing/79999_iter.pth 。
或者在RAD-NeRF目录直接下载,这种方式可能会出现下载不了。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth2.basel脸部模型处理
从AD-NeRF/data_utils/face_trackong项目里面的3DMM这个目录复制到Rad-NeRF/data_utils/face_trackong里面
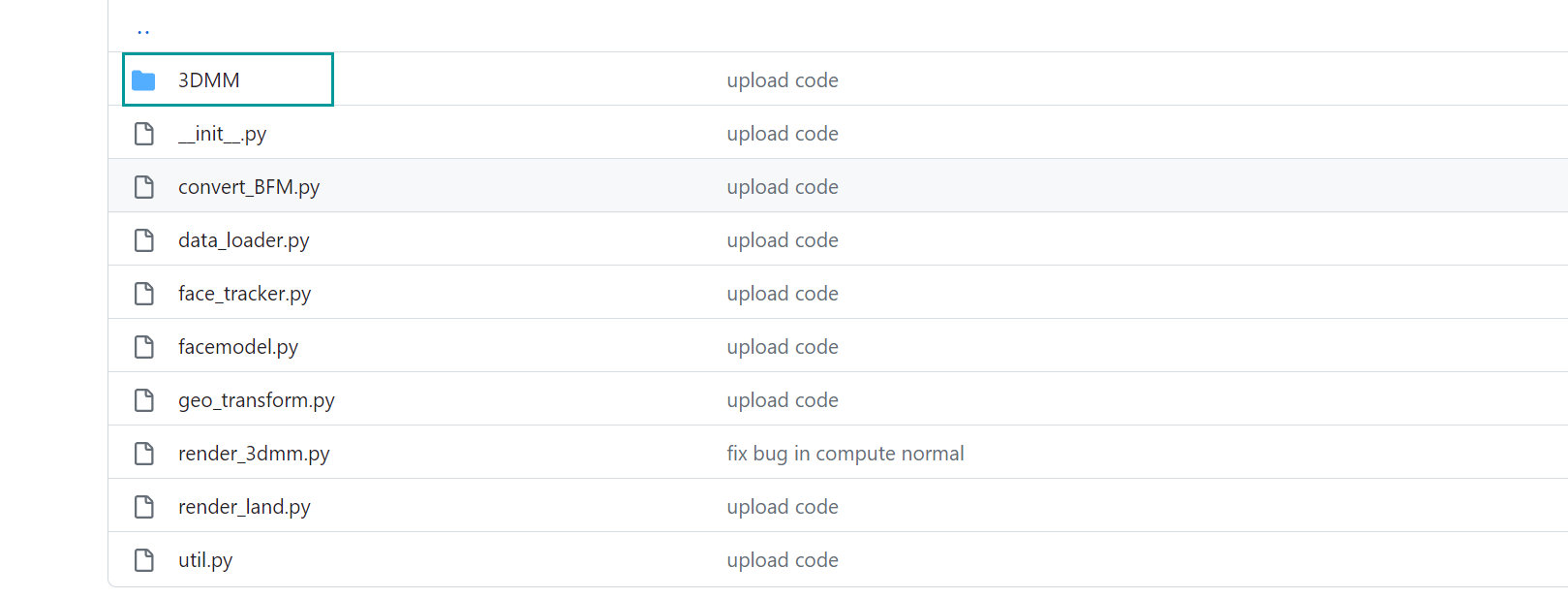
移动到的位置:
或者是在Rad_NeRF项目下,直接下载,命令如下:
- wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth## prepare basel face model
- # 1. download `01_MorphableModel.mat` from https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads and put it under `data_utils/face_tracking/3DMM/`
- # 2. download other necessary files from AD-NeRF's repository:
- wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy
- wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy
- wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj
- wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy
从https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads下载01_MorphableModel.mat放到Rad-NeRF/data_utils/face_trackong/3DMM里面。
运行
- cd xx/xx/Rad-NeRF/data_utils/face_tracking
- python convert_BFM.py
四、数据处理
1.处理数据
- #按自己的数据与目录来运行对应的路径
- python data_utils/process.py data/vrhm/vrhm.mp4
在这一步会下载四个模型,如果没有魔法上网,这四个模型下载很慢,或者直接下到一半就崩掉了。
也可以先把这个模型下载好之后放到指定的目录,在处理的过程中就不会再次下载,模型下载路径:
- https://download.pytorch.org/models/resnet18-5c106cde.pth
- https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
- https://www.adrianbulat.com/downloads/python-fan/2DFAN4-cd938726ad.zip
- https://download.pytorch.org/models/alexnet-owt-7be5be79.pth
下载完成之后,把四个模型放到指定目录,如果目录则创建目录之后再放入。目录如下:
2.处理数据时,会在data所放的视频目录下生成以下几个目录:
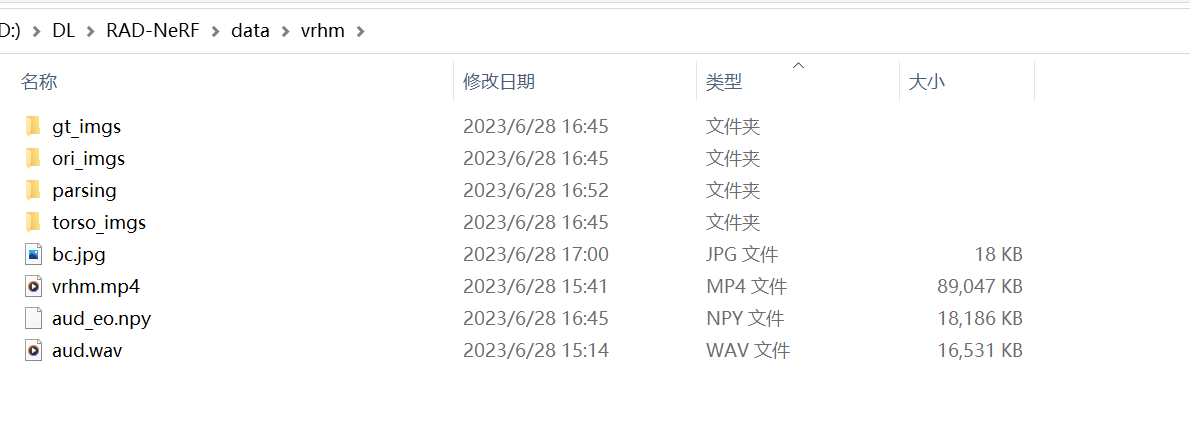
这里主要注意的是parsing这个目录,目录下的数据是分割后的数据。

这里要注意分割的质量,如果分割质量不好,就要借助别的工具先做人像分割,要不然训练出来的人物会出现透背景或者断开的现象。比如我之后处理的数据:

这里人的脖子下面有一块白的色块,训练完成之后,生成数字人才发现,这块区域是分割模型把它当背景了,合成视频时,这块是绿色的背景,直接废了。
在数据准备中,也尽量不要这种头发披下来的,很容易出现拼接错落的现象。

我在使用这个数据训练时,刚刚开始不清楚其中的关键因素,第一次训练效果如下,能感觉到头部与身体的连接并不和协。

五、模型训练
先看看训练代码的给的参数,训练时只要关注几个主要参数就可以了。
- import torch
- import argparsefrom nerf.provider import NeRFDataset
- from nerf.gui import NeRFGUI
- from nerf.utils import *# torch.autograd.set_detect_anomaly(True)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('path', type=str)parser.add_argument('-O', action='store_true', help="equals --fp16 --cuda_ray --exp_eye")parser.add_argument('--test', action='store_true', help="test mode (load model and test dataset)")parser.add_argument('--test_train', action='store_true', help="test mode (load model and train dataset)")parser.add_argument('--data_range', type=int, nargs='*', default=[0, -1], help="data range to use")parser.add_argument('--workspace', type=str, default='workspace')parser.add_argument('--seed', type=int, default=0)### training optionsparser.add_argument('--iters', type=int, default=200000, help="training iters")parser.add_argument('--lr', type=float, default=5e-3, help="initial learning rate")parser.add_argument('--lr_net', type=float, default=5e-4, help="initial learning rate")parser.add_argument('--ckpt', type=str, default='latest')parser.add_argument('--num_rays', type=int, default=4096 * 16, help="num rays sampled per image for each training step")parser.add_argument('--cuda_ray', action='store_true', help="use CUDA raymarching instead of pytorch")parser.add_argument('--max_steps', type=int, default=16, help="max num steps sampled per ray (only valid when using --cuda_ray)")parser.add_argument('--num_steps', type=int, default=16, help="num steps sampled per ray (only valid when NOT using --cuda_ray)")parser.add_argument('--upsample_steps', type=int, default=0, help="num steps up-sampled per ray (only valid when NOT using --cuda_ray)")parser.add_argument('--update_extra_interval', type=int, default=16, help="iter interval to update extra status (only valid when using --cuda_ray)")parser.add_argument('--max_ray_batch', type=int, default=4096, help="batch size of rays at inference to avoid OOM (only valid when NOT using --cuda_ray)")### network backbone optionsparser.add_argument('--fp16', action='store_true', help="use amp mixed precision training")parser.add_argument('--lambda_amb', type=float, default=0.1, help="lambda for ambient loss")parser.add_argument('--bg_img', type=str, default='', help="background image")parser.add_argument('--fbg', action='store_true', help="frame-wise bg")parser.add_argument('--exp_eye', action='store_true', help="explicitly control the eyes")parser.add_argument('--fix_eye', type=float, default=-1, help="fixed eye area, negative to disable, set to 0-0.3 for a reasonable eye")parser.add_argument('--smooth_eye', action='store_true', help="smooth the eye area sequence")parser.add_argument('--torso_shrink', type=float, default=0.8, help="shrink bg coords to allow more flexibility in deform")### dataset optionsparser.add_argument('--color_space', type=str, default='srgb', help="Color space, supports (linear, srgb)")parser.add_argument('--preload', type=int, default=0, help="0 means load data from disk on-the-fly, 1 means preload to CPU, 2 means GPU.")# (the default value is for the fox dataset)parser.add_argument('--bound', type=float, default=1, help="assume the scene is bounded in box[-bound, bound]^3, if > 1, will invoke adaptive ray marching.")parser.add_argument('--scale', type=float, default=4, help="scale camera location into box[-bound, bound]^3")parser.add_argument('--offset', type=float, nargs='*', default=[0, 0, 0], help="offset of camera location")parser.add_argument('--dt_gamma', type=float, default=1/256, help="dt_gamma (>=0) for adaptive ray marching. set to 0 to disable, >0 to accelerate rendering (but usually with worse quality)")parser.add_argument('--min_near', type=float, default=0.05, help="minimum near distance for camera")parser.add_argument('--density_thresh', type=float, default=10, help="threshold for density grid to be occupied (sigma)")parser.add_argument('--density_thresh_torso', type=float, default=0.01, help="threshold for density grid to be occupied (alpha)")parser.add_argument('--patch_size', type=int, default=1, help="[experimental] render patches in training, so as to apply LPIPS loss. 1 means disabled, use [64, 32, 16] to enable")parser.add_argument('--finetune_lips', action='store_true', help="use LPIPS and landmarks to fine tune lips region")parser.add_argument('--smooth_lips', action='store_true', help="smooth the enc_a in a exponential decay way...")parser.add_argument('--torso', action='store_true', help="fix head and train torso")parser.add_argument('--head_ckpt', type=str, default='', help="head model")### GUI optionsparser.add_argument('--gui', action='store_true', help="start a GUI")parser.add_argument('--W', type=int, default=450, help="GUI width")parser.add_argument('--H', type=int, default=450, help="GUI height")parser.add_argument('--radius', type=float, default=3.35, help="default GUI camera radius from center")parser.add_argument('--fovy', type=float, default=21.24, help="default GUI camera fovy")parser.add_argument('--max_spp', type=int, default=1, help="GUI rendering max sample per pixel")### elseparser.add_argument('--att', type=int, default=2, help="audio attention mode (0 = turn off, 1 = left-direction, 2 = bi-direction)")parser.add_argument('--aud', type=str, default='', help="audio source (empty will load the default, else should be a path to a npy file)")parser.add_argument('--emb', action='store_true', help="use audio class + embedding instead of logits")parser.add_argument('--ind_dim', type=int, default=4, help="individual code dim, 0 to turn off")parser.add_argument('--ind_num', type=int, default=10000, help="number of individual codes, should be larger than training dataset size")parser.add_argument('--ind_dim_torso', type=int, default=8, help="individual code dim, 0 to turn off")parser.add_argument('--amb_dim', type=int, default=2, help="ambient dimension")parser.add_argument('--part', action='store_true', help="use partial training data (1/10)")parser.add_argument('--part2', action='store_true', help="use partial training data (first 15s)")parser.add_argument('--train_camera', action='store_true', help="optimize camera pose")parser.add_argument('--smooth_path', action='store_true', help="brute-force smooth camera pose trajectory with a window size")parser.add_argument('--smooth_path_window', type=int, default=7, help="smoothing window size")# asrparser.add_argument('--asr', action='store_true', help="load asr for real-time app")parser.add_argument('--asr_wav', type=str, default='', help="load the wav and use as input")parser.add_argument('--asr_play', action='store_true', help="play out the audio")parser.add_argument('--asr_model', type=str, default='cpierse/wav2vec2-large-xlsr-53-esperanto')# parser.add_argument('--asr_model', type=str, default='facebook/wav2vec2-large-960h-lv60-self')parser.add_argument('--asr_save_feats', action='store_true')# audio FPSparser.add_argument('--fps', type=int, default=50)# sliding window left-middle-right length (unit: 20ms)parser.add_argument('-l', type=int, default=10)parser.add_argument('-m', type=int, default=50)parser.add_argument('-r', type=int, default=10)opt = parser.parse_args()if opt.O:opt.fp16 = Trueopt.exp_eye = Trueif opt.test:opt.smooth_path = Trueopt.smooth_eye = Trueopt.smooth_lips = Trueopt.cuda_ray = True# assert opt.cuda_ray, "Only support CUDA ray mode."if opt.patch_size > 1:# assert opt.patch_size > 16, "patch_size should > 16 to run LPIPS loss."assert opt.num_rays % (opt.patch_size ** 2) == 0, "patch_size ** 2 should be dividable by num_rays."if opt.finetune_lips:# do not update density grid in finetune stageopt.update_extra_interval = 1e9from nerf.network import NeRFNetworkprint(opt)seed_everything(opt.seed)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = NeRFNetwork(opt)# manually load state dict for headif opt.torso and opt.head_ckpt != '':model_dict = torch.load(opt.head_ckpt, map_location='cpu')['model']missing_keys, unexpected_keys = model.load_state_dict(model_dict, strict=False)if len(missing_keys) > 0:print(f"[WARN] missing keys: {missing_keys}")if len(unexpected_keys) > 0:print(f"[WARN] unexpected keys: {unexpected_keys}") # freeze these keysfor k, v in model.named_parameters():if k in model_dict:# print(f'[INFO] freeze {k}, {v.shape}')v.requires_grad = False# print(model)criterion = torch.nn.MSELoss(reduction='none')if opt.test:if opt.gui:metrics = [] # use no metric in GUI for faster initialization...else:# metrics = [PSNRMeter(), LPIPSMeter(device=device)]metrics = [PSNRMeter(), LPIPSMeter(device=device), LMDMeter(backend='fan')]trainer = Trainer('ngp', opt, model, device=device, workspace=opt.workspace, criterion=criterion, fp16=opt.fp16, metrics=metrics, use_checkpoint=opt.ckpt)if opt.test_train:test_set = NeRFDataset(opt, device=device, type='train')# a manual fix to test on the training datasettest_set.training = False test_set.num_rays = -1test_loader = test_set.dataloader()else:test_loader = NeRFDataset(opt, device=device, type='test').dataloader()# temp fix: for update_extra_statesmodel.aud_features = test_loader._data.audsmodel.eye_areas = test_loader._data.eye_areaif opt.gui:# we still need test_loader to provide audio features for testing.with NeRFGUI(opt, trainer, test_loader) as gui:gui.render()else:### evaluate metrics (slow)if test_loader.has_gt:trainer.evaluate(test_loader)### test and save video (fast) trainer.test(test_loader)else:optimizer = lambda model: torch.optim.Adam(model.get_params(opt.lr, opt.lr_net), betas=(0.9, 0.99), eps=1e-15)train_loader = NeRFDataset(opt, device=device, type='train').dataloader()assert len(train_loader) < opt.ind_num, f"[ERROR] dataset too many frames: {len(train_loader)}, please increase --ind_num to this number!"# temp fix: for update_extra_statesmodel.aud_features = train_loader._data.audsmodel.eye_area = train_loader._data.eye_areamodel.poses = train_loader._data.poses# decay to 0.1 * init_lr at last iter stepif opt.finetune_lips:scheduler = lambda optimizer: optim.lr_scheduler.LambdaLR(optimizer, lambda iter: 0.05 ** (iter / opt.iters))else:scheduler = lambda optimizer: optim.lr_scheduler.LambdaLR(optimizer, lambda iter: 0.1 ** (iter / opt.iters))metrics = [PSNRMeter(), LPIPSMeter(device=device)]eval_interval = max(1, int(5000 / len(train_loader)))trainer = Trainer('ngp', opt, model, device=device, workspace=opt.workspace, optimizer=optimizer, criterion=criterion, ema_decay=0.95, fp16=opt.fp16, lr_scheduler=scheduler, scheduler_update_every_step=True, metrics=metrics, use_checkpoint=opt.ckpt, eval_interval=eval_interval)if opt.gui:with NeRFGUI(opt, trainer, train_loader) as gui:gui.render()else:valid_loader = NeRFDataset(opt, device=device, type='val', downscale=1).dataloader()max_epoch = np.ceil(opt.iters / len(train_loader)).astype(np.int32)print(f'[INFO] max_epoch = {max_epoch}')trainer.train(train_loader, valid_loader, max_epoch)# free some memdel train_loader, valid_loadertorch.cuda.empty_cache()# also testtest_loader = NeRFDataset(opt, device=device, type='test').dataloader()if test_loader.has_gt:trainer.evaluate(test_loader) # blender has gt, so evaluate it.trainer.test(test_loader)
参数:
--preload 0:从硬盘加载数据
--preload 1: 指定CPU,约70G内存
--preload 2: 指定GPU,约24G显存
1.头部训练
python main.py data/vrhm/ --workspace trial_vrhm/ -O --iters 2000002.唇部微调
python main.py data/vrhm/ --workspace trial_vrhm/ -O --iters 500000 --finetune_lips3.身体部分训练
python main.py data/vrhm/ --workspace trial_vrhm_torso/ -O --torso --head_ckpt <trial_ID>/checkpoints/npg_xxx.pth> --iters 200000 --preload 2
六、报错解决
报错No module named 'sklearn'
pip install -U scikit-learn附:xuniren windows安装教程
NeRF视频三维重建视频训练步骤:
环境说明:
官方:Ubuntu 22.04,Pytorch 1.12 and CUDA 11.6。
实测:Ubuntu 20.04,PyTorch 1.11.0,Python 3.8(ubuntu20.04),Cuda 11.3。
视频训练(fay):
一、训练准备
1.使用以下仓库进行模型训练
git clone https://github.com/ashawkey/RAD-NeRF.git
cd RAD-NeRF
2.安装依赖
sudo apt install portaudio19-dev
sudo apt install ffmpeg
pip install -r requirements.txt
3.生成扩展
bash scripts/install_ext.sh
4.安装pytorch3d
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
二、视频数据预处理
1.视频要求
512*512像素,25FPS,1~5分钟,mp4格式。
(用V100或者3090,视频大于4分钟,训练效果不太理想,3分钟左右会比较合适。)
2.安装pytorch3d
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
3.准备人脸解析模型
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth
4.准备basel脸部模型
从https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads下载`01_MorphableModel.mat`
将文件放到 `data_utils/face_tracking/3DMM/`
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy
5.运行convert_BFM.py
cd data_utils/face_tracking
python convert_BFM.py
6.准备ASR模型
选择安装DeepSpeech(需要手动安装TensorFlow 1.15)或Wav2Vec(PyTorch实现)。
7.开始处理
#执行全部步骤
python data_utils/process.py data/<ID>/<ID>.mp4
#分步执行(共9步)
python data_utils/process.py data/<ID>/<ID>.mp4 --task 1
8.检查输出文件
处理完成结果:
./data/<ID>
├──<ID>.mp4 # original video
├──ori_imgs # original images from video
│ ├──0.jpg
│ ├──0.lms # 2D landmarks
│ ├──...
├──gt_imgs # ground truth images (static background)
│ ├──0.jpg
│ ├──...
├──parsing # semantic segmentation
│ ├──0.png
│ ├──...
├──torso_imgs # inpainted torso images
│ ├──0.png
│ ├──...
├──aud.wav # original audio task 1
├──aud_eo.npy # audio features (wav2vec)
├──aud.npy # audio features (deepspeech)
├──bc.jpg # default background
├──track_params.pt # raw head tracking results
├──transforms_train.json # head poses (train split)
├──transforms_val.json # head poses (test split)
9.替换xuniren的文件
transforms_train.json替换/xuniren/data/kf.json
(重命名为kf.json)
三、视频训练
# 默认使用硬盘.
# 可以指定CPU/GPU进行训练.
# `--preload 0`:从硬盘加载数据 (默认, 慢).
# `--preload 1`: 指定CPU,约70G内存 (较慢)
# `--preload 2`: 指定GPU,约24G显存 (快)
1.头部训练(不建议增加太多)
python main.py data/<ID>/ --workspace <trial_ID>/ -O --iters 200000
2.唇部微调
python main.py data/<fay03_fh>/ --workspace <trial_ID>/ -O --iters 500000 --finetune_lips
3.躯干训练(视频身体部分一定不能太多)
python main.py data/<fay03_fh>/ --workspace <trial_ID_torso>/ -O --torso --head_ckpt <trial_ID>/checkpoints/<npg_0043.pth> --iters 200000 --preload 2
4.替换xuniren的文件
/RAD-NeRF/data/<trial_ID>/<trial_ID_torso>/checkpoints/<ngp_ep0043.pth>替换/xuniren/data/pretrained/ngp_kf.pth
(重命名为ngp_kf.pth)
————————————————
版权声明:本文为CSDN博主「郭泽斌之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/aa84758481/article/details/131135823
一步步教学在 Windows 下面安装 pytorch3d 来部署 xuniren 这个项目
对于这篇教程打算上个星期就准备写了,无奈一直在跑产品和参加行业活动,始终迟迟未能和大家见面。这个项目主要是小郭总开源的 Fay 虚拟人控制器然后看到有这么一个真人 2D 的项目——xuniren,激发了我部署项目的好奇心。从而有了一些经验(踩了很多坑),顺利在几台电脑上跑通,而且远程也帮了一位朋友部署成功。所以趁热打铁,我写下这篇文章来给感兴趣的小伙伴分享下心得,希望大家顺顺利利地部署 pytorch, torch3d, 这些项目。顺便说一句,这些项目在 Linux, macOS 部署都很简单,可惜 Windows 下面确实需要折腾很久。
我这里安装的版本先罗列一下。pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 cub_home=1.11.0 torch3d==0.7.1 为了方便大家我先把下载链接一并放出。接下来就进入我们的正式安装环境。从0到1的开始。然后所需要的C++ 编译工具是Visual Studio 2019 的版本。版本号如下:
然后就是安装Mingw的c++编译工具,这个安装包可以上网下载,也可以私信我来取。
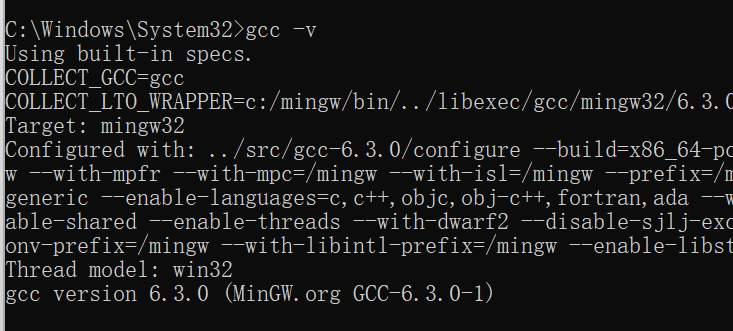
通过conda 新建一个虚拟环境
conda create -n torch3d python=3.9
激活虚拟环境
conda activate torch3d
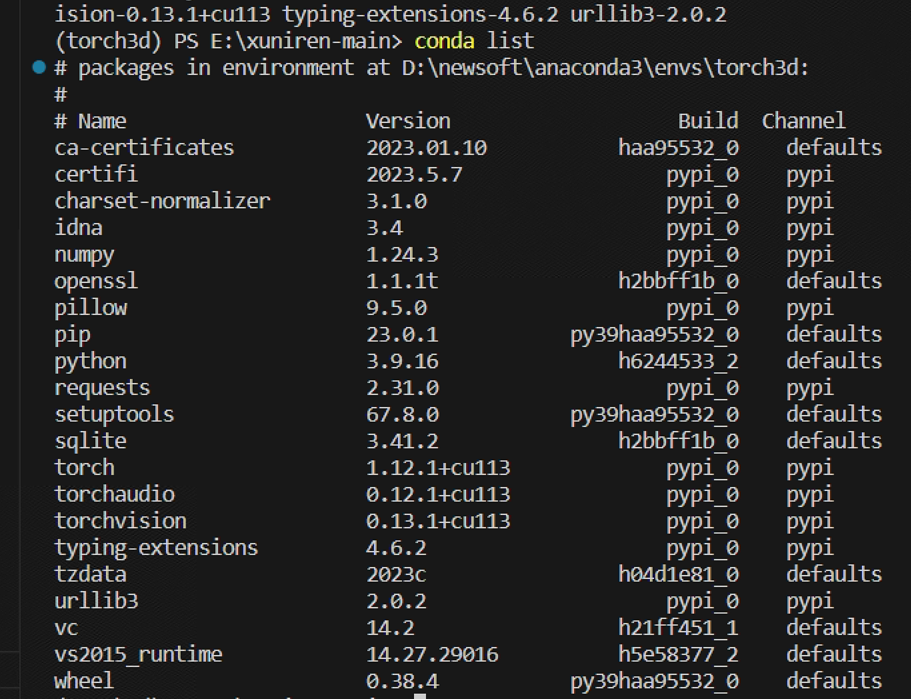
接下来就可以执行pytorch安装命令了。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
安装好之后,可以看到下面这张图。
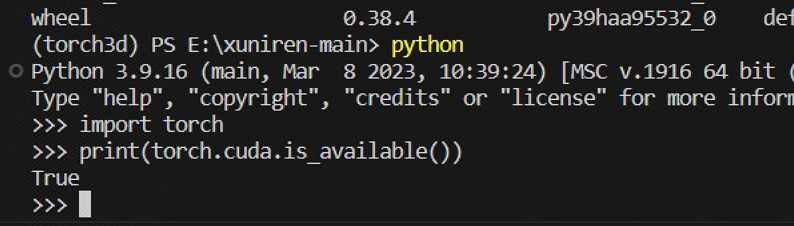
然后我们进入虚拟环境里执行下面两段代码
import torch print (torch.cuda.is_available())
验证一下我们安装的 cuda 是否为 True
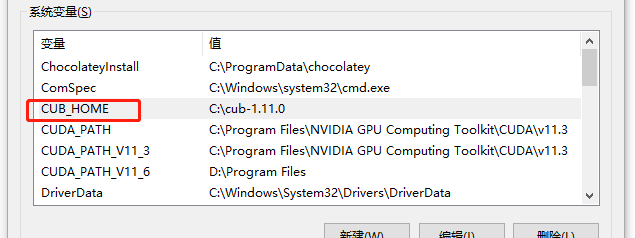
这里顺便插播 CUDA_TOOLKIT 和 CUB_HOME 安装过程。cuda_toolkit 可以直接通过我上面的链接进行下载安装,直接一路 Next 安装就可以了,cub_home 也是下载完之后,在系统的环境变量里面进行设置如下图。
看到这些我们就可以把 torch3d 的文件进行下载,编译安装了。我这里是把 torch3d 的项目放到虚拟环境里面的 site-packages 里面,这里每个人的虚拟环境安装不同可以找一下。我这里是在C盘下面的 anaconda 下面。如下图
然后需要把 pytorch3d 里的 setup.py 文件77行里的 -std=c++14 参数去掉,不加这个参数即可。具体如下图:

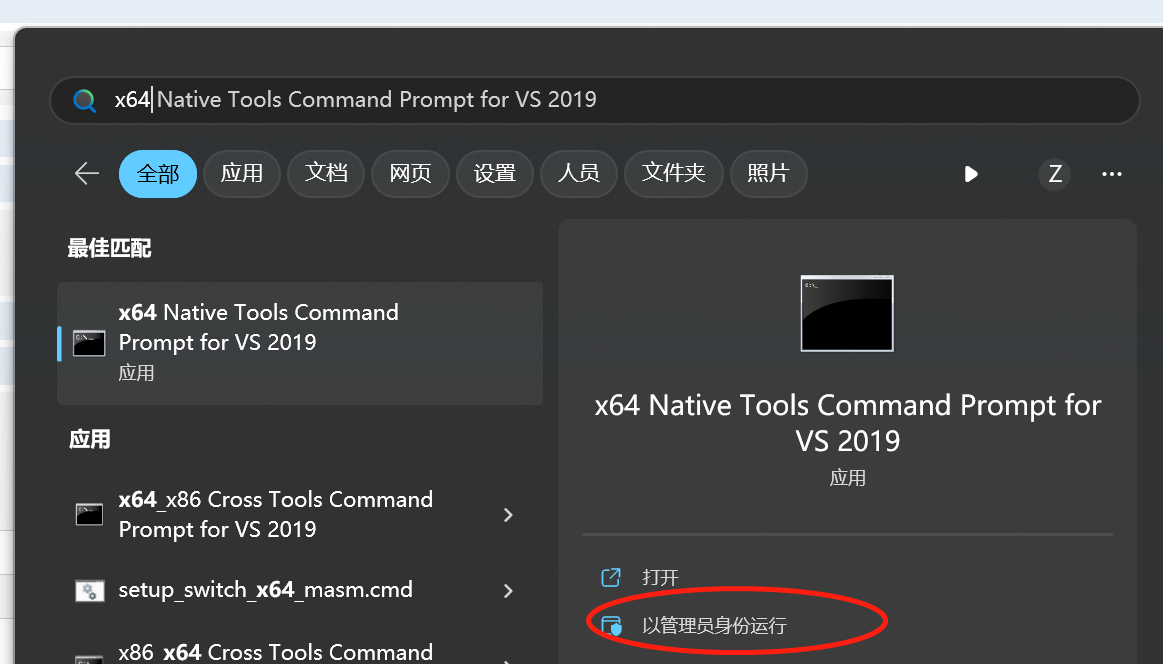
这样的我们就可以以管理员身份打开 VC++ 的编译工具了。如下图:
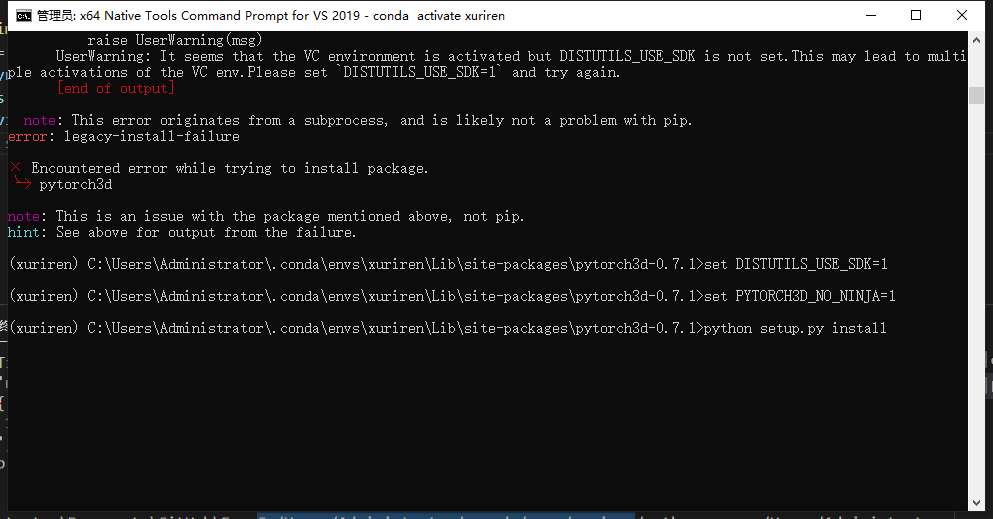
然后找到刚才的虚拟环境里的 pytorch3d 的文件路径,激活虚拟环境之后,需要输入下面两个命令就可以执行安装了。执行顺序依次为:
set DISTUTILS_USE_SDK=1 set PYTORCH3D_NO_NINJA=1
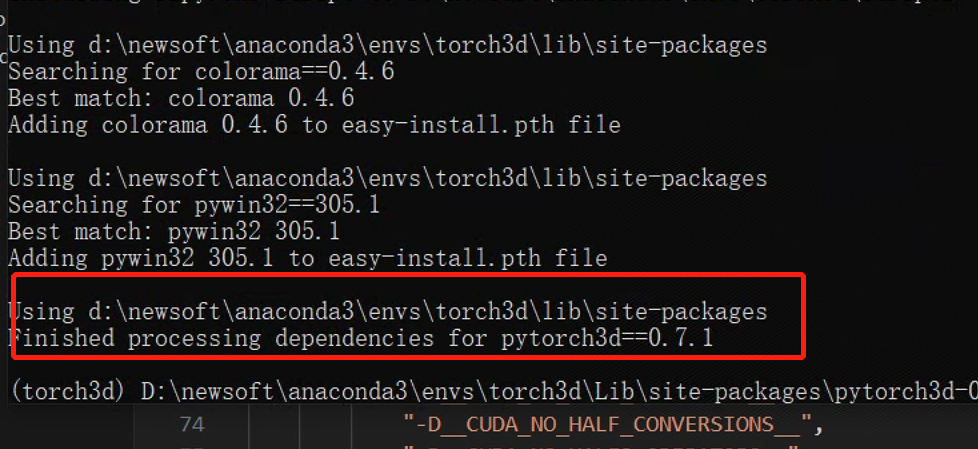
经过长时间漫长的等待,中间不出错误的话,可以看到下面这张图片。
这样我们就成功编译了 torch3d 这个项目,接下来就是我们把 xuniren 这个项目 clone 下来,激活我们刚才创建的 torch3d 这个虚拟环境。在这个项目的 ReadMe 文档里有说到要用 VC ++ 编译器去编译 freqencoder, gridencoder, raymarching shencoder 这几个项目,其实这是 Nerf 项目所依赖的第三方库,如果后面用到数据训练的话,这些是必须要安装的。接下来我就演示一下如何编译这些文件。我是一个一个进行编译了,没有执行批处理命令。这里需要注意的两点就是需要把四个文件的 setup.py 文件里的代码,按照下面的格式进行修改。

cmdclass 里的 build_ext 加上 use_ninja=False, 然后把 ‘-03’, '-std=c++14' 注释掉,如下图:

这样就可以继续在 VC ++ 2019 的编译器下面进行逐个安装。需要在 xuniren 这个项目里对应的文件夹下面执行安装命令:
conda activate torch3d
set DISTUTILS_USE_SDK=1
python setup.py install
依次执行完之后就可以得到这四个依赖库安装成功的界面了。我这里当时过于激动只截了一张图,给大家看看。

进行到这里的时候,应该会提示有些库有冲突了,我这里是pillow,我重新安装之后就可以了。这个项目用到了ffmpeg,Windows 系统下载一个即可,然后在环境变量配置一下即可。我安装的是ffmpeg-5.1.2 这个版本。
pip install pillow==9.0.0
如果你能进行到这里,那么你离这个项目 Run 起来就咫尺之遥了。接下来我们就可以执行项目中说的命令了。
python fay_connect.py
经过漫长的模型下载,就可以看到下面的这个运行窗口了。

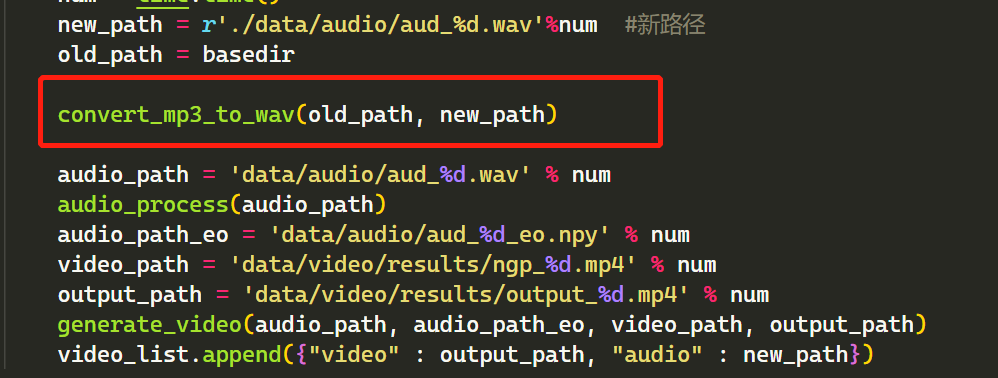
不过不要高兴太早,每个令人兴奋的项目在最后的关键时刻总会有个小问题站出来,让你看不到心中的亮光。我们需要在fay_connect.py 这个文件里做一个小修改。把原来的方法 convert_mp3_to_wav("/" + old_path, new_path) 改成下面的就可以看到虚拟人张嘴,听到虚拟人说话了。当然你是需要把 Fay 控制器打开,才可以进行互动交流哦。
整个安装过程就是这样的,这里遇到最多的问题就是 C++ 编译的问题,找了很多资料都没有把这个虚拟人项目部署说得精准的,所以这篇文章就应运而生了,解决大家在部署过程中遇到的难题。对于训练自己的数字人,我这边也已经部署成功,只不过训练出来的数字人播报,远没有 metahuman 有意思。如果大家也有疑问,就给我留言吧。

