
- 1Python+Yolov5果树上的水果(苹果)检测识别_pytorch 水果识别案例源码
- 2C#和.NET框架_c# .net框架
- 3微软商店重新安装 微软商店清单中指定了未知的布局
- 4for i in range(len(alist))_for i in range(len(list))语法
- 5通过xml方式配置Rabbitmq_xml 動態rabbitmq隊列配置
- 6力扣第 42 场双周赛T1:无法吃午餐的学生数量_学校的自助午餐提供圆形和方形的三明治,分别用数字0和1表示。所有学生站在一
- 7c语言冲刺,1、输入一个实数,分别输出其整数部分和小数部分2、输入三个单精度数,输出最小值3、计算a-b之间所有奇数之和与偶数之和,a,b,通过键盘输入4、使用以下公式计算π,要求精度<1e-5_三个单精度数,输出其中最小数是多少
- 8Asp.NetCore 利用SqlSugar连接数据库
- 9day16_map课后练习 - 参考答案
- 10HarmonyOS4.0从零开始的开发教程07容器组件介绍
python04- for in 、while in、列表、交叉赋值、元组、字典、集合(set)、公共方法、列表推导式、集合推导式、字典推导式_python while in
赞
踩
1、for in 、while in 循环区别
# for i in range (开始/左边界, 结束/右边界, 步长) i 是循环点,in 后是循环体
# for i in range(开始/左边界, 结束/右边界, 步长): for i in range(1, 10, 2): # 等价于 for (i=1;i<=10;i+=2) print(i)

# for i in a 一般为非数值,每次步长只能为1, i 是循环点,in 后是循环体
# 一般为非数值,每次步长只能为1 a = 'abcdef' for i in a: print(i)
# 非数值,每次步长只能为1 a = ['你好','世界'] for i in a: print(i)


总结:for i in a 模式,是将in后面a作为一个循环体,通过i,默认每次+1,做a的循环遍历。每执行一次遍历,for 会重新连接 in 后的 a 的 id 索引,获取数值。
while i in a 代表的是,判断 i 在不在 a中,假如 i =1 ,a = 42351,while会在每次执行循环的时候,将整个a进行顺序检索,看是不是有 i = 1,只有遇到,执行循环。而 for 循环,是每次按照顺序将in 后 面的数据中获取数据并使用。
2、列表删除:pop remove clear
变量表示是一个容器,列表可以表示是一组容器
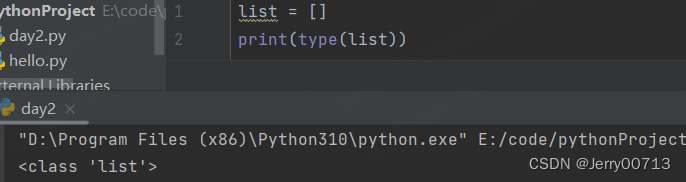
空列表 list = [ ]
类型是list
有内容得到列表 list = ['A','B','C']
列表中可以嵌套列表 list = [ [ ],[ ],[ ] ] ,有什么作用,比如去超市分类,有水果类、日杂类、零食类,其中水果类还有苹果、香蕉等,日杂类有锅、铲子等等。所以里面可以存储,int float char 包括 list
空列表 list = [ ]
有内容得到列表 list = ['A','B','C']
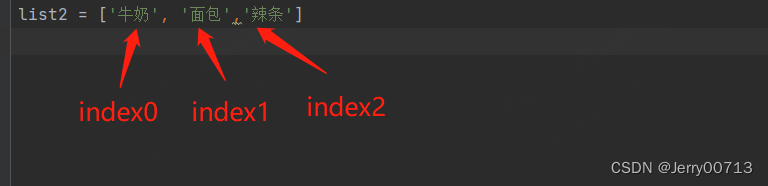
list2 = ['牛奶', '面包','辣条'] print(type(list))
获取列表中的元素,通过索引
list2 = ['牛奶', '面包', '辣条'] print(list2[1]) # 面包
索引也有正序、倒叙
list2 = ['牛奶', '面包', '辣条'] print(list2[1]) # 面包 print(list2[-1]) # 辣条

由于列表也有索引、正序、倒叙,所以就能使用切片机制
如果是字符串,切片切完之后,是字符串
如果是列表,切片切完之后,是列表list = ['a', 'b', 'c'] list2 = 'abc' print(list[1]) # b print(list[-1]) # c print(list[:-1]) print(list2[:-1]) # start是空,所以是非负数(代表从左到右),因为是空,代表0,并且从index0开始,到倒数-1条,不包含-1,所以是['a', 'b']

列表删除:pop
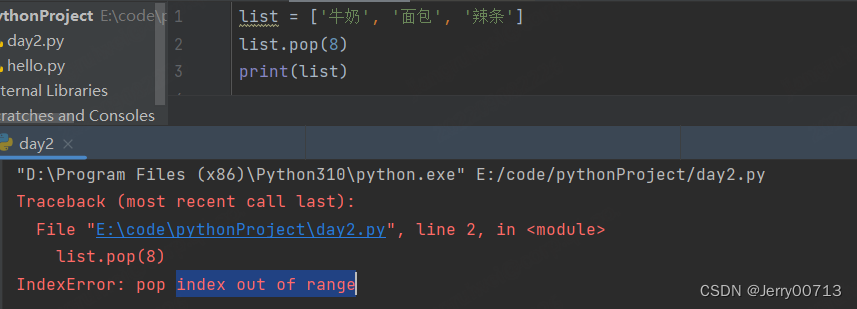
pop :指定删除那个索引的数值
list = ['牛奶', '面包', '辣条'] list.pop(-1) print(list) # 删除了index(-1)='辣条',所以是['牛奶', '面包']
如果索引数值大于当前的索引范围,则报错,超出索引范围
pop() 不添加任何,表示从后往前依次删除一位
list = ['牛奶', '面包', '辣条'] list.pop() print(list) list.pop() print(list)

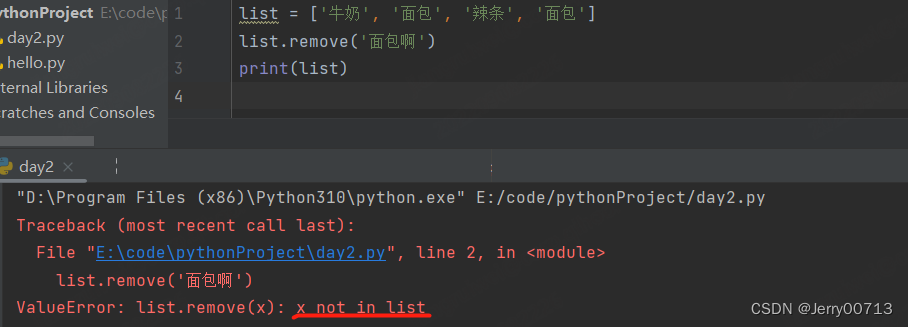
列表删除: remove() 你想删除列表中的一个数值,不是下标索引。默认只删除匹配到第一个。如果要都删除,就需要循环
list = ['牛奶', '面包', '辣条', '面包'] list.remove('面包') print(list)
如果删除一个不存在的数值,提示x not in list,代表你给定的数值不在列表中
如何确定,在删除之前有没有这个元素,有删除,没有不删除。
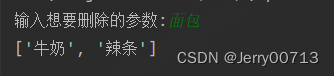
in 表示元素是不是在列表中,返回布尔,所以可以使用 if 语句list = ['牛奶', '面包', '辣条', '面包'] a = input("输入想要删除的参数:") if a in list: list.remove('面包') print(list) else: print("%s 不存在" % a)
删除所有的指定的元素
错误用法:
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] a = input("输入想要删除的参数:") for a in list: if a == '面包': list.remove(a) print(list)
为什么?
1、for a in list # a = list[0] = '牛奶'
2、if a == '面包': list.remove(a) # 判 断 '牛奶' 不等于 ’面包‘,False3、for a in list # a = list[1] = '面包'
4、if a == '面包': list.remove(a) # 判 断 '面包' 不等于 ’面包‘,True , 移除列表中第一个'面包' ,此时 list = ['牛奶', '面包', '面包', '辣条', '面包']。注意:索引位置已经发生改变5、for a in list # 这时候按照默认for 开始获取list[2]的数据,a = list[2] = '面包' , 但是list已经发生改变,list = ['牛奶', '面包', '面包', '辣条', '面包'],现在取list[2] = '面包' ,就会将list[1] = '面包' 给略过
正确用法:while len
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] a = input("输入想要删除的参数:") n = 0 while n < len(list): if list[n] == '面包': list.remove('面包') else: n += 1 print(list)
解释:
1、while n < len(list): # n < 6
2、if list[n] == '面包': list.remove('面包') # if list[0] == '面包': list.remove('面包') 不成立
3、esle n=n+1 # 所以 n 等 1
4、while n < len(list): # 1 < 6
5、if list[n] == '面包': list.remove('面包') # if list[1] == '面包': list.remove('面包') 成立,此时list = ['牛奶', '面包', '面包', '辣条', '面包'] ,也就是移除一个元素,在移除元素的后面所有元素,索引都往前移动了一位
6、不触发 n=n+1,所以n 还是等于 1
7、while n < len(list): # 1 < 6 上文可知,索引向前移动一位,所以我还校验上次的索引,不就是校验下一个元素了么正确用法:while in
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] a = '面包' while a in list: list.remove(a) print(list)
解释:
正确用法:for 满足添加新数组
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] a = input("输入想要删除的参数:") list1 = [] for n in list: if n != a: list1.append(n) # 直接将不符合的,传递到一个新的列表 list = list1 print(list)
正确用法:for 倒序
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] b = '面包' for a in list[::-1]: if a == b: list.remove(a) print(list)
# a = list[5] = '面包'
# if a == b: list.remove(a) # '面包'='面包' 移除第一个面包,list = ['牛奶', '面包', '面包', '辣条', '面包']# a = list[4] = '辣条' 不做处理
# a = list[3] = '面包'
# if a == b: list.remove(a) # '面包'='面包' 移除上次的列中的第一个面包,list = ['牛奶', '面包', '辣条', '面包']# a = list[2] = '面包'
# if a == b: list.remove(a) # '面包'='面包' 移除上次的列中的第一个面包,list = ['牛奶', '辣条', '面包']# a = list[1] = '面包'
# if a == b: list.remove(a) # '面包'='面包' 移除上次的列中的第一个面包,list = ['牛奶', '辣条']



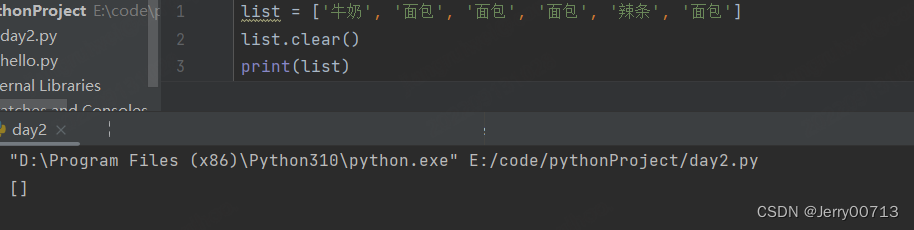
列表删除:clear
表示清除列表中所有的数据
3、for in 后的循环体
案例:如下两个案例中,在 for 后,一个是进行list = ['你好', '环境'],一个是list.remove(a)。都是进行了对 list 改变,为什么第一个案例中,for i in list 中的 list 还是 list = ['1', '2', '3', '4', '5', '6']。而第二个案例中,for a in list 中的 list 是获取的 list.remove(a) 后的列表
list = ['1', '2', '3', '4', '5', '6'] a = 0 while True: if a == 10: break else: for i in list: print(i) list = ['你好', '环境'] a += 1
list = ['牛奶', '面包', '面包', '面包', '辣条', '面包'] a = '面包' for a in list: if a == '面包': list.remove(a) print(list)

解释:
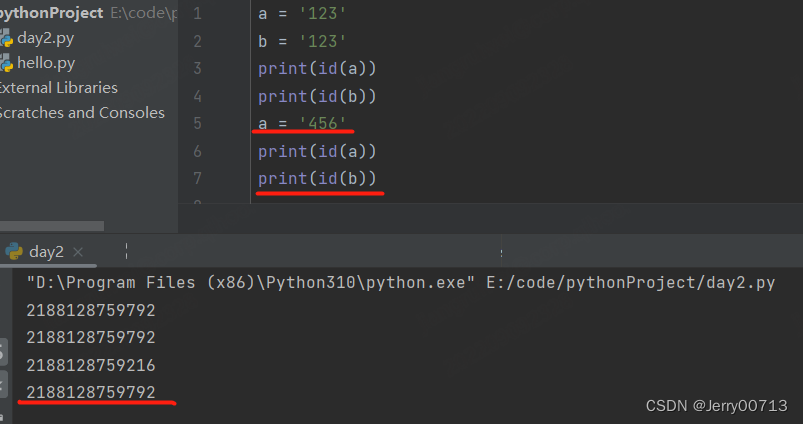
首先我们都知道,a = 123, 其中123 (value)、123(id)、123(type) 都是在堆中,而变量a在栈中。通过a = 123,将123(id)跟 a 绑定。而我们还知道,堆中相同类型的数值只有一个,比如变量 a 要跟堆中的'123' 绑定。b 也要跟堆中的'123'绑定。堆中不会在开辟一莫一样的数据,而是复用一个。a = '123' ,a 跟 ‘123’的 id 数值 2188128759792绑定, 这时候 a = '456' ,并不是将2188128759792这个 id 中的这个value = ‘123’ 修改。而是堆中,在开辟一个'456',绑定 a
但是如果是列表,会重新开辟

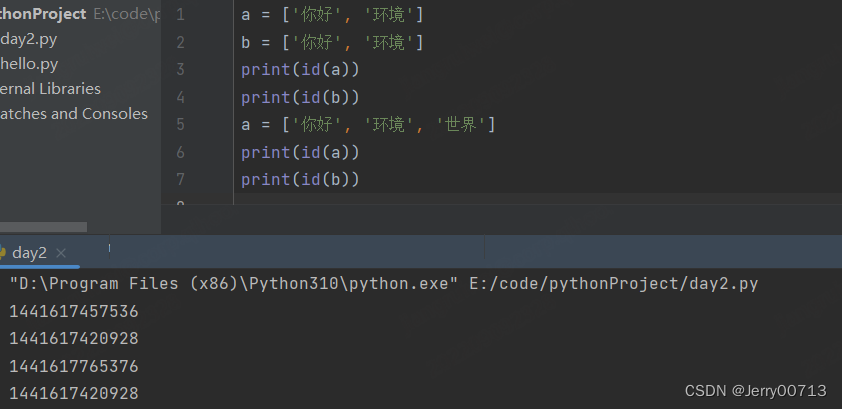
通过上述讲解- for i in list ,其中 list 是不会跟着变得,in 后接的是第一次循环的id数值,即使你 list 变量跟另一个id绑定,不影响我 in 后面找之前的 id 中的数值。
list = ['1', '2', '3', '4'] print(id(list)) a = 0 while True: if a == 6: break else: for i in list: print(i) list = ['你好', '环境'] print(id(list)) print(list) a += 1

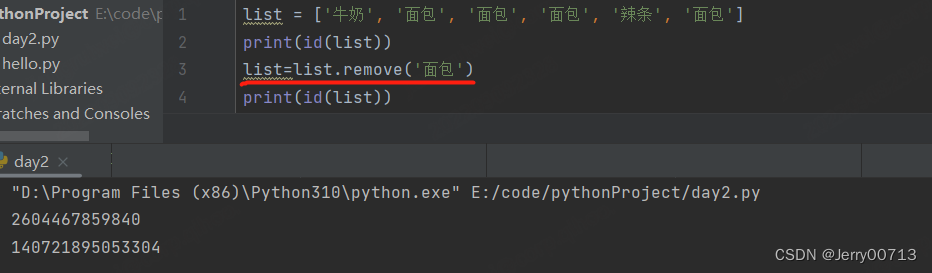
如果单纯的执行remove() ,会发现其实没有改变原list指向的 id,而且value发生了改变
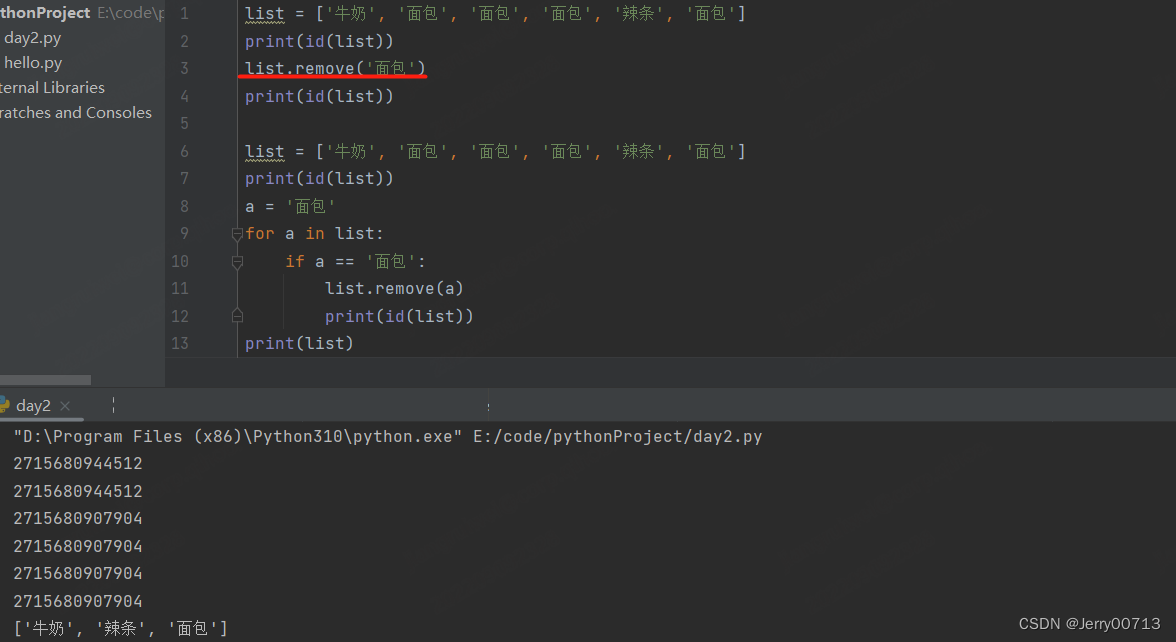
如果remove()重新复制,就会将 id 改变
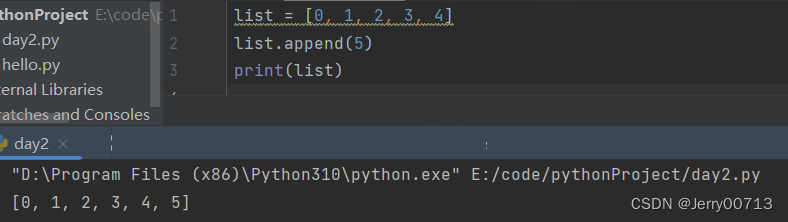
4. 列表元素插入
append() # 在最后的位置上追加
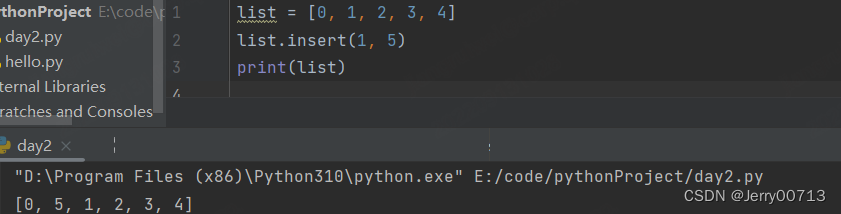
insert (位置,元素) # 元素占了位置,其他元素只能像后移动
list = [0, 1, 2, 3, 4] list.insert(1, 5) # 在index(1)下插入5,其他元素index 位置自动往后移动一位 print(list)
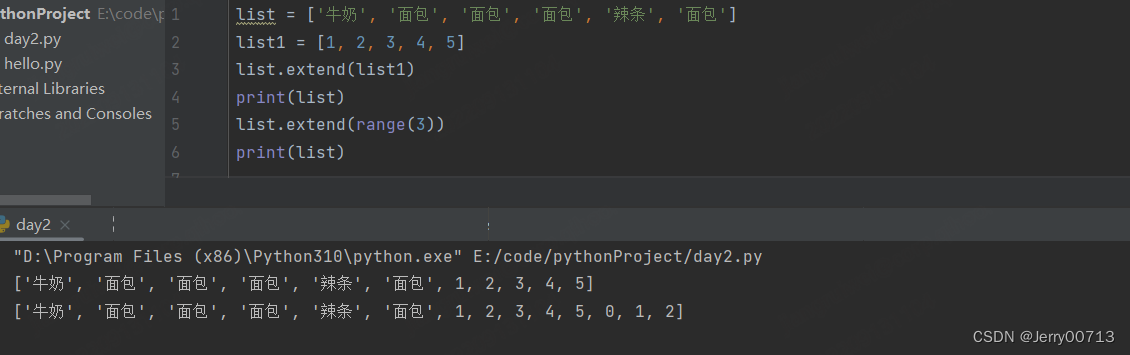
extend # 合并两个列表
5. 列表元素的修改
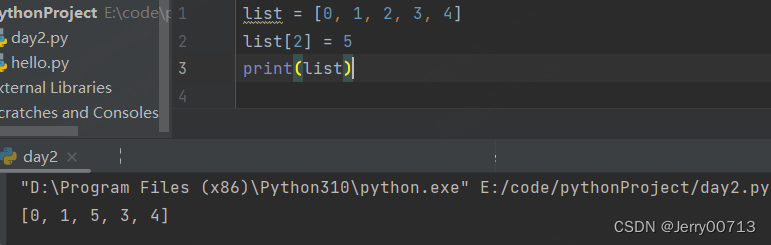
直接通过 lisrt[index] =
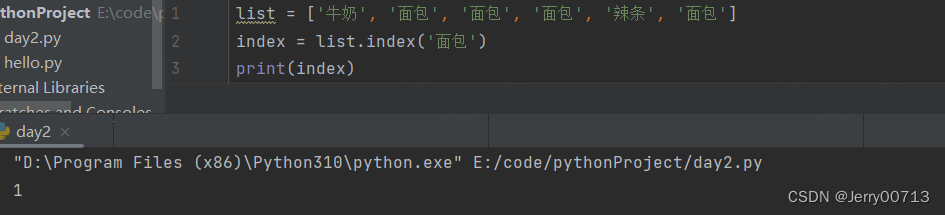
index(元素) # 检索列表中,符合要求的第一个元素,并返回索引位置。
在使用 lisrt[index] =

6. 列表元素的查找
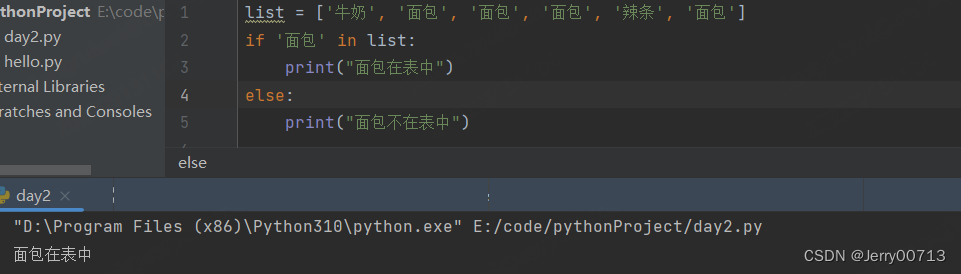
1、元素 in 列表 # 返回 bool 类型
元素 not in 列表 # 返回 bool 类型
2、列表.index(元素) # 返回列表中符合要求的第一个元素下标位置,如果没有此元素则报错
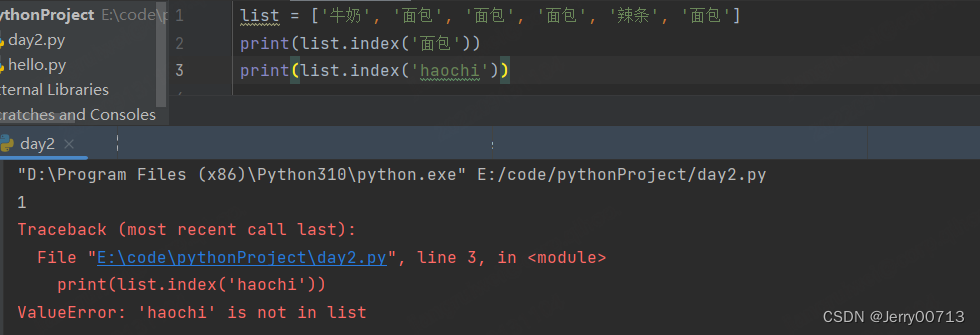
3、列表.conut () # 查看符合的元素出现的次数之和,如果没有此元素则返回0,故返回整数

7、删除列表元素
删除一个元素:
del list[index] # 删除指定下标的元素,跟 list.pop(index) 是一个性质

删除列表所有元素:
del 删除列表 相关的所有,包括列表本身
0
clear 只清除列表中的元素,保留列表本身
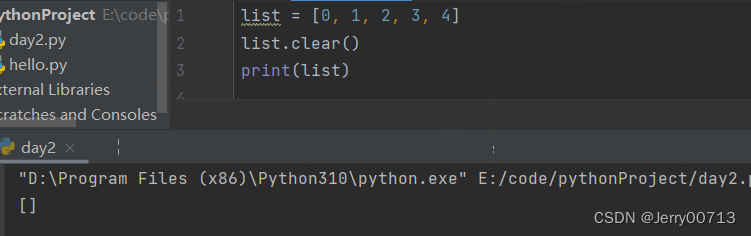
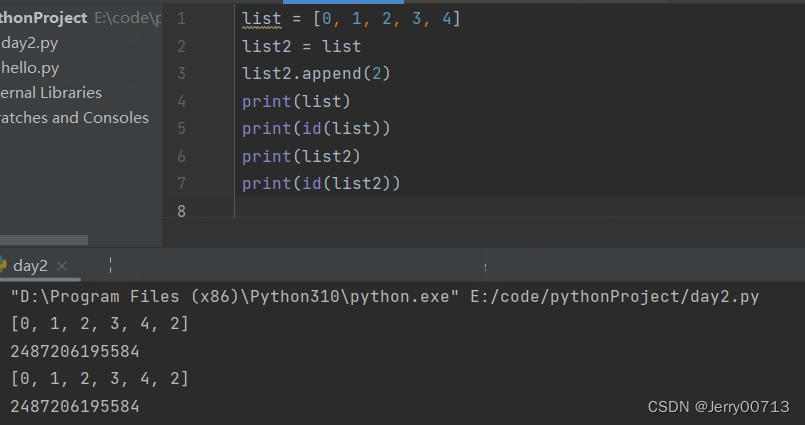
8、列表在内存中的调用
list2 = list # 表示将list连接的堆中的id数值给了list2
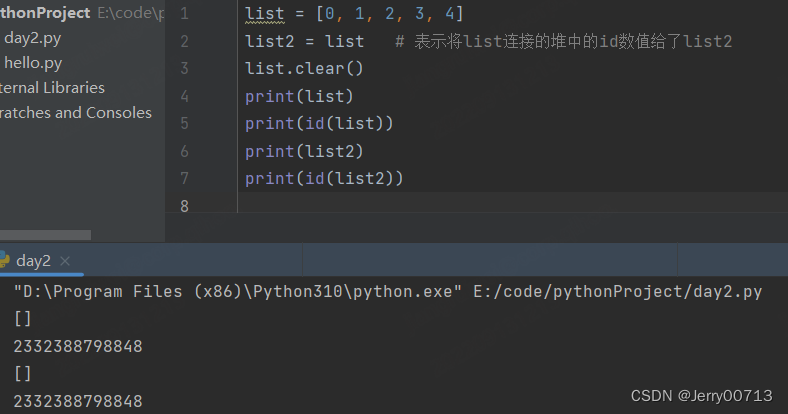
del 删除后,删除的是栈中的变量list2,并不是堆的id

9、列表排序
sort() # 将 list 按特定顺序重新排序,默认为由小到大(reverse=False)升序,参数 reverse=True 可改为由大到小。不能print(mumber.sort) 返回None ,因为sort 是直接改变的列表的本身
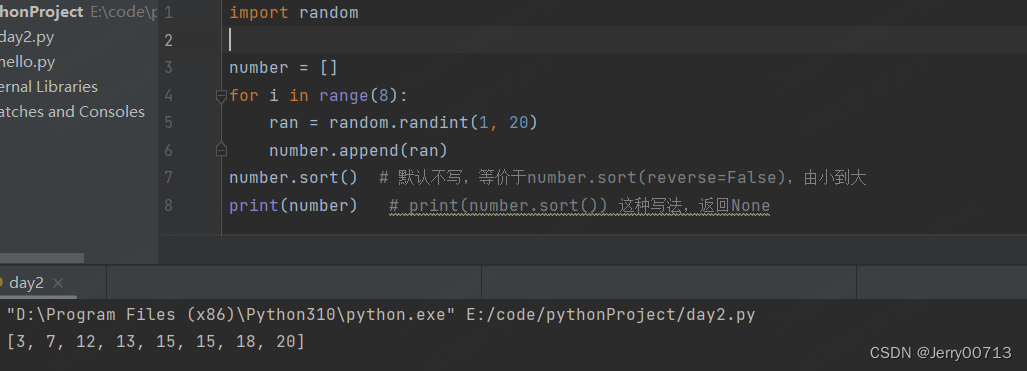
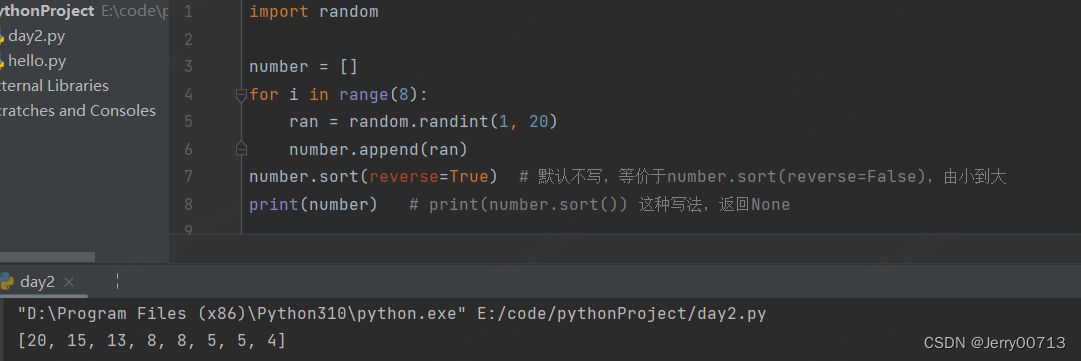
reverse # 对列表原有的数据进行反转

10、交叉赋值
a, b, c = b, a, b # a = b b = a c = b
11、元组
元组与列表的区别类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号,元组的格式要求,如果是无任何数据,则 t1 = ()
t1 = () print(type(t1)) # <class 'tuple'>
如果有一个数据,则必须有逗号,t1 = ('aa',) ,否则元组是字符串
t1 = ('aa',) print(type(t1)) # <class 'tuple'>t1 = ('aa') print(type(t1)) # <class 'str'>
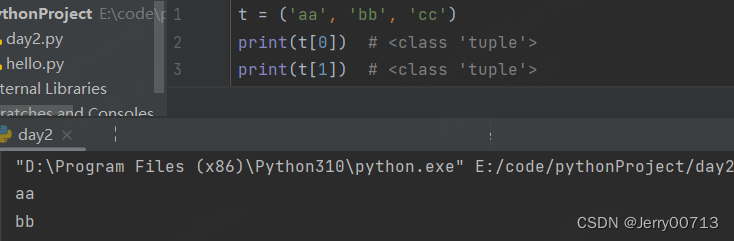
元组不能修改,但是可以使用下标跟切片,如下使用 t [index]显示下标,但注意不能越界,包括字符串、列表
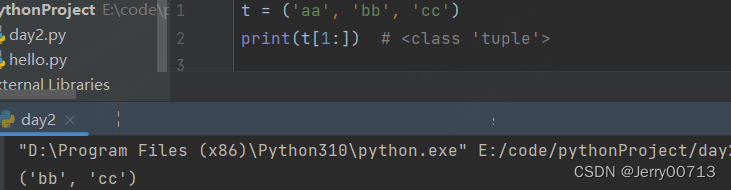
元组不能修改,但是可以使用切片,如下,切的是元组,返回的是元组。切的是列表,返回的是列表。字符串切的是字符串
元组计数count

元组元素的查找index() ,如果找不到报错
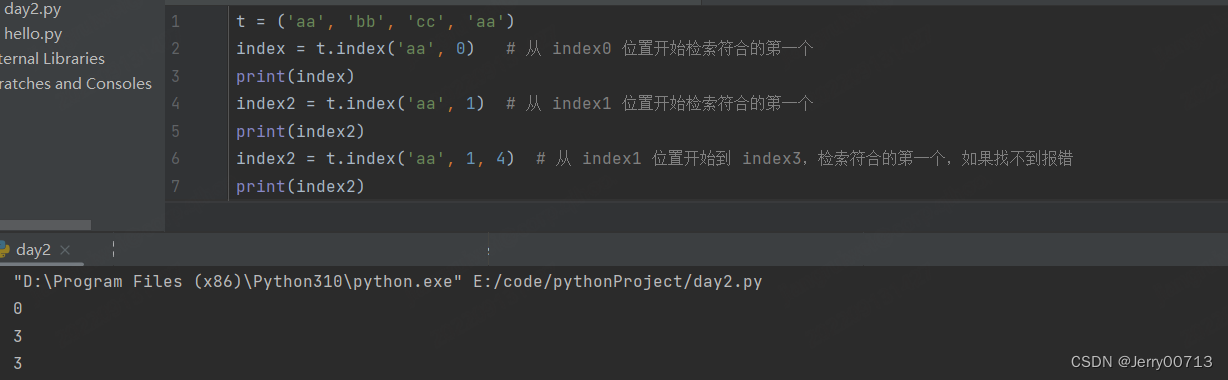
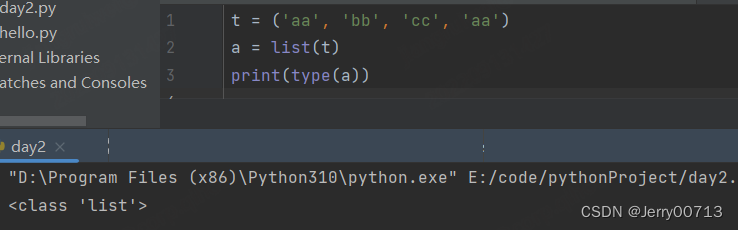
元组转列表 list( 元组 )
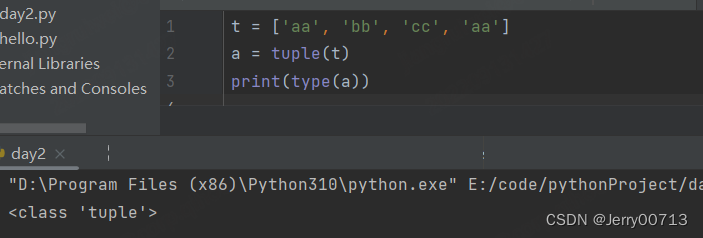
列表转元组 tuple( 列表 )
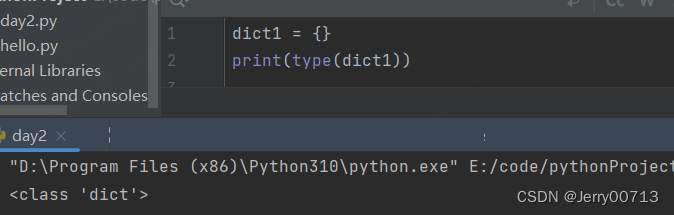
12、字典
结构: {键1:值 , 键2:值, 键3:值.......}
字典: {}
元素: 键值对 注意:键是唯一的,值是允许重复的
没有 下标 或者 切片
1、添加元素
字典名 [key] = value
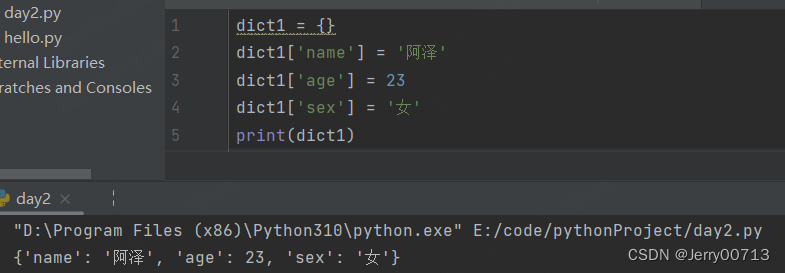
注意:key 是唯一的,所以在添加的时候如果出现同名的key,后面的key对应的value则替换原来的
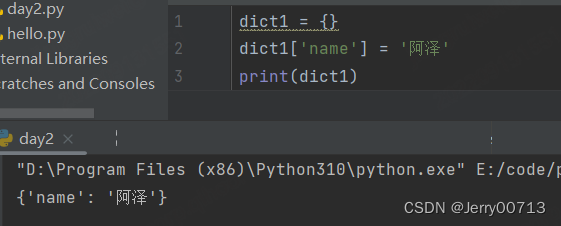
2、修改元素
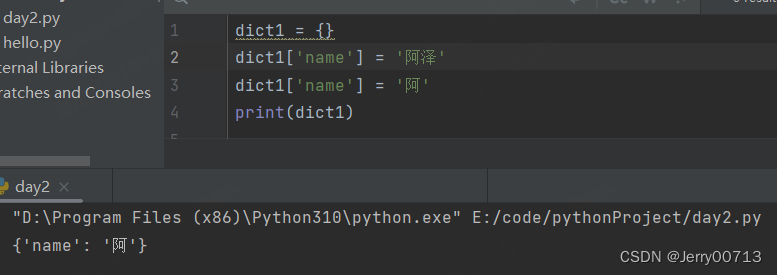
字典名 [key] = value # 不存在 key、value 添加,存在的 key、value 修改
注意:字典中的key是不能更改的,只有value能改。如果要修改key,可以将其删除添加

3、案例,已知书名、价格、作者,在过年的时候进行价格8折
book = {} book['书名'] = "<<三国演义>>" book['价格'] = 23 book['作者'] = '罗贯中' print(book) book['价格'] *= 0.8 # book['价格'] = book['价格']*0.8 book['价格']= round(book['价格'], 2) print(book)

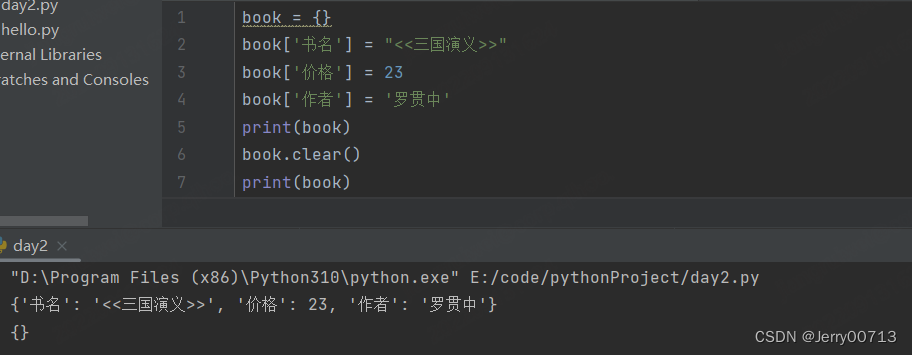
4、清除字典所有元素
.clear()
5、删除单个元素
.pop('key') , 返回值是删除的 value
如果字典没有对应的key,报错
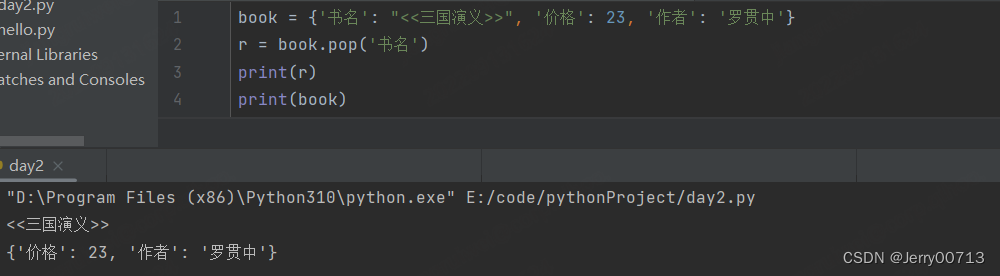
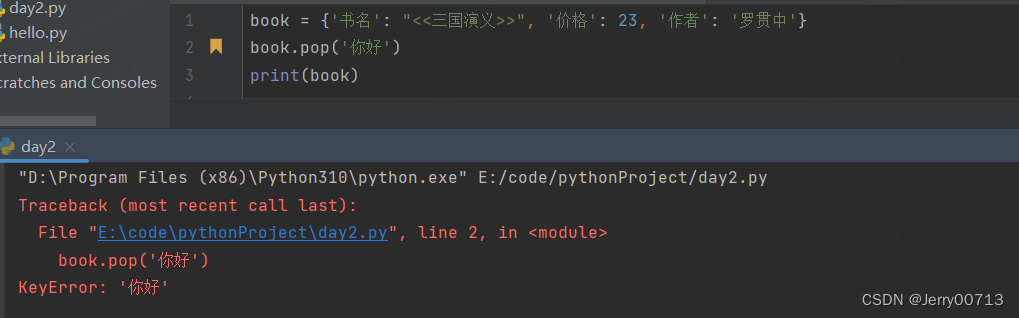
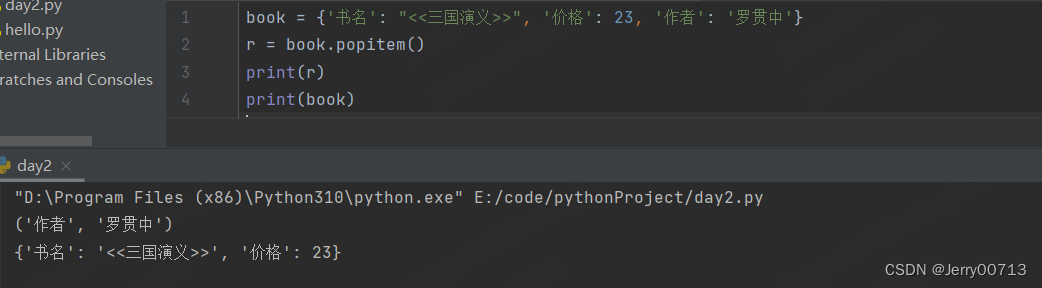
.popitem() 删除最后一个key = value, , 返回值是一个原则,最后一个key = value
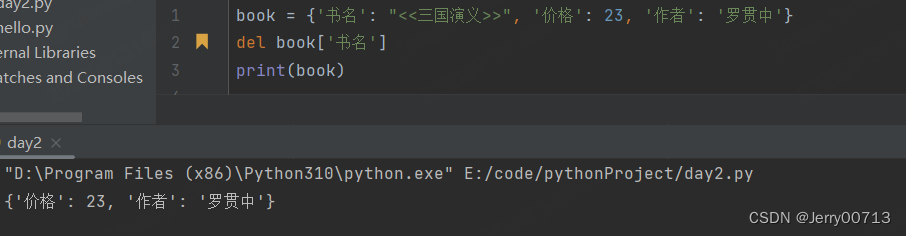
del book['书名'] # 类似pop 一样, 如果字典没有对应的key,报错
6、删除整个字典结构
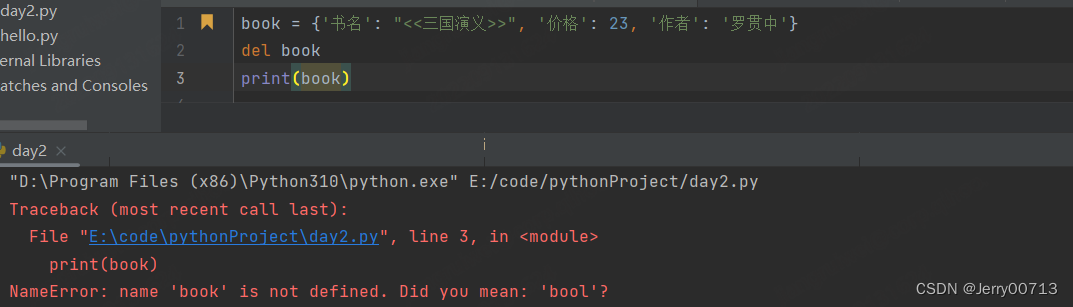
7、表达有两本书,两本书分别介绍,'书名' 价格' '作者' , 删除每本书中的作者 books = [ { } ,{ } ]
books = [] book1 = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} books.append(book1) book2 = {'书名': "<<水浒传>>", '价格': 21, '作者': '作者1'} books.append(book2) book3 = {'书名': "<<红楼梦>>", '价格': 22, '作者': '作者2'} books.append(book3) print(books) for i in range(3): if '作者' in books[i]: books[i].pop('作者') print(books)或者
books = [ {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'}, {'书名': "<<水浒传>>", '价格': 21, '作者': '作者1'}, {'书名': "<<红楼梦>>", '价格': 22, '作者': '作者2'} ] print(books) for book in books: book.pop('作者') print(books)

8、查询
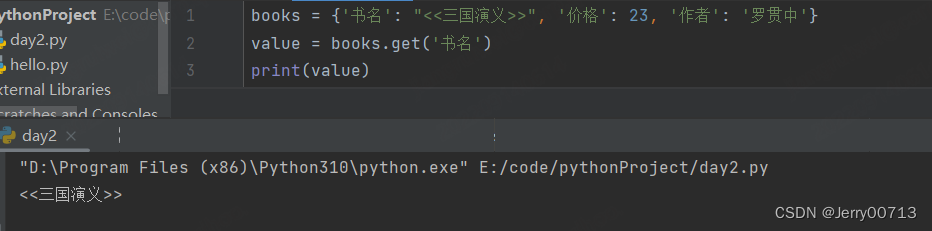
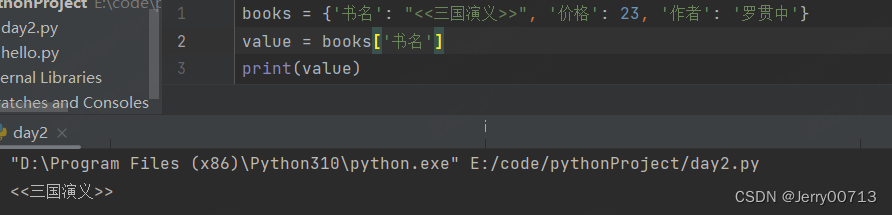
# 根据key获取value
value = books.get('书名') 或者 books['书名']
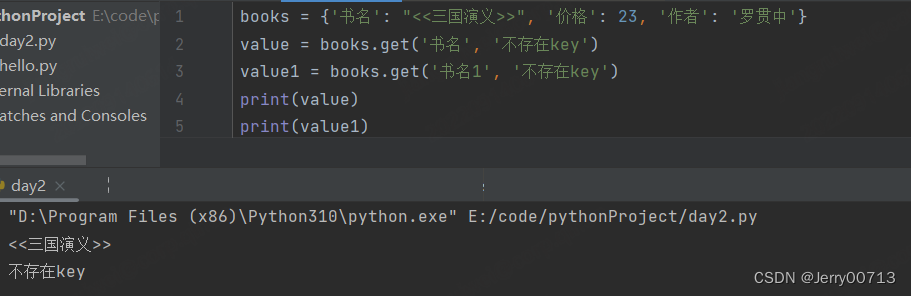
有什么区别?在于key中在字典中如果不存在,books['nihao'] 形式会报错 KeyError: 'nihao'。而books.get('nihao') 则不会报错 ,提示 None。
并且可以修改默认数值None,比如设置找不到的key返回‘不存在key’

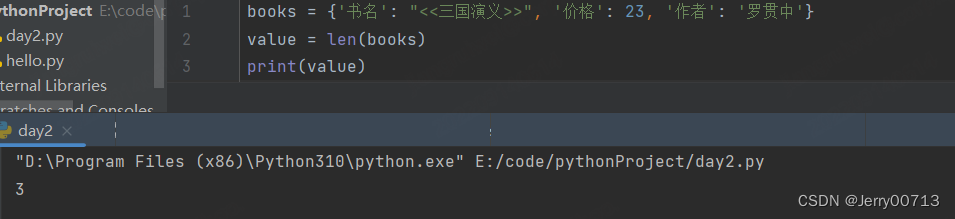
# len 返回的有即对key、value
value = len(books)
9、遍历
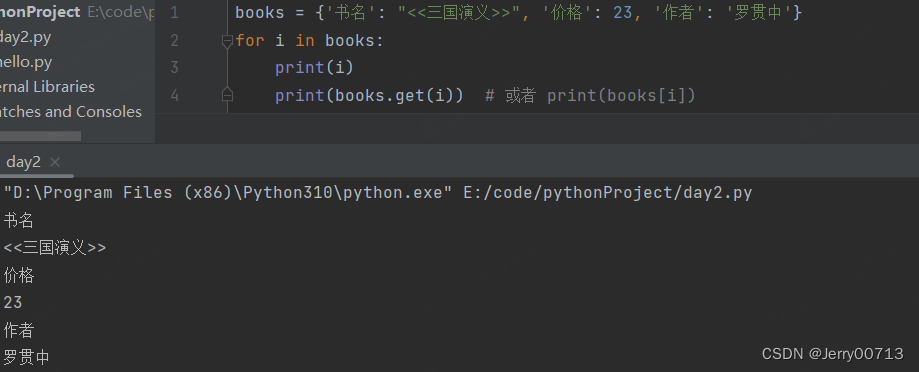
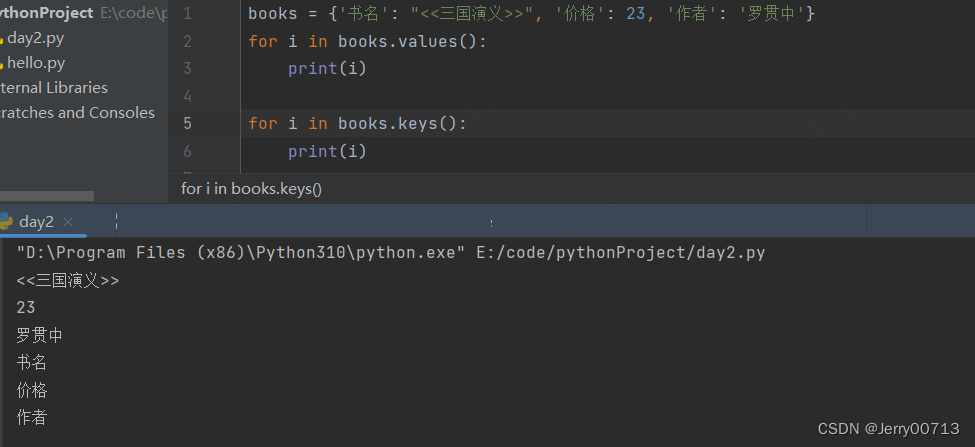
# 使用 for in 循环遍历字典,取出的是 key 数值
books = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} for i in books: print(i) print(books.get(i)) # 或者 print(books[i])

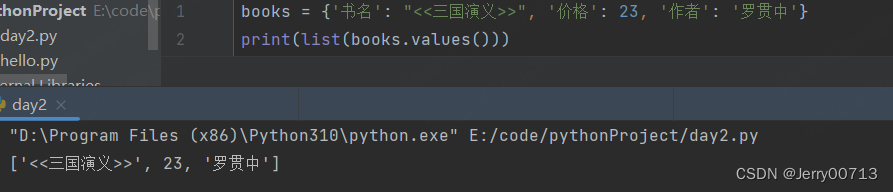
# 取出 value 数值,放入一个列表中
print(books.values())
返回的是 dict_values(['<<三国演义>>', 23, '罗贯中']) ,这种类型的列表,如果不想用dict_values( )包裹我们需要的这个列表,可以使用如下,强制转换成列表
print(list(books.values()))
列表可以使用for in 通过 books.value() 取出数值

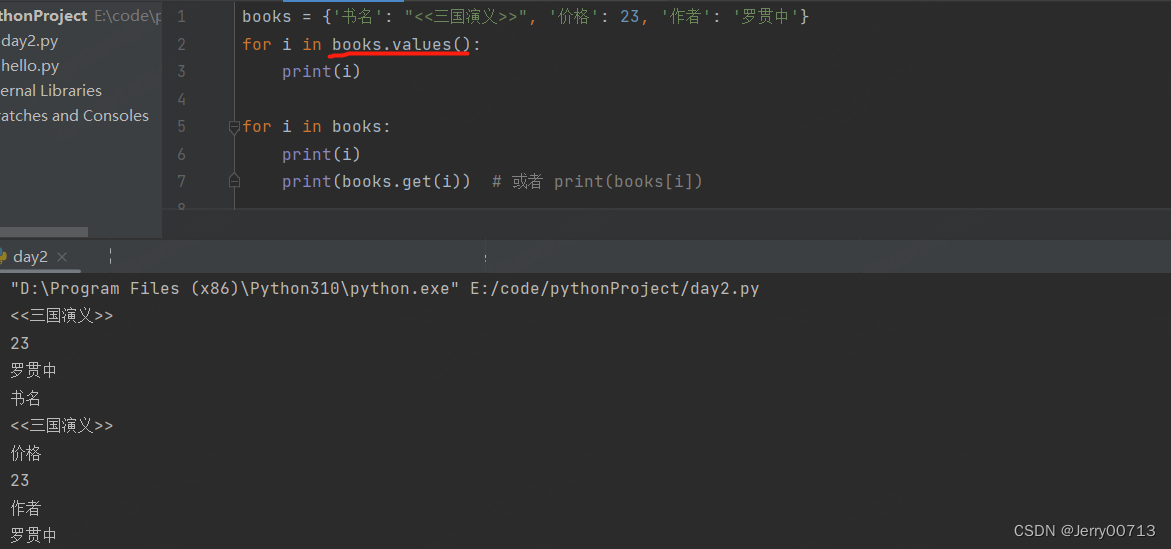
有 books.value(),就有对应的 books.keys() 拿到所有的 key 键
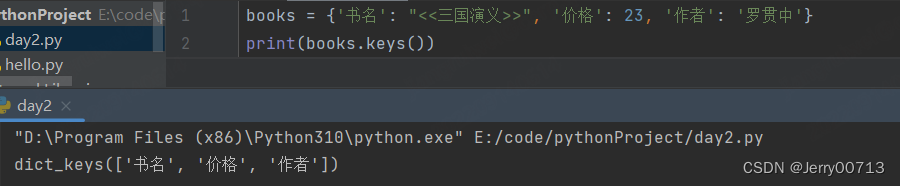
遍历列表,将每一个 key value 用元组形式显示
books = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} print(books.items()) # dict_items([('书名', '<<三国演义>>'), ('价格', 23), ('作者', '罗贯中')]) for i in books.items(): print(i)

建议使用 k ,v 形式获取key 或者 value 或者key, value
books = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} for k, v in books.items(): print(k) print("\n") for k, v in books.items(): print(v) print("\n") for k, v in books.items(): print(k, v) print("\n")

setdefault 在最末尾添加,不常用,因为添加直接使用kooks[key]=value 。
books = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} books.setdefault("<<语文>>", '作者1') books['语文2'] = '作者2' print(books)
两个区别为,setdefault只能添加,不能修改,输入已经存在的key,也无法修改。kooks[key]=value 如果不存在key 添加,存在修改

10、字典合并
列表使用 +
list = [1,2,3,4] list1 = [5,6,3,4] list2 = list + list1 print(list2) # [1, 2, 3, 4, 5, 6, 3, 4]
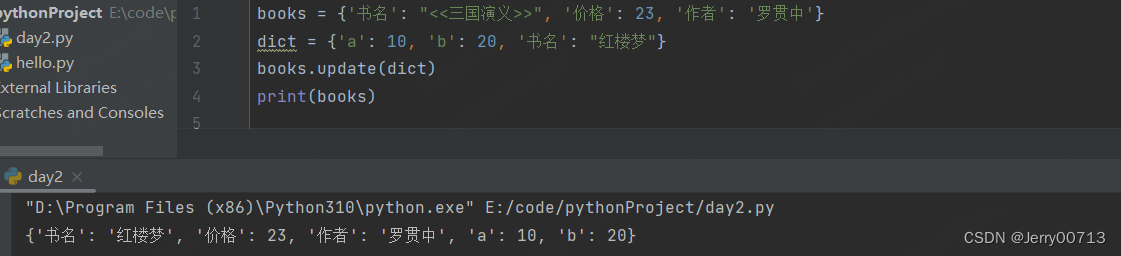
字典使用 update
books = {'书名': "<<三国演义>>", '价格': 23, '作者': '罗贯中'} dict = {'a': 10, 'b': 20} books.update(dict) print(books)
如果被合并的字典中,跟主动合并字典中存在一样的key,则被合并的字典替代

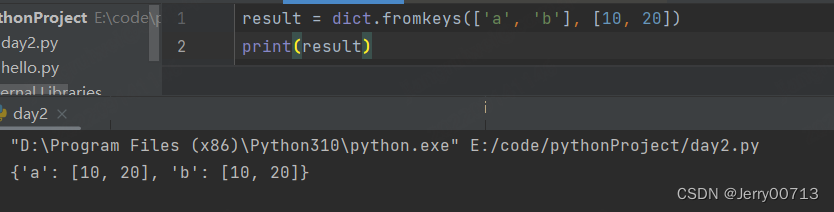
fromkeys() 函数创建一个新的字典,特点是指定value是统一的value,无法单独指定。给定的key, 不给value 数值是 None

指定key value,每个key都会获取其 value
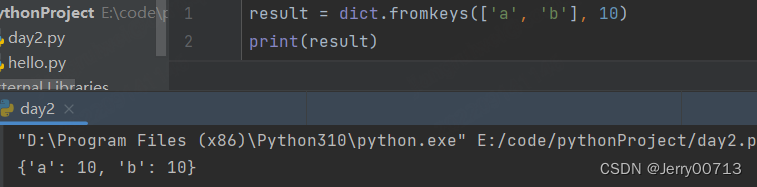
给指定key value,每个 key 都会获取其 value
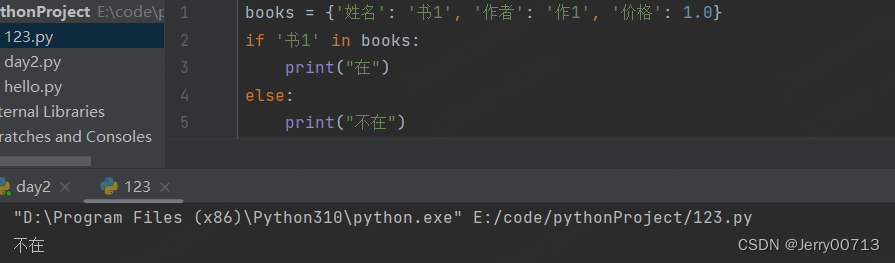
11、字典案例:添加三本书,每次不能添加同名的书名
books = [] # 定义列表,书的框架
while True:
a = False
if len(books) == 3:
break
name = input("输入书名:")
for book in books:
if name in list(book.values())[0]:
print("书名重复")
a = True
continue # 跳出当前for循环
if a:
continue
else:
anthor = input("请输入作者:")
price = float(input("请输入价格:"))
books.append({
'姓名': name,
'作者': anthor,
'价格': price
})
print(books)
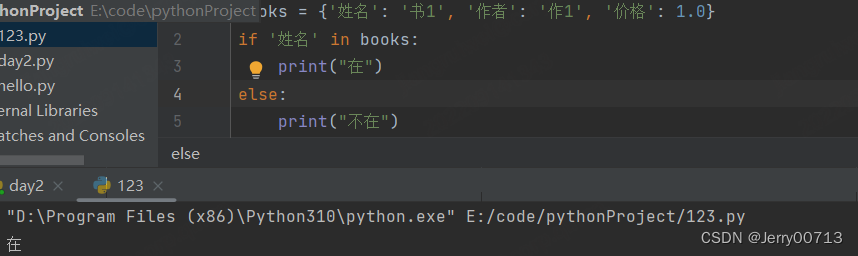
注意:if in 字典, 是判断的 key 在不在,并不能检索 value
第二种:
books = [] # 定义列表,书的框架
while True:
if len(books) == 3:
break
name = input("输入书名:")
for book in books:
if name == book.get('姓名'):
print("书名重复")
break
else:
anthor = input("请输入作者:")
price = float(input("请输入价格:"))
books.append({
'姓名': name,
'作者': anthor,
'价格': price
})
print(books)
# for book in books: 第一次books是空,for in 会执行一次,取出的 book 空
# if name == book.get('姓名'): book.get('姓名') 是空,所以不等,直接跳到else
# else 通过 books.append ,向 books 添加一个元素
# for book in books: 第二次,默认 book 取第二次,如果还是空,则直接退出不在for,
但是由于这里的 books 只绑定的堆中的id,而上一步中,在这个id 中添加了元素,所以可以取到第二个数值
13、集合(set)
集合(set)是一个无序的、不重复的序列,可以使用大括号 { } 或者 set () 函数创建集
特点:
集合内的元素可以是无序的,比如插入一个a,不确定在那那个index位置
集合内的元素必须不重复(可以理解取字典中的 key 构成)
如何确定是集合还是字典,都是{ } ,注意字典必须是key:value 需要键值对 ,而集合只有key
字典:
set1 = {} print(type(set1)) # <class 'dict'> 字典集合(set)
set1 = {'zhangsna'} print(type(set1)) # <class 'set'>
1、集合的用处:去除重复元素,注意此时列表已经转成集合{ } ,可通过 list 强转
list1 = [1, 2, 3, 4, 5, 2, 5, 13, 1, 3, 2, 2, 1]
set2 = set(list1)
print(set2) # {1, 2, 3, 4, 5, 13}
print(list(set2)) # [1, 2, 3, 4, 5, 13]
2、注意:创建一个空集合,必须用 set () 而不是 { } , 因为 { } 是用来创建一个空字典
list = []
print(type(list)) # <class 'list'>
tuple = ()
print(type(list)) # <class 'tuple'>
dict = {}
print(type(list)) # <class 'dict'>
set = set()
print(type(set)) # <class 'set'>
3、{ } 或者 set () 区别
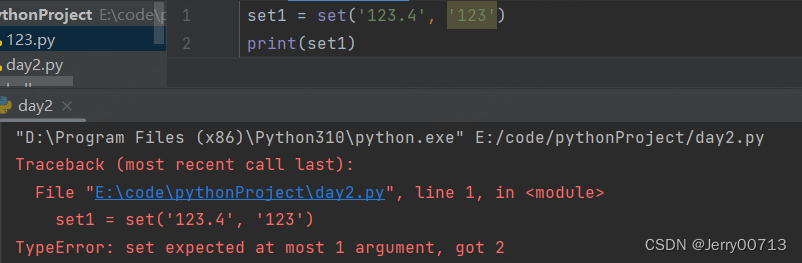
set () 只能添加一个字符串,并且会将其中的元素,按照每个字符为一个元素
set1 = set('1234') print(set1) # {'3', '1', '2', '4'}set1 = set('123.4') # {'4', '.', '3', '1', '2'} print(set1)set () 只能添加一个字符串
如果是数字或者非字符串就会报错
{ } 能添加任何数据(整型、字符串等等)
{ } 能添加多个元素,用逗号分割,其中不会将数一组数据打散划分为一个一个元素

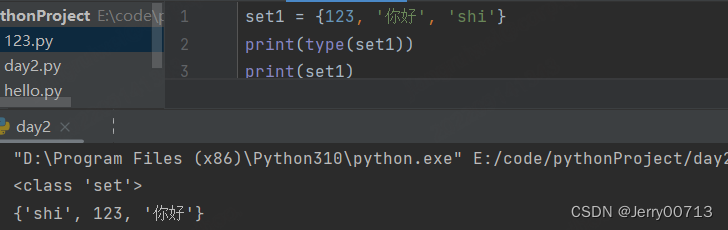
4、添加元素
append extend 只存在列表中,对应的set中 add update ,由于没有下标,所以没有insert
add 末尾追加,帮必须先声明空集合,而且一次只能添加一个,如果要使用多元素添加,只能使用 update 合并
set1 = set() set1.add('nihao') print(set1) # {'nihao'} set1.add('shijie ') print(set1) # {'nihao','shijie'}
集合(无序),多运行几次发现集合中得到元素位置不定,所以没有下标
set1 = set() set1.add('nihao') set1.add('shijie') set1.add('w') print(set1)


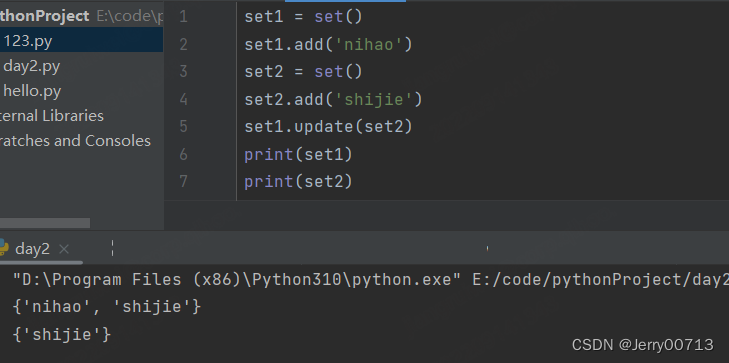
5、update 合并
set1.update(set2)
6、移除
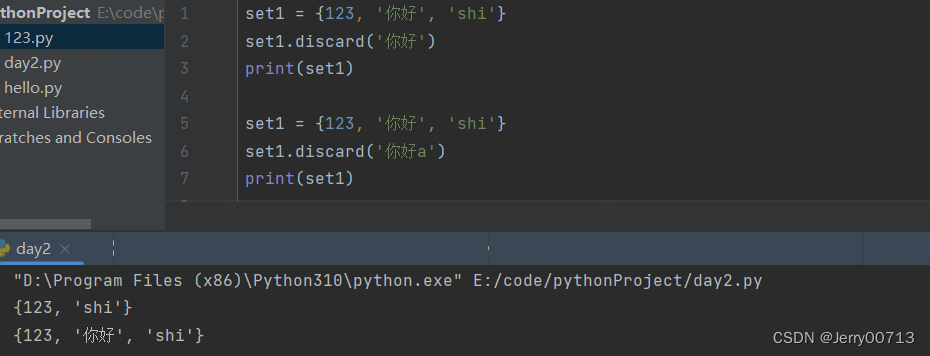
s.remove() 移除指定的元素,如果不存在,报错
set1 = {123, '你好', 'shi'} set1.remove('你好') print(set1) set1 = {123, '你好', 'shi'} set1.remove('你好a') # 报错 print(set1)s.discard() 移除指定的元素,如果不存在,不报错
del 删除整个 set ,因为没有下标
clear 清空整个 set ,不删除set
pop 随机删除
set1 = {123, '你好', 'shi'} set1.pop() print(set1)
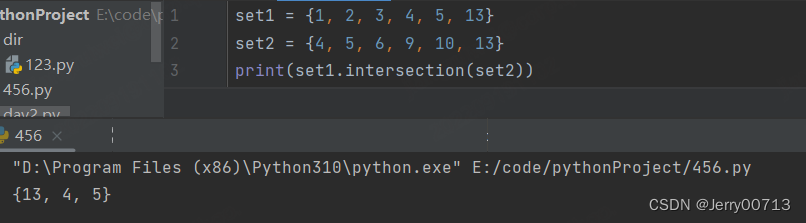
7、集合取交集.intersection() 或者 &
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1.intersection(set2))
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1 & set2) # {13, 4, 5}
8、集合取并集.union() 或者 |
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1.union(set2))
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1 | set2) # {1, 2, 3, 4, 5, 6, 9, 10, 13}

9、集合差集.difference() 或者 A - B
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1.difference(set2)) # set1有的元素,set2没有 print(set2.difference(set1)) # set2有的元素,set1没有 print(set1 - set2) # set1有的元素,set2没有 print(set2 - set1) # set1有的元素,set2没有
对称差集symmetric_difference() 或者 A ^ B
A.symmetric_difference(B) # A有的元素,B没有,记录到一个集合中。B有的元素,A没有,追加到集合中
set1 = {1, 2, 3, 4, 5, 13} set2 = {4, 5, 6, 9, 10, 13} print(set1.symmetric_difference(set2)) # set1有的元素,set2没有。set2有的元素,set1没有,记录到一个集合中 print(set2.symmetric_difference(set1)) print(set1 ^ set2) # set1有的元素,set2没有。set2有的元素,set1没有,记录到一个集合中


10、判断子集还是父集
A.issubset(B) A是B的子集?
A.issuperset(B) A是B的父集?set1 = {1, 2, 3, 4, 5, 13} set2 = {1, 2, 3} set3 = {1, 2, 3, 10} print(set1.issubset(set2)) # set1是set2的子集?False print(set2.issubset(set1)) # set2是set1的子集?True print(set3.issubset(set1)) # set2是set1的子集?Falseset1 = {1, 2, 3, 4, 5, 13} set2 = {1, 2, 3} set3 = {1, 2, 3, 10} print(set1.issuperset(set2)) # set1是set2的父集?True print(set2.issuperset(set1)) # set2是set1的父集?False print(set1.issuperset(set3)) # set1是set3的父集?False
14、公共方法
Python包含以下内置函数
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del有两种方式 |
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对key比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对key比较 |
| cmp(item1,item2) | 比较两个值,-1小于/0相等/1大于 | Python3.X取消了cmp函数 |
| + - * / % | 字符串、列表、元组 | |
| in not in | 元素是否存在 | 字符串、列表、元组、字典 |
| > >= == < <= | 元素比较 | 字符串、列表、元组 |
| min max sum abs | 最小值 最大值 求和 绝对值 | 整型 |
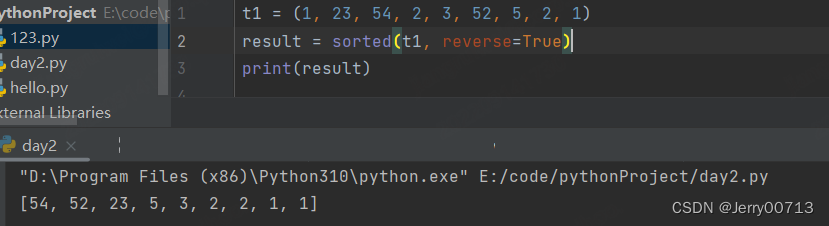
| sorted | 排序 sorted ( t1 ,reversr=True )降序 | 字符串、列表、元组、字典。默认列表带sort ,而元组等都不带,有了此函数,不用将字典转换成列表 |
| chr | 转换成字符型 | 整型、浮点型、字符型 |

15、列表推导式
想要获得一个 [1..20] 的列表
list = [] for i in range(20): list.append(i) print(list)
python 帮助我们构建了,通过有序创元素构建列表模式
list = [i for i in range(20)] print(list)解释:for i in range(20) 还是那个意思,取0~19,取出什么元素呢?取出 [ i for i in range(20)] ,取出 i ,然后存入列表中
list = [i+2 for i in range(11)] print(list)

案例:0~100 的偶数
list = [i for i in range(0, 101, 2)] print(list)

加 if 判断写法: 格式:[ i for i in 可迭代的 if 条件] 意思式如果满足if 条件,取出 i 然后存入列表中
案例:0~100 的偶数,如何通过加判断
list = [i for i in range(0, 101) if i % 2 == 0] print(list)

案例:取出列表中,全部式单词的元素,并放在列表中
list = ['b6', 'hello', '100', 'world'] list2 = [world for world in list if world.isalpha()] # isalpha判断是不是全部是单词,是返回True print(list2)

加 if else 判断写法: 格式:[ i if 条件 else 结果 for i in 可迭代的 ] 满足 if 条件,将 i 存在列表中,如果不满足if 条件,那就的满足else 条件,然后将 else 操作后的数据,存在列表中 [ 结果1 if 条件 else 结果2 for i in 可迭代的 ]
案例: 如果是h开头的纯字母,则将首字母大写,不是h开头的,全部转成大写
list = ['b6sd', 'hello', '100', 'world'] list2 = [world.title() if world.isalpha() and world.startswith('h') else world.upper() for world in list] # .title()将首字母大写 .isalpha() isalpha 是否是纯字母 startswith('h') 是否是h开头 .upper() 将字符串中小写的字母转成大写 print(list2)

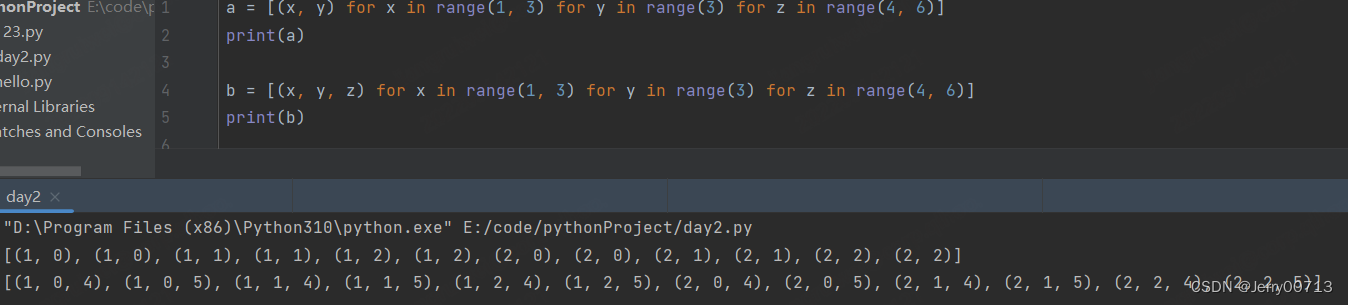
两个for 循环
a = [(x,y) for x in range(3) for y in range(3)] print(a)

三个for 循环
a = [(x, y) for x in range(1, 3) for y in range(3) for z in range(4, 6)] print(a) b = [(x, y, z) for x in range(1, 3) for y in range(3) for z in range(4, 6)] print(b)
案例:写出一段python,代码实现分组一个 list 里面的元素,比如 [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
a = [a for a in range(1, 10)] b = [a[x:x + 3] for x in range(0, len(a), 3)] print(b)解释:先使用 for 循环,打印1~9的,存入到一个 a 的列表中,在使用步长为 3 的 for 循环,控制起始值,在通过切片,取切割列表 a ,从 x 位置到 x+3 ,进行切割
或者
a = [[i, i + 1, i + 2] if i <= 98 else [i for i in range(i, 101)] for i in range(1, 101, 3)]解释:else [i for i in range(i, 101)] 会将单独的一个打出来
或者
a = [[j for j in range(i, i + 3)] for i in range(1, 100, 2)]
案例:找出里面名字含有两个 ‘a’ 的放到新的列表中
name = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
name = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] a = [y for x in name for y in x if y.lower().count('a') >= 2] print(a)

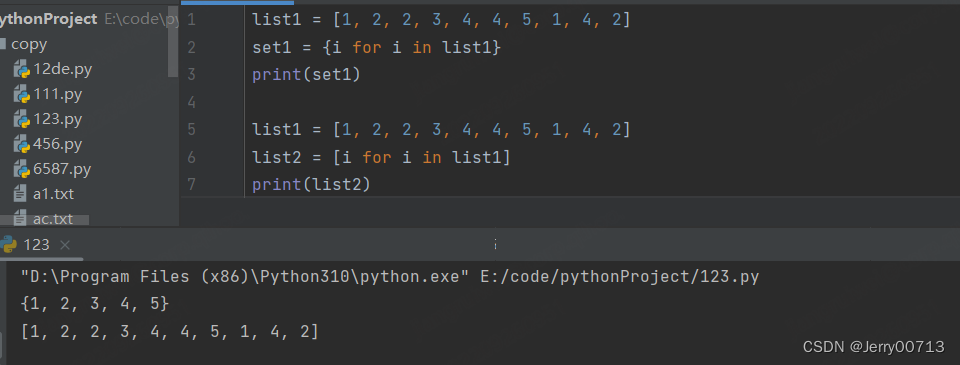
16、集合推导式
集合推导式跟列表推导式的用法一致,只不过有了集合的特性,去重
格式:使用 { }
list1 = [1, 2, 2, 3, 4, 4, 5, 1, 4, 2] set1 = {i for i in list1} print(set1) list1 = [1, 2, 2, 3, 4, 4, 5, 1, 4, 2] list2 = [i for i in list1] print(list2)
17、字典推导式
字典推导式跟列表推导式的用法一致,只不过有了字典的特性,key:value
格式:使用 { key:value }
dict1 = {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'E'} newdict = {value: key for key, value in dict1.items()} print(dict1)


