
热门标签
热门文章
- 1UIWebView和WKWebView
- 2Linux笔记--查看Linux系统自动Kill掉的进程_linux查看进程被杀掉原因
- 3c++ 报错 error: call of overloaded ‘abs(unsigned int)’ is ambiguous
- 4教你如何实现长按图片保存到相册_开启app允许长按保存图片
- 5怎么在Anaconda上更换python版本_anaconda更改新安装的python版本
- 6【目标检测】YOLO v1 (You Only Look Once) 详细解读
- 7UE5笔记【五】操作细节——光源、光线参数配置、光照图修复_ue5光照需要重建
- 8DELL服务器创建raid_戴尔服务器做raid
- 9Kubernetes 持久卷_volumeclaimtemplates
- 10【计算机网络常见面试题】电信网络的分类_电信网络类型分类的理解
当前位置: article > 正文
Kafka快速实战以及基本原理详解
作者:我家小花儿 | 2024-02-25 23:40:18
赞
踩
Kafka快速实战以及基本原理详解
Kafka快速实战以及基本原理详解
基本概念
- Kafka是一个分布式、支持分区、多副本,基于ZK的分布式消息系统,最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如Hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎、日志等
- 使用场景
- 日志收集
- 可以用Kafka收集各种服务的日志,通过Kafka以统一接口服务的方式开放给各种Consumer,比如Hadoop、Hbase、Solr等
- 消息系统
- 解耦、消息等
- 用户活动跟踪
- 记录用户的各种活动。如浏览网页、搜索、点击等,按照不同类型放到不同的Topic中,然后订阅者通过这些topic来做实时的监控分析,或者装载到Hadoop、数仓中做离线分析和挖掘
- 运营指标
- 记录运营监控数据,包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如告警和报告
- 日志收集
组成部分
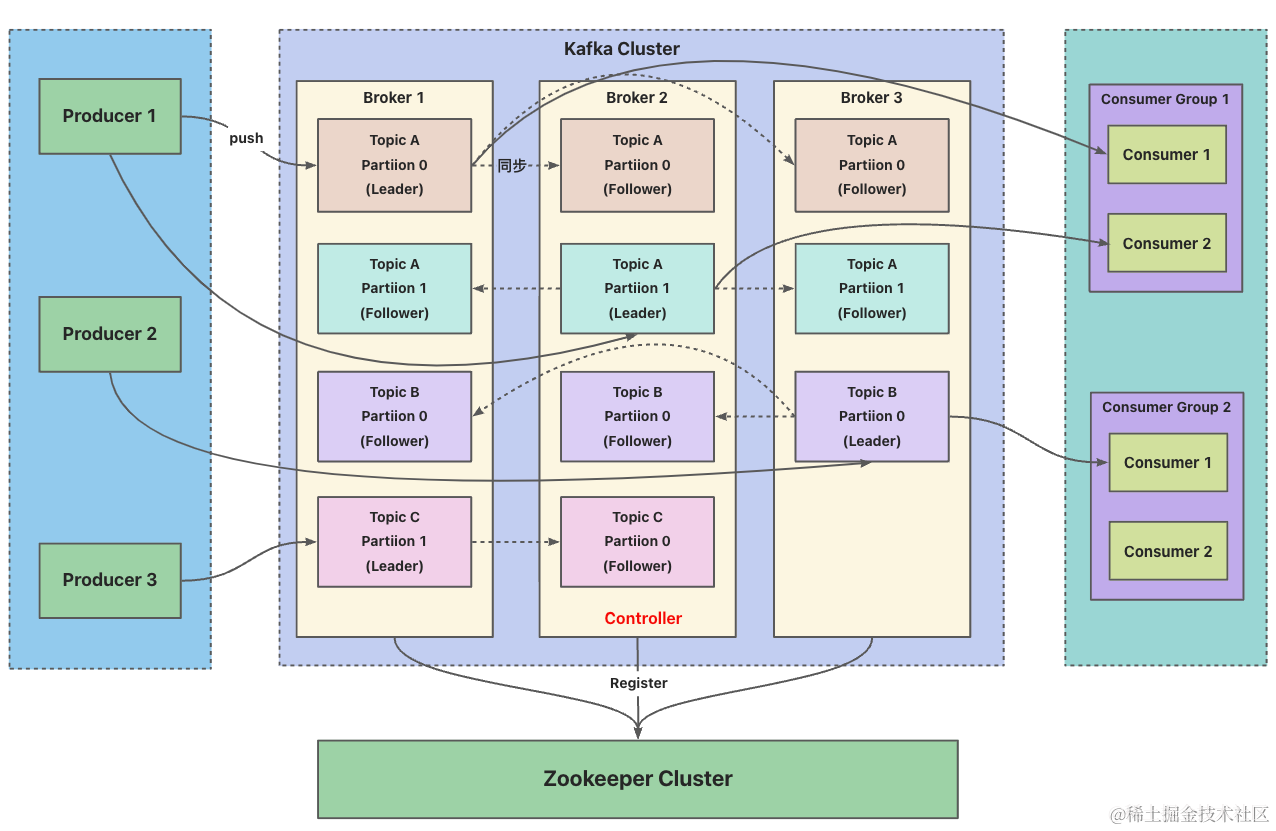
Broker- 消息中间件处理节点,一个Kafka节点就是一个Broker,一个或者多个Broker可以组成一个Kafka集群
Topic- Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个Topic
- Producer
- 生产者,向Broker发送消息的客户端
- Consumer
- 消费者,从Broker读取消息的客户端
ConsumerGroup- 每个Consumer属于一个特定的ConsumerGroup,一条消息可以被多个不同的ConsumerGroup消费,但是一个ConsumerGroup中只能有一个Consumer能够消费该消息
Partition- 物理上的概念,一个Topic可以分为多个Partition,每个Partition内部消息是有序的(类似于RocketMQ中的MessageQueue)
消息模式
单播消息- 一条消息只能被某一个消费者消费,类似Queue模式,只需让所有消费者在同一个消费组里
多播消息- 一条消息能被多个消费者消费,类似于发布/订阅模式,针对Kafka同一条消息只能被同一个消费组的一个消费者消费的特性,要实现多播只要保证消费者属于不同消费组即可
消息传递机制
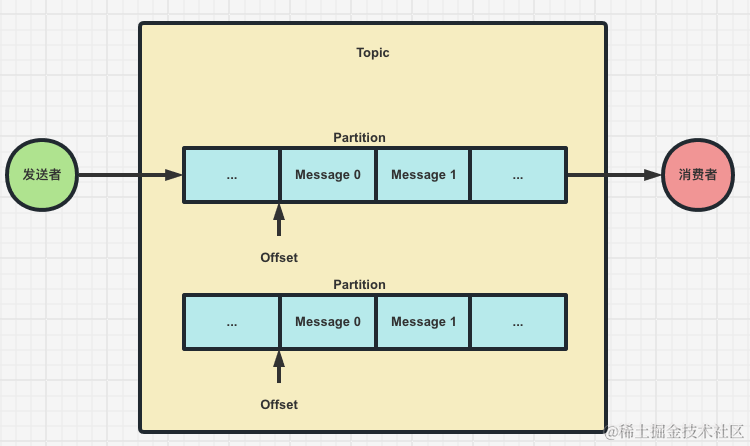
基本概念- Kafka的消息发送者和消费者通过Topic的逻辑概念进行业务沟通,但是实际上所有的消息是存在服务端的Partition这样的一个数据结构当中的
- 客户端: 包括消息生产者和消息消费者
- 消费者组: 每个消费者可以指定一个所属的消费者组,相同消费者组的消费者共同构成一个逻辑消费者组,
每一个消息可以被多个消费组的其中一个消费者消费一次 - 服务端Broker: 一个Kafka服务就是一个Broker
- 主题Topic: Topic只是一个逻辑概念,一个Topic被认为是业务含义相同的一组消息,客户端通过绑定Topic来生产或者消费消息
- 分区Partition: Partition是实际存储消息的组件,每个Partition就是一个Queue队列结构,所有消息满足先进先出的顺序保存在Partition中
Topic、Partition和Broker的关系- Kafka设计需要支持海量数据,通过将数据拆分成多个Partition,每个Broker只存储部分数据用来提升集群吞吐量,对于每个Topic下的多个Partition只有一个leader来负责客户端请求,并且遵循主备模式来应对单点故障,并且提升了读取并行度
- Topic可以有多个Partition,每个Partition是一个有序的MessageQueue,,Message会被按顺序存入commitlog中,对应的每个Message会存在一个唯一的标识offset,对于这些消息默认保留最近一周的消息,也可以通过配置进行更改,存储消息的数据量也不会影响Kafka的性能
问题: 为什么要对Topic的数据进行分区存储- commitlog会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于分布式存储,理论上一个Topic可以处理任意数量的数据,并且能提升并行度
- 每个Consumer基于自己维护在commitlog中的offset进行消费,实际业务中,我们可以通过指定offset进行消息重复消费、顺序逐条消费、跳过等操作,并且不会影响到集群以及其它Consumer
支持增加Topic的Partition数量,但不支持减少
集群消费
- 多个Partition分布在Kafka集群中不同的Broker上,每个Broker可以请求备份其它Broker上Partition的数据,Kafka集群支持配置Partition备份的数量,针对每个Partition都会有一个Broker起到leader的作用来进行读写请求,其它作为follower进行备份来保证多副本数据与消费的一致性,如果leader宕了,followe中会选举一个新leader
- 生产者
- 生产者将消息发送到Topic中,同时负责指定某个Partition进行存放,可以通过轮询进行负载均衡或关键字key进行指定,通常情况下选择关键字key较多,主要是为了保证具有相同key的消息能够被发送到同一个Partition,从而保证消息的有序性
备注- 在日志系统中,可能会将日志的某个字段(如user_id)作为key,以确保同一个用户的日志消息能够被发送到同一个Partition,并按照发送的顺序进行消费
- 如果不关心消息的有序性,或者消息本身就没有key,那么也可以不指定key,让分区采用轮询的方式来选择Partition
- 生产者将消息发送到Topic中,同时负责指定某个Partition进行存放,可以通过轮询进行负载均衡或关键字key进行指定,通常情况下选择关键字key较多,主要是为了保证具有相同key的消息能够被发送到同一个Partition,从而保证消息的有序性
- 消费者
- 队列模式
- 同一个消费组下有多个消费者,但是消息只会分配给其中一个
- 发布/订阅模式
- 多个消费组下的其中一个消费者可以收到广播消息
- 队列模式
- 消息有序
- 一个Partition同一时刻在一个消费者组下只有一个消费者进行消费,从而保证消息有序
- 消费者组下的消费者不能比一个Topic下的Partition数量多,否则多出来的消费者就消费不到消息,Kafka只能保证在Partition的范围内保证消息消费的局部有序性,不能保证在同一个Topic下多个Partition的全局消费有序性(和RocketMQ一样,只能保证局部有序,不能保证全局有序)
问题: 如何保证消息顺序消费- 如果要保证全局有序,可以将Topic的Partition数量置1,将消费者组下的消费者数量也置为1,但是这样影响了消费性能,所以Kafka全局消费有序很少用
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/142297
推荐阅读
相关标签

