
- 1RecyclerView的基本用法、横向/纵向/网格/瀑布流布局显示及点击事件_recyclerview 横向
- 2什么是SOTA,SOTA是什么意思_sota水平
- 3python湖北武汉购物店铺数据可视化大屏全屏系统设计与实现(django框架)
- 4linux+QT+FFmpeg 6.0,把多个QImage组合成一个视频_ffmpeg 6.0 + qt
- 5Linux:使用ntpdate命令同步更新系统时间_ntpd 更新时间
- 6精品微信小程序基于Uniapp+springboot基于微信小程序的摄影平台设计与实现|计算机毕业设计|Java毕业设计|课程设计|Python毕设|小程序|毕业设计推荐_基于微信小程序的摄影作品交流平台
- 7sqlalchemy更新json 字段的部分字段_sqlalchemy json字段
- 8[23000][1452] Cannot add or update a child row: a foreign key constraint fails (`test2`.`#sql-1238_5
- 9网页设计与制作(HTML+CSS)(三)_html如何在css调整视频和文字的距离
- 10LeetCode 1229. Meeting Scheduler - 亚马逊高频题32_input slots[10,50]
yolov5训练coco128数据集和测试与检测
赞
踩
yolov5训练coco128数据集和测试与检测
参考链接
为YOLOv5搭建COCO数据集训练、验证和测试环境
CoCo数据集下载
YOLOv5 环境搭建、 coco128 训练示例 、 详细记录【一文读懂】
一、coco数据集
1. 简介
MS COCO的全称是Microsoft Common Objects in Context,起源于微软2014年的Microsoft COCO数据集,主要用于目标检测,图像分割,姿态估计等,共有80个类

MSCOCO 是具有80个类别的大规模数据集,其数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片,总大小约25g。其中测试数据集没有标注信息,所以注释部分只有训练和验证的。
关于COCO的测试集:2017年COCO测试集包含〜40K个测试图像。 测试集被分成两个大致相同大小的split约20K的图像:test-dev 和test-challenge。
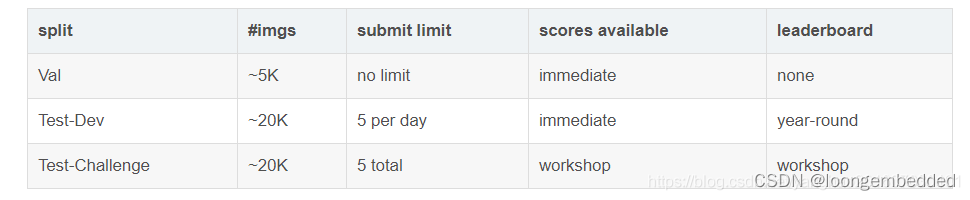
Test-Dev:test-dev split 是在一般情况下测试的默认测试数据。通常应该在test-dev集中报告论文的结果,以便公正公开比较。
Test-Challenge:test-challenge split被用于每年托管的COCO挑战
2. 下载
(1) 官网
第一种方法肯定是官网,来到下载页面:官网
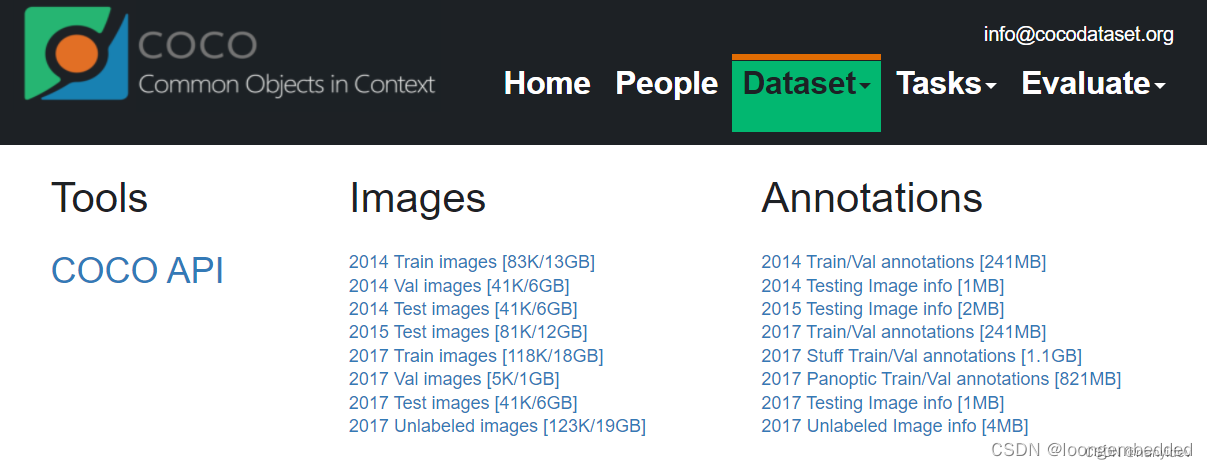
Images就是数据集,Annotations表示标注信息使用 JSON 格式存储( annotations ), COCO API用于访问和操作所有“标注”进行预处理
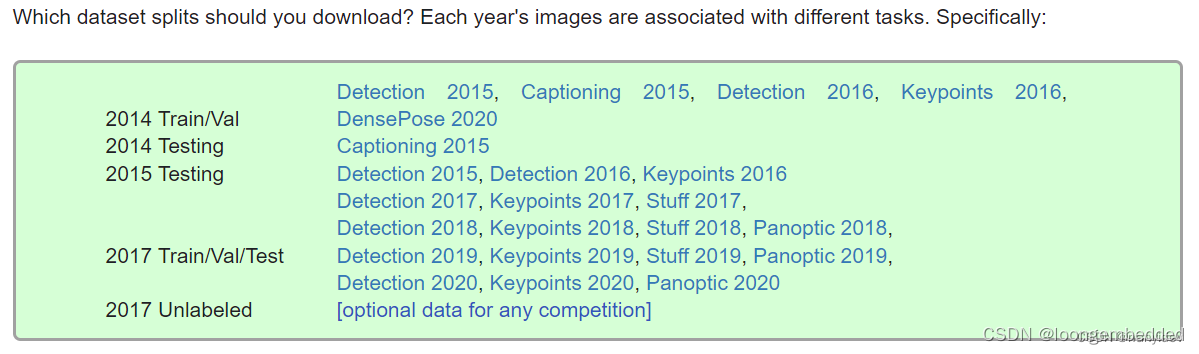
不同年份的数据集用在不同的任务上,常用的是2017 train/val/test images
(2) 其他下载方式
CoCo数据集下载
Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略
3.解压后的数据
下载后,依据https://github.com/cocodataset/cocoapi 的要求,将图片解压到coco/images/,如下图所示。

下载并按路径要求解压图片
接着下载标注文件annotations_trainval2017.zip,并按cocoapi 的要求,将标注文件解压到coco/annotations/

下载并按路径要求解压标注,其中用于目标检测的是:instances_val2017.json和instances_train2017.json
4. COCO数据集(.json)训练格式转换成YOLO格式(.txt)
详细!正确!COCO数据集(.json)训练格式转换成YOLO格式(.txt)
yolov5的数据集格式 :COCO数据集转换成yolov5训练的数据集格式代码
把下载的coco数据原图放到images目录下,标准文件放在annotatioons下,在coco数据集中,coco2017train或coco2017val数据集中标注的目标(类别)位置在annotations 文件中以 (x, y, width, height) 来进行表示,x,y表示bbox左上角位置,width, height表示bbox的宽和高。而在YOLO训练或者进行验证的时候读取的标注格式是以 (xmin, ymin, xmax, ymax) 来进行表示,xmin, ymin表示bbox左上角位置, xmax, ymax表示bbox右下角位置,并且要求保存为.txt文件格式(名字与image对应)

实现代码如下
#-*-coding:gb2312-*- #COCO 格式的数据集转化为 YOLO 格式的数据集 #--json_path 输入的json文件路径 #--save_path 保存的文件夹名字,默认为当前目录下的labels。 import os import json from tqdm import tqdm import argparse parser = argparse.ArgumentParser() #这里根据自己的json文件位置,换成自己的就行 parser.add_argument('--json_path', default='/home/kandi/datasets/coco/annotations/instances_train2017.json',type=str, help="input: coco format(json)") #这里设置.txt文件保存位置 parser.add_argument('--save_path', default='/home/kandi/datasets/coco/labels/train2017', type=str, help="specify where to save the output dir of labels") arg = parser.parse_args() def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = box[0] + box[2] / 2.0 y = box[1] + box[3] / 2.0 w = box[2] h = box[3] #round函数确定(xmin, ymin, xmax, ymax)的小数位数 x = round(x * dw, 6) w = round(w * dw, 6) y = round(y * dh, 6) h = round(h * dh, 6) return (x, y, w, h) if __name__ == '__main__': json_file = arg.json_path # COCO Object Instance 类型的标注 ana_txt_save_path = arg.save_path # 保存的路径 data = json.load(open(json_file, 'r')) if not os.path.exists(ana_txt_save_path): os.makedirs(ana_txt_save_path) id_map = {} # coco数据集的id不连续!重新映射一下再输出! with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f: # 写入classes.txt for i, category in enumerate(data['categories']): f.write(f"{category['name']}\n") id_map[category['id']] = i # print(id_map) #这里需要根据自己的需要,更改写入图像相对路径的文件位置。 list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w') for img in tqdm(data['images']): filename = img["file_name"] img_width = img["width"] img_height = img["height"] img_id = img["id"] head, tail = os.path.splitext(filename) ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致 f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w') for ann in data['annotations']: if ann['image_id'] == img_id: box = convert((img_width, img_height), ann["bbox"]) f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3])) f_txt.close() #将图片的相对路径写入train2017或val2017的路径 list_file.write('./images/train2017/%s.jpg\n' %(head)) list_file.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
YOLOv5把官方的json格式的标注文件解析成为txt文件,也可从链接下载,然后解压到…/datasets文件夹
二、训练train.py
- train.py:数据加载器旨在兼顾速度和准确性
- val.py:验证(Validation)通常在完成模型训练后,用于测试模型的精度,mAP
- detect.py:旨在真实世界中获得最佳的推理结果。
。
我这里选择 COCO128 上训练 YOLOv5s 模型。预训练权重是从最新的 YOLOv5 版本自动下载的。
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
- img:指定训练照片的像素
- batch:单次迭代训练图片数,越大所需内存越大
- epochs:训练轮次
- data:需按照自己的数据集及其位置修改
- weights:权重文件
训练时终端的输入部分日志信息如下:
Class Images Instances P R mAP50 mAP50-95: 50%| | 2/4 00:00 Class Images Instances P R mAP50 mAP50-95: 75%| | 3/4 00:00 Class Images Instances P R mAP50 mAP50-95: 100%|| 4/4 00:00 Class Images Instances P R mAP50 mAP50-95: 100%|| 4/4 00:00 all 128 929 0.748 0.651 0.737 0.487 3 epochs completed in 0.003 hours. Optimizer stripped from runs/train/exp/weights/last.pt, 14.8MB Optimizer stripped from runs/train/exp/weights/best.pt, 14.8MB Validating runs/train/exp/weights/best.pt... Fusing layers... Model summary: 157 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs Class Images Instances P R mAP50 mAP50-95: 0%| | 0/4 00:00 Class Images Instances P R mAP50 mAP50-95: 25%| | 1/4 00:00 Class Images Instances P R mAP50 mAP50-95: 50%| | 2/4 00:01 Class Images Instances P R mAP50 mAP50-95: 75%| | 3/4 00:02 Class Images Instances P R mAP50 mAP50-95: 100%|| 4/4 00:03 Class Images Instances P R mAP50 mAP50-95: 100%|| 4/4 00:03 all 128 929 0.752 0.651 0.738 0.487 person 128 254 0.871 0.718 0.808 0.528
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
其中可以看到Validating runs/train/exp/weights/best.pt…,说明在训练阶段每个batch训练结束后,都会调用一次val脚本,进行一次模型的验证。而当整个模型训练结束是,同样再会调用一次这个val脚本。
所有训练结果都保存在runs/train/递增的运行目录中,即runs/train/exp2等runs/train/exp3,训练完成后,在runs->train->exp->weights文件夹下找到last.pt和best.pt文件,其中best.pt是训练效果最好的权重文件,last.pt是训练最后一轮的权重文件
三、验证val.py
- test.py已改为val.py
- train.py:数据加载器旨在兼顾速度和准确性
- val.py:验证(Validation)通常在完成模型训练后,用于测试模型的精度,mAP
- detect.py:旨在真实世界中获得最佳的推理结果。
训练完成后,在runs->train->exp->weights文件夹下找到last.pt和best.pt文件打开val.py运行,进行模型验证。
python val.py --weights runs/train/exp6/weights/best.pt --data coco128.yaml --img 640
四、推理预测detect.py
- train.py:数据加载器旨在兼顾速度和准确性
- val.py:验证(Validation)通常在完成模型训练后,用于测试模型的精度,mAP
- detect.py:旨在真实世界中获得最佳的推理结果。
1. 用coco128训练的模型best.pt来检测
上面我们训练出来的小权重文件best.pt大概14.1M左右,检测的命令如下:
python detect.py --weights runs/train/exp6/weights/best.pt --source data/images/zidane.jpg
检测的结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pi7ruYTd-1670036355059)(yolov5训练coco数据集.assets/image-20221203091642062.png)]](https://img-blog.csdnimg.cn/c25d18bc42b8432ea9822c227a7dd46e.png)
2.用yolov5预先训练好的小模型yolov5s.pt
yolov5s.pt大概也是14.1M左右,检测命令如下:
python detect.py --weights weights/yolov5s.pt --source data/images/zidane.jpg
检测结果如下:

3. 用yolov5预先训练好的大模型yolov5x6.pt
yolov5x6.pt约为269M,检测命令如下
python detect.py --weights weights/yolov5x6.pt --source data/images/zidane.jpg
检测的结果如下

从上面3种情况检测得到的置信度值(红色和绿色框上的数值),大权重文件得到的可信度数值越高。

