
- 1div+css网页html成品学生作业包含10个html页面——动漫主题海贼王
- 2Unity 如何把UGUI做到极致的优化_ugui如何美化
- 3python毕设选题 - 大数据B站数据分析与可视化 - python 数据分析 大数据
- 4ubuntu安装opencv4.X+opencv_contrib教程(c++)_c++ ubuntu opencv_contrib
- 5提高VB6.0处理图像的速度的方法_vb propertybag 存取图片
- 6Unity|| 如何把生存类游戏设计得更优秀_unity生存游戏
- 7Unity3D教程:动画合成教程(Animation Blending)_untiy animation合并
- 8下班前几分钟,Express 快速入门_express入门
- 9unity中2种模型边缘划线的方法 outline unity3d_unity 三维模型怎么加outline
- 10VUE学习(三) 箭头函数(=>)_vue =>
【Linux】基础IO
赞
踩
目录
每个操作系统级别的概念,都必须有操作系统级别的数据结构与之对应。
文件的基础知识
我们常说的文件,一般指的是磁盘中的文件,要对文件进行操作,首先应该先将它加载到内存中。
文件 == 内容 + 属性
文件内容和文件属性都是文件的数据,操作文件,包括对文件内容做操作和对文件属性做操作!
当我们要访问一个文件的时候,一般都是通过进程去访问,而文件是存在磁盘中的,所以肯定是进程通过操作次用来打开文件,那么操作系统一定要给进程提供调用文件的接口!
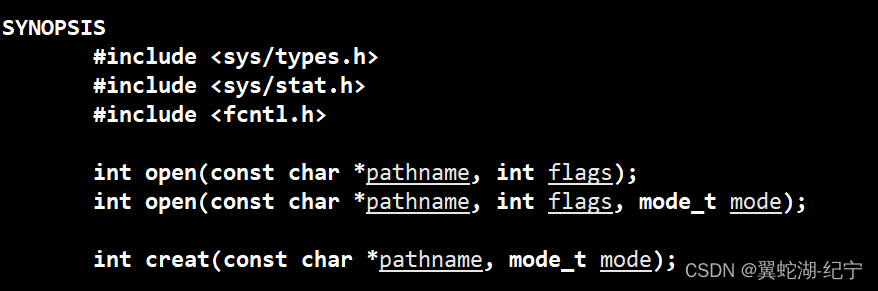
上图为操作系统提供的打开文件的接口,C中的 fopen函数,C++中的open函数,其实底层都封装了系统中的 open 接口。
调用 open 接口需要将文件路径和打开方式、文件权限作为参数传给 open,而 open 接口的返回值叫 文件描述符 fd,fd 是一个整数,它是进程访问文件的基本方式!在关闭某个文件的时候,只需要给 close 接口传这个文件的 fd 即可。

对于进程访问文件,用C程序来举例子:(下面先列举对应的C语言文件接口)
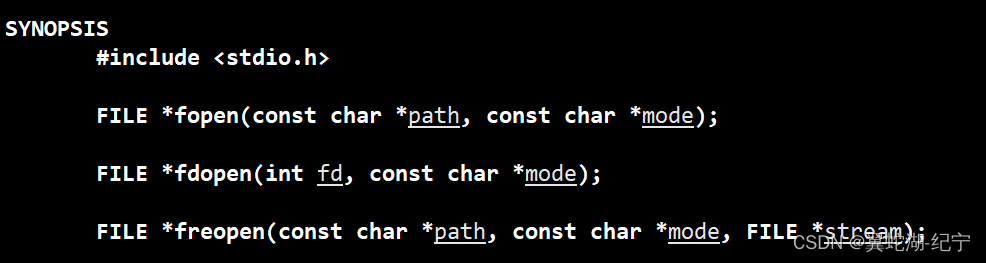

比如在C文件中调用 fopen 函数打开对文件做操作,当这个C文件被编译成一个可执行程序加载到并内存的时候,就会变成一个进程,当这个进程代码运行到 fopen 的时候,就会执行打开文件操作,文件就会被加载到内存中,一个C程序可以多次调用 fopen 函数,那么说明一个进程可以打开多个文件,那么多个进程在被轮转调度的时候,就可能会打开更多的文件!
所以 进程 :打开的文件 = 1:n
打开如此多的文件,那么在内核中必须形成对应的文件描述对象(里面存文件的属性等内容),通过某种数据结构将文件管理起来,来方便操作系统组织和访问。
文件打开的方式
第一个参数是要打开文件的路径,而第二个参数是打开的方式。
第二个参数,运行位图的方式,巧妙的传递了打开方式。

第一种传参方式类似于 fopen 函数中的以 "w" 方式打开(会清空文件重新写),而第二种传参方式类似于 fopen 中的以 "a" 方式打开(在已有文件后追加内容)
如果是创建文件的话,还可以将新文件的权限作为第三个参数传过去。
进程、系统、文件之间的关系
那么,在操作系统中,进程如何对打开的文件进行管理呢?
每一个被打开的文件,都会用一个 struct file 结构体来描述它,多个文件就用多个 struct file 结构体描述,并且将这些结构体用合适的数据结构管理起来。已知,在一个进程中,每一个被打开的文件都会用一个进程描述符 fd 来表示,这个 fd 就是进程访问文件的方式。
每个进程的 struct files_struct 中都有一个 struct files_struct* file 指针,指向同一个 struct files_struct ,而struct files_struct 中保存着一个数组 fd_array,这个数组中存储着当前进程打开的所有文件的地址,而这些文件的地址在这个数组中对应的下标就是 fd。也就是说,当一个文件打开被加载到内存的时候,它的地址就被存到了 struct files_struct 结构体对应的 fd_array 数组中,并且会返回它存储位置的数组下标 fd,以后就可以通过数组下标 fd 来得到文件地址,进而对文件进行访问!
操作系统访问文件,只认文件描述符!

但奇怪的是,当我们创建多个文件,并打印出文件描述符的时候,虽然 fd 是一个连续的小整数,很符合数组的连续存储,但却不是从零开始的,这是为什么呢?

Linux 中一切皆文件!!!
其实,一个进程在运行的时候,就默认打开了三个标准输入输出:
标准输入:键盘 stdin ——> fd:0
标准输出:显示器 stdout——> fd:1
标准错误:显示器 stderror ——> fd:2
1 ——> 常规输出 2——> 错误输出(C语言中的 perror 就可以打印错误信息),也可以将正常输出信息和错误输出信息分别重定向到不同的文件中,方便管理和调试。
这三个硬件,在Linux 经过系统上层封装后,键盘、显示器等可以用统一的接口(read()、write())利用不同的变量来访问,其他的软硬件也都经过通过文件的访问方式封装,所以Linux 下一切皆文件!(VFS 虚拟文件系统)

这提前打开这三个文件是为了方便程序员写代码的。
std、stdout、stderr都返回一个 FILE* 指针(而FILE 其实是C语言提供的结构体类型),因为操作系统访问文件时只认文件描述符,所以由此推断:FILE 必定封装了文件描述符!
由此得出:每一种语言,在底层其实封装的是一种系统调用接口,这是由操作系统决定的,而且必须是一样的,不然在同一个操作系统中没法使用!
文件重定向
文件重定向的本质是:修改特定文件 fd 下标对应的文件地址
一般有三种重定向方式:
- 输出重定向(先清空,再写入)
- 追加重定向
- 输入重定向
dup2(int oldfd, int newfd); // 系统调用接口在文件被打开后调用,即可将 oldfd 对应的地址拷贝到 newfd 对应的地址处去,这样 oldfd 和 newfd 都指向同一个文件,在内核 struct file 中会有一个 f_count 的引用计数来控制,当要 close 文件的时候,f_count 先减1,只有当 f_count 减到 0 的时候,文件才会被关闭!
进程访问文件的步骤
总结:进程要访问,第一步,必须将文件数据先加载到文件缓冲区(内存中),然后通过进程中的struct files_struct* file指针,访问 struct files_struct,找到并遍历 fd_array 数组,找到最小的,未被使用的空间,将打开文件的地址存进去,然后就可以通过这个数组下标 fd 来访问文件了!
缓冲区
缓冲区分为:语言级缓冲区(用户级缓冲区)和内核缓冲区
缓冲区的主要作用是提高使用者的效率
缓冲区因为能暂存数据,必定有一定的刷新方式。
缓冲区刷新的一般策略有三种:无缓冲(立即刷新);行缓冲(行刷新,一般是显示器文件);全缓冲(缓冲区满了再刷新,一般是磁盘文件)
特殊情况:强制刷新;进程退出时,要刷新缓冲区。
我们平时使用的缓冲区,其实是语言级缓冲区(用户级缓冲区),从C语言缓冲区写入到OS/文件缓冲区中,这个工作叫做刷新。
以C语言为例:C语言给C库函数提供缓冲区,可以提高C库函数(IO类)的调用效率(都是在用户层),而IO的本质就是拷贝,先由用户级缓冲区拷贝至内核(文件缓冲区),再由文件缓冲区拷贝至文件(硬件)
正常情况下,在进行输入输出的时候,都有一个FILE,FILE是一个结构体,C语言中的缓冲区就在FILE中(FILE 中也包含了fd),FILE 可能会提供 buffer[]数组这种类型的东西作为缓冲区暂时储存数据。
int fsync(int fd);//将数据从文件缓冲区刷新到文件/磁盘中文件系统
无论被打开的文件还是尚未被打开的文件,都要进行管理,路径的存在就是为了解决快速定位文件,因为无论什么对文件的操作,都得先找到!文件被管理起来,就是为了方便OS进行增删查改。
在磁盘中,通过 CHS 定位法(C、H、S)三个参数读取扇区位置,不同的扇区存不同的数据,这是用软件来控制的。
将磁盘高度抽象为以扇区大小为单位的数组,那么对磁盘的管理,就变成了对数组的管理,只要知道这个文件的起始扇区、大小,就可以通过索引来访问文件。
操作系统可以基于文件系统,按照文件块为单位进行数存取。
文件块都存储在磁盘中的 blocks[n] 数组中,对文件系统的管理,其实就是对 blocks 数组的管理;对存储设备的管理,在 OS 层面上,转换成了对数组的增删查改。
文件系统存储、寻址
我的文件信息分为内容和属性,内容和数据在原则上是分开存储的。很多管理文件的数据,得先让管理系统写入到块组中。
下图为文件系统图

- Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
- 超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息,有兴趣的同学可以在了解一下
- 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
- inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
- i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
- 数据区:存放文件内容
运行下面的指令
ls -li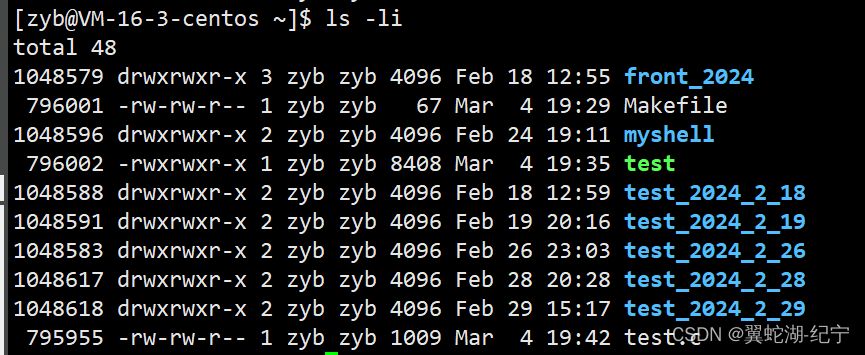
可以看到每个文件前面都有一串类似于编号的数字,这个数字就是 inode 编号,基本上 inode 编号每个文件都会有,inode 编号对应的文件在整个分区具有唯一性,在Linux 内核中,同一份区,识别文件和文件名无关,只和 inode 有关!
inode Table i 结点表中存储了很多内容,例如文件大小、权限、拥有者、所属组、inode 编号等等,还存储着文件在文件数据区的块号 block[N] 1 2 3 4...,一个 inode Table 通常是128字节
数据区 Data blocks 相当于是一张非常大的以 4KB 为单位的连续数据块区域。通过 inode Table 中的 block[n]编号来访问。
inode Bitmap ——inode 位图,每一个比特位表示某个 inode 是否可用(1为可用,0为不可用)
Block Bitmap ——block 位图,每一个比特位表示某块 block 区域是否可用。
位图可以用最小的代价来对 inode 和 Block 块区做管理
新建 / 删除一个文件的步骤
新建文件
- 1、查询 inode Bitmap ,找到最近一个未被占用的 bit 位,置1,并记录相对于第一个比特位的偏移量
- 2、找到 inode Table 里对应的 inode,写入属性,编号
- 3、查 block Bitmap 找到一块未使用的区域,往 inode Table 中的 block[N] 中填写上去。(这个 N 一般是 15 ,一个块是 4 kb 大小的空间,有13个可以直接进行存储使用,因此至少有 13*4 = 52 kb 的大小放置文件,这对于普通文件足够了,对于大文件会在下面详谈。)
- 4、找到数据区对应的块后,将数据写入块,并向上层系统反映,文件创建成功!
如果新建文件过大如何处理?
inode Table 中,block[N],这个N一般是15,但只有编号 0~12 是直接映射数据块的,13号是间接映射,里面存储其他块的索引;14号是三级索引,相当于两次间接索引,可表示的文件大小会成指数级增加,但如果这样都满了呢?可以将文件存在其他的 group 块里,只需要在inode Table 索引中记录下另一个或多个 group 的编号信息即可。
删除文件
改变位图即可!只需要先根据 inode找到 inode Bitmap,将位图中 inode 对应的 bit 位置0,再找到 inode Table,找到数据块数组 block[N],通过这个找到对应的 block Bitmap 位图,将对应的数据块(们)在位图中的 bit 位置零。
将位图对应的 bit 位置零后,会让 inode 和 data block 无效,而不是立即清除数据区里面的内容,因为可能会存在误删的情况,且被删除文件的 inode 和 data block 将来会被覆盖,所以误删后,最好是什么文件都不能创建。
想要恢复文件,就要直到 inode 编号,通过inode 编号找到位图,修改位图,即可恢复文件!
由文件系统到文件名
inode 是系统中对于文件的“名称”,而文件名是同一目录下文件的唯一名称。用户只用文件名,内核只用 inode 编号!
那么文件名是如何和 inode 进行映射的呢?
一个文件的上级目录中保存着文件名(包括目录文件)和 inode 的映射关系 如 test.c:1234,test.c 与 1234 互为键值,所以在同一目录下不允许存在同名文件!
Linux 下一切皆文件,而目录文件与普通文件的区别只是存储内容的不同,其余存储方案都一模一样,当然,这也说明:Linux 下文件名不属于文件属性,因为属性在 inode Table 里存储,而文件名再目录里呢!
那如何找到目录的 inode 呢?
首先要知道路径(环境变量 PWD),根据路径一直向上找父亲目录,直到找到根目录 ,根目录的inode已知,再根据目录中存着文件名和 inode 的对应关系这一理论,一直往下,即可找到目标目录的 inode。补充:OS 基本都是以绝对路径查找的,难道每次找相同的文件,都要从根目录慢慢加载吗?其实不是的,Linux中会将常用路径缓存带内存中,第二次就直接在内存里找了!

那么如何确认文件在哪个区下呢?
一般操作系统会在挂载的时候,将目录的数据结构和文件系统的数据结构用指针关联起来,因此知道了目录就能找到分区! 每个文件都有路径,通过路径的前缀,就能判断文件在哪个分区下!
进程加载文件的总步骤!
吗,每个进程都有自己的 CWD,由CWD 和自己传入的路径,就能确认文件在磁盘中的位置,进而确定文件的分区,根据路径就能找到文件的上级目录,上级目录中存着目标文件与 inode 的映射关系,找到 inode 后,就找到了文件的属性,将属性加载到内存中,在内存中构建 struct file 结构体,把 inode 中的属性填充到 strcut file 中,你在内核中也就有了文件的 inode,然后可以由 struct struct_file* 执行内存级 inode,此时文件属性也就有了,然后根据文件的 inode ,找到文件的 data block 数据块,加载到内存的缓冲区里,如果要读的话,将缓冲区里的数据拷贝到应用层即可!

