
基于GPT-SoVITS少样本语音转换的实时交互TTS
赞
踩
项目地址:https://github.com/DLW3D/GPT-SoVITS
该项目基于 RVC-Boss/GPT-SoVITS-WebUI
前言
GPT-SoVITS-WebUI 实现了使用WebUI的简易小样本语音模拟和文本转语音所需的完整流程,包括数据清洗、文本标注、模型微调、文本转语音。
该项目是对 GPT-SoVITS-WebU 中文本转语音功能的一个封装,提供了一个命令行程序,实现了实时输入文本播放语音的高效交互。
介绍
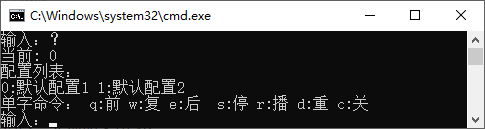
该项目提供一个命令行交互程序,实现如下功能:
- 在命令行中直接输入文本并点击回车,将在后台开启一个线程基于配置文件中指定的模型将该文本转为语音,转换完成后立即在指定的音频输出设备播放。
- 文本转语音和语音播放将使用后台线程进行,在这过程中可以输入下一条文本。
- 可以随时切换不同的模型。
- 可以随时切换不同的音频输出设备。
- 在命令行中输入
[配置序号]:切换配置。配置文件中可包含多个配置,每个配置可以指定不同的声音模型和播放设备。- 配置文件支持热重载
- 在命令行中输入
单字指令可控制语音播放,如选择上一句、选择下一句、暂停、继续、重播等。
项目配置
-
下载项目文件
-
在windows下按照
GPT-SoVITS-WebUI官方文档进行配置,确保通过官方测试用例。 -
在你使用的python环境中安装 pyaudio 库
pip install pyaudio -
编辑模型配置文件
cmd/model.yaml,指定使用中可切换的模型、参考音频以及声音输出设备。0: name: 默认配置1 device: sovits_path: GPT_SoVITS/pretrained_models/s2G488k.pth gpt_path: GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt ref_wav_path: ref_wav/ref_wav1.wav prompt_text: ref_wav1.wav 对应的文本 prompt_language: 中文 text_language: 中英混合 1: name: 默认配置2 device: CABLE Input sovits_path: SoVITS_weights/Sample_e8_s144.pth gpt_path: GPT_weights/Sample-e15.ckpt ref_wav_path: ref_wav/ref_wav2.wav prompt_text: ref_wav2.wav 对应的文本 prompt_language: 中英混合 text_language: 中英混合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
其中
device留空为使用系统默认播放设备。若需指定输出设备,则执行下述python代码检查系统中的音频输出设备,并选择其一填入。import pyaudio pyAudio = pyaudio.PyAudio() all_device = [pyAudio.get_device_info_by_index(i) for i in range(pyAudio.get_device_count())] output_device_name_1 = [i['name'] for i in all_device if i['maxOutputChannels']>0 and i['hostApi']==0] print('----------------------------') print('\n'.join(output_device_name_1)) print('----------------------------') output_device_name_2 = [i['name'] for i in all_device if i['maxOutputChannels']>0 and i['hostApi']>0] print('\n'.join(output_device_name_2)) print('----------------------------')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
如需将音频输出转为输入(播放的声音映射到麦克风中),安装虚拟音频设备 VB-CABLE Virtual Audio Device 然后配置文件中指定
device: CABLE Input
操作说明
启动根目录下的 tts.bat。程序初始化完成后,最后一行出现输入:后即可输入需要TTS的文本。
输入文本后敲击回车,会开启一个线程在后台将其转换为音频,并立即播放到指定设备。在这过程中用户可以输入下一条文本并提交下一个TTS任务。
输入?可查看当前选择的模型、配置可用的模型和用于播放控制的命令。
模型选择
在交互界面中,输入[num]: [text],使用第[num]个模型将[text]转为语音并立即播放。例如:
输入:1: 测试测试,一二三四
- 1
也可输入[num]:切换模型,再直接输入[text]进行TTS:
输入:1: 测试一 (使用模型1播放:测试一)
输入:2:
输入:测试二 (使用模型2播放:测试二)
输入:测试三 (使用模型2播放:测试三)
输入:3:测试四 (使用模型3播放:测试四)
输入:测试五 (使用模型3播放:测试五)
- 1
- 2
- 3
- 4
- 5
- 6
播放控制
可以使用单字命令进行播放控制,也可选择之前播放的语音进行重播。
- s: 暂停播放
- r: 恢复播放
- d: 重播
- c: 关闭(删除该条语音)
- q: 选择前一句
- w: 选择最后一句
- e: 选择后一句
输入:1: 测试一 (模型1播放:测试一)
输入:2: 测试二 (模型2播放:测试二)
输入:测试三 (模型2播放:测试三)
输入:d (模型2播放:测试三)
输入:q
选择:测试二
输入:q
选择:测试一
输入:d (模型1播放:测试一)
输入:e
选择:测试二
输入:d (模型2播放:测试二)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

