
- 1Realtek WiFi调试命令_reltek wifi校准
- 2树莓派Ubuntu Server20.4.1搭建web可外网访问_how can i visit foreign web in ubuntu system20.04
- 3外包众包接单方法_中移在线众包平台为什么找不到了
- 4在线AI文本生成工具有哪些?10款强大的文本生成器推荐!
- 5Day09 WEB服务(Enginner03)
- 6python入门中_
- 7抽取ORACLE表数据到HIVE_${src_table}
- 8图像融合质量评价方法的python代码实现——MS-SSIM_msssim
- 9JS中的事件监听操作_document.body.removechild 怎么监听
- 10vscode安装react,初始化一个react新项目_vscode怎么终端下载react
从Hadoop到云原生,谈如何消除程序员35岁危机
赞
踩


作者:小智
来源:智领云科技
前
言
35岁这个“职场枯荣线”,确实真实存在。
不知从何时起,很多企业将入职门槛限定在35岁以下,“35岁”已然成为职场中年的魔咒。尤其是程序员这个群体,年龄绝对是最难以隐忍的痛点。因为很多程序员普遍存在于如前期“打英雄”发育快,越到后期越乏力的尴尬窘境。
提前做好规划,看清技术趋势,不沉迷于以往的成就,不仅可以优雅过渡35岁危机,甚至会迎来职场真正的黄金期。
无论么时候,锤炼和深挖自己的技能都是必不可少的。但是,跟上快速迭代的技术变化,同样不可忽视。比如,很多程序员声称自己是Hadoop专家,此前他们对此的确非常精通,而如今在精湛的技能下却不得不感到危机,毕竟Hadoop正面临着淘汰,这就意味着以前是专家以后很可能没饭吃。所以,程序员必须意识到技术是不断前进的,如何掌握技术趋势而不是追求热点才是关键所在。

让Hadoop面临淘汰的,正是来自云原生的力量
伴随云计算的滚滚浪潮,云原生的概念应运而生,而如此火爆的概念却难以用只言片语解释清楚,因为云原生一直在发展变化之中,解释权不归某个人或组织所有。
CNCF对云原生的定义:云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
我们以CNCF官方的定义来看,云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。云原生技术可以让系统松耦合,支持弹性伸缩、可管理且清晰。通过整合健壮且有效的自动化,工程师可以用很少的劳动来完成频繁的、预期中的高危代码修改。
说白了,如果是Cloud Native的程序,写完之后在云上一发布,程序就自动运行和运维了,我只需要负责业务逻辑就可以了。通俗来说其特征是:
发布的时候最简化,不用指定主机、端口、存储……
日志、容错、数据备份、监控都是自动的
底层硬件错误跟程序员没有关系
自动扩容、降容、加机器、换机器都不是程序员的事情
别人发布应用肯定不会影响自己的应用
如果这家云厂商太贵了,可以直接迁到另一家云上运行
只为自己实际使用的计算和存储付费,不用预先购买
实际上,近两年云计算概念被清晰细分,“云原生”已经成为那条最大的鱼。“大鱼”来了,程序员们能做的不应该是墨守成规,而是必须拥抱“大鱼”。
Hadoop使命已经完成 并一定会被取代
Elephant in the room,比喻一个问题因太过于庞大或麻烦,导致没有人愿意去碰。
巧的是,Hadoop的标志就是一头大象,正面临着“Elephant in the room”这样的窘境。

不得不说,很多大数据系统不是云原生的,像Hadoop、Hive、Mongo等绝大部分大数据组件发展于云计算技术成熟之前,所以这些组件必须自己做协同、存储、备份、日志,来处理资源与集群管理。
而像Kubernetes这样的云基础设施,很长一段时间对Stateful Applications(有状态应用)的支持并不友好。即使像Spark这样在云原生的环境下开发的应用(其原生就是在Mesos集群中发布),并没有做自己调度和集成管理,但是后期为了与K8s兼容,还是做了很多改动,今年年初才进入GA的阶段。
但是,随着Kubernetes对各种大数据组件的支持不断完善,Hadoop的历史使命似乎已经逐渐完成,而所有的新的大数据应用,大概率都会基于容器发布,否则必将失去市场。
Hadoop如何被取代?
Hadoop的三驾马车是MapReduce、YARN、HDFS。
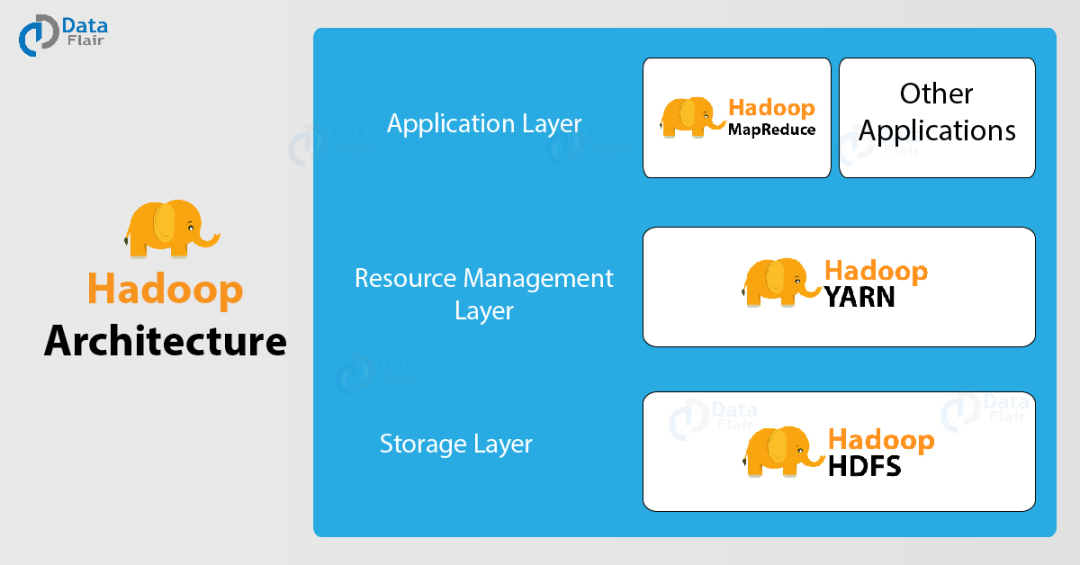
其中,MapReduce因效率太低,早已被Spark所取代;YARN并非正规的容器且效率不高,可以被类似于K8s的新一代容器调度体系取代;唯一生命力比较强的是HDFS,因为大部分大数据组件的HDFS API是兼容的,所以取代HDFS暂时有些难度。
尽管,HDFS很难被去掉,不过不用担心,因为基本上HDFS只有API是真正有用的。
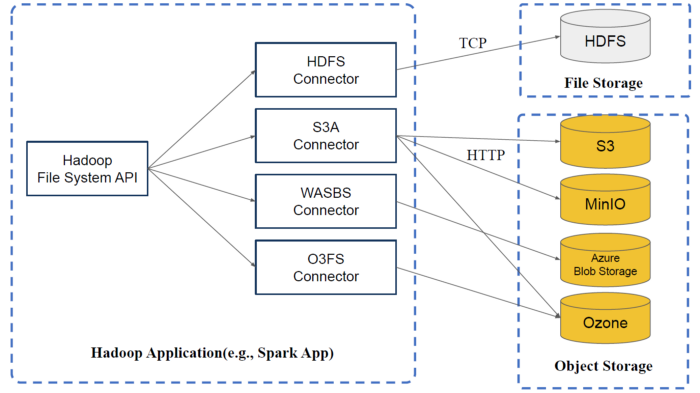
因为很多程序是用HDFS的API使用的,如图通过HDFS连接器,再通过TCP访问HDFS,效率是最高的。当然也可以通过S3A、WASBS、O3FS访问相应的S3、MinIO、Ozone……但如果意识到HDFS是真正的存储,下面都是其他的存储,只需要使用相同的API就可以了。
所以,其实Hadoop里所有的东西都可以替换。如图,显示了在不安装Hadoop的情况下,可以相对应替代的工具。
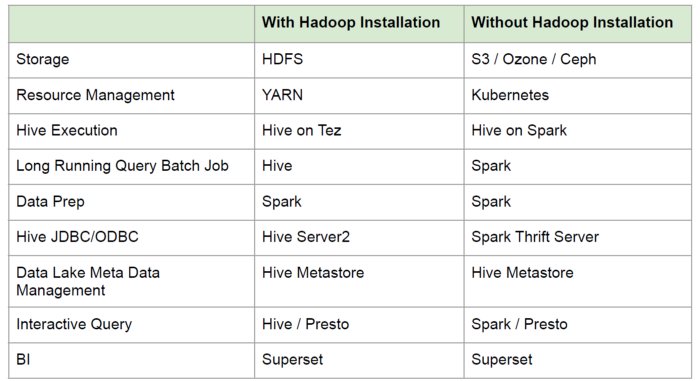
图片来源:Cloud Native Data Platform without Hadoop Installation
以前,传统Hadoop的方式,在Lambda架构中所有的应用都在各自的主机上运行。
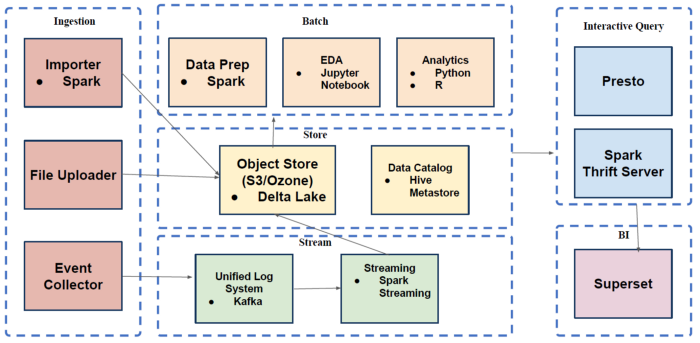
图片来源:Big Data without Hadoop/HDFS? MinIO tested on Jupyter + PySpark
现在,可以把所有的数据处理放在云上。
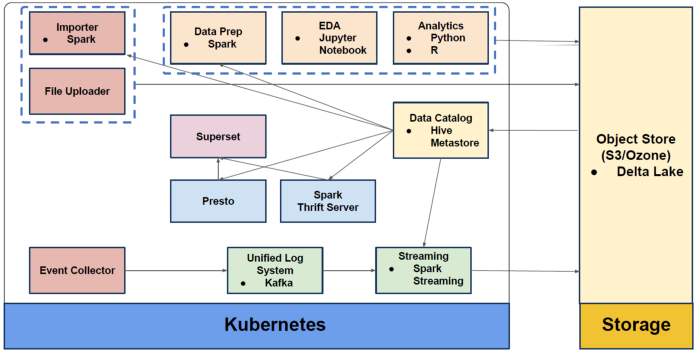
甚至可以把整个存储放在Kubernetes上。
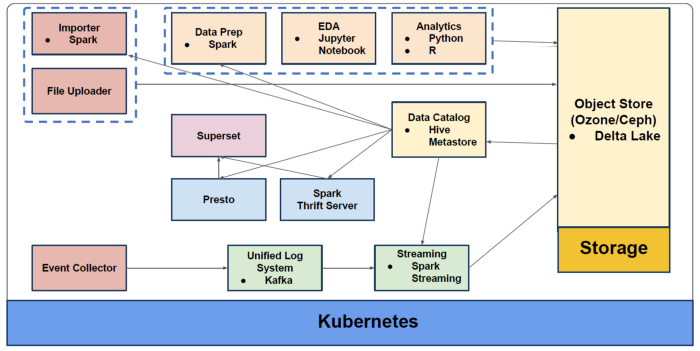
综上所述,我们看到,Hadoop的去除,使得应用在容器化中运行,能够让管理更加方便,从而大大减少工作的复杂度,全面的让大数据平台,享受云原生的好处,因此,这必定是未来的趋势。
当然,并不是只有我们意识到了Hadoop如今尴尬的问题,像这样的说法其实已经得到了初步的共识,诸如像《云原生数据平台,无需安装Hadoop》《没有Hadoop/HDFS的大数据,怎么样用Jupyter+PySpark来做MinIO测试》《构建云原生,在各个云上都可以迁移的数据湖》这样的文章,都能够窥见“去Hadoop”的趋势。
其中一篇名为《没有Hadoop的大数据》的文章,介绍“用户已经在公有云上为特定地区建立了一个完整的数据湖和分析解决方案,并希望将这个解决方案部署到另一个区,而此前的数据湖并不是云原生的,所以负责解决方案的部门通过一系列操作(如图),实现了云原生架构,才得以在不同的公有云上顺利实现该解决方案。”
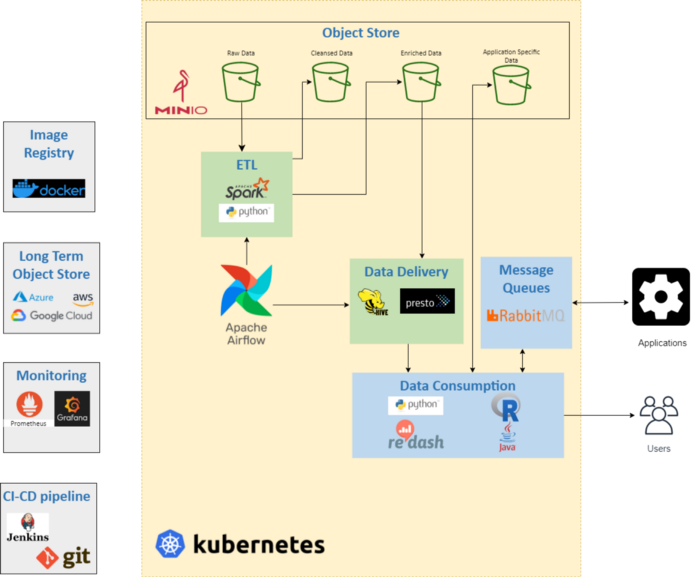
云原生的组件
原文链接:
https://towardsdatascience.com/building-a-cloud-native-cloud-agnostic-data-lake-376aa2f2aacd
云原生新思考 它为什么越来越重要?
首先,我们来看一下CNCF发布的云原生全景图,这张全景图技术之多规模之大,无疑会让人感到震惊。可见,云原生发展之迅猛,可提供的服务与选择非常多。
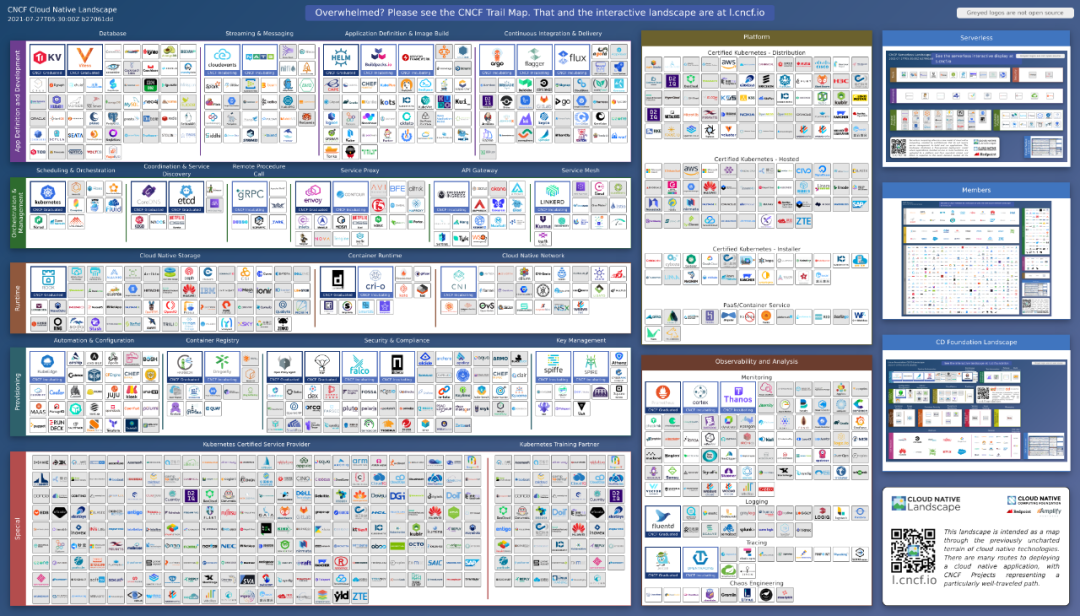
云原生技术图谱
关于这份云原生技术图谱,详细内容可以参考我们之前发布的文章《都在说云原生,它的技术图谱你真的了解吗?》。
显然,现在构建一个系统比云原生之前的时代容易多了。如果构建恰当,云原生技术将提供更强大的灵活性。在现如今快速变化的技术生态中,这可能是最重要的能力之一。
接下来,我们要讲的重点是云原生的要点之一DevOps,作为是一个合成词,DevOps由开发(Developments)和运维(Operations)两个单词组成,其主要目的是拆断不同部门之间隔离的墙。简而言之,DevOps可以让公司的流程更快、更有效,并且更可靠。
那么,DevOps的平台功能,是作为容器调度平台完全基于编排和部署,并且能够将云原生应用的生命周期进行抽象,可以替换存储、CRI等,甚至发布流程都可以用不同的策略来管理;以代码形式部署集群;开放接口CRI、CNI、CSI的插件架构。
这就是DevOps的核心价值,在此基础上还提供了一些常用服务,例如:负载均衡、存储编排、自动部署和回滚、混排、容错、机密和配置管理……
K8s将整个分布式集群的发布变成云原生,发布到一个分布式集群,用K8s一整套的YAML描述出来就可以在一个集群上发布,也可以在另一个集群上发布。
DataOps与DevOps十分形似,也有着与DevOps类似的软件开发角色,它是数据工程师简化数据使用、实现以数据驱动企业的方法,也是企业顺利实现第三阶段的关键。
那么,我们的思考是DataOps是否也可以这样做?
将DevOps变量替换到DataOps,我们看DataOps的核心价值主要是基于容器的部署和编排、生命周期的抽象、DSL——作为代码的管理部署、支持不同分析工作负载的插件架构。以及常用服务调度、元数据、数据质量、访问控制、版本控制、自动部署和回滚、日志/审计……
简而言之,DataOps遵循类似于 DevOps 的方法:从编写代码到生产部署的路径(包括调度和监控)应由同一个人完成,并遵循系统管理的标准。与提供许多标准 CI、部署、监控工具以实现快速交付的 DevOps 类似,通过标准化大量大数据组件,新手可以快速建立生产级的大数据应用并充分利用数据的价值。(关于DataOps的详细内容,可以参考我们之前发布的文章《一文读懂DataOps》。)
从Hadoop的气数已尽到云原生的风光正好,看起来是说新技术的快速迭代,但实际上对于Hadoop这样的分布式系统的深入理解其实也是精通云原生架构大数据体系的基础。总之,我们要避免的是固守就有技术,以为“一招鲜吃遍天”,而是要从架构、体系上,充分理解自己的工作内容,并不断巩固算法、架构、测试、工程管理与沟通等基础知识技能体系。
最重要的是,要时刻保持学习和提高的心态。如果这样,程序员完全不会存在35岁危机,而会在这个黄金年龄迎来自己的收入巅峰。如今,云原生与数字化的转型大潮才刚刚开始,我们希望所有的程序员都能够抓住机会,深耕专业技术能力实现人生价值。


往期推荐

点分享

点收藏

点点赞

点在看

