
- 1python之串口编程_python串口编程
- 2c语言环境搭建(vs)2022版_vs搭建c语言环境
- 3Imagination支持Google的Android GPU Inspector
- 4uniapp+vue3+vites使用lime-echart问题记录
- 5springboot259交通管理在线服务系统的开发
- 6Intel C++ Compiler 关于Warning, error的处理
- 7C语言的for循环中i++和++i的关系_c语言for循环中i++和++i
- 8【Kotlin】Kotlin环境搭建_org.jetbrains.kotlin:kotlin-bom:1.9.22
- 9r语言:空间面板Moran 指数计算_r语言分析不同试验点之间的空间自相关性,计算moran's 指数
- 10Android https网络编程协议 双向验证 报文 请求体 响应头(自定义okhttp框架)_安卓请求头通用
关于 MySQL insert 和自增 ID 的奇怪事件_mysql自增id,插入报错id有时自增有时不自增
赞
踩
你好,我是yes。
上周五,我的微信星球用户向我提了个问题,这个问题既熟悉又生僻,还是挺有意思的,所以我在这里分享一下。
首先有建立一张表
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
- 1
- 2
- 3
- 4
- 5
- 6
表没什么花头,主键是 ID,然后是自增的。
此时执行一条插入语句:
insert into t (id,c,d) values (1,1,1),(null,2,2),(7,7,7),(null,4,4);
- 1
语句中既有指定的 ID,又有让 MySQL 自己计算的自增 ID。
然后此时,再执行一条sql
insert into t (id,c,d) values (null,9,9);
- 1
你觉得这条插入的 ID 应该是几?
你肯定以为是 9 ,实际上这条新纪录的 ID 是 10。
乍一看,不对啊,第一条插入语句的最后一个记录是 (null,4,4),它的 ID 是 8 ,那为什么紧接着的后面一个插入自增 ID 直接变到了 10 而不是 9 ?
为什么中间空了一个 ID?
讲实话,我也不知道,于是我去官网寻寻觅觅,果然皇天不负有心人,嘻嘻。

这种一条语句里面,即包含指定 ID 又有自增 ID 的叫做Mixed-mode inserts。
然后关于自增 ID 的模式,又分为三种,我在之前的文章分析过:

所以默认值是 1。
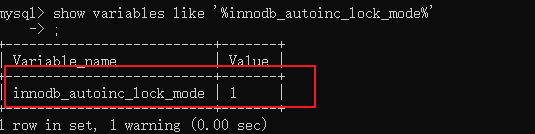
然后默认值是 1 再加上这次的插入是Mixed-mode inserts,就发生了点火花。

简单的来了个机翻:
例外情况是“混合模式插入”,其中用户为多行“简单插入”中的某些(但不是全部)行提供 AUTO_INCREMENT 列的显式值。 对于此类插入,InnoDB 分配的自动增量值多于要插入的行数。 但是,所有自动分配的值都是连续生成的(因此高于)由最近执行的前一条语句生成的自动增量值。 “多余”的数字丢失。
好了,破案了,官网上已经写的很清楚了,这样的插入在innodb_autoinc_lock_mode = 1的情况下,InnoDB 就是会分配多余插入行数的 ID 数,而多出来的 ID 就被丢弃了。
所以后面的插入看起来就和前面断掉了,搞得像一部分 ID 莫名其妙被吃了一样。
那为什么会 InnoDB 要这样实现呢?
如果想具体知道这个问题,那肯定得看源码了,那成本就太大了。
我盲猜猜,你一条插入里面即自己设定了 ID,又让 InnoDB 计算自增 ID,在代码实现上估计有点难度,想要做到完美的自增 ID 序列估计成本有点大。
简单来说就是得不偿失,自增 ID 这么多,少一两个不要紧,所以就简单实现,一次多准备点,这样插入就不会出错啦~
好了,官网链接:https://dev.mysql.com/doc/refman/8.0/en/innodb-auto-increment-handling.html
这次短平快到此结束。
我是yes,从一点点到亿点点,我们下篇见。


