
- 1【NLP】Python NLTK结合Stanford NLP工具包进行分词、词性标注、句法分析
- 2软件与硬件的区别?(逻辑,材料,开发,零售,维修,报废,成本)_即征即退软件与硬件的成本对比
- 3L1、L2正则regularization和weight decay_regularizers.l2_regularize
- 4【MyBatis-Plus问题集】当我们使用MyBatis-Plus版本3.5.x时,会发现一直无法注册xxxMapper_type com.baomidou.mybatisplus.extension.ddl.iddl n
- 5上层算法开发和服务标准化和普适化建设,三步实现AI工程化_算法产品标准化
- 6NLP —— 文本预处理_nlp文本预处理
- 7paddlepaddle测试安装_「深度学习系列」PaddlePaddle之手写数字识别
- 8【Linux】CUDA Toolkit和cuDNN版本对应关系(更新至2022年6月,附官网永久更新链接)_cuda12.0对应cudnn
- 9第七行:如何使用Python进行自然语言处理(NLP)?_python nlp
- 10基于TextCNN实现情感分析任务_sentencepiece用textcnn模型情感分析
一文综述:自然语言处理技术NLP_nlp综述
赞
踩
自然语言处理技术综述1-到2020年
写在最前面
参考:
Review of Natural Language Processing in Radiology
放射学中的自然语言处理技术综述
https://pubmed.ncbi.nlm.nih.gov/33038995/
由于论文比较老,只总结、翻译感兴趣的部分
本文介绍了现代自然语言处理技术的关键组成部分。
综述了NLP中常用的标记化等预处理技术、机器学习、深度学习
其他与放射学相关的部分,放于下篇文章中学习分享。
摘要
自然语言处理(NLP)可以改善临床工作流程,并解锁放射学和临床报告中包含的非结构化文本信息,以开发放射学和临床人工智能应用。
本文介绍了现代自然语言处理技术的关键组成部分。综述了常用的标记化和标记化等预处理技术。本文介绍了使用单词嵌入作为抽象工具的意义,并探讨了经典的机器学习技术和深度学习在NLP任务中的使用。此外,它还讨论了NLP的临床应用,并为其在放射学中的应用提供了未来的方向。
NLP简介
NLP的目的是使机器能够为达到有意义的目的而读取和理解人类语言。
任何自然语言应用程序都会出现某些共同的模式。大致上有
(1)预处理阶段,可以使用经典或单词嵌入方法将原始数据转换为适合机器学习的格式;
(2)模型训练,可以使用经典的机器学习或深度学习方法,用于语言理解或生成的广泛任务类别。
Preprocessing预处理
预处理将原始文本转换为可用于训练语言模型的格式通常需要许多预处理步骤。
在NLP术语中,单个放射学报告、单个医疗图表或任何其他原始文本文件通常被称为文档,而文档的集合,如放射学报告的集合,被称为语料库。
与计算机视觉和成像工作流类似,许多NLP工作流依赖于一组常见的预处理任务,将原始数据转换为适合于模型训练和机器学习的格式。
Tokenization令牌化、标记化
标记化定义为将单词转换为索引格式。
字符串中的单个单词将被转换为带有索引的令牌。最后一个向量化的字符串以数字表示原始字符串,用标记化的数字表示每个单词。
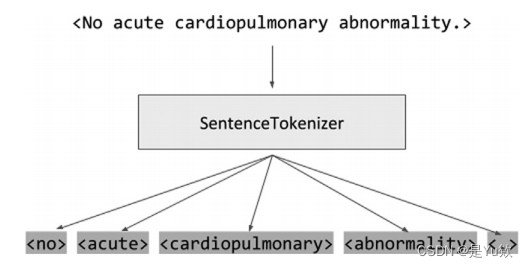
所述索引可以从一个预定义的词汇表(例如,所有英语单词的列表),或者,更典型的是,从一个已定义的语料库中的所有单词。
在通常的实践中,该索引格式存储在一个向量中,其中该单位对应于索引位置。
标记化或向量化的语言实现多个目标,
在实际层面上,压缩成浓缩表示节省计算内存和处理能力。
在语言层面上,也帮助词汇的概念抽象,结合密切相关的关键词或消除歧义词,可以有多种意义。
Stop Words 停用词
通常,特别是在处理非结构化的原始全文时,某些小词会被故意省略,而不是标记化。这些被排除在外的单词,这个概念被称为停止词,指的是可能不会对期望的任务提供重要信息的特别常见的单词,如“the”、“a”、“is”和“on”。
通过消除这些词,可以
1、节省空间,
2、加速后续的模型训练。
3、在许多情况下,由于删除允许模型忽略不相关的词汇表,模型性能也会提高。
对于某些任务,错误地选择停用词可能会消除文档中有价值的上下文信息,特别是否定(例如,“不”,“不是”)和关键字的高频率并不一定意味着缺乏效用。
此外,在标记化过程中,可能会有意地忽略大写或其他形式的字符表示和语言上的微小差异,从而提高模型性能。
Stemming and Lemmatization词干提取和词形还原(英文单词)
考虑到关键字的多样性,偶尔会执行一个额外的预处理步骤,称为词干提取和词形还原。
进行时变成一般时
“walking” and “talking” and “radiologically”
would be reduced to “walk,”“talk,” and “radiology.”
词干提取。词元化不同从根源上讲,它试图减少适当的引理(即一个基本词可以在字典中找到),因此需要适当的上下文和语义意义,在这个过程中执行降维或抽象一个词高级的概念。
词性还原是一种更严格的技术,可以执行复杂的、非直观的抽象
两个概念相关,但拼写不同,几乎没有共同的字符。
将“更好”简化为“好”
相比之下,纯粹通过模式匹配来引导函数,粗略地截断了的末端
根据预先确定的规则集使用的单词
removing “-ing” from verbs “talking” to “talk”
偶尔,这可能会导致被称为过度停止或停止不足的错误。
由于过度引导,
universal,” “university,” and “universe” to “univers-,”
一个词柄可能会把“通用”、“大学”和“宇宙”变成“统一”
无意中把3个词组合到一个词干概念,尽管3个原始词是多么不相关。
虽然词干提取可以忽略词形还原的边缘情况,但它比词形还原快得多,因此更常用。
Parts-of-Speech Tagging词性标记
词性(POS)是指每个单词在一个句子中所具有的语法功能。
名词、代词、形容词、动词、介词、连词和感叹词都被认为是词性类。
对句子中单个词性的识别被称为词性标记。鉴于同一个词在不同的上下文中可以有不同的含义,词性标记可以提取额外的显著信息,不是直接从词本身,而是从句子中的关系。
例如,“给我你的答案”中的“答案”是一个名词,而在句子“回答问题”中,“回答”是一个动词。
the word “answer”in “Give me your answer” is a noun, whereas, in
the sentence “Answer the question,” the word “answer” is a verb.
- 1
- 2
- 3
- 4
因此,POS标签可以是消除单词义歧义的第一步,歧义是指在给定上下文的同一单词区分不同含义的行为。
Bag of Words and N-Grams词袋模型、N元模型
单词袋的概念只是简单地指将文本表示为其组成词的无序集合。
这种方法简化了存储,因为上下文和语法被忽略了,但保留了单词的频率。
如果常见的停止词被删除,缺乏单词上下文是有问题的,特别是在处理大型文档或句子结构时。
if a document’s text is “the apple is a red apple,”
a bag-of-words model would represent it as [“apple”, “apple”, “the”, “is”, “a”],
or, if common stop words are removed, [“apple”, “apple”].
- 1
- 2
- 3
- 4
- 5
N-gram模型可以帮助保存更多的上下文信息,尽管在实践中,很少使用比3-gram更多的表示。
Under a bigram model,
the preceding document would be stored as [(the, apple), (apple, is), (is,a), (a, red), (red, apple)].
- 1
- 2
- 3
Term Frequency–Inverse Document Frequency(TF-IDF)
术语频率(词频)-逆文档频率[TF-IDF]是一种数字统计数据,旨在对一个单词在给定文档中的重要性进行排序。
术语频率和逆文档频率有助于理解这一分数。
术语频率是一个更直观的概念,它衡量的是给定文档中一个单词的频率。虽然这提供了一定程度的比例,更频繁的关键词具有较高的相关性得分,但这会容易允许非常频繁但不重要的单词(例如,“the”,“和”)显得过于相关。
逆文档频率度量了一个给定语料库中至少包含一次术语的文档数量,这允许降低几乎所有文档中出现的通用术语的权重。
通过将词频与逆文档频率相乘,得到TF-IDF得分。
一个高TF-IDF的术语经常出现在单个文档中(例如,大脑报告中的蛛网膜下腔),但不经常出现在语料库中的所有文档中(例如,所有放射学报告)。
TF-IDF不仅在搜索查询和文档中是一个重要的概念,在NLP机器学习和AI模型中也是如此,因为使用TF-IDF值可以提供文档或语料库中给定关键字的相对权重和重要性。
Negation Detection否定检测
否定检测是指识别暗示负面情绪的线索(例如,“没有证据”,“不再看到”,“已经解决”),在patient cohorting(患者队列?)方面发挥特别重要的作用,特别是在研究和质量保证工作流程方面。
虽然可以通过关键字匹配来确定发现和疾病,但区分报告中是否存在疾病需要准确的否定检测。由于表达否定句子的方式多种多样,这本身可能是一项具有挑战性的任务。
非常早期的基于规则的尝试来执行这个任务,最显著的是一个名为NegEx的正则表达式算法在生物医学文档中显示了早期的成功,但很快就遇到了由于未能考虑关键字概念和否定词之间的依赖关系而造成的错误阳性的限制。
试图提高数据的准确性,例如通过系统解析语法树进行词性标签和语法分析。
WORD EMBEDDINGS文本嵌入
虽然简单的单词标记化能将每个单词单独映射到作为一个一维数组或向量的一个索引,但这些标记化方法忽略了类似单词之间的上下文。
一个根据字母位置为一个单词分配一个数字索引的模型
可能会使“国王”和“王后”或“男人”和“女人”相距很远,
但这些术语与更高层次的概念(即“皇家头衔”、“性别”)密切相关。
可以生成模型来将一组单词或短语映射到数值的向量上,并将单词的高维性降低为已学习的低维表示。
在推导嵌入的过程中,推导出的向量有时可以推导出基本概念和语言结构;
例如,如图所示,性别和标题之间的关系。
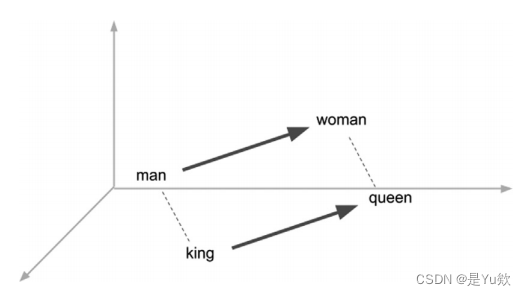
文本嵌入不像标记化那样简单地将单词翻译成机器可读的格式,而是试图捕获词汇表中固有的语义和上下文信息。
通过将单词编码到向量中,其中距离和方向度量它的语义关系,而不是任意的,可以对这些术语执行向量操作,从而允许模型理解一个词相对于另一个词的相对含义。
该模型能获得对单词的适当的语义理解,从而获得了同义词、类比和修饰词的数学表示。
通常,文本嵌入的使用会导致模型性能的显著改善。
Word2vec
最常见的单词嵌入模型之一是Word2vec,2013年谷歌发表。 Word2vec,使用一个浅层的三层神经网络,
试图预测给定中心单词的任何给定单词的上下文(跳过gram),
或者预测给定一系列上下文单词(连续的单词袋)的中心单词。
例如,像“出血”这样的词可以出现在“蛛网膜下腔出血”、“实质内出血”或“脑室内出血”的背景下。
因此,“蛛网膜下腔”、“实质内”和“脑室内”将被归为同一类。
因为这三个单词经常与“出血”一起出现,所以在向量空间中彼此接近。words such as “hemorrhage” can occur either in the context of “subarachnoid hemorrhage,” “intraparenchymal hemorrhage,” or “intraventricular hemorrhage.”
Thus, the words “subarachnoid,” “intraparenchymal,” and “intraventricular” would be classified into the same category,
and thus be close to one another in the vector space
因此,接近这3个词的其他词也可能指神经解剖学的其他层次。
GloVe
Word2vec使用基于预测神经网络的模型生成嵌入,GloVe则直接使用给定语料库中所有单词的共现矩阵,按照降维技术生成单个单词嵌入。
在实践中,GloVe嵌入通常比Word2vec更容易获得,并且在类比等语义关联任务上表现得更好,但它们通常需要更多的内存来存储。
然而,如果嵌入来自于一个小的语料库,那么Word2vec和GloVe方法都不能很好地处理词汇表外的单词(未登录词)。
出于性能和泛化能力的原因,现成的嵌入模型通常在维基百科等大型公开文本语料库上进行训练。近年来,人们尝试用一个来自自由文本报告的语料库来训练放射学特定的单词嵌入,例如智能文本嵌入计划,它使用了一个Word2衍生的模型【1】。
基于规则和经典的机器学习技术
Regular Expressions正则表达式
正则表达式,又称regex或regexp,是一个定义搜索模式的字符序列,通常用于搜索和匹配在字符串中找到的模式。
许多定义良好的NLP任务都惊人地由最小的正则表达式实现,特别是在词汇表定义良好且表达式变化很少的情况下。最高度引用的否定检测算法之一,NegEx,使用正则表达式来检测一个详尽的负面阶段
从[不,没有,没有,排除]
更先进的短语如[没有迹象,没有演示,没有证据表明)
结合灵活的词接近占多个短语变化的短语(例如,“{没有}{肺栓塞}”,“{没有}{肺embolus}的证据)from [no, not, without, ruled out]
to more advanced phrases such as [no sign of, not demonstrate, no evidence of]
with incorporation offlexible word proximity to account for multiple phrase variations of phrases (eg, “{No} {pulmonary embolus},” “{No}evidence of {pulmonary embolus}).
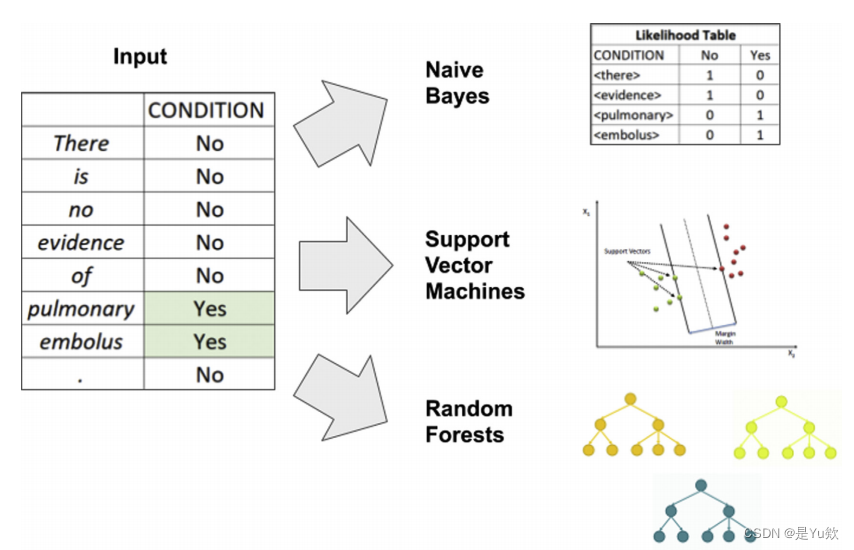
Naive Bayes, Support Vector Machines, and Random Forests朴素贝叶斯、支持向量机和随机森林
利用标记化和向量化预处理可以对文档进行数值分析。
一旦转换为一个数字向量,机器学习模型的训练易于统计和机器学习建模,与模型学习输入向量和期望输出之间的关联。
这种分析模型在考虑涉及文档分类或情绪分析的任务时效果最好,也可以扩展到其他更高级的任务,如词性标记和命名实体识别。
经典的自然语言处理机器学习技术 依赖于训练监督学习模型来生成给定输入向量的分类,从关键词、词性的二值朴素贝叶斯分类器到更复杂的模型。
涉及大维输入向量来支持向量机,或随机森林。
通过将相对词N-gram频率与朴素贝叶斯、随机森林决策规则或输入向量化字符串上的支持向量机分离超平面相结合,可以进行分类以支持所需的NLP任务。
深度学习
深度学习指的是更现代的机器学习,能够更好地利用大量的原始、结构化和非结构化数据获得更高层次的信息表示,通过使用神经网络更大的层和参数空间比以前认为可训练的,并利用新的训练方法来允许成功的模型生成。
在实践中,几乎所有的深度学习模型现在都是使用神经网络实现的,神经网络是一种由相互连接的节点或神经元组成的结构,灵感来自人类神经元结构,但不同。
本期的另一篇文章提供了对深度学习的详细回顾,但这里提供了简要的概述。(后期可以再看看)
Convolutional Neural Networks卷积神经网络
在计算机视觉和医学成像中一个特别成功的架构是卷积神经网络(CNN)。
cnn,也被称为凸面网络,是一种依赖于被称为卷积的数学运算的神经网络。
卷积是指对中心输入点周围的连续数量的点应用滤波器。
在成像的情况下,卷积可以用于锐化或模糊一个特定的(如5×5)窗口周围的二维输入(图像)。
一个CNN将多个卷积节点或神经元集成到一个神经网络中,是在各种图像分类和目标检测任务上负责突破性性能的架构。
输入数组使用内核卷积到更高级别的输出数组。
通过多层卷积,输入信息越来越抽象为期望的结果。
虽然在视觉上被描述为一个二维数组,但这是任意的,卷积可以发生在1维或更高的任意N维上。
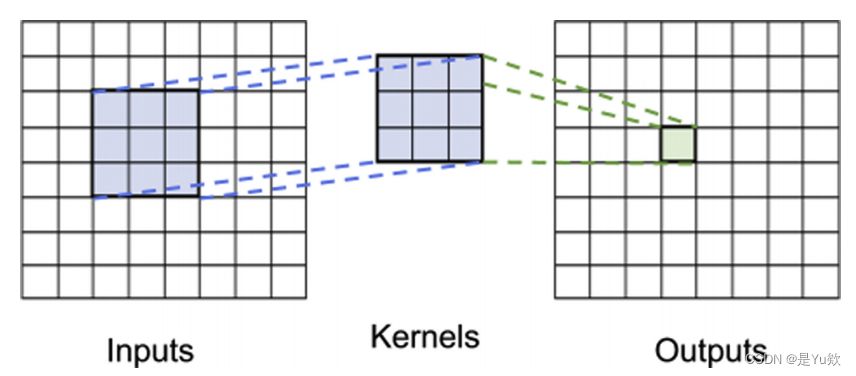
虽然cnn在成像方面取得了巨大的成功,但它可能不是立即直观的,但文本处理也可以从卷积方法中获益。
与词袋方法将文档编码为文档单词的总和相比,文本的CNN方法将输入视为向量,从而围绕中心单词应用卷积运算。
该模型能够学习任何给定单词的局部上下文,这取决于过滤器的大小:一个长度为7的过滤器将在和之前学习一个带有3个相邻单词的单词,类似于在成像中,一个7×7的滤波器将在图像上的7×7像素区域上进行训练。
例如,在一个积极的诊断情绪分类任务中。
CNN对上下文转换一个输入句子的建模,通过一系列的卷积操作,输出2个输出类。
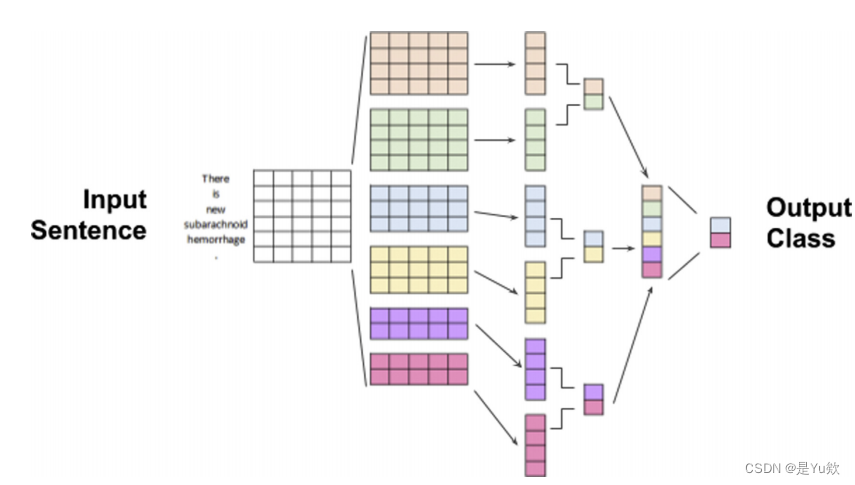
因此,CNN的NLP方法可以理解为,
给定句子中任何单词的局部上下文。
通过二阶卷积(如段落级、句子级)
堆叠在一阶(如单词级)卷积上
等等
模型可以覆盖文档中越来越大的部分,直到它被完全覆盖。
CNN中单词的层次表示允许模型获得对任何给定文档的全局理解。
在实践中,结合单词嵌入技术,如Word2vec,cnn在各种NLP任务中获得了良好的性能,特别是在文档分类任务中。
Recurrent Neural Networks(RNN)
另一种流行的神经网络结构类型是递归神经网络(RNN)。
在传统的网络体系结构中,包括cnn,当前的输入独立于过去的输入或输出。
rnn是一种特殊的网络神经网络的一种形式,除了当前步骤的输入外,上一个步骤的输出还作为当前步骤的输入。
这种体系结构明确地允许对序列类结构进行建模,例如文本或时间序列数据。
因此,虽然cnn只能处理单个数据点,如图像或完整的文档,
但rnn可以处理数据序列,如句子或来自生物硬件传感器的数据流。与整个文档相比,基于RNN的模型可以更自然地处理句子中的单个单词。
Long Short-Term Memory(LSTM)
由于其健壮性,一个性能特别好的RNN体系结构 是一个长短期记忆神经网络(LSTM)。
由于神经网络的训练方式,传统的rnn通常在长序列中表现不佳,“忘记”在句子或段落开头的上下文,即梯度消失问题。
LSTM是一种RNN体系结构,它被设计用于建模时间或顺序的依赖关系,使其与NLP中的使用高度相关。它的主要优点是能够使用记忆单元 使用先前状态的信息来告知当前状态预测,使这种网络设计能够捕获长期的语言依赖关系。
lstm通过添加3个门来调节先前输入的权重:一个更新门、一个输出门和一个遗忘门(图7)。
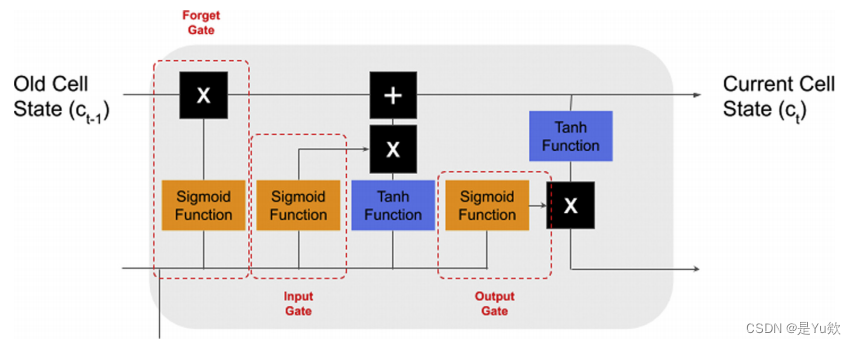 当在NLP中用于基于文本的应用程序时,单词级LSTM模型的性能往往略优于基于cnn的文档级模型。
当在NLP中用于基于文本的应用程序时,单词级LSTM模型的性能往往略优于基于cnn的文档级模型。
此外,LSTM模型的循环架构允许可变长度的输出,而不是CNN模型必须将文档的句子填充到一个固定的输入大小。
因此,LSTM模型可以用于文本分类和文本生成,
而cnn的固定输出,通常只执行分类。
然而,循环模型的一个主要缺点是,它们比CNN模型更难训练,计算资源更密集,并行性也更低。LSTM模型通常会减慢至少1到2个数量级。
Semisupervised, Transfer Learning, and Transformer Based Natural Language Processing Approaches基于半监督、迁移学习和基于转换器的自然语言处理方法
自2018年以来,NLP技术已经进行了重大的创新substantial innovation,通过开发那些已被证明对基于图像的任务的性能至关重要的想法。
从ULMFiT开始【2】,与领先的人工智能实验室如谷歌(BERT【3】,Transformer【4】,XLNet【5】),华盛顿大学(ELMo)【6】,Facebook(RoBERTa【7】,XLM【8】),和OpenAI(GPT)【9】,几乎所有现代先进的NLP模型使用预训练的文本组件,显著增加网络参数空间,以实现不断增长的常见NLP任务,如情感分类和命名实体识别。
这种训练通常是半监督或无监督,
即少标注任务:最小预处理和很少的注释或标签执行这些文本组件,任务是不可克服的手动或基于规则的技术语料库大小和复杂性
通常利用数据集,如来自高质量维基百科文章的WikiText-103,以及专有的预训练文本数据集,
然后应用于完全监督的任务时,有时可能需要少100倍的标记示例来达到类似的性能。
这一点对放射学和生物医学应用特别感兴趣,因为完成标记所需的显著多样性和困难。
参考文献
【1】Banerjee I , Ph. D , Madhavan S , et al. Intelligent Word Embeddings of Free-Text Radiology Reports[J]. AMIA. Annual Symposium proceedings / AMIA Symposium. AMIA Symposium, 2017, 2017.
【2】Howard J , Ruder S . Universal Language Model Fine-tuning for Text Classification[J]. 2018.
【3】Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
【4】Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.
【5】You Y , Li J , Hseu J , et al. Reducing BERT Pre-Training Time from 3 Days to 76 Minutes[J]. 2019.
【6】Peters M , Neumann M , Iyyer M , et al. Deep Contextualized Word Representations[J]. 2018.
【7】Liu Y , Ott M , Goyal N , et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach[J]. 2019.
【8】Lample G , Conneau A . Cross-lingual Language Model Pretraining[J]. 2019.
【9】Radford A . Language Models are Unsupervised Multitask Learners.

