
- 1python实现onnx模型推理_onnx推理代码
- 2基于SpringBoot+Vue+uniapp微信小程序的微信阅读小程序的详细设计和实现_springboot vue 小程序
- 33.6k star, 免费开源跨平台的数据库管理工具 dbgate_数据库管理工具 开源
- 4从Github上下载文件的方法汇总_github如何下载文件
- 5【计算机毕业设计】基于ssm的宠物医院管理系统的设计与实现
- 6maven jar包瘦身
- 7构建文本数据集(tokenize、vocab)_数据集:英文小说time machine
- 8解码自然语言处理之 Transformers
- 9基于DataX迁移MySQL到OceanBase集群_datax mysql 同步到oceanbean
- 10ros打开笔记本电脑的摄像头_roslaunch usb_cam-test.launch
前沿 | 使用Transformers进行端到端目标识别
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者:Nicolas Carion、Francisco Massa、Gabriel Synnaeve 等
论文链接:https://arxiv.org/pdf/2005.12872v1.pdf
摘要:近年来,Transformer 成为了深度学习领域非常受欢迎的一种架构,它依赖于一种简单但却十分强大的机制——注意力机制,使得 AI 模型有选择地聚焦于输入的某些部分,因此推理更加高效。Transformer 已经广泛应用于序列数据的处理,尤其是在语言建模、机器翻译等自然语言处理领域。此外,它在语音识别、符号数学、强化学习等多个领域也有应用。但令人意外的是,计算机视觉领域一直还未被 Transformer 所席卷。
为了填补这一空白,Facebook AI 的研究者推出了 Transformer 的视觉版本—Detection Transformer(以下简称 DETR),用于目标检测和全景分割。与之前的目标检测系统相比,DETR 的架构进行了根本上的改变。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。在性能上,DETR 可以媲美当前的 SOTA 方法,但架构得到了极大简化。
具体来说,研究者在 COCO 目标检测数据集上将 DETR 与 Faster R-CNN 基线方法进行了对比,结果发现 DETR 在大型目标上的检测性能要优于 Faster R-CNN,但在小目标的检测上性能不如后者,这为今后 DETR 的改进提供了新的方向。
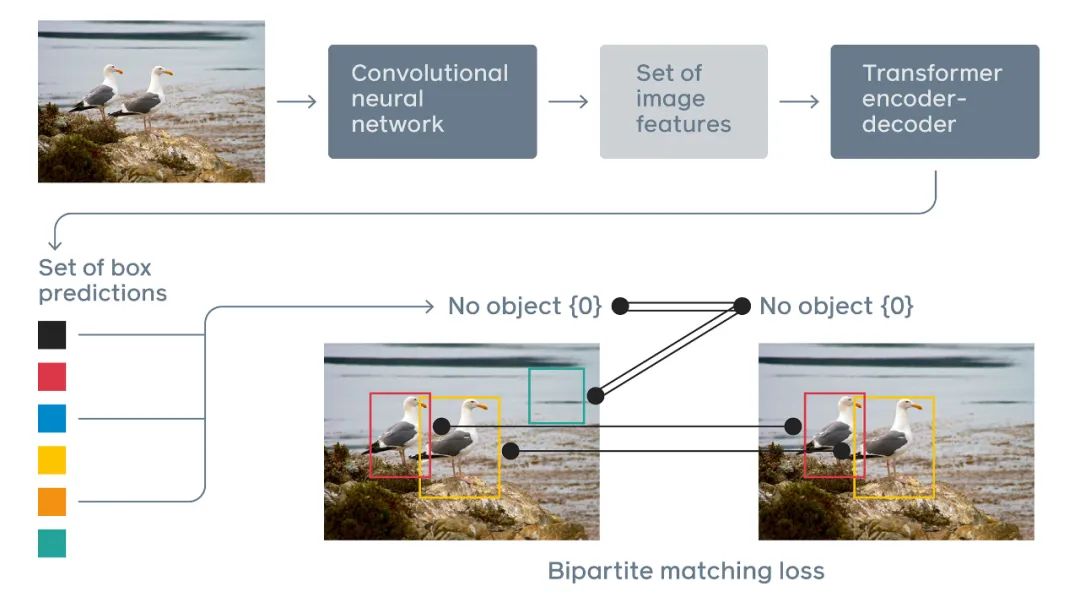
DETR 通过将一个常见 CNN 与 Transformer 结合来直接预测最终的检测结果。在训练期间,二分匹配(bipartite matching)向预测结果分配唯一的 ground truth 边界框。没有匹配的预测应生成一个「无目标」的分类预测结果。
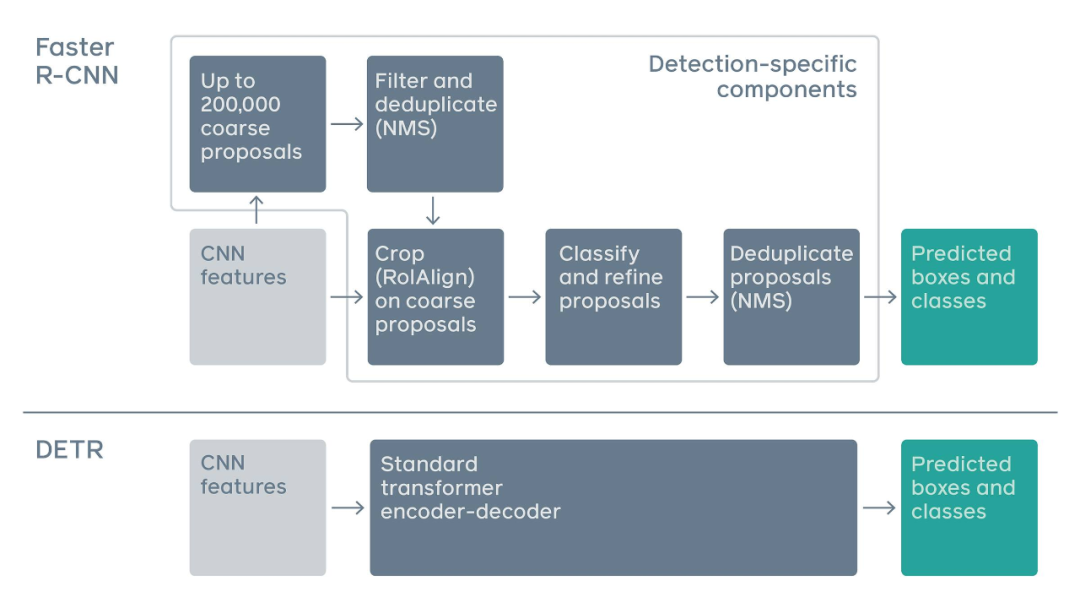
传统两阶段检测系统,如 Faster R-CNN,通过对大量粗糙候选区域的过滤来预测目标边界框。与之相比,DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。
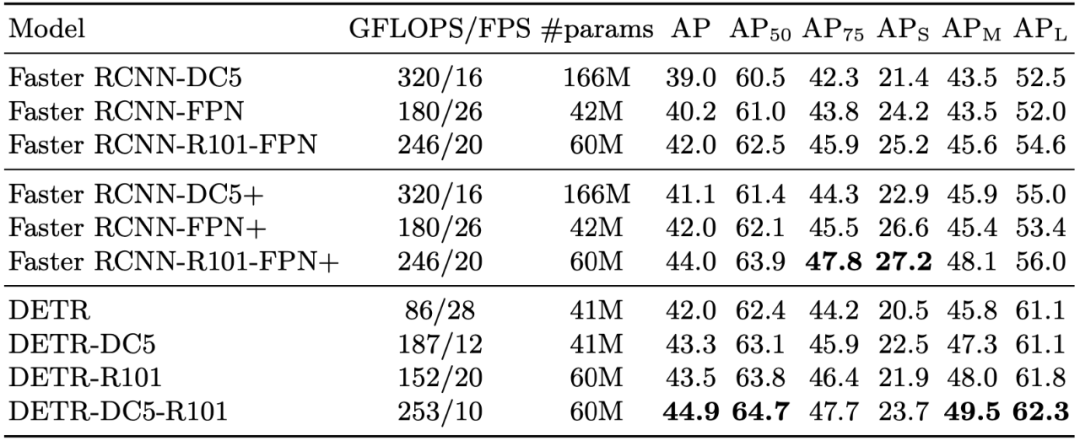
在 COCO 验证集上与 Faster R-CNN 的对比结果。
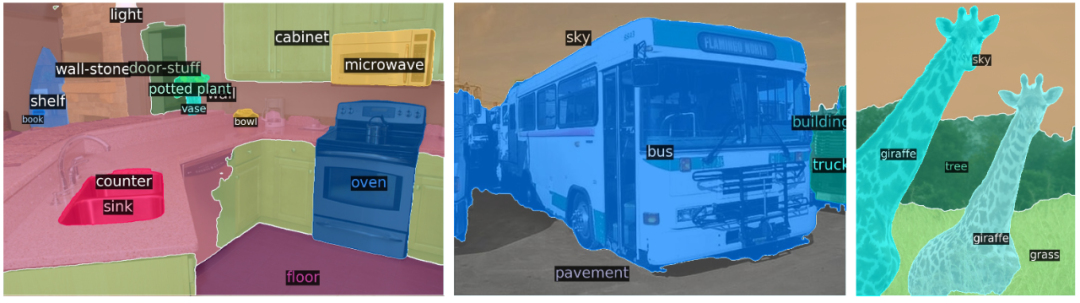
DETR-R101 处理的全景分割效果。
好消息!
小白学视觉知识星球
开始面向外开放啦
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

