
- 1快速上手Spring Cloud 九:服务间通信与消息队列
- 2linux下golang开发环境配置+liteidex+第三方库的下载和引用_go linux下,怎么根据go.mod下载第3方库
- 3Python自动抓取网页新闻,轻松实现!_python爬取新闻网站内容
- 4回溯算法设计(2):回溯法解决0/1背包问题_0/1背包回溯法算法设计
- 5升级鸿蒙谷歌框架下载,网友Mate 40 Pro+升级鸿蒙2.0:谷歌服务不受影响
- 6Swin-Transformer网络结构详解_swin transformer
- 7DragGAN:简介,安装,使用!
- 8【工作中问题解决实践 三】深入理解RBAC权限模型_rbac1模型
- 9基于差影法实现基于图像的人体姿态行为识别(附带MATLAB代码)_matlab差影法代码
- 10Ubuntu中使用Nginx将静态网页部署到云服务器_网页如何发布到ubuntu服务器上
用于序列建模的深度学习:序列到序列模型简介_深度学习中的序列化建模技术,和机器翻译机制
赞
踩
概述
谷歌首先发布了用于机器翻译的序列到序列模型。在此之前,翻译以一种极其无知的方式运作。它会自动翻译成预期的语言,而不考虑您输入的每个单词的语法或句子结构。序列到序列模型使用深度学习来转换翻译过程。翻译时,它会考虑当前单词或输入及其周围环境。
它被用于许多应用程序,包括文本摘要、对话建模和图像字幕。
序列到序列模型简介
RNN 的多对多架构是序列到序列模型 (seq2seq) 使用的架构。它能够将任意长度的输入序列转换为任意长度的输出序列,因此可用于各种应用。一些用途是语言翻译、音乐创作、语音创作和聊天机器人都包含在序列到序列模型中 概念。
在大多数情况下,输入和输出的长度不同。例如,如果我们接受翻译任务。假设我们需要将一个句子从英语转换为法语。
考虑将句子“我正在做好事”映射到“Je vais bien”。我们可以看到输入源有四个单词,但在输出中,我们只能看到三个单词。因此,该算法使用不同的输入和输出序列长度处理这些场景。
序列到序列模型的体系结构包括两个组件:
-
编码器
-
译码器
编码器学习输入句子的嵌入。嵌入是构成句子含义的向量。然后,解码器将嵌入向量作为输入,并尝试构造目标句子。
简单来说,在翻译任务中,编码器将英语句子作为输入,从中学习嵌入,并将嵌入提供给决策者。解码器使用嵌入 fed 生成目标法语句子。
序列到序列模型的用例
您每天使用的许多技术都是基于序列到序列模型的。例如,声控小工具、在线聊天机器人和谷歌翻译等服务都由序列到序列模型架构提供支持。这些应用包括:
- 机器翻译-seq2seq 模型从用户的输入中预测一个单词,然后使用第一个单词出现的可能性来预测每个后续单词。
- 视频字幕 -为了理解帧序列的时间结构和RNN生成句子的序列模型,开发了一种用于视频字幕的序列到序列模型。
- 文本摘要 -使用神经序列到序列模型,已经提供了一种有效的抽象文本摘要新方法(不限于从原始文本中选择和重新排列段落)
任何基于序列的问题都可以使用这种技术来解决,特别是当输入和输出有各种大小和分类时。
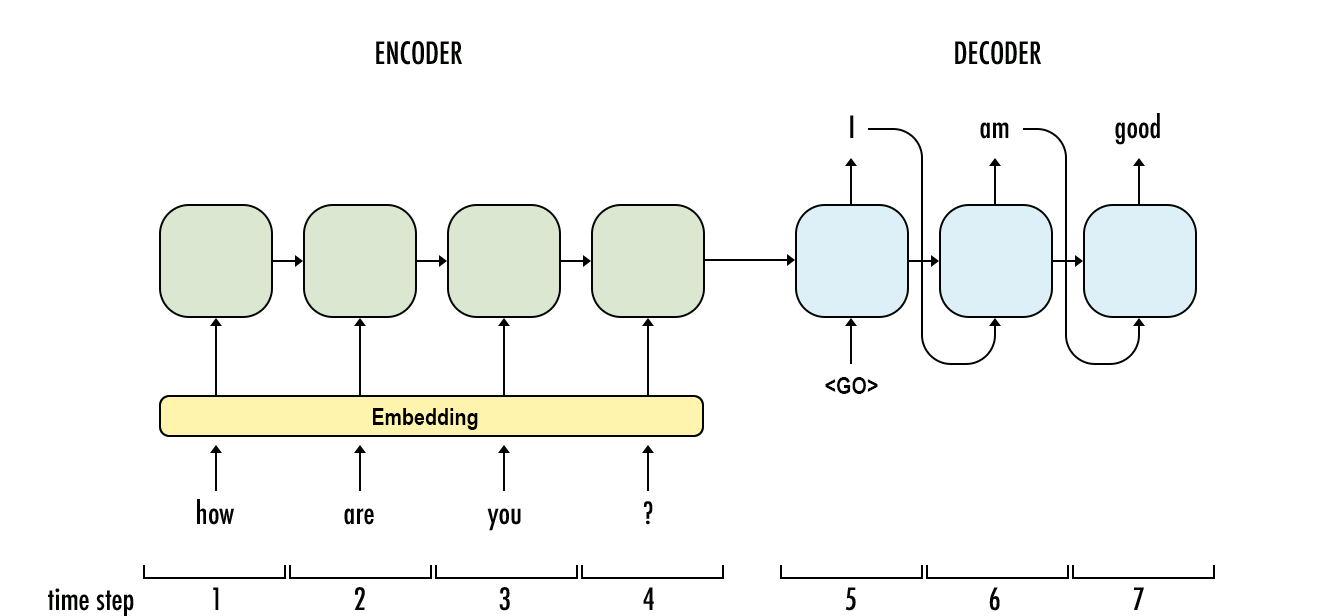
编码器-解码器架构
该模型的概述如下图所示。两者的右侧都有解码器,左侧有编码器。编码器和解码器输出组合在一起,以预测每个时间步的下一个单词。
一个序列通过序列到序列模型(序列转换)转换为另一个序列。它使用递归神经网络 (RNN) 或更常见的 LSTM 或 GRU 来克服梯度消失问题。上一阶段的输出用作每个项目的上下文。一个编码器和一个解码器网络构成了主要部分。首先,编码器将每个项目转换为相应的隐藏向量,其中包括项目及其上下文。然后,将上一个输出作为输入上下文,解码器反转该过程并生成矢量作为输出项。
-
编码器-使用深度神经网络层将输入词转换为匹配的隐藏向量。每个向量表示当前单词及其上下文。
-
译码器-若要创建以下隐藏向量并最终预测下一个单词,它使用当前单词、其隐藏状态和编码器创建的隐藏向量作为输入。除了这两者之外,还必须进行大量优化,从而产生以下额外的序列到序列模型组件。
-
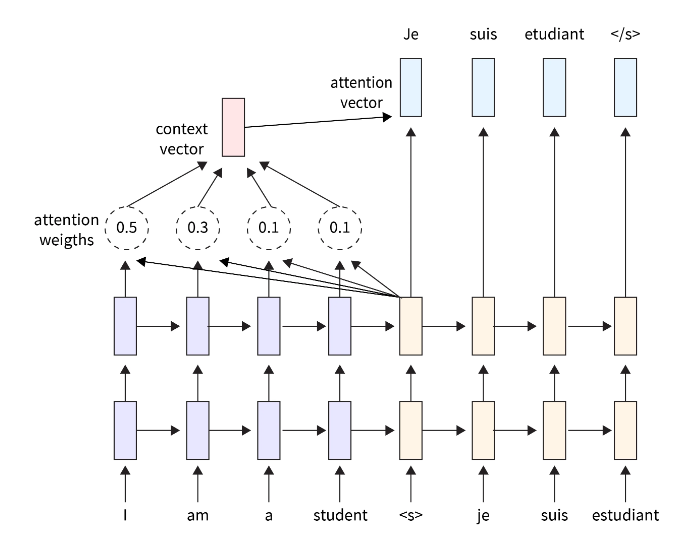
注意力-解码器的输入是单个向量,必须包含所有与上下文相关的数据。大序列会导致这方面的困难。因此,注意力机制使解码器能够专注于特定的输入序列并生成注意力向量。
-
光束搜索-解码器选择概率最高的单词作为输出。但是,由于贪婪的算法是问题的根源,因此这并不一定会产生最佳结果。因此,使用波束搜索,建议每个阶段的潜在平移。为此,将创建顶部 k 结果的树。
-
铲斗-由于序列到序列模型的输入和输出都用零填充,因此可以想象可变长度序列。但是,如果我们将最大长度设置为 100,而句子只有三个单词长,则会显着损失空间。因此,我们应用了分桶概念。首先,我们创建不同大小的存储桶,例如 (4, 8)、(8, 15) 等,其中 4 是最大输入长度,8 是最大输出长度。
长度相等的输入和输出序列
当输入和输出序列的长度相同时,您可以轻松地使用 Keras LSTM 或 GRU 层创建相似的模型。
这种策略有一个缺点,因为它假定你可以生成目标[...t] 对于给定的输入[...不幸的是,在生成目标序列之前,通常需要整个输入序列。这在少数情况下有效(例如添加数字字符串),但对于大多数用例来说可能更有效。
使用 seq2seq 模式进行语言翻译
如上所述,让我们了解编码器和解码器如何处理映射不同长度的输入和输出的任务。
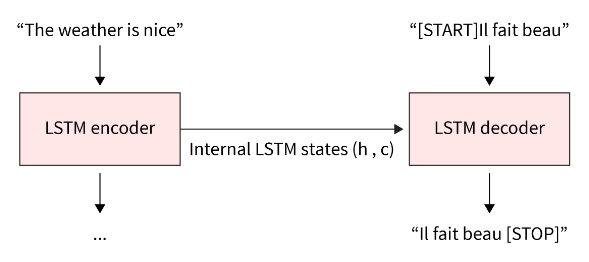
我们尝试将一个句子从英语翻译成法语。 这句话就是“天气很好”。
编码器
编码器的基本结构是带有 LSTM 或 GRU 单元的 RNN(控制要保留哪些信息或抛出什么信息)。另一种选择是双向 RNN。我们不使用编码器的输出,而是将输入句子输入其中,并使用上一个时间步的隐藏状态作为嵌入。
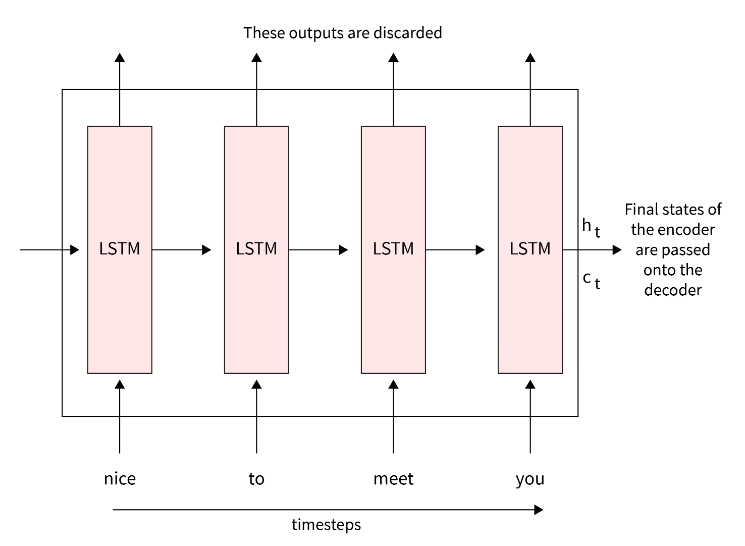
作为时间步长的第一步t=0,对于 LSTM 单元,我们将输入传递到 LSTM 单元格![]() ,这是源句子中的第一个单词。该模型使用 input(
,这是源句子中的第一个单词。该模型使用 input(![]() );LSTM 单元计算第一个隐藏状态,
);LSTM 单元计算第一个隐藏状态,![]() 如:
如:
![]()
在时间的下一步中t=1,我们传递输入,![]() ,句子“weather”的下一个单词,到编码器。与此同时,我们还传递了之前隐藏的状态ℎ0h0到单元格并计算隐藏状态
,句子“weather”的下一个单词,到编码器。与此同时,我们还传递了之前隐藏的状态ℎ0h0到单元格并计算隐藏状态![]() :
:
![]()
该过程在整个源句子中重复。因此,最后一个隐藏层从源句子中捕获所有单词的上下文。这里的英文句子“The weather is nice”是来源。在图层中处理的单词将是“The”、“Weather”、“is”和“nice”。
由于最终的隐藏层包含上下文,因此形成了嵌入![]() ,也称为上下文向量:
,也称为上下文向量:
![]()
译码器
解码器是具有 LSTM 或 GRU 单元的 RNN。解码器旨在从给定的输入句子生成输出。现在,我们将了解解码器的工作原理,以使用编码器生成的向量 Z 生成输出。
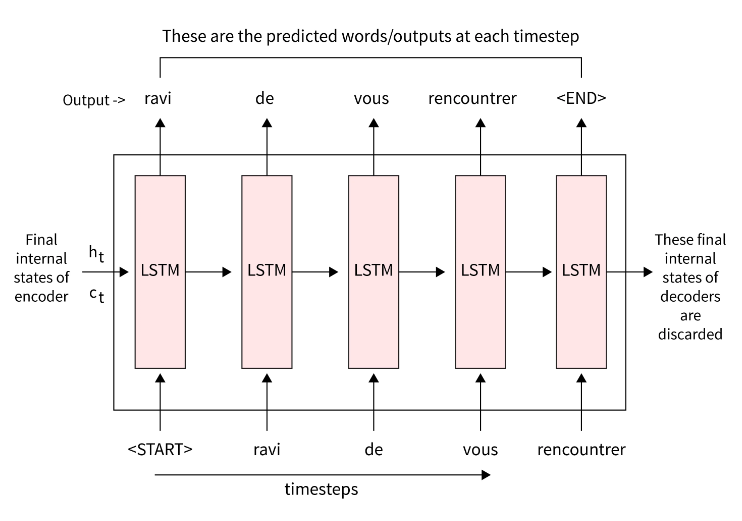
我们为解码器提供 <sos>,它表示句子的开头,作为输入。因此,在收到 <sos> 后,解码会尝试猜测目标句子的第一个单词。
我们使用编码器生成的向量初始化解码器的第一个隐藏状态,而不是使用随机值初始化它们。接下来,我们将预测的输出和上一个时间步的隐藏状态作为当前时间步的输入提供给解码器,然后预测当前输出。
我们需要预测输出句子,一个法语句子映射作为模型输入的英语句子。然后,我们输入解码器隐藏状态,它将词汇表中所有单词的分数返回到相应的输入中。
我们将它们转换为概率并使用 softmax 函数,该函数压缩 0 到 1 之间的值。然后,我们选择高概率值的单词作为映射到输入。
因此,序列到序列模型以这种方式将源句子更改为目标句子。
编码器-解码器模型的缺点
这种架构有两个主要缺点,这两个缺点都与长度有关。
- 首先,它的架构内存要少得多。您正在尝试压缩整个句子以转换为 LSTM 的最后一个隐藏状态。通常,它们只有几百个单位(或浮点整数);你越是试图适应这个受限维度的向量,神经网络就越有损。考虑神经网络必须完成的“有损压缩”会很有帮助。
- 其次,神经网络越深入,训练就越具有挑战性。对于递归神经网络,序列长度决定了网络随时间推移的延伸程度。结果,来自递归神经网络的梯度信号在向后移动时会消失,从而导致梯度消失。因此,即使RNN旨在帮助防止梯度消失,如LSTM,这仍然是一个基本问题。
结论
- 序列到序列 (Seq2Seq) 模型在文本摘要、图像字幕和机器翻译等任务中表现出色。
- 它们使处理具有不同输入长度和预期输出的任务变得更加容易。
- 此外,注意力模型和变形金刚等模型可用于更长、更复杂的句子。

