- 1突破编程_C++_C++11新特性(type_traits的复合类型特性以及关系类型特性)
- 21、Flutter开发-安装和配置Flutter SDK_d:\fluttersdk\flutter\bin\flutter.bat --no-color t
- 3LTP简介_ltp模型
- 4【论文笔记】ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks_eca-net的网络结构图
- 5舞台音效控制软件_QLab Pro 4.3.2 优秀的舞台音乐控制软件
- 6SharePreferenc详解(一)_sharepreference 在生命周期
- 7ChatGPT:人工智能语言模型的革命性进步
- 8python小波包分解_Matlab小波包分解后如何求各频带信号的能量值?
- 9Opencv图像处理(全)_opencv 图像处理
- 10利用Python将多个excle文档和并成一个Excle_将多个excel文件合并去重到一个excel,python
pytorch 神经网络笔记-RNN和LSTM_pytorch crnn +lstm解码
赞
踩
b站课程链接课时自己找一下
时间序列表示方法
-
- 一般都是二维的图像数据
-
- sequence类型数据
- 时间序列
- 文本
- 一个句子是连续的单词,一个单词是连续的字母这样
- 编码
- one—hot编码很稀疏
- 一般会通过语义相关性进行编码
-
输入数据类型
- 对于CNN,一般是[batch_size,channels,Height,width]
- 对于sequence,分两种
- [word num ,batch_size, word vec]
- 从图像上更好理解
- 这里word num 就是横轴
- batch_size就是几条曲线
- word vec就是每个点有几个特征,这里就一个值,所以 word vec就是1
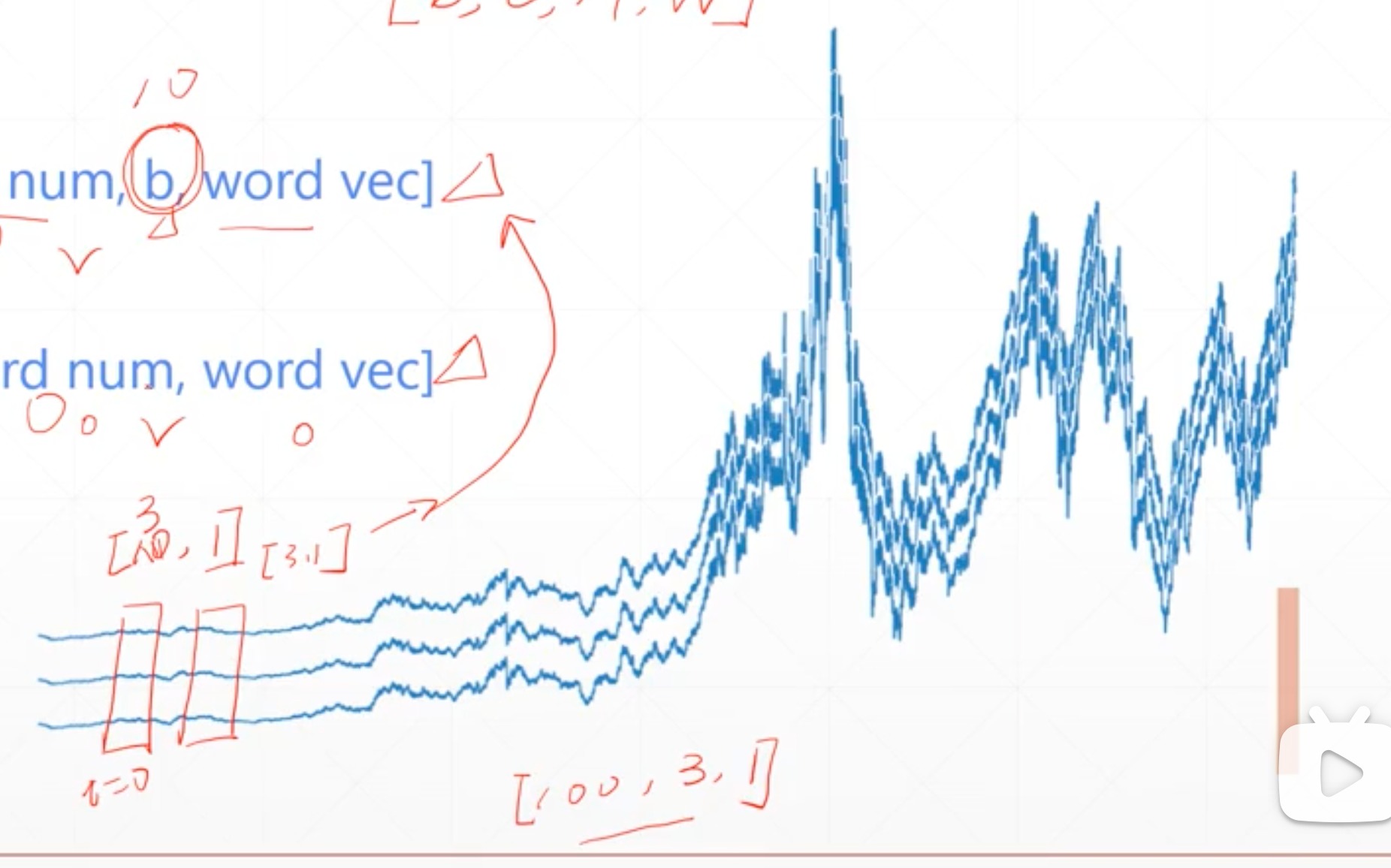
- 从图像上更好理解
- [batch_size,word num , word vec]
- 可以理解为第batch_size个句子,里面有word num个单词,每个单词有word vec个表达方式
- [word num ,batch_size, word vec]
- word vec 就是词向量,比如情感相关度
一般过程
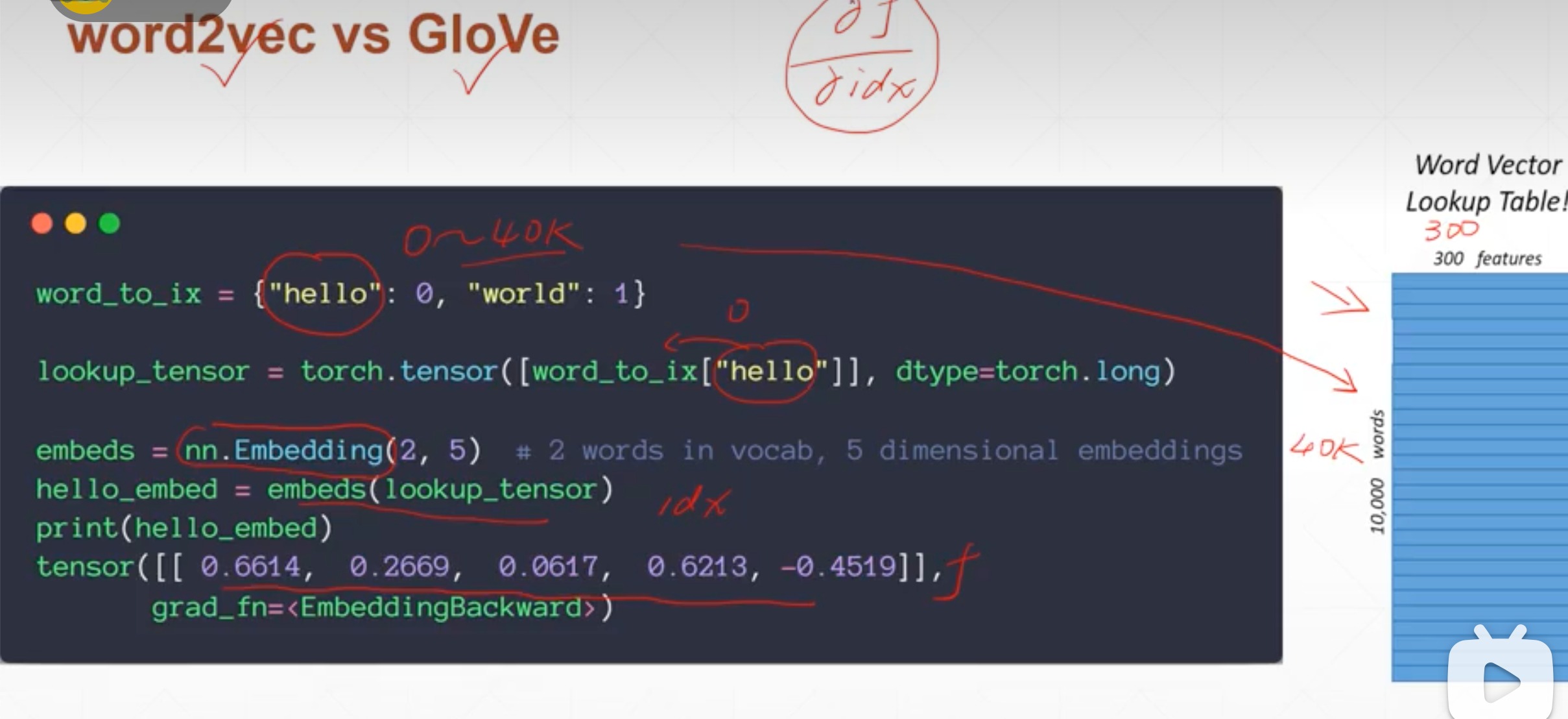
先找到单词的索引
embed一般是下载好的,存储每个词的特征,这里例子举例是随机的,实际上是由官方编制,下载word2vec或者GloVe,到本地使用
通过索引,查找到对应单词的词向量
注意:这种官网的embed是不能直接算梯度进行优化的
- 比如这里直接调用GloVe,查找“Hello”,由一个100维度的词向量表示

RNN
RNN原理1

-
说明:
- 这句话就是一个[5,100]的tensor
- 每一个时间戳(单词)是100维的向量,作为输入x,输入到一个Linear线性层里,进行一个特征的抽取,比如说输出一个2维的
- 加起来就是[5,2]的向量
- 然后再去做positive/negative的二分类
-
上述存在的问题
- Long sentence
- 100 + words
- too much parameters[w,b]
- 每个词都有一个w和b
- no context information
- Consistent tensor
- Long sentence
-
解决办法
-
减少参数数量
- weight sharing
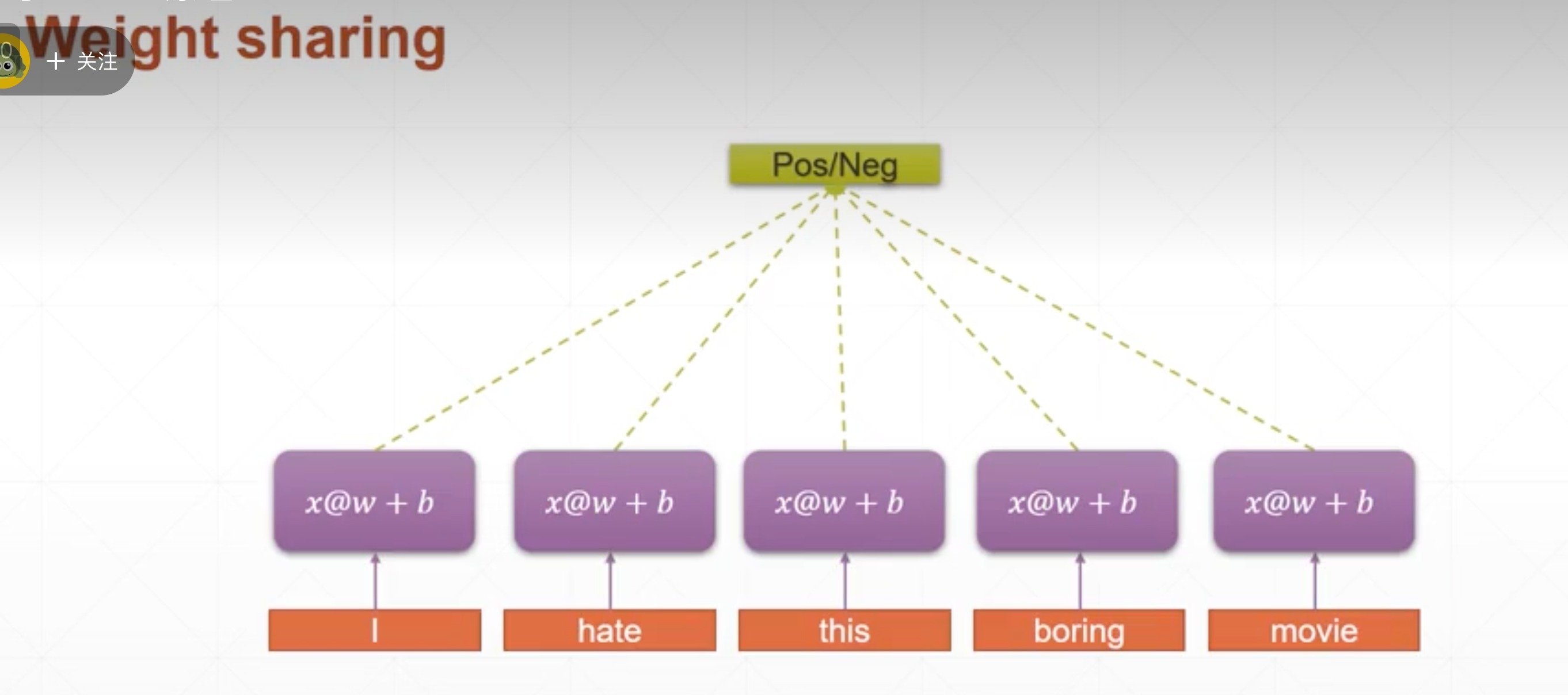
- 一个[w,b]表示5个词,相当于是5个词都过一遍这个线性层,所以一个[w,b]就能提取出这句话,而不是一个单词一个
- weight sharing
-
保存语境信息
-
比如“不喜欢”,不能只看到了“喜欢”没看到“不”
-
需要一个语境单元,来贯穿整个网络,保存整个语境信息
-
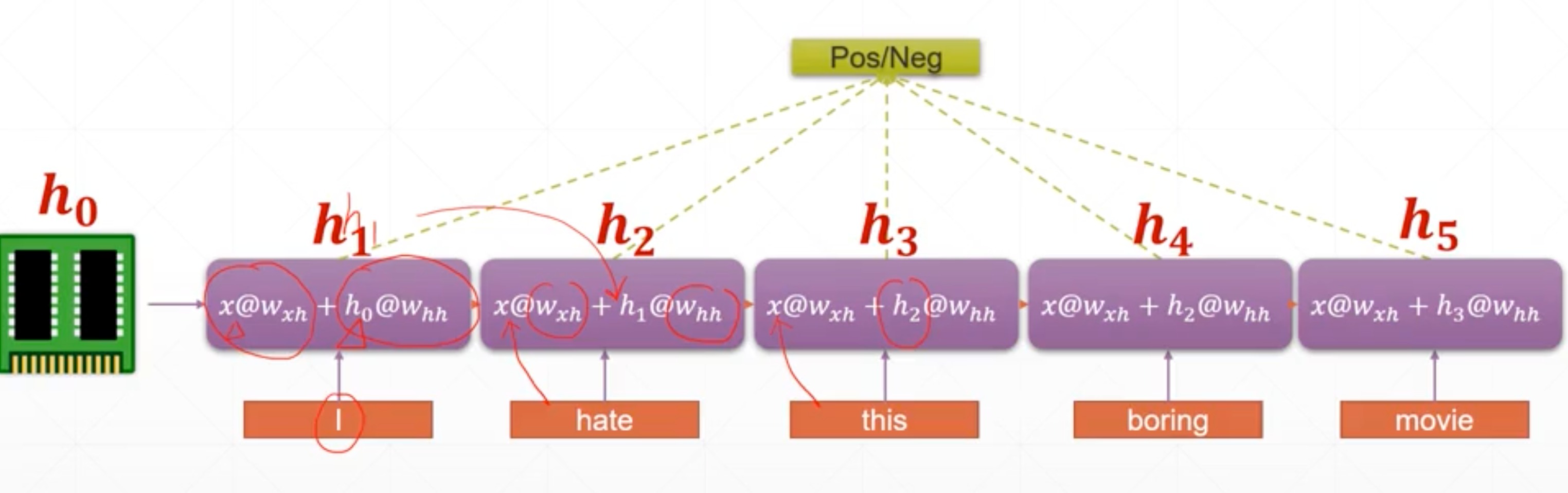
consistent memory
-
h t h_{t} ht,记忆单元,会不断根据输入,循环更新自身,而不是像CNN一直往前冲

-
上述的模型非常合理
-
至于最后选择输出的话,可以选择最后的 h t h_{t} ht,或者中间的 h t h_{t} ht,或者做一个融合,非常自由

-
-
RNN原理2
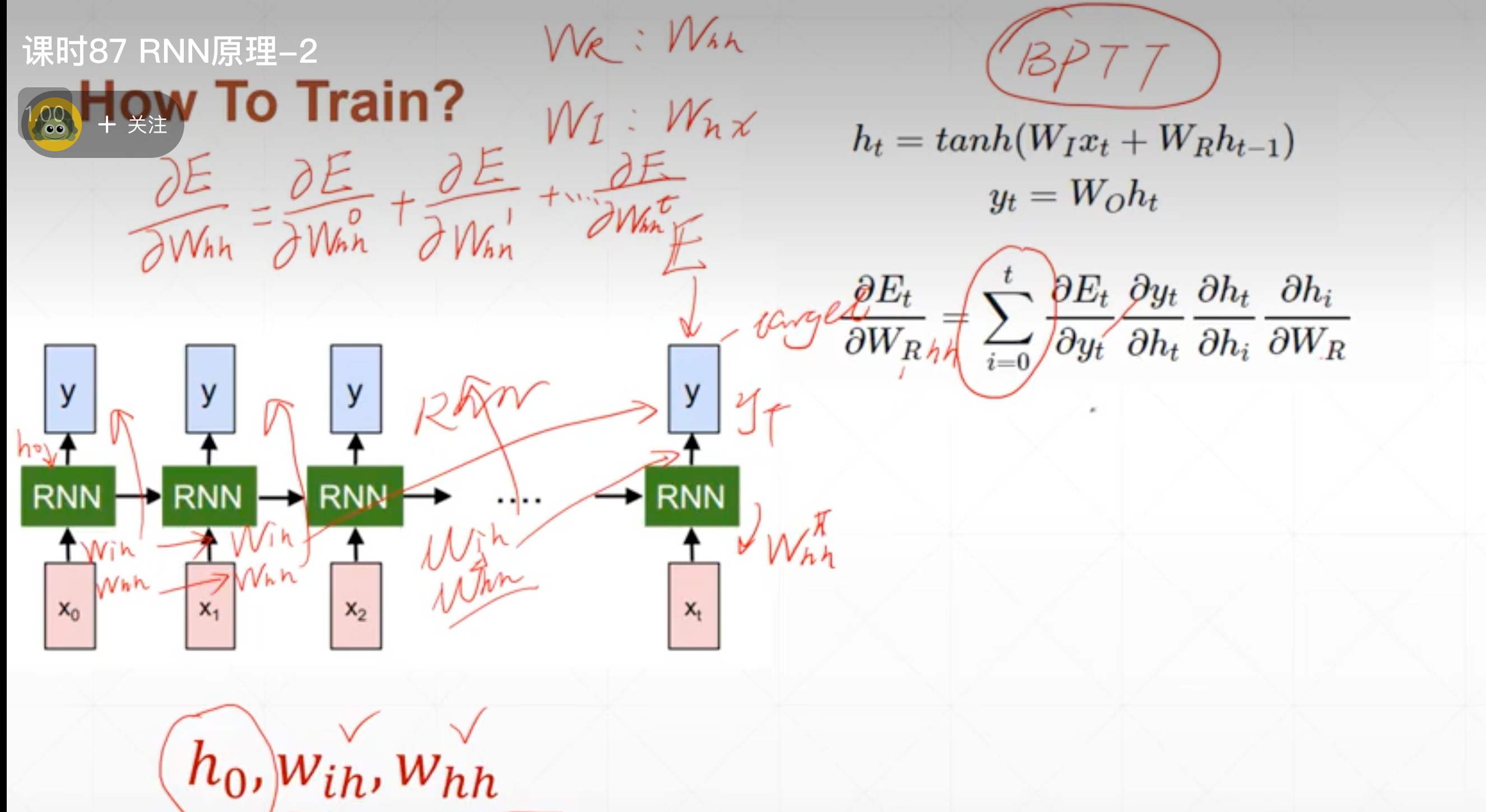
- memory是如何更新的

- 根据上一次的memory和这次输入的x,两个参数,两组矩阵想乘再相加,一般用tanh作为激活函数。最后那个得到y就是可以再加一个linear层,不用看
-
这里E就是error
-
h0一般是[0,0…0]
这里表示方式有所不同
W R W_{R} WR就是 W h h W_{hh} Whh
W I W_{I} WI就是 W x h W_{xh} Wxh
- 是累加的,每一步都有影响
- 使用链式法则是为了把每一个单元的导数都很好的推导出来


- 感受到这个大概的推导过程后,主要是推导一个这个梯度是怎么求的,说明是能更新的
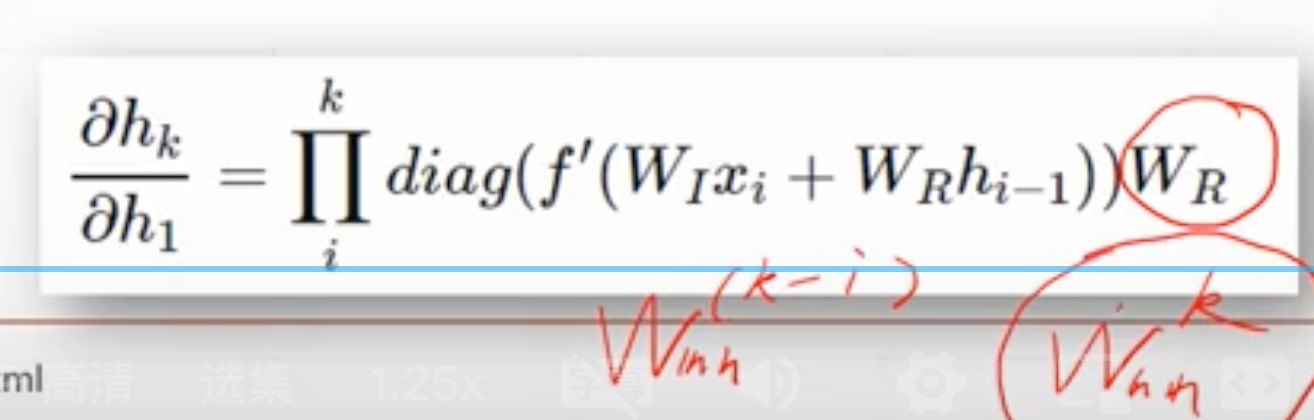
- (因为 W R W_{R} WR就是 W h h W_{hh} Whh,且这里算梯度是累乘)所以这里就有 W h h k − i W_{hh}^{k-i} Whhk−i ,如果i=0,就是 W h h k W_{hh}^{k} Whhk ,这个比较关键,在后面会阐释
RNN layer使用
回顾: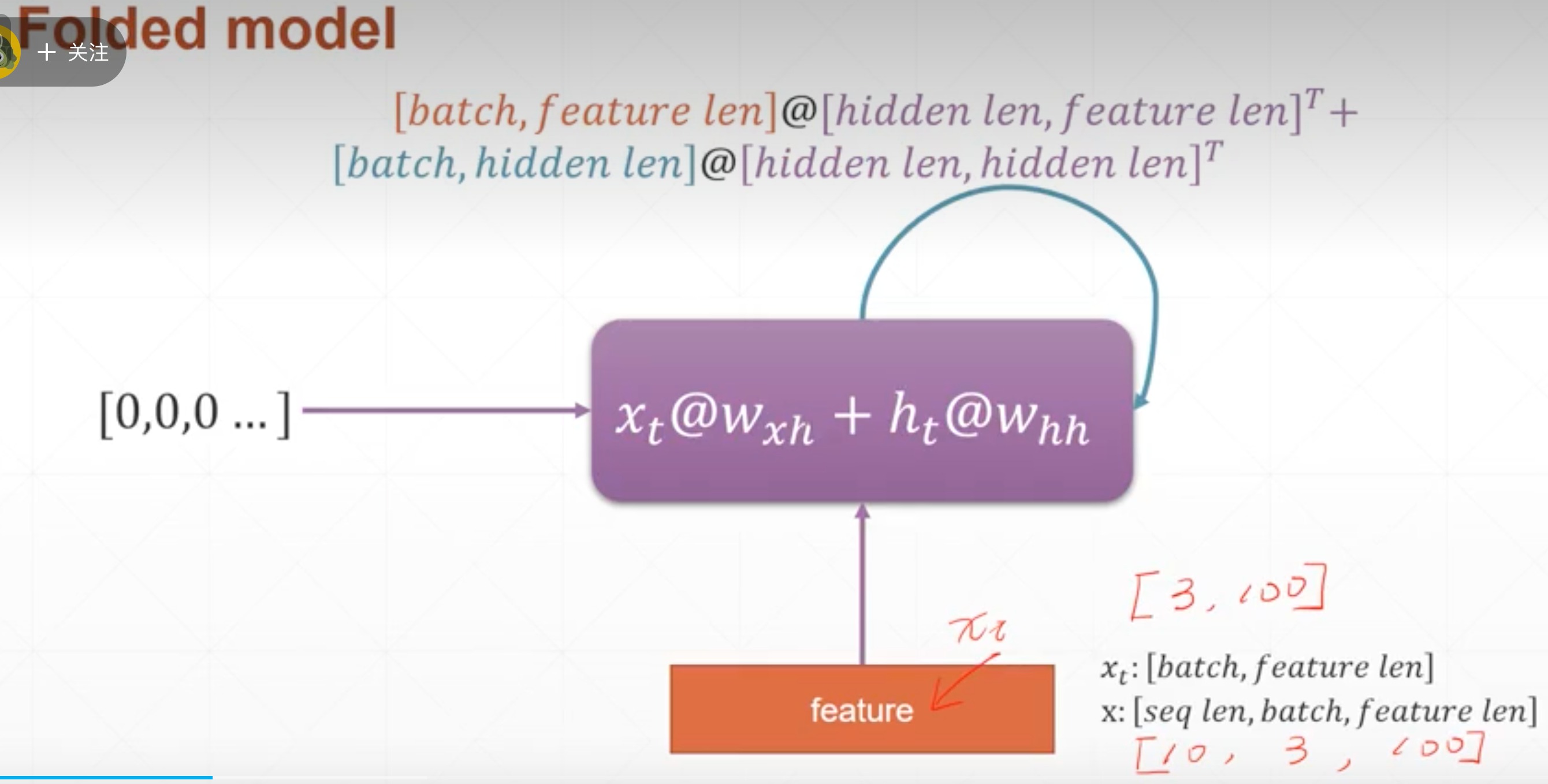
-
X[总共多少个词,总共几句,特征数]
-
某一时刻的输入 X t X_{t} Xt,是每句话输入一个单词,这里就是[3,100]
-
这里用20维的memory来表示,每一步的memory更新是这样的,所以初始的memory设置应该是[batch_size,20]

- 调用pytorch代码验证一下
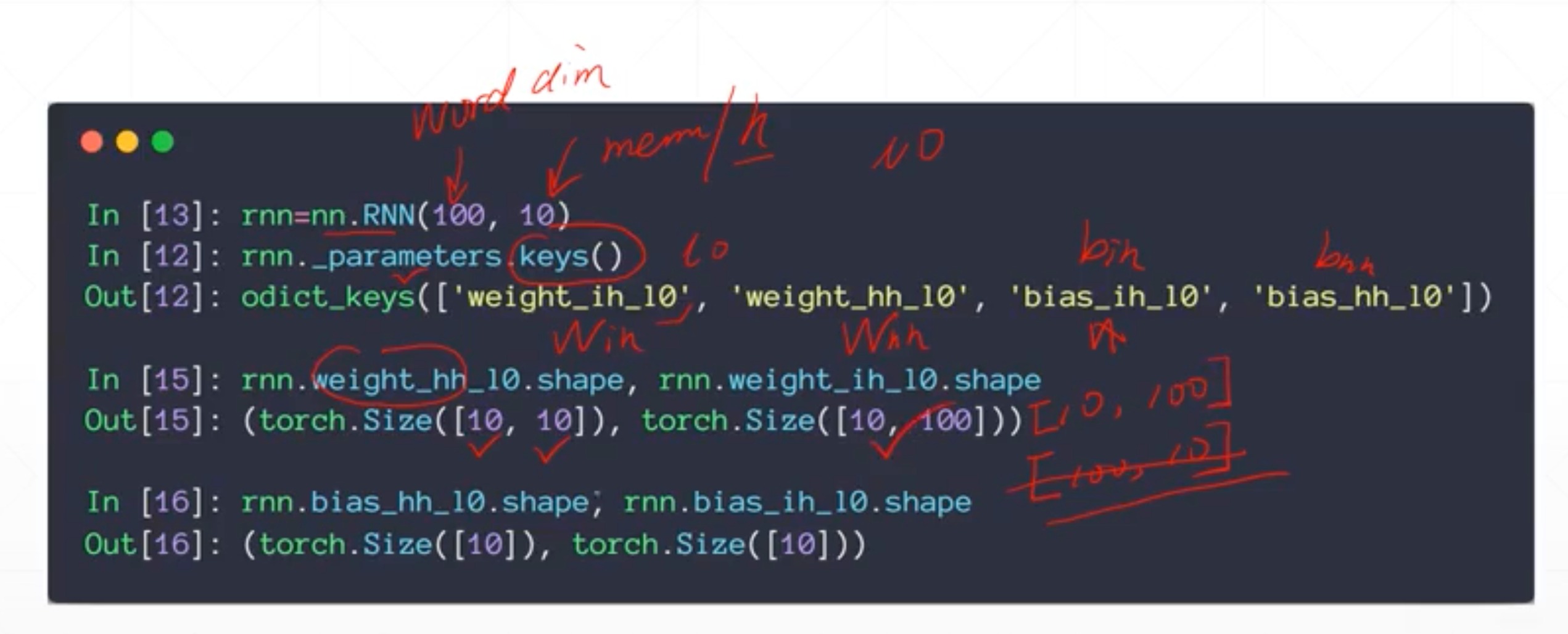
pytorch实现nn.RNN
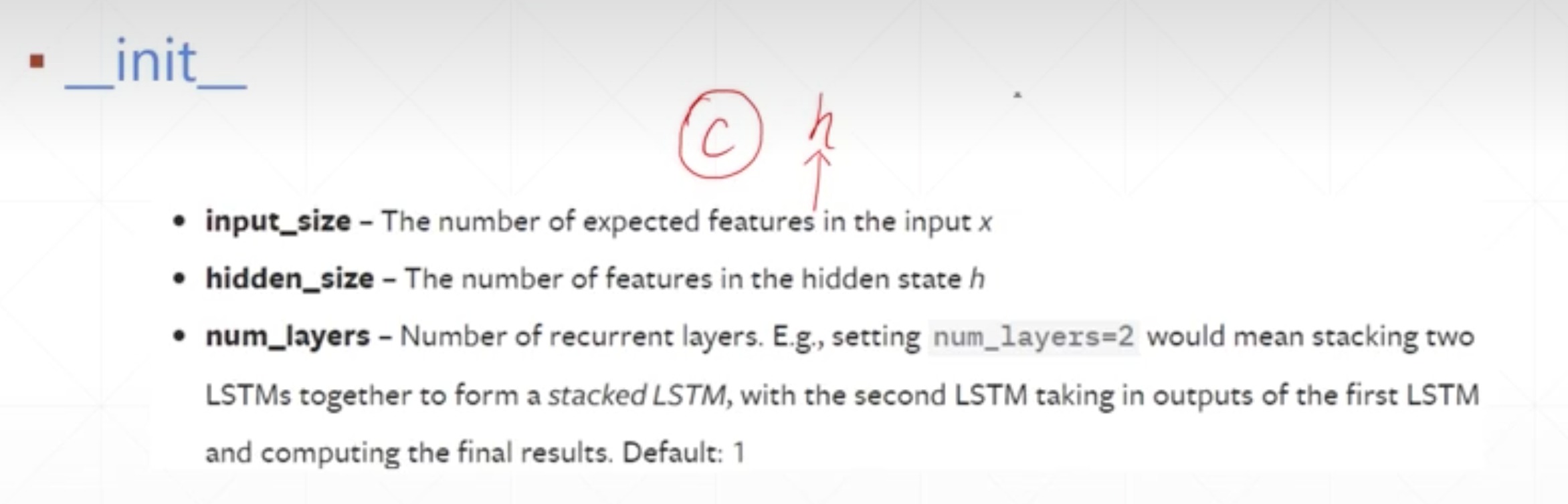
init
- Input_size
- 对于一个单词,你用100维的向量来表示,那这个就是100
- 对于预测房价,只有一个价格,那这个就是1
- 是X[seq,batch_size,vec]里面的vec
- hidden_size
- 是隐藏层的维度
- 是前面的h[batch_size,h_dim]里面的h_dim,应该是纯自己设置的,跟输入无关
- num_layers
- 不使用,默认是1
- 使用,可以是1,2,4等
forward

-
这里是把数据一步喂到位,而不是前面分解的,比如对于X[5,3,100](3句话,每句五个词,每个词100维度表示),是自动在时间上进行五次展开的。输入的是X,不是一步步的 X t X_{t} Xt
-
h t h_{t} ht的参数是,第一个是几层,第二个是batch_size,第三个是h_dim。
- h0一般不设,就是初始化为0
- 对于返回的ht,其实就是最后一个时刻的ht,就是[layer_num,batch_size,h_dim]
-
out
- Out是每一个时间戳,的最后一个ht(memory)的状态,[ h 0 h_{0} h0, h 1 h_{1} h1,…, h t h_{t} ht]
-
对于X[5,3,100],h[1,3,10]来说
- h t h_{t} ht就是[1,3,10]
- out就是[5,3,10]
Single layer RNN
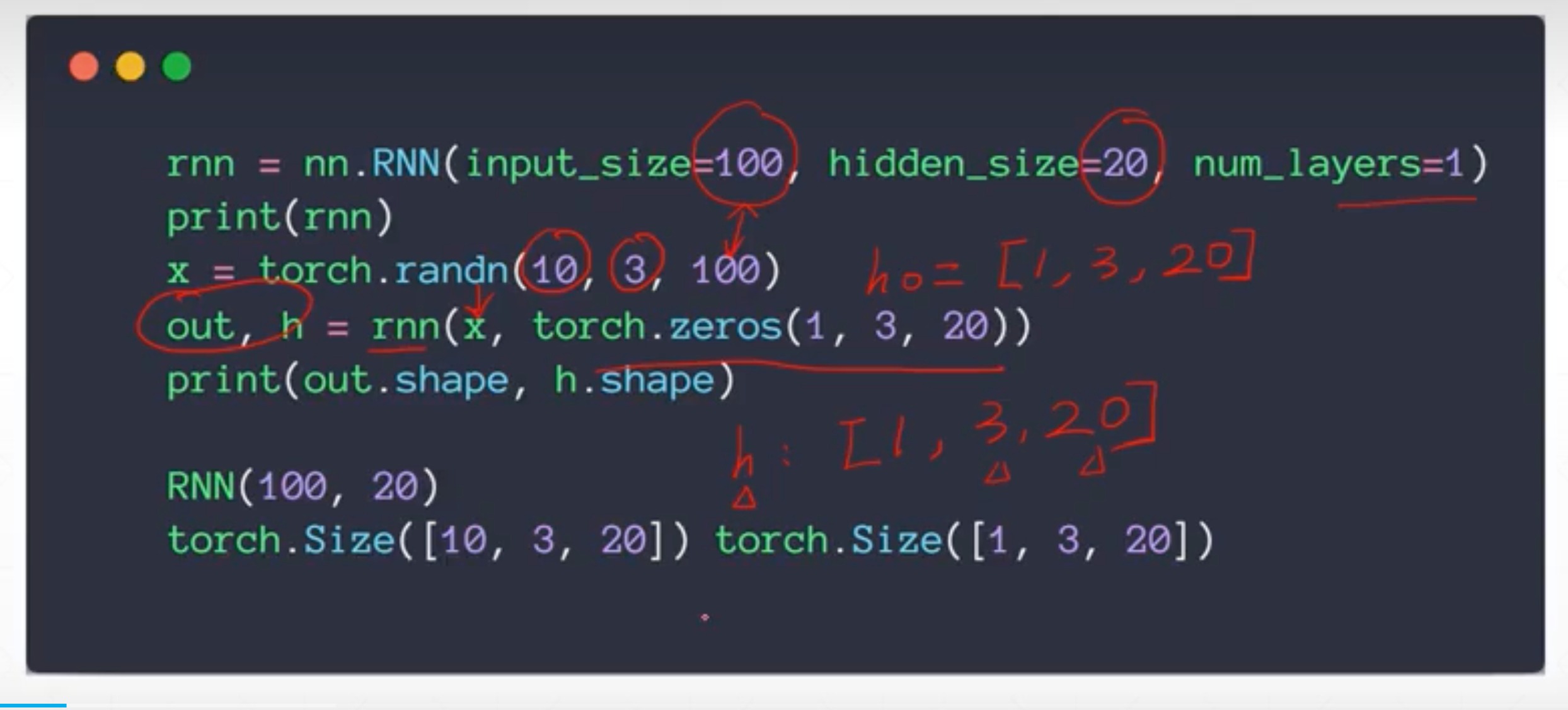
h是最后一个时刻的,维度是[1,3,20]
out是所有时刻的,维度是[10,3,20]
2 layer RNN

两层的话,out还是跟以前一样,代表是最后一层的,而h则是两层都有,二者是不同方向的,一个横着一个竖的
- 2层
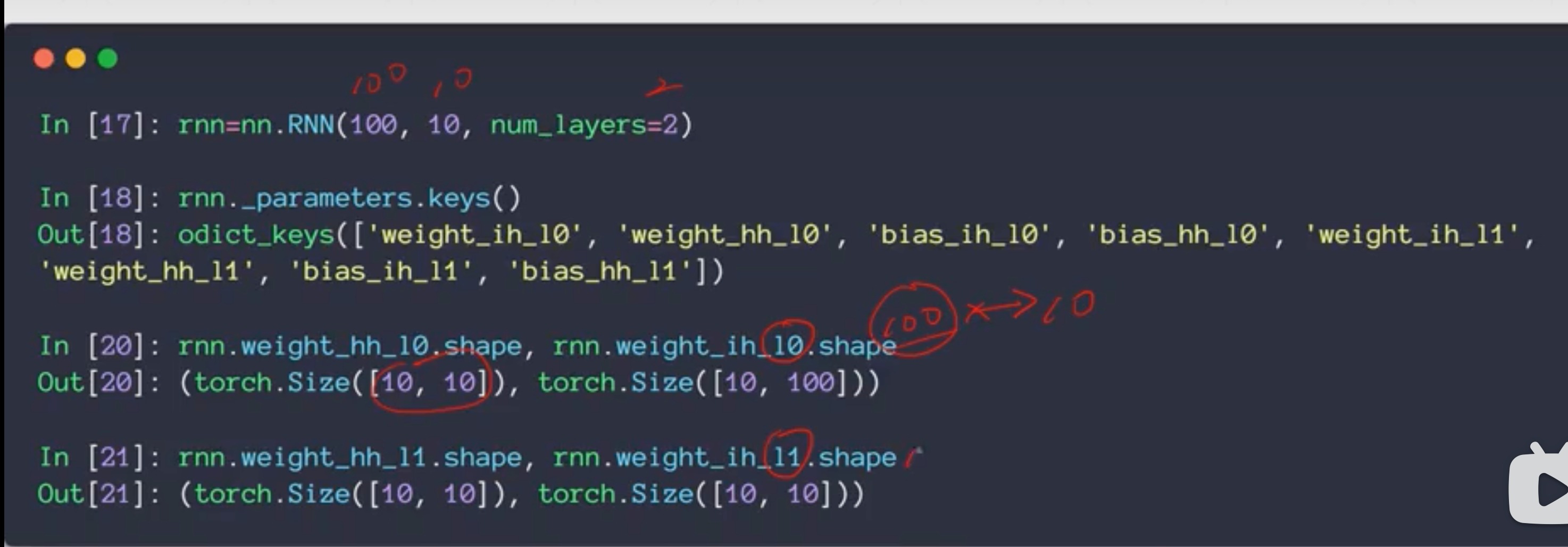
- 4 层

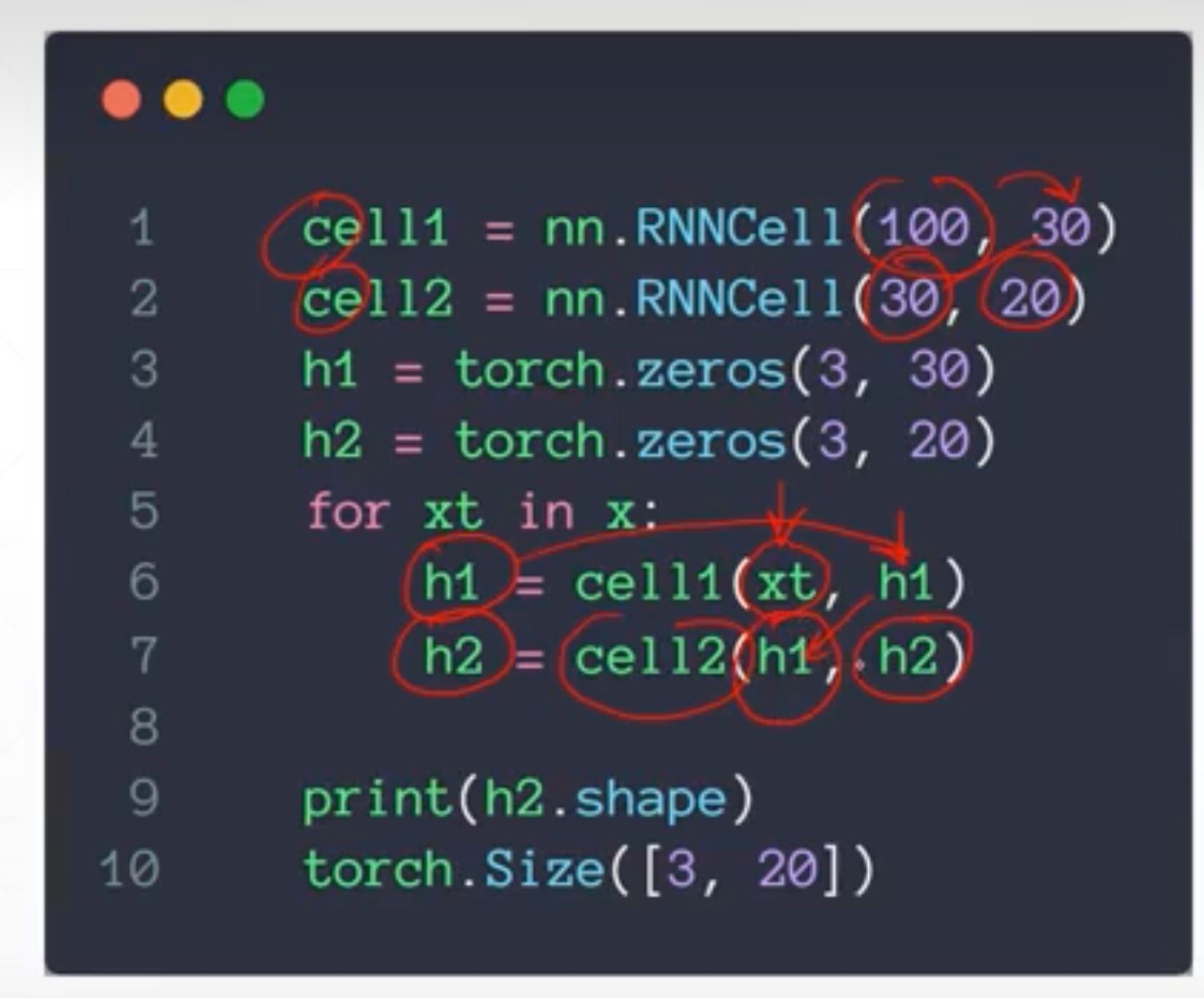
pytorch实现nn.RNNCell
前面是一次全部喂进去,这个是手动一次一次喂,相当于没有循环的步骤,没有在时间上展开
- 初始化参数,跟前面完全一样

- 然后后面类似forward方法这有一点不一样

- 一层的
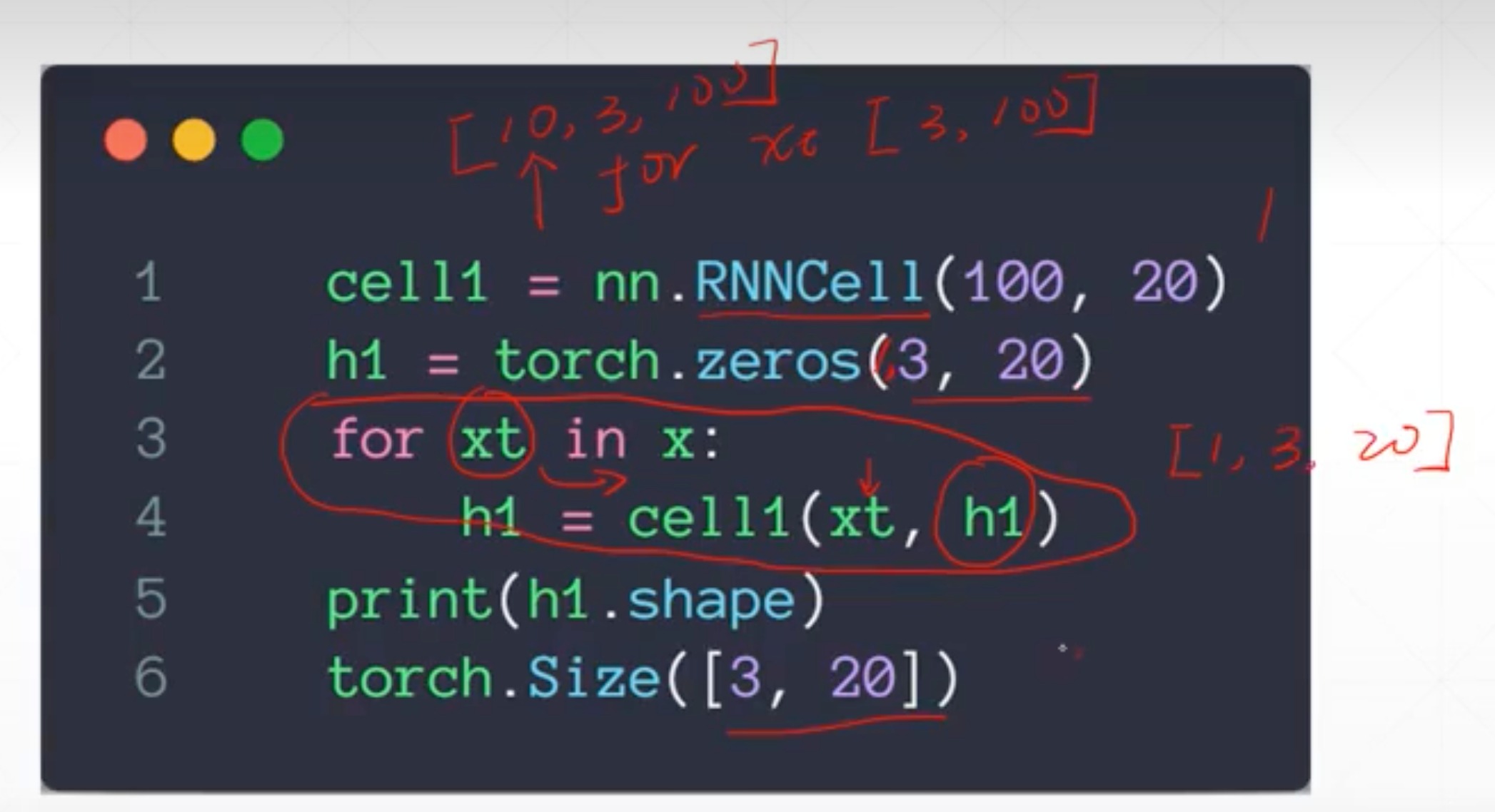
- 两层的
- 先把100特征变为30,再从30变为20
时间序列波形预测例子
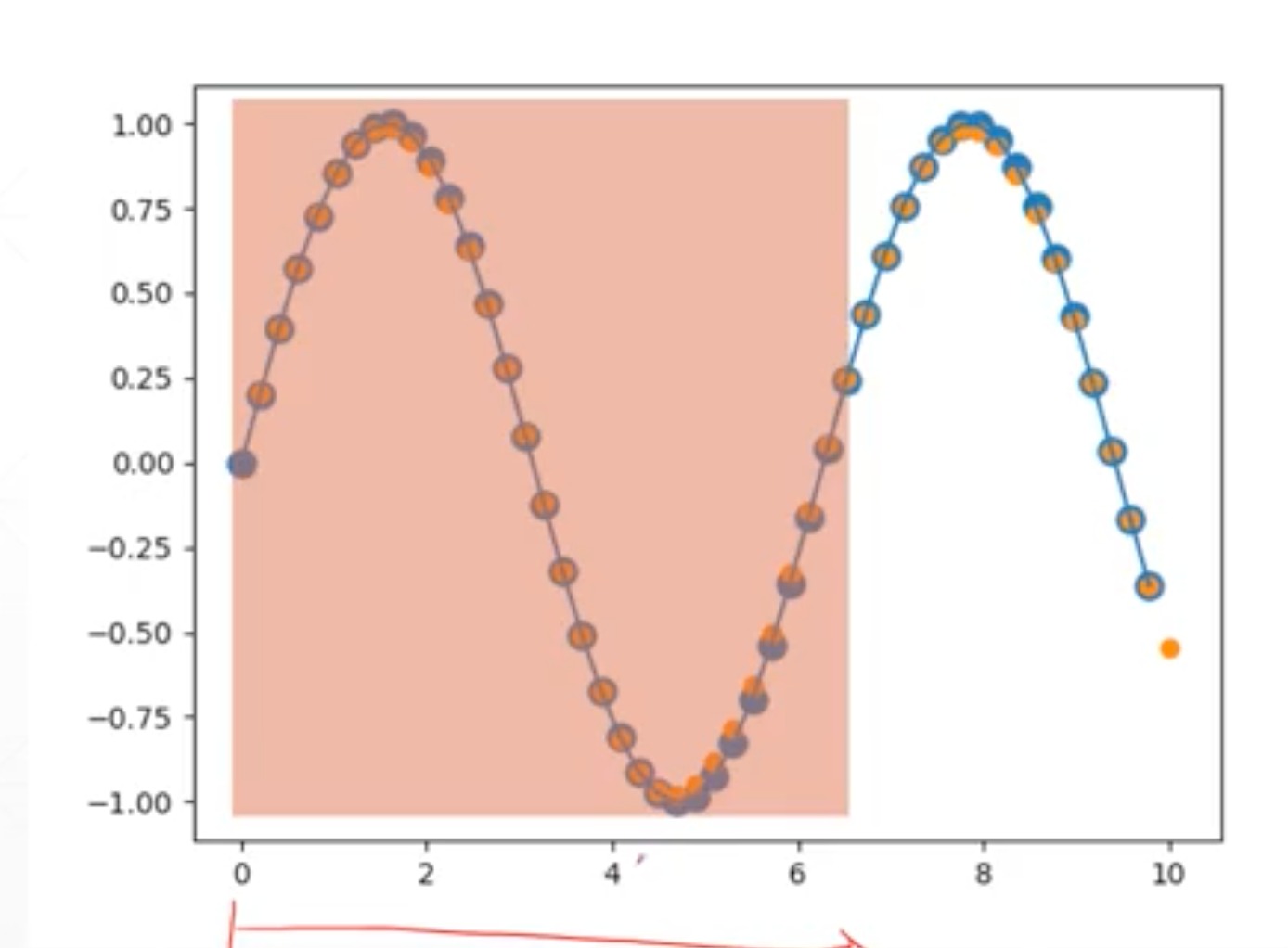 通过前一段波形,能很好的预测下一段的曲线形状
通过前一段波形,能很好的预测下一段的曲线形状
因为很简单,所以batch设置为1,假设总长为50个点,那X就是[50,1,1]
import torch
import numpy as np
num_time_steps = 1
start = np.random.randint(3,size=1)[0]
time_steps = np.linspace(start, start+10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps-1,1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps-1,1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
随机初始化start,不然会记住
-
x,y比如说,这里x是0~48之间的曲线,y就是要预测的1~49的曲线。当然也可以通过0~40的点去预测10~50的点
-
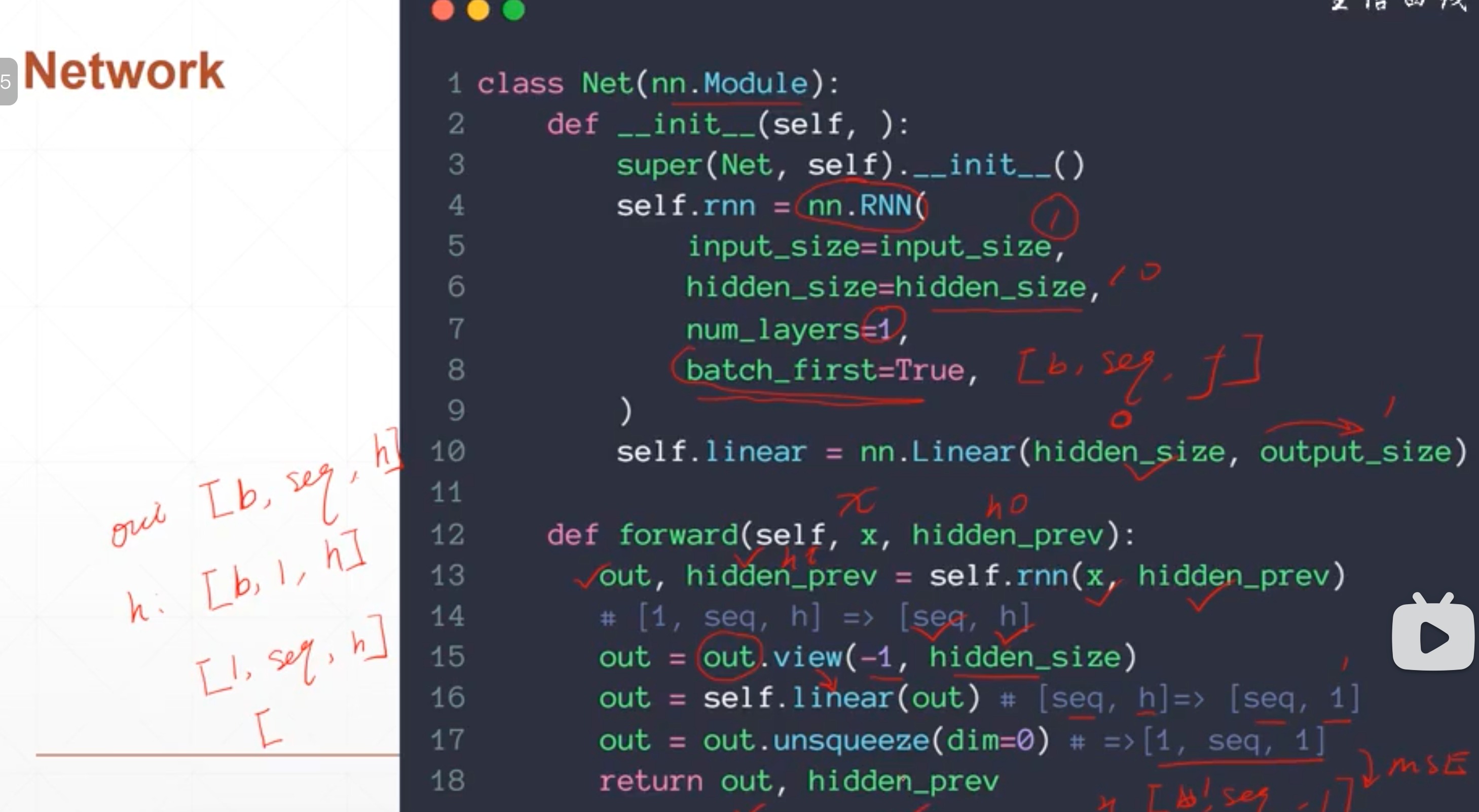
网络结构
class Net(nn.Module): def __init__(self): super().__init__() self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True, # 让输入X是[b,seq,f]的结构 ) for p in self.rnn.parameters(): nn.init.normal_(p,mean=0.0,std = 0.001) self.linear = nn.Linear(hidden_size, output_size) #output_size为1 def forward(self,x,hidden_prev): out, hidden_prev = self.rnn(x,hidden_prev) # hidden_prev就是ht out = out.view(-1,hidden_size) # 将[1,seq,h]reshape为[seq,h] out = self.linear(out) # 线性层 [seq,h]->[seq,1] out = out.unsqueeze(dim=0) # [seq,1]->[1,seq,1]方便和真实值算mse return out, hidden_prev

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 整体代码
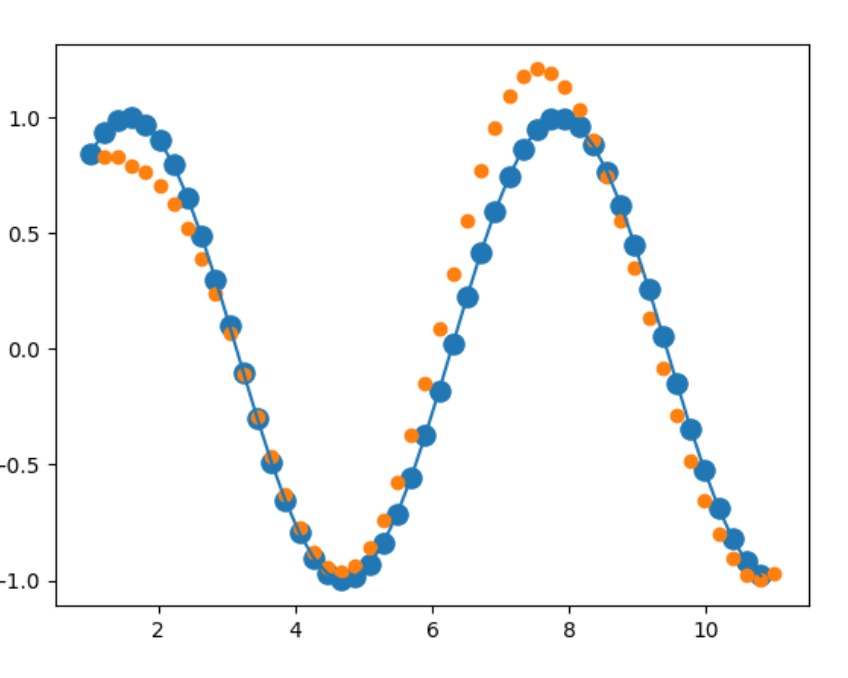
import torch import numpy as np import torch.nn as nn import matplotlib.pyplot as plt num_time_steps = 50 # 点的数量 input_size = 1 hidden_size = 16 # memory的维度 output_size = 1 lr = 0.01 # 训练过程 model = Net() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr) hidden_prev = torch.zeros(1,1,hidden_size) # h0 是[b,1,10] 这里batch设为1 for iter in range(6000): start = np.random.randint(3, size=1)[0] time_steps = np.linspace(start, start + 10, num_time_steps) data = np.sin(time_steps) data = data.reshape(num_time_steps, 1) x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) output, hidden_prev = model(x,hidden_prev) hidden_prev = hidden_prev.detach() loss = criterion(output,y) model.zero_grad() loss.backward() optimizer.step() if iter % 100 == 0: print(f"Iteration:{iter} loss:{loss.item()}") # 预测代码,给定一个点。后面会一个一个将预测值作为输入值,一个一个预测 prediction = [] input = x[:,0,:] for _ in range(x.shape[1]): input = input.view(1,1,1) pred, hidden_prev = model(input,hidden_prev) input = pred prediction.append(pred.detach().numpy().ravel()[0]) x = x.data.numpy().ravel() y = y.data.numpy() plt.scatter(time_steps[:-1], x.ravel(), s=90) plt.plot(time_steps[:-1], x.ravel()) plt.scatter(time_steps[1:], prediction) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 效果
LSTM
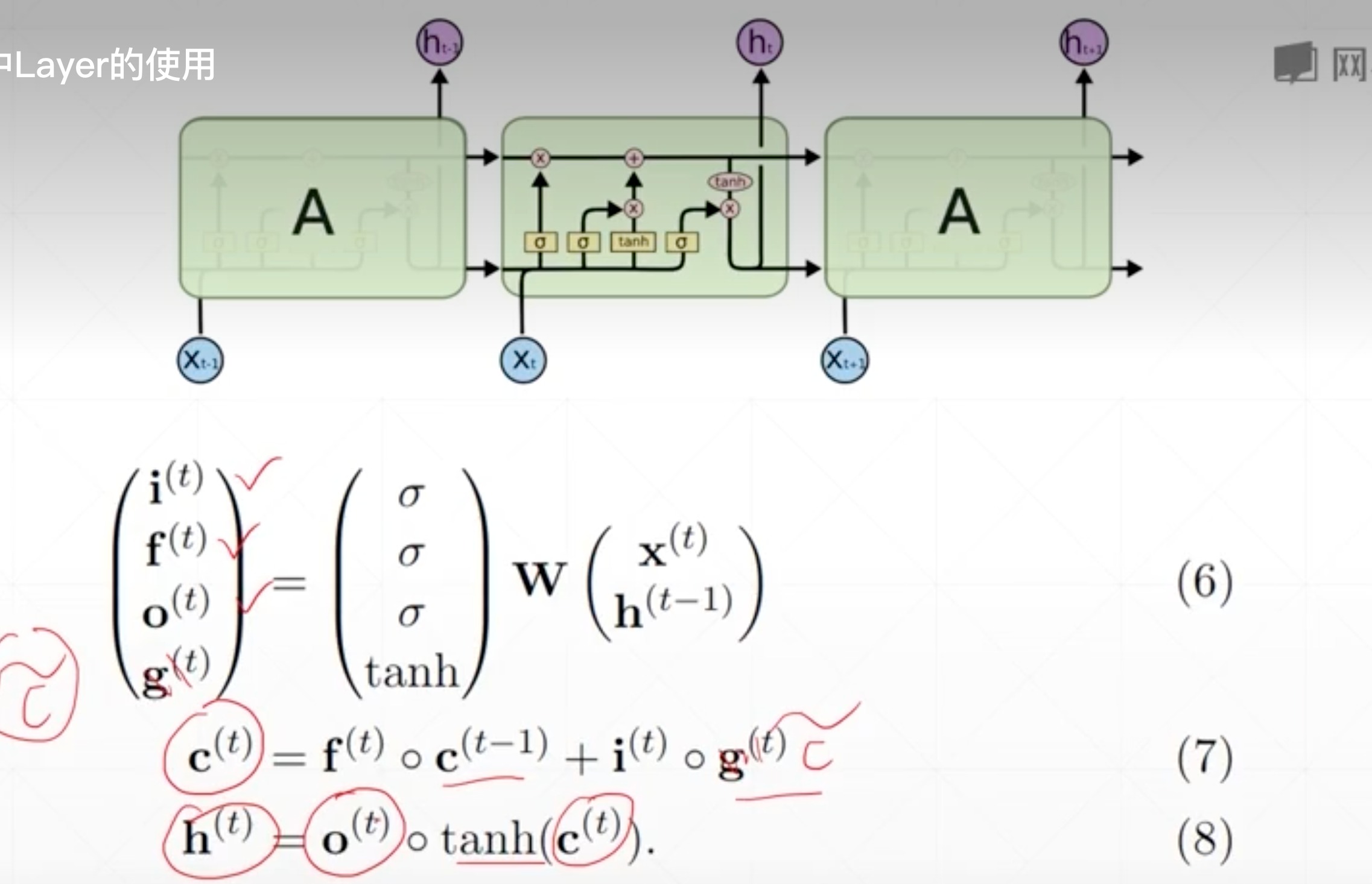
nn.LSTM
因为LSTM中,ht充当了输出的角色,中间流通的memory用C表示(C经过一定筛选才作为h输出),所以C和H的size是一样的
所以这里输入每个size,跟RNN是一样的,上面的代表x的特征维,第二个是h/c的维度,第三个是有几层

forward函数里,其余都跟RNN的一样,就是把h变为了h和c
-
例子
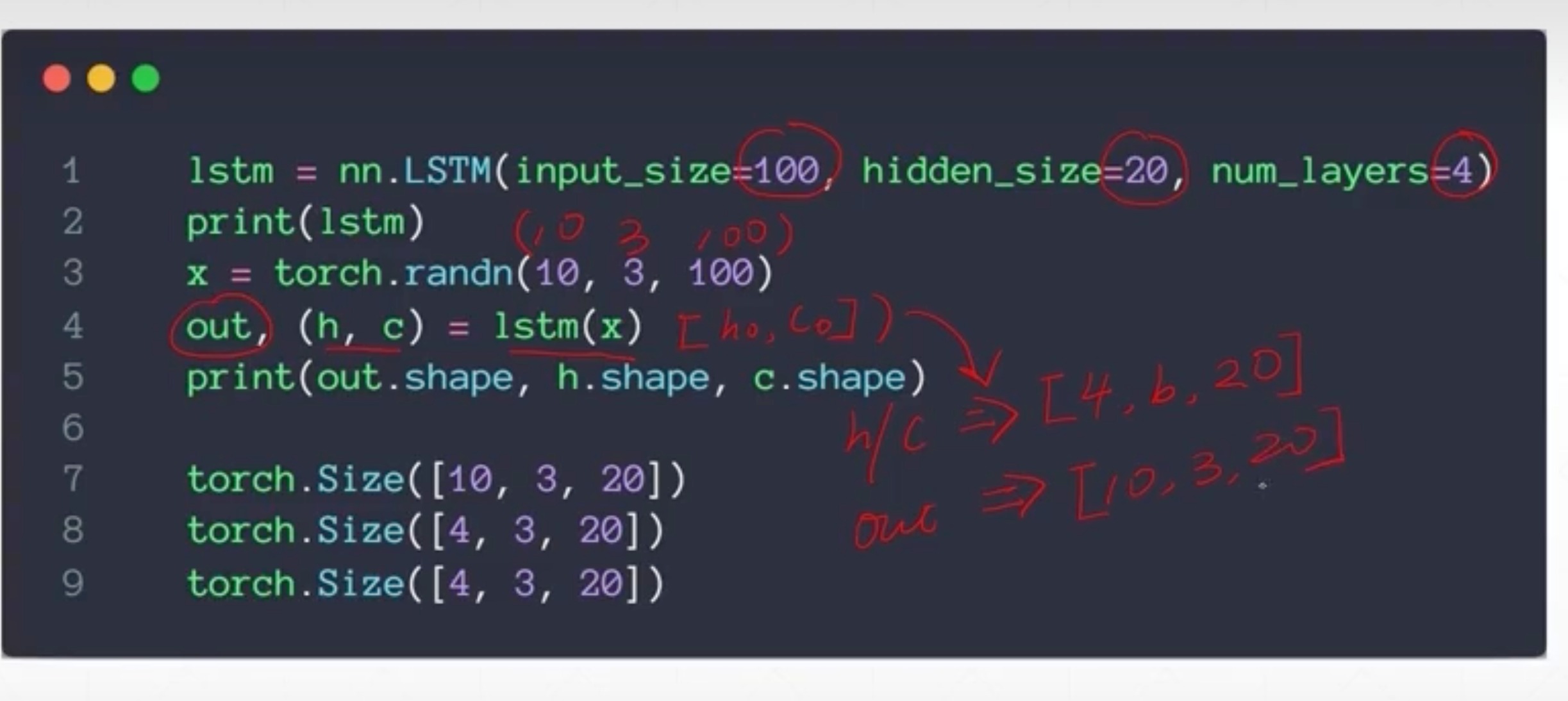
3句话,每句10个单词
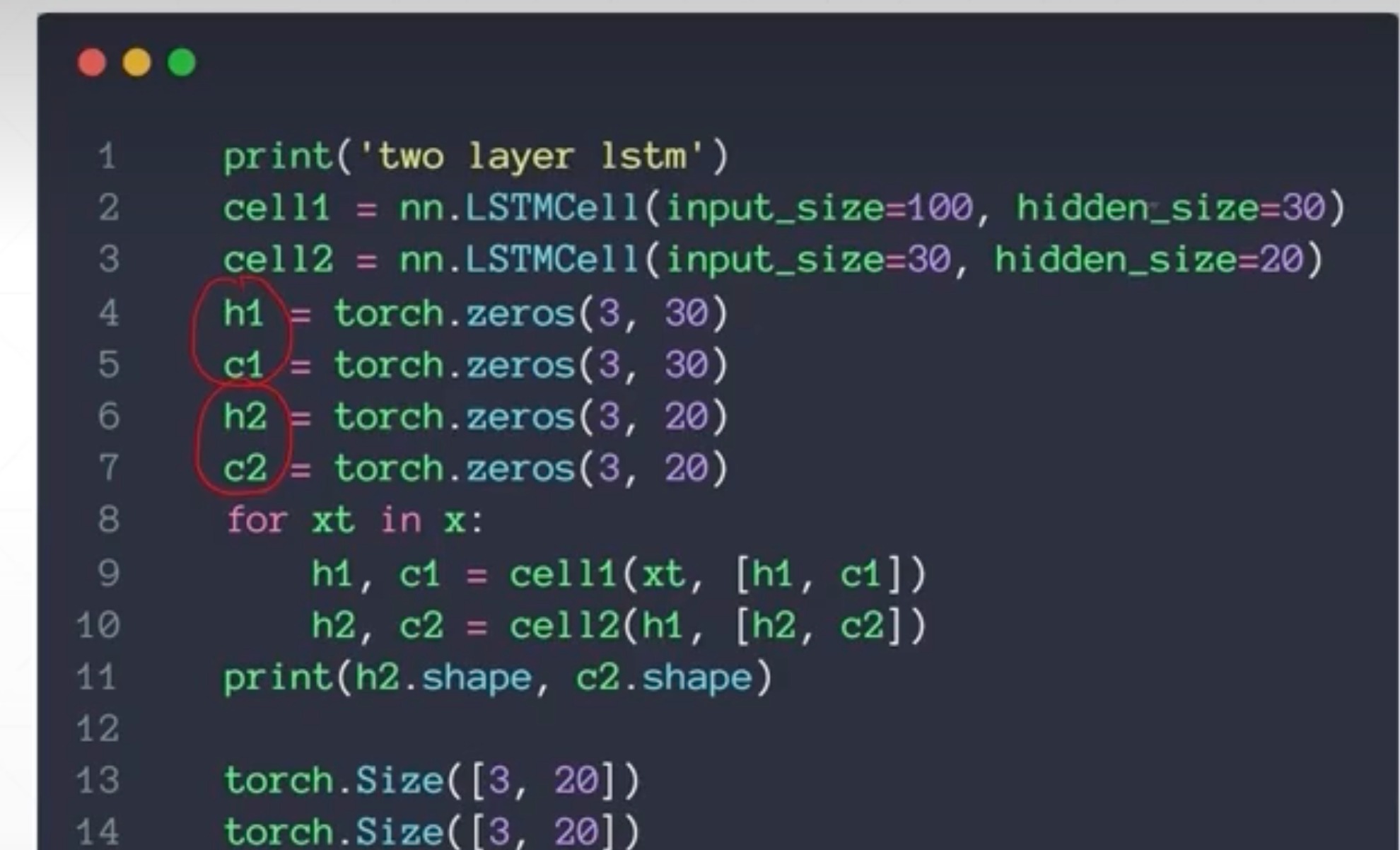
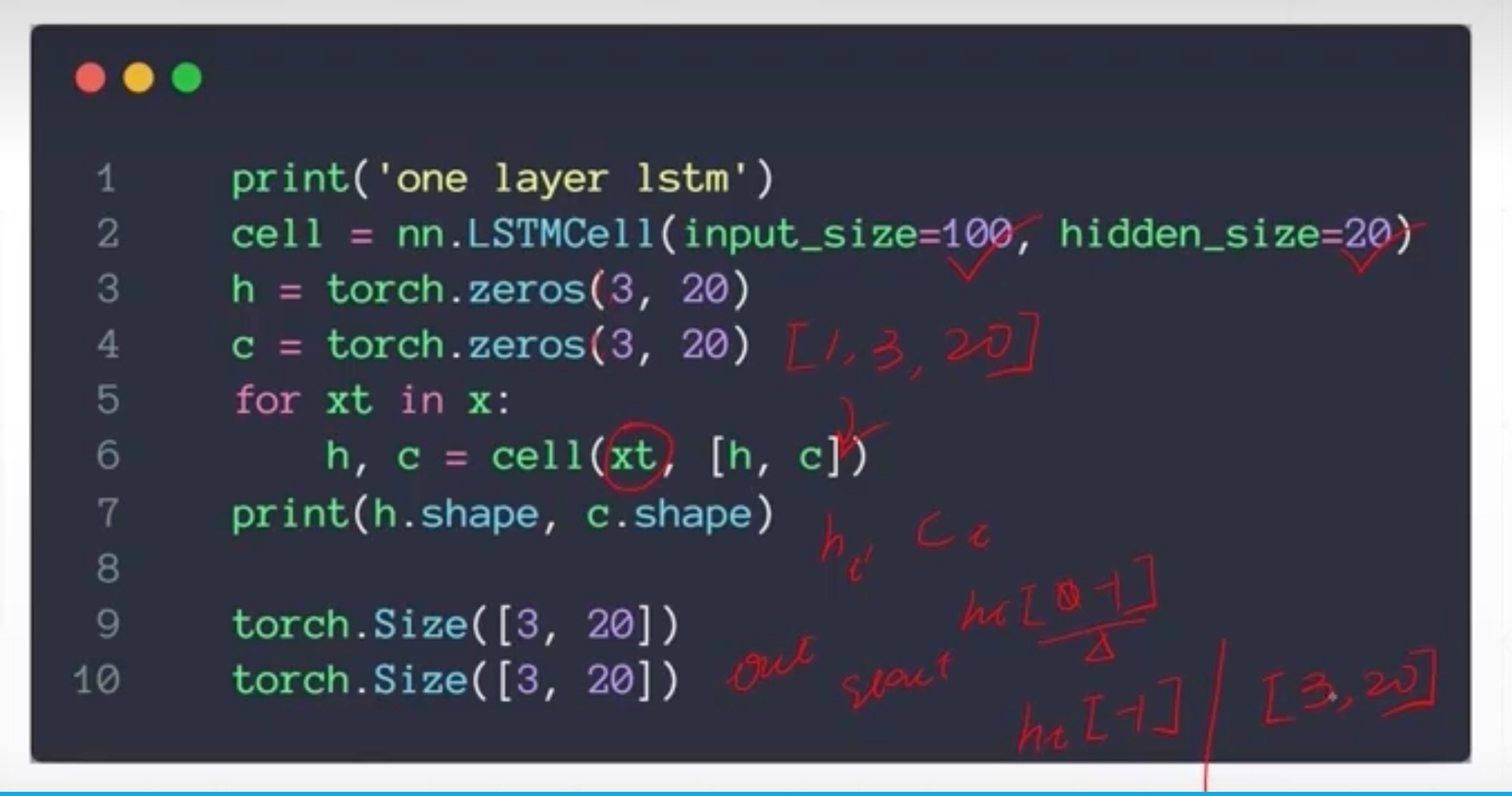
nn.LSTMCell


只有一层,所以这里第一个参数不写
Single layer
Two Layers