
- 1nlp知识点总结(上)_hanlp语料
- 2Spring Boot使用@Cacheable时设置部分缓存的过期时间_@cacheable 的缓存不更新是不是不会过期
- 3Ubuntu16.04 安装pyhton3.6及升级pip遇到的问题_error: ppa 'fkrull/deadsnakes' not found (use --lo
- 4HanLP分词原理剖析_hanlp原理
- 5KenLM使用教程_kenlm.pyx", line 139, in kenlm.model.__init__
- 6libsvm java 情感分类_自然语言处理系列篇——情感分类
- 7iOS开发过程中常见错误问题及解决方案
- 8BERT中的Tokenizer说明_berttokenizer
- 9为什么人工智能和Python要一起学?两者有何联系?_人工智能的底层是python吗
- 10结构风险最小化(Structural Risk Minimization, SRM)
【开源】本周不容错过开源论文,含分割、检索、神经渲染、deepfake 检测、超分、视频相关等...
赞
踩
本篇文章推荐本周值得关注的 10 篇开源论文,含 deepfake 检测、视频分类、图像分割、遥感图像检索、车辆检索、神经渲染、超分辨率等。
01
FReTAL: Generalizing Deepfake Detection using Knowledge Distillation and Representation Learning
来自成均馆大学
本次的研究工作,作者采用表征学习(ReL)和知识蒸馏(KD)范式,引入一个基于迁移学习的Feature Representation Transfer Adaptation Learning(FReTAL)方法。使用 FReTAL 在新的 deepfake 数据集上执行域适应任务,同时尽量减少 catastrophic forgetting(灾难性遗忘)。
student 模型可以通过从预训练好的 teacher 模型中进行知识蒸馏,并在域适应过程中不使用源域数据的情况下应用迁移学习来快速适应新类型的deepfake。通过在 FaceForensics++ 数据集上的实验,证明 FReTAL 在域适应任务上优于所有基线,在低质量的deepfakes 上的准确率高达 86.97%。
论文链接:https://arxiv.org/abs/2105.13617
项目链接:https://github.com/alsgkals2/FReTAL-Domain-Transfer-Adaptation-learning-without-Prior-data

标签:知识蒸馏+表征学习+Deepfake Detection
02
FCPose: Fully Convolutional Multi-Person Pose Estimation with Dynamic Instance-Aware Convolutions
来自阿德莱德大学&蒙纳士大学
FCPose,无 ROI 和无分组的端到端可训练人体姿势估计器可以达到更好的准确性和速度,与最近的自上而下和自下而上的方法相比,更有优势。
FCPose,是一个使用动态实例感知卷积的完全卷积式多人姿势估计框架。现有的方法通常需要 ROI(感兴趣区域)操作和/或分组后处理,与之不同的是,FCPose 通过动态实例感知的关键点估计头消除了 ROI 和分组后处理。
实验结果证明,在 COCO 数据集上,使用 DLA-34 主干的 FCPose 实时版本比 Mask R-CNN(ResNet-101)快 4.5 倍(41.67FPS vs. 9.26FPS),同时实现了性能的提高。与其他最先进的方法相比,FCPose 还实现了更好的速度/准确度权衡。FCPose 是一个简单而有效的多人姿势估计框架。
论文链接:https://arxiv.org/abs/2105.14185
项目链接:https://github.com/aim-uofa/AdelaiDet

标签:CVPR 2021+姿态估计
03
Towards Diverse Paragraph Captioning for Untrimmed Videos
来自中国人民大学&INRIA
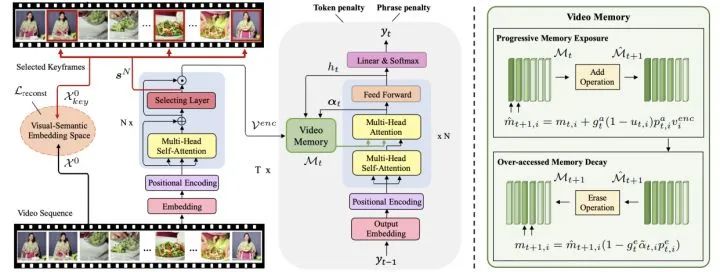
提出一个段落字幕模型,可以避开有问题的事件检测阶段,直接为未修剪的视频生成段落。对于如何描述连贯而多样的事件,作者提出用动态视频记忆来加强传统的时间注意,逐步暴露新的视频特征,并抑制过度访问的视频内容,以控制模型的视觉焦点。另外提出一种多样性驱动的训练策略,来提高语言角度的段落多样性。由于未经修剪的视频通常包含大量但多余的帧,作者又进一步用关键帧感知增强视频编码器以提高效率。
在 ActivityNet 和 Charades 数据集上的实验结果表明,所提出模型在不使用任何事件边界标注的情况下,在准确性和多样性指标上都明显优于最先进的方法。
论文链接:https://arxiv.org/abs/2105.14477
项目链接:https://github.com/syuqings/video-paragraph
标签:CVPR 2021+视频描述
04
Connecting Language and Vision for Natural Language-Based Vehicle Retrieval
来自阿里达摩院&悉尼科技大学&浙江大学
本文方案获得第五届人工智能城市挑战赛第一名的成绩,在私人测试集上获得了 18.69% 的 MRR 准确率的竞争性表现。
论文链接:https://arxiv.org/abs/2105.14897
项目链接:https://github.com/ShuaiBai623/AIC2021-T5-CLV

标签:车辆检索+CVPR 2021
05
A Novel Graph-Theoretic Deep Representation Learning Method for Multi-Label Remote Sensing Image Retrieval
来自柏林工业大学
本文在多标签遥感(RS)图像检索问题的框架内提出一种全新的 graph-theoretic(图论)深度表示学习方法。所提出的方法旨在提取和利用与档案中每个 RS 图像相关的多标签同现关系。为此,每幅训练图像最初都用一个图结构来表示,提供基于区域的图像表示,结合局部信息和相关空间组织。不同于其他基于 graph 方法的是,所提出方法包含一个新的学习策略,用于训练一个深度神经网络,以自动预测档案中每个 RS 图像的图形结构。这个策略采用一个区域表示学习损失函数,根据图像内容的多标签同现关系来描述其特征。
实验结果表明,与最先进的深度表征学习方法相比,所提出的方法对 RS 中的检索问题非常有效。
论文链接:https://arxiv.org/abs/2106.00506
项目链接:https://git.tu-berlin.de/rsim/GT-DRL-CBIR

标签:IGARSS 2021+遥感图像检索
06
Prior-Enhanced Few-Shot Segmentation with Meta-Prototypes
来自浙江大学&悉尼科技大学
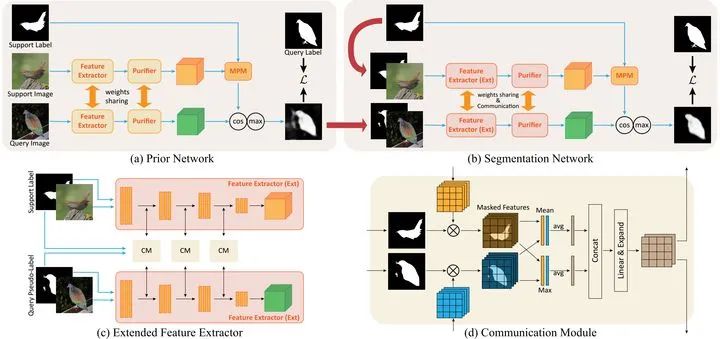
通过引入 episodic training 和 class-wise prototypes 可以提升 Few-shot segmentation(小样本分割FSS)的性能。但由于以下三个原因:1)模型被与任务无关的信息所干扰;(2)单个原型的表示能力有限;(3)与类相关的原型忽略了基类的先验知识;FSS 任务仍存在很大挑战。
在本次工作中,作者提出带有 Meta-Prototypes 的 Prior-Enhanced 网络来缓解上述挑战。它在特征提取中利用支持和查询(伪)标签,引导模型专注于前景物体的任务相关特征,并抑制由于缺乏监督知识而产生的大量噪音。此外,引入多个元原型来编码分层特征并学习与类别无关的结构信息。层次特征帮助模型突出决策边界并关注硬像素,而从基础类中学习的结构信息被视为新类的先验知识。
结果表明,所提出方法在 PASCAL-5i 和 COCO-20i 上平均IoU分数分别取得了 6 0.79% 和 41.16%,在 5-shot 设置情况下,比最先进的方法高出了 3.49% 和 5.64%。此外,与 1-shot 测试结果相比,在上述两个基准上将 5-shot 测试的准确性提高了 3.73% 和 10.32%。
论文链接:https://arxiv.org/abs/2106.00572
项目链接:https://github.com/Jarvis73/PEMP
标签:小样本分割
07
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
来自北大&微软亚洲研究
本次工作作者通过探索标记数据和额外的未标记数据对半监督语义分割的问题进行了研究。并提出一种新的一致性正则化方法,cross pseudo supervision(CPS)。通过使用从一个网络获得的 one-hot 伪分割图来监督另一个网络,从而使具有相同结构和不同初始化的两个网络之间具有一致性。CPS 的一致性有两个作用:鼓励两个扰动网络对同一输入图像预测的高度相似性,并通过使用带有伪分割图的未标记数据来扩大训练数据。在 Cityscapes 和PASCAL VOC 2012 上实现了最先进的半监督分割性能。
论文链接:https://arxiv.org/abs/2106.01226
项目链接:https://github.com/charlesCXK/TorchSemiSeg

标签:CVPR 2021+语义分割
08
Robust Reference-based Super-Resolution via C2-Matching
来自南洋理工大学&腾讯pcg
基于参考的超级分辨率(Ref-SR)是近期非常值得研究的一项任务,它是通过引入额外的高分辨率(HR)参考图像来增强低分辨率(LR)输入图像。现有的 Ref-SR 方法大多依赖于隐性的对应匹配,从参考图像中借用HR纹理来补偿输入图像的信息损失。但由于在输入和参考图像之间存在两个差距:transformation gap(转换差距(如比例和旋转))和分辨率差距(如HR和LR),会导致执行局部迁移变得困难。
方案:提出 C2-Matching,它可以跨过 transformation(变换)和分辨率,产生明确的鲁棒性匹配。具体来说,对于 transformation gap,提出 contrastive correspondence network(对比性对应网络),使用输入图像的增强视图来学习 transformation-robust 对应关系;对于分辨率差距,采用 teacher-student 关联蒸馏法,从较容易的 HR-HR 匹配中进行知识蒸馏,来指导较模糊的 LR-HR 匹配;最后,通过设计一个动态聚合模块来解决隐藏的错位问题。另外,为了更好对 Ref-SR 在现实环境下的性能进行评估,作者构建了 Webly-Referenced SR(WR-SR)数据集,它模拟了实际使用场景。
结果表明,在标准的 CUFED5 基准上,C2-Matching 明显优于现有技术水平,超过 1dB。值得注意的是,它在WR-SR 数据集上也显示出它极强的泛化能力,以及对大尺度和旋转变换的鲁棒性。
论文链接:https://arxiv.org/abs/2106.01863
项目链接:https://github.com/yumingj/C2-Matching
主页链接:https://yumingj.github.io/projects/C2_matching

标签:CVPR 2021+超分辨率
09
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
来自麻省理工学院&谷歌
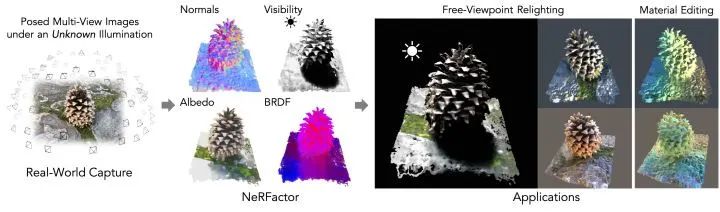
所要解决得问题是,从一个未知照明条件下的物体摆放的多视角图像中恢复物体的形状和空间变化的反射率。达到可以在任意环境照明下渲染物体的新视角,并编辑物体的材料属性。
方案:提出 Neural Radiance Factorization(NeRFactor),其关键思想是将物体的神经辐射场(NeRF)表示的体积几何学蒸馏成一个表面表示,然后在解决空间变化的反射率和环境照明的同时,共同完善几何形状。
具体来说,NeRFactor 在没有任何监督的情况下,只使用了重新渲染损失、简单的平滑度先验和从真实世界BRDF测量中学习的数据驱动的BRDF先验,恢复了表面法线、光线可见度、反照率和 BRDFs 的三维神经场。通过明确地对光的可见性进行建模,NeRFactor 能够将阴影与反照率分开,并在任意的照明条件下合成真实的软阴影或硬阴影。
NeRFactor 能够恢复令人信服的三维模型,以便在这种具有挑战性和欠约束的捕捉设置中对合成和真实场景进行自由视点重照明。实验表明,NeRFactor 在各种任务中的表现优于经典和基于深度学习的技术水平。
论文链接:https://arxiv.org/abs/2106.01970
项目链接:https://github.com/google/nerfactor
主页链接:https://people.csail.mit.edu/xiuming/projects/nerfactor/
视频链接:https://www.youtube.com/watch?v=UUVSPJlwhPg
标签:神经渲染
10
CT-Net: Channel Tensorization Network for Video Classification
来自中科院&国科大&SIAT&中佛罗里达大学
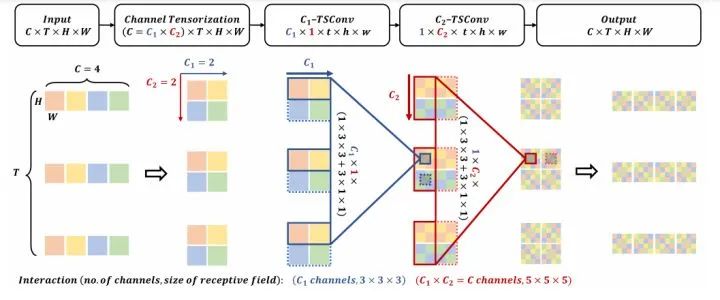
文中构建一个高效的张量可分离卷积来学习鉴别性的视频表征。将输入特征的通道维度看作是K个子维度的乘法,并沿K个子维度堆叠空间/时间张量可分离卷积。CT-模块与张量激发机制合作,可以进一步提高性能。实验验证得出CT-Net 在大规模视频数据集上获得了精度和效率之间的理想平衡。
论文链接:https://arxiv.org/abs/2106.01603
项目链接:https://github.com/Andy1621/CT-Net
标签:视频分类+ICLR 2021
- END -
编辑:CV君
转载请联系本公众号授权

备注如:SR

计算机视觉交流群
分割、检索、神经渲染、SR等最新资讯,若已为CV君好友请直接私信。
在看,让更多人看到 

